






什么是正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
通配符


通配符的使用
import glob
glob.glob('./[0-9].*')
['./1.gif', './2.txt']
glob.glob('*.gif')
['1.gif', 'card.gif']
glob.glob('?.gif')
['1.gif']
glob.glob('**/*.txt', recursive=True)
['2.txt', 'sub/3.txt']
glob.glob('./**/', recursive=True)
['./', './sub/']
import glob
glob.glob('*.gif')
['card.gif']
glob.glob('.c*')
['.card.gif']
"""
import os
import glob
files1 = [file for file in os.listdir('.') if file.endswith('.conf')]
#获取当前目录所有以.conf结尾的文件;
files2= glob.glob('./*.conf')
print(files1)
print(files2)
正则表达式的常用方法
使用re模块
import re
#*************************match方法*************************
#match尝试从字符串的起始位置开始匹配;
#如果起始位置没有匹配成功, 返回None;
#如果起始位置匹配成功, 返回一个对象, 通过group方法获取匹配的内容;
#Try to apply the pattern at the start of the string, returning
#a match object, or None if no match was found.
aObj = re.match(r'we', 'wetoshello')
print(aObj)
print(aObj.group())
#\d 单个数字
#\D \d的取反 , 除了数字之外
bObj = re.match(r'\d', '1westos')
if bObj:
print(bObj.group())
bObj = re.match(r'\D', '_westos')
if bObj:
print(bObj.group())
#*****************************findall********************
#findall会扫描整个字符串, 获取匹配的所有内容;
res = re.findall(r'\d\d', '阅读数为2 点赞数为10')
print(res)
#*************************search*******************8
#search会扫描整个字符串, 只返回第一个匹配成功的内容的SRE对象;
#如果起始位置没有匹配成功, 返回None;
#如果起始位置匹配成功, 返回一个对象, 通过group方法获取匹配的内容;
resObj = re.search(r'\d', '阅读数为8 点赞数为10')
if resObj:
print(resObj.group())
正则表达式的特殊字符类
特殊字符类:
.: 匹配除了\n之外的任意字符; [.\n]
\d: digit–(数字), 匹配一个数字字符, 等价于[0-9]
\D: 匹配一个非数字字符, 等价于[^0-9]
\s: space(广义的空格: 空格, \t, \n, \r), 匹配单个任何的空白字符;
\S: 匹配除了单个任何的空白字符;
\w: 字母数字或者下划线, [a-zA-Z0-9_]
\W: 除了字母数字或者下划线, [^a-zA-Z0-9_]
import re
#匹配数字
#pattern = r'\d'
pattern = r'[0-9]'
string = "hello_1$%"
print(re.findall(pattern, string))
#匹配字母数字或者下划线;
#pattern = r'\w'
pattern = r'[a-zA-Z0-9_]'
string = "hello_1$%"
print(re.findall(pattern, string))
#匹配除了字母数字或者下划线;
#pattern = r'\W'
pattern = r'[^a-zA-Z0-9_]'
string = "hello_1$%"
print(re.findall(pattern, string))
#.: 匹配除了\n之外的任意字符; [.\n]
print(re.findall(r'.', 'hello westos\n\t%$'))
指定字符出现的次数
匹配字符出现次数:
: 代表前一个字符出现0次或者无限次; \d, .*
+: 代表前一个字符出现一次或者无限次; d+
?: 代表前一个字符出现1次或者0次; 假设某些字符可省略, 也可以不省略的时候使用
第二种方式:
{m}: 前一个字符出现m次;
{m,}: 前一个字符至少出现m次; * == {0,}; + ==={1,}
{m,n}: 前一个字符出现m次到n次; ? === {0,1}
^: 以什么开头
$: 以什么结尾
import re
#* : 代表前一个字符出现0次或者无限次; \d *,.*
print(re.findall(r'\d*', '234'))
print(re.findall(r'.*', 'hello223%'))
print(re.findall(r'd*', 'ddhello223%'))
#+: 代表前一个字符出现一次或者无限次; d+
print(re.findall(r'd+', ''))
print(re.findall(r'd+', 'dddderrttt'))
print(re.findall(r'\d+', '阅读数: 8976 点赞数:900'))
#?: 代表前一个字符出现1次或者0次; 假设某些字符可省略, 也可以不省略的时候使用
#2019-10
print(re.findall(r'\d+-?\d+', '2019-10'))
print(re.findall(r'\d+-?\d+', '201910'))
print(re.findall(r'\d{4}-?\d{1,}', '2019-1'))
print(re.findall(r'\d{4}-?\d{1,2}', '2019-10'))
print(re.findall(r'\d+-?\d+', '201910'))
练习题–北美电话的合法性
问题描述:
北美电话的常用格式:(eg: 2703877865)
前3位: 第一位是区号以2~9开头 , 第2位是0~8, 第三位数字可任意;
中间三位数字:第一位是交换机号, 以2~9开头, 后面两位任意
最后四位数字: 数字不做限制;
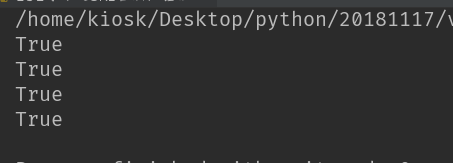
import re
#pattern = r'[2-9][0-8]\d[2-9]\d\d\d\d\d\d' # 传统方式
pattern = r'[2-9][0-8]\d[2-9]\d{6}' # 利用重复符号方式
string = "phone: 1777777777"
print(re.findall(pattern, string))
首个数字是1 匹配不到结果

练习-匹配邮箱规则
练习: 匹配一个163邮箱;(xdshcdshvfhdvg@qq.com) — 如果想在正则里面匹配真实的. , .
#xdshcdshvfhdvg(可以由字母数字或者下划线组成, 但是不能以数字或者下划线开头; 位数是6-12之间)
import re
def isEmail(address):
pattern = r'^[a-zA-Z]\w{5,11}@163.com$'
res = re.findall(pattern, address)
if res:
return True
else:
return False
if __name__ == '__main__':
print(isEmail('hello@163.com'))
print(isEmail('wehello@163.com'))
print(isEmail('wehello@163.comaa'))
练习-url合法性检验
问题描述:
检查某段给定的文本是否是一个符合需要的URL;
思路:
1). 检查URL是否以web浏览器普遍采用的通信协议方案开头: http, https, ftp file
2). 协议后面紧跟 ?/
3). 协议后面字符任意;
import re
def isUrl(url):
pattern = re.compile(r'^(http|https|ftp|file)://.+$')
resObj = re.search(pattern, url)
if resObj:
return True
return False
if __name__ == '__main__':
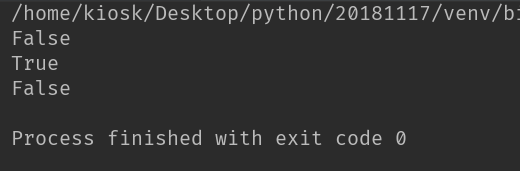
print(isUrl('file:///tmp'))
print(isUrl('http://www.baidu.com'))
print(isUrl('https://www.baidu.com'))
print(isUrl('ftp://www.baidu.com'))
北美电话号码的合法性
1234567890
123-456-7890
123.456.7890
123 456 7890
(123) 456 7890
统一格式为:
(123) 456-7890
import re
def isPhone(phone):
pattern = r"\(?(?P<firstNum>[2-9][0-8]\d)\)?[-\.\s]?(?P<secondNum>[2-9]\d{2})" \
r"[-\.\s]?(?P<thirdNum>\d{4})"
res = re.search(pattern, phone)
if res:
info = res.groupdict()
formatPhone = "(%s) %s-%s" %(info['firstNum'],
info['secondNum'], info['thirdNum'])
print(formatPhone)
return True
return False
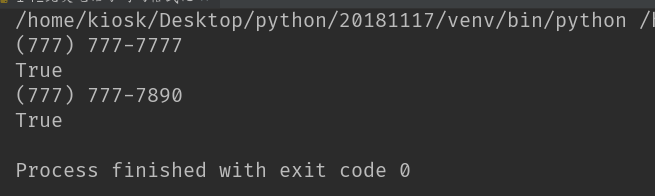
print(isPhone('777-777-7777'))
print(isPhone('(777) 777 7890'))
字符串的替换与分离
import re
s = 'westos is a company'
print(s.replace('westos', 'fentiao'))
#将westos和company都替换位cat
print(re.sub(r'(westos|company)', 'cat', s))
#将所有的数字替换位0;
s1 = "本次转发数位100, 点赞数为80;"
print(re.sub(r'\d+', '0', s1))
def addNum(Obj):
# num是一个字符串
num = Obj.group()
# newNum是一个整形数
newNum = int(num) + 1
return str(newNum)
#.*?
#对于所有的数字加1;
print(re.sub(r'\d+', addNum, s1))
s2 = '1+2=3'
print(re.split(r'[+=]', s2))
匹配URL地址
import re
url = 'http://www.baidu.com'
pattern = r'^((https|http|ftp|rtsp|mms)?:\/\/)\S+'
# 进行分组的时候, findall方法只返回分组里面的内容;
# print(re.findall(pattern, url))
resObj = re.search(pattern, url)
if resObj:
# group方法会返回匹配的所有内容;
print(resObj.group())
# groups方法返回分组里面的内容;
print(resObj.groups())
匹配日期
import re
date = '2019-10-10'
pattern = r'\d{4}(\-|\/|.)\d{1,2}\1\d{1,2}'
reObj = re.search(pattern, date)
if reObj:
print(reObj.group())
print(reObj.groups())
匹配用户名
字符串是否包含中文 []表示匹配方括号的中任意字符,
\u4e00是Unicode中汉字的开始,\u9fa5则是Unicode中汉字的结束
[\w-\u4e00-\u9fa5]+
import re
user = '西部开源123'
pattern = r'[\w\-\u4e00-\u9fa5]+'
print(re.findall(pattern, user))














 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









