









一、将数组转换为ArrayList
要将数组转换为ArrayList,开发人员通常会这样做:
List<String> list = Arrays.asList(arr);
Arrays.asList()将返回 ArrayList私有静态类的Arrays,而不是java.util.ArrayList类。该java.util.Arrays.ArrayList有set(),get(),contains()方法,但没有添加元素的任何方法,所以它的大小是固定的。要创建一个real ArrayList,您应该执行以下操作:
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(arr));
构造函数 ArrayList可以接收 Collection类型,它也是超类型java.util.Arrays.ArrayList。
二、检查数组是否包含值
开发人员经常这样做:
1 Set<String> set = new HashSet<String>(Arrays.asList(arr));
2 return set.contains(targetValue);
该代码有效,但是无需先转换列表即可设置。将列表转换为集合需要额外的时间。它可以很简单:
Arrays.asList(arr).contains(targetValue);
or
1 for(String s: arr){
2 if(s.equals(targetValue))
3 return true;
4 }
5 return false;
第一个比第二个更具可读性。
三、从循环内的列表中删除元素
考虑以下代码,该代码在迭代期间删除元素:
1 ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c", "d"));
2 for (int i = 0; i < list.size(); i++) {
3 list.remove(i);
4 }
5 System.out.println(list)
输出为:
[b,d]
该方法存在严重的问题。删除元素后,列表的大小会缩小,索引也会更改。因此,如果您想通过使用索引删除循环中的多个元素,那将无法正常工作。您可能知道使用迭代器是删除循环内元素的正确方法,并且您知道 Java中的 foreach循环就像迭代器一样工作,但实际上并非如此。考虑以下代码:
1 ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c", "d"));
2
3 for (String s : list) {
4 if (s.equals("a"))
5 list.remove(s);
6 }
它将抛出ConcurrentModificationException,因为它去检查list前后的大小的时候,发现不相等就会抛错,具体源码中有体现。相反,可以执行以下操作:
1 ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c", "d"));
2 Iterator<String> iter = list.iterator();
3 while (iter.hasNext()) {
4 String s = iter.next();
5
6 if (s.equals("a")) {
7 iter.remove();
8 }
9 }
.next()必须在.remove()方法之前调用。在 foreach循环中,编译器将 .next()方法在元素删除操作之后进行调用,从而导致ConcurrentModificationException。
ArrayList.iterator()的源代码:

1 ...
2
3 public Iterator<E> iterator() {
4 return new Itr();
5 }
6
7 /**
8 * AbstractList.Itr的优化版本
9 */
10 private class Itr implements Iterator<E> {
11 int cursor; // 下一元素的索引返回
12 int lastRet = -1; // 返回的最后一个元素的索引,如果没有这为 -1
13 int expectedModCount = modCount;
14
15 public boolean hasNext() {
16 return cursor != size;
17 }
18
19 @SuppressWarnings("unchecked")
20 public E next() {
21 checkForComodification();
22 int i = cursor;
23 if (i >= size)
24 throw new NoSuchElementException();
25 Object[] elementData = ArrayList.this.elementData;
26 if (i >= elementData.length)
27 throw new ConcurrentModificationException();
28 cursor = i + 1;
29 return (E) elementData[lastRet = i];
30 }
31
32 public void remove() {
33 if (lastRet < 0)
34 throw new IllegalStateException();
35 checkForComodification();
36
37 try {
38 ArrayList.this.remove(lastRet);
39 cursor = lastRet;
40 lastRet = -1;
41 expectedModCount = modCount;
42 } catch (IndexOutOfBoundsException ex) {
43 throw new ConcurrentModificationException();
44 }
45 }
46
47 final void checkForComodification() {
48 if (modCount != expectedModCount)
49 throw new ConcurrentModificationException();
50 }
51 }
52
53 ...
四、HashTable 、HashMap、LinkedHashMap、TreeMap
HashMap 和 HashTable之间的主要区别是 HashTable同步(所有的读写等操作都进行了锁(synchronized)保护,在多线程环境下没有安全问题。但是锁保护也是有代价的,会对读写的效率产生较大影响)。因此,通常建议不使用 HashTable,而使用 HashMap。
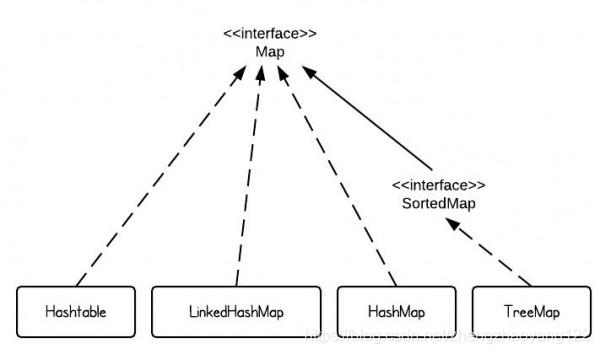
Java SE中有4种常用的Map实现-HashMap,TreeMap,Hashtable和LinkedHashMap。如果我们仅使用一个句子来描述每个实现,则将是以下内容:这就是如果程序是线程安全的,则应使用 HashMap的原因。
【1】HashMap被实现为哈希表,并且键或值没有排序。
【2】TreeMap是基于红黑树结构实现的,并通过 key进行排序。
【3】LinkedHashMap保留插入顺序
【4】与 HashMap相比,Hashtable是同步的。同步有开销。
如果 HashMap的键是自定义对象,则需要遵循equals()和hashCode()协定。
1 class Dog {
2 String color;
3
4 Dog(String c) {
5 color = c;
6 }
7 public String toString(){
8 return color + " dog";
9 }
10 }
11
12 public class TestHashMap {
13 public static void main(String[] args) {
14 HashMap<Dog, Integer> hashMap = new HashMap<Dog, Integer>();
15 Dog d1 = new Dog("red");
16 Dog d2 = new Dog("black");
17 Dog d3 = new Dog("white");
18 Dog d4 = new Dog("white");
19
20 hashMap.put(d1, 10);
21 hashMap.put(d2, 15);
22 hashMap.put(d3, 5);
23 hashMap.put(d4, 20);
24
25 //print size
26 System.out.println(hashMap.size());
27
28 //loop HashMap
29 for (Entry<Dog, Integer> entry : hashMap.entrySet()) {
30 System.out.println(entry.getKey().toString() + " - " + entry.getValue());
31 }
32 }
33 }
【输出结果】 :
1 4
2 white dog - 5
3 black dog - 15
4 red dog - 10
5 white dog - 20
注意这里,我们错误地两次添加了“white dog”,但是 HashMap接受了它。这没有道理,因为现在我们对真正有多少只 white dog感到困惑。Dog类应定义如下:
1 class Dog {
2 String color;
3
4 Dog(String c) {
5 color = c;
6 }
7
8 public boolean equals(Object o) {
9 return ((Dog) o).color.equals(this.color);
10 }
11
12 public int hashCode() {
13 return color.length();
14 }
15
16 public String toString(){
17 return color + " dog";
18 }
19 }
【输出结果】 :
1 3
2 red dog - 10
3 white dog - 20
4 black dog - 15
原因是 HashMap不允许两个相同的元素。默认情况下,使用在 Object类中实现的hashCode()和equals()方法。默认的hashCode()方法为不同的对象提供不同的整数,而equals()方法仅在两个引用引用同一对象时才返回true。所以hashCode()和equals()方法校验结果不相同。如果重写了此方法,就会返回true,过滤掉多余的 white dog 。
五、使用原始集合类型
在Java中,原始类型和无界通配符类型很容易混合在一起。以 Set为例,Set是原始类型,Set<?>无界通配符类型。考虑以下使用原始类型List作为参数的代码:
1 public static void add(List list, Object o){
2 list.add(o);
3 }
4 public static void main(String[] args){
5 List<String> list = new ArrayList<String>();
6 add(list, 10);
7 String s = list.get(0);
8 }
此代码将引发异常:
线程“主”中的异常java.lang.ClassCastException:无法将java.lang.Integer强制转换为java.lang.String
...
使用原始类型集合很危险,因为原始类型集合会跳过泛型类型检查并且不安全。之间存在巨大差异Set,Set<?>和Set<Object>。如果要使用泛型类型,但不知道或不在乎该参数的实际类型,则可以使用<?>但不能插入nul。如果知道类型则需要传入类型,因为原始类型没有限制。
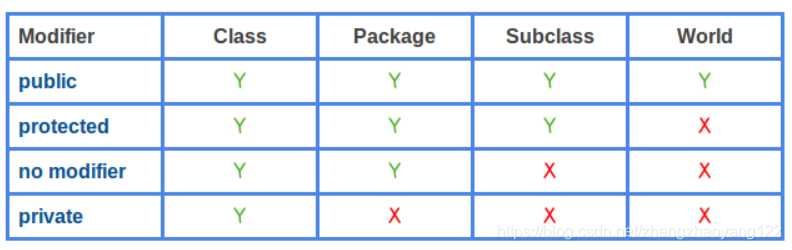
六、访问权限
开发人员经常将 public用于类字段。通过直接引用很容易获得字段值,但这是一个非常糟糕的设计。经验法则是为成员提供尽可能低的访问级别。下面总结了成员的不同修饰符的访问级别。访问级别确定字段和方法的可访问性。它具有4个级别:公共,受保护,包私有(无显式修饰符)或私有。
七、ArrayList与LinkedList
当开发人员不知道 ArrayList和LinkedList 之间的区别时,他们经常使用ArrayList,因为它看起来很熟悉。但是,它们之间存在巨大的性能差异。简而言之,LinkedList如果有大量的添加/删除操作并且没有很多随机访问操作,则应首选此方法。如果您是新手,请查看 ArrayListvs.LinkedList以获得有关其性能的更多信息。
八、可变与不可变
不可变的对象具有许多优点,例如简单性,安全性等。但是对于每个不同的值,它都需要一个单独的对象,并且太多的对象可能会导致垃圾回收的高成本。在可变和不可变之间进行选择时应保持平衡。通常,使用可变对象以避免产生太多中间对象。一个经典的例子是 String 连接大量的字符串时,如果使用不可变的字符串,则会立即产生许多符合垃圾回收条件的对象,会浪费CPU的时间和精力。所以需要使用可变对象(例如StringBuilder)
1 String result="";
2 for(String s: arr){
3 result = result + s;
4 }
还有其他一些情况需要可变对象。例如,将可变对象传递给方法收集多个结果。另一个示例是排序和过滤:当然,您可以创建一个原始集合,利用原始集合的排序方法返回排序结果,但是这对于较大的集合将变得非常浪费。
九、Super 和 Sub的构造函数
因为未定义默认的超级构造函数,所以会发生此编译错误。在Java中,如果类未定义构造函数,则编译器将默认为该类插入默认的无参数构造函数。如果在Super类中定义了构造函数,在这种情况下为Super(String s),则编译器将不会插入默认的无参数构造函数。上面的超级类就是这种情况。
Sub类的构造函数(带参数或无参数)将调用无参数Super构造函数。由于编译器试图将super() 插入Sub类中的2个构造函数,但是未定义 Super的默认构造函数,因此编译器将报告错误消息。
要解决此问题,只需【1】将Super() 构造函数添加到Super类,例如:
1 public Super(){
2 System.out.println("Super");
3 }
【2】或者删除自定义的Super构造函数;
【3】或者添加super(value)到子构造函数;
十、还是构造函数
可以通过两种方式创建字符串:
1 //1. use double quotes
2 String x = "abc";
3 //2. use constructor
4 String y = new String("abc")
有什么区别?以下示例可以提供快速解答:
1 String a = "abcd";
2 String b = "abcd";
3 System.out.println(a == b); // True
4 System.out.println(a.equals(b)); // True
5
6 String c = new String("abcd");
7 String d = new String("abcd");
8 System.out.println(c == d); // False
9 System.out.println(c.equals(d)); // True
么区别?以下示例可以提供快速解答:
[[外链图片转存中…(img-2UMV56AJ-1618317594480)]](javascript:void(0)😉
1 String a = "abcd";
2 String b = "abcd";
3 System.out.println(a == b); // True
4 System.out.println(a.equals(b)); // True
5
6 String c = new String("abcd");
7 String d = new String("abcd");
8 System.out.println(c == d); // False
9 System.out.println(c.equals(d)); // True














 1759
1759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









