







一.下载IMDB数据集
在之前第二个介绍tensorflow的博客里面关于文本分类的时候,也是使用的IMDB数据集,但是需要注意的是那时候我们将每一个样本的单词数目扩充到256的长度,而不是采用下面的方法,下面我们将每一个样本都转化成10000维度的向量,比如样本[3,5]只有下标3和5的地方向量的元素值为1,其他情况下都是为0.实现这个步骤的代码封装在函数multi_hot_sequences(sequences,dimension)里面,注意我们先创建长度为len(sequences)*dimension的数组(元素全为0),然后在更新参数为1.
代码:
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
imdb=keras.datasets.imdb
NUM_WORDS=10000
(train_data,train_labels),(test_data,test_labels)=imdb.load_data(num_words=NUM_WORDS)
def multi_hot_sequences(sequences,dimension):
#create an all-zero matrix of shape(len(sequences),dimension)
results=np.zeros((len(sequences),dimension))
for i,word_indices in enumerate(sequences):
results[i,word_indices]=1.0
return results
# print(train_data.shape)
train_data=multi_hot_sequences(train_data,NUM_WORDS)
test_data=multi_hot_sequences(test_data,NUM_WORDS)
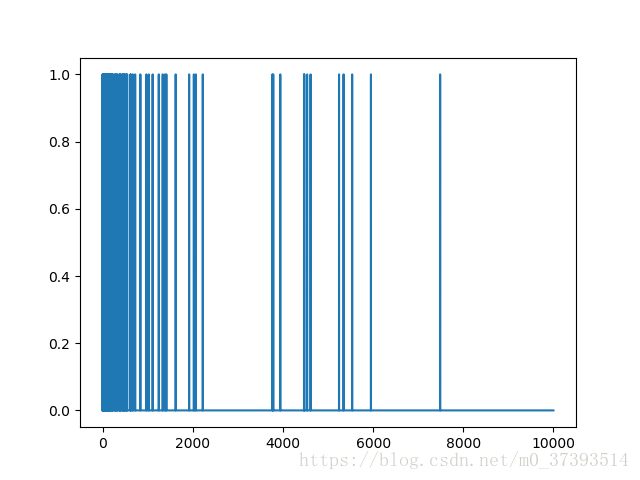
plt.plot(train_data[0])
plt.show()
# print(train_data.shape)结果:之前的train_data的shape为(25000,),现在的train_data的shape为(25000,10000),每一行都是一个样本的向量.
二.证明过拟合
记住一点:深度学习的模型很容易在训练集上很好的拟合,但是难点在于在很好的在未见过的数据上范化.
第二点:当你的模型很小的时候很难学习到足够的特性,过大的话第一内存不行,第二个过拟合的问题.
2.1 创造基线模型
代码如下:下面这个基线模型,设置verbose参数为2,是为每一个epoch进行输出一条记录.
baseline_model=keras.Sequential([
keras.layers.Dense(16,activation=tf.nn.relu,input_shape=(10000,)),
keras.layers.Dense(16,activation=tf.nn.relu),
keras.layers.Dense(1,activation=tf.nn.sigmoid)
])
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
baseline_model.summary()
baseline_history=baseline_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data,test_labels),
verbose=2)
结果展示:
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 16) 160016
_________________________________________________________________
dense_2 (Dense) (None, 16) 272
_________________________________________________________________
dense_3 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
_________________________________________________________________
Epoch 1/20
- 3s - loss: 0.5991 - acc: 0.5974 - binary_crossentropy: 0.5991 - val_loss: 0.5215 - val_acc: 0.8069 - val_binary_crossentropy: 0.5215
Epoch 2/20
- 3s - loss: 0.4568 - acc: 0.8730 - binary_crossentropy: 0.4568 - val_loss: 0.4494 - val_acc: 0.8670 - val_binary_crossentropy: 0.4494
Epoch 3/20
- 3s - loss: 0.2811 - acc: 0.9266 - binary_crossentropy: 0.2811 - val_loss: 0.2895 - val_acc: 0.8864 - val_binary_crossentropy: 0.2895
Epoch 4/20
- 3s - loss: 0.1659 - acc: 0.9458 - binary_crossentropy: 0.1659 - val_loss: 0.3049 - val_acc: 0.8816 - val_binary_crossentropy: 0.3049
Epoch 5/20
- 3s - loss: 0.1254 - acc: 0.9602 - binary_crossentropy: 0.1254 - val_loss: 0.3324 - val_acc: 0.8739 - val_binary_crossentropy: 0.3324
Epoch 6/20
- 3s - loss: 0.0953 - acc: 0.9718 - binary_crossentropy: 0.0953 - val_loss: 0.3640 - val_acc: 0.8719 - val_binary_crossentropy: 0.3640
Epoch 7/20
- 3s - loss: 0.0717 - acc: 0.9809 - binary_crossentropy: 0.0717 - val_loss: 0.4085 - val_acc: 0.8654 - val_binary_crossentropy: 0.4085
Epoch 8/20
- 3s - loss: 0.0527 - acc: 0.9875 - binary_crossentropy: 0.0527 - val_loss: 0.4538 - val_acc: 0.8654 - val_binary_crossentropy: 0.4538
Epoch 9/20
- 3s - loss: 0.0370 - acc: 0.9930 - binary_crossentropy: 0.0370 - val_loss: 0.4920 - val_acc: 0.8632 - val_binary_crossentropy: 0.4920
Epoch 10/20
- 3s - loss: 0.0252 - acc: 0.9963 - binary_crossentropy: 0.0252 - val_loss: 0.5243 - val_acc: 0.8610 - val_binary_crossentropy: 0.5243
Epoch 11/20
- 3s - loss: 0.0175 - acc: 0.9981 - binary_crossentropy: 0.0175 - val_loss: 0.5733 - val_acc: 0.8620 - val_binary_crossentropy: 0.5733
Epoch 12/20
- 3s - loss: 0.0122 - acc: 0.9988 - binary_crossentropy: 0.0122 - val_loss: 0.6084 - val_acc: 0.8604 - val_binary_crossentropy: 0.6084
Epoch 13/20
- 3s - loss: 0.0087 - acc: 0.9993 - binary_crossentropy: 0.0087 - val_loss: 0.6388 - val_acc: 0.8603 - val_binary_crossentropy: 0.6388
Epoch 14/20
- 3s - loss: 0.0064 - acc: 0.9997 - binary_crossentropy: 0.0064 - val_loss: 0.6660 - val_acc: 0.8598 - val_binary_crossentropy: 0.6660
Epoch 15/20
- 2s - loss: 0.0047 - acc: 0.9999 - binary_crossentropy: 0.0047 - val_loss: 0.6902 - val_acc: 0.8602 - val_binary_crossentropy: 0.6902
Epoch 16/20
- 3s - loss: 0.0036 - acc: 1.0000 - binary_crossentropy: 0.0036 - val_loss: 0.7084 - val_acc: 0.8598 - val_binary_crossentropy: 0.7084
Epoch 17/20
- 3s - loss: 0.0029 - acc: 1.0000 - binary_crossentropy: 0.0029 - val_loss: 0.7291 - val_acc: 0.8606 - val_binary_crossentropy: 0.7291
Epoch 18/20
- 3s - loss: 0.0024 - acc: 1.0000 - binary_crossentropy: 0.0024 - val_loss: 0.7460 - val_acc: 0.8594 - val_binary_crossentropy: 0.7460
Epoch 19/20
- 3s - loss: 0.0020 - acc: 1.0000 - binary_crossentropy: 0.0020 - val_loss: 0.7608 - val_acc: 0.8598 - val_binary_crossentropy: 0.7608
Epoch 20/20
- 3s - loss: 0.0017 - acc: 1.0000 - binary_crossentropy: 0.0017 - val_loss: 0.7742 - val_acc: 0.8594 - val_binary_crossentropy: 0.77422.2 创造小点的模型
代码如下:神经元数目降低
smaller_model=keras.Sequential([
keras.layers.Dense(4,activation=tf.nn.relu,input_shape=(10000,)),
keras.layers.Dense(4,activation=tf.nn.relu),
keras.layers.Dense(1,activation=tf.nn.sigmoid)
])
smaller_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
smaller_model.summary()
smaller_history=smaller_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data,test_labels),
verbose=2)结果展示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 4) 40004
_________________________________________________________________
dense_4 (Dense) (None, 4) 20
_________________________________________________________________
dense_5 (Dense) (None, 1) 5
=================================================================
Total params: 40,029
Trainable params: 40,029
Non-trainable params: 0
_________________________________________________________________
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 3s - loss: 0.6105 - acc: 0.7224 - binary_crossentropy: 0.6105 - val_loss: 0.5243 - val_acc: 0.8374 - val_binary_crossentropy: 0.5243
Epoch 2/20
- 3s - loss: 0.4352 - acc: 0.8771 - binary_crossentropy: 0.4352 - val_loss: 0.3993 - val_acc: 0.8734 - val_binary_crossentropy: 0.3993
Epoch 3/20
- 3s - loss: 0.3257 - acc: 0.9021 - binary_crossentropy: 0.3257 - val_loss: 0.3344 - val_acc: 0.8828 - val_binary_crossentropy: 0.3344
Epoch 4/20
- 3s - loss: 0.2637 - acc: 0.9170 - binary_crossentropy: 0.2637 - val_loss: 0.3044 - val_acc: 0.8850 - val_binary_crossentropy: 0.3044
Epoch 5/20
- 3s - loss: 0.2254 - acc: 0.9268 - binary_crossentropy: 0.2254 - val_loss: 0.2905 - val_acc: 0.8861 - val_binary_crossentropy: 0.2905
Epoch 6/20
- 3s - loss: 0.1985 - acc: 0.9340 - binary_crossentropy: 0.1985 - val_loss: 0.2833 - val_acc: 0.8889 - val_binary_crossentropy: 0.2833
Epoch 7/20
- 3s - loss: 0.1780 - acc: 0.9414 - binary_crossentropy: 0.1780 - val_loss: 0.2825 - val_acc: 0.8876 - val_binary_crossentropy: 0.2825
Epoch 8/20
- 3s - loss: 0.1616 - acc: 0.9475 - binary_crossentropy: 0.1616 - val_loss: 0.2858 - val_acc: 0.8853 - val_binary_crossentropy: 0.2858
Epoch 9/20
- 3s - loss: 0.1485 - acc: 0.9527 - binary_crossentropy: 0.1485 - val_loss: 0.2905 - val_acc: 0.8850 - val_binary_crossentropy: 0.2905
Epoch 10/20
- 3s - loss: 0.1362 - acc: 0.9571 - binary_crossentropy: 0.1362 - val_loss: 0.3014 - val_acc: 0.8806 - val_binary_crossentropy: 0.3014
Epoch 11/20
- 3s - loss: 0.1261 - acc: 0.9611 - binary_crossentropy: 0.1261 - val_loss: 0.3065 - val_acc: 0.8807 - val_binary_crossentropy: 0.3065
Epoch 12/20
- 3s - loss: 0.1168 - acc: 0.9640 - binary_crossentropy: 0.1168 - val_loss: 0.3199 - val_acc: 0.8775 - val_binary_crossentropy: 0.3199
Epoch 13/20
- 3s - loss: 0.1084 - acc: 0.9672 - binary_crossentropy: 0.1084 - val_loss: 0.3256 - val_acc: 0.8772 - val_binary_crossentropy: 0.3256
Epoch 14/20
- 3s - loss: 0.1009 - acc: 0.9709 - binary_crossentropy: 0.1009 - val_loss: 0.3375 - val_acc: 0.8757 - val_binary_crossentropy: 0.3375
Epoch 15/20
- 3s - loss: 0.0937 - acc: 0.9735 - binary_crossentropy: 0.0937 - val_loss: 0.3496 - val_acc: 0.8745 - val_binary_crossentropy: 0.3496
Epoch 16/20
- 3s - loss: 0.0873 - acc: 0.9756 - binary_crossentropy: 0.0873 - val_loss: 0.3615 - val_acc: 0.8730 - val_binary_crossentropy: 0.3615
Epoch 17/20
- 3s - loss: 0.0813 - acc: 0.9784 - binary_crossentropy: 0.0813 - val_loss: 0.3781 - val_acc: 0.8697 - val_binary_crossentropy: 0.3781
Epoch 18/20
- 3s - loss: 0.0757 - acc: 0.9802 - binary_crossentropy: 0.0757 - val_loss: 0.3944 - val_acc: 0.8682 - val_binary_crossentropy: 0.3944
Epoch 19/20
- 3s - loss: 0.0705 - acc: 0.9822 - binary_crossentropy: 0.0705 - val_loss: 0.4047 - val_acc: 0.8682 - val_binary_crossentropy: 0.4047
Epoch 20/20
- 3s - loss: 0.0654 - acc: 0.9848 - binary_crossentropy: 0.0654 - val_loss: 0.4194 - val_acc: 0.8663 - val_binary_crossentropy: 0.41942.3 创造大点的模型
代码:
bigger_model = keras.models.Sequential([
keras.layers.Dense(512, activation=tf.nn.relu, input_shape=(10000,)),
keras.layers.Dense(512, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
bigger_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
bigger_model.summary()
bigger_history = bigger_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
结果:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 512) 5120512
_________________________________________________________________
dense_7 (Dense) (None, 512) 262656
_________________________________________________________________
dense_8 (Dense) (None, 1) 513
=================================================================
Total params: 5,383,681
Trainable params: 5,383,681
Non-trainable params: 0
_________________________________________________________________
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 7s - loss: 0.3439 - acc: 0.8528 - binary_crossentropy: 0.3439 - val_loss: 0.2957 - val_acc: 0.8806 - val_binary_crossentropy: 0.2957
Epoch 2/20
- 6s - loss: 0.1364 - acc: 0.9492 - binary_crossentropy: 0.1364 - val_loss: 0.3539 - val_acc: 0.8661 - val_binary_crossentropy: 0.3539
Epoch 3/20
- 6s - loss: 0.0439 - acc: 0.9881 - binary_crossentropy: 0.0439 - val_loss: 0.4364 - val_acc: 0.8692 - val_binary_crossentropy: 0.4364
Epoch 4/20
- 6s - loss: 0.0076 - acc: 0.9990 - binary_crossentropy: 0.0076 - val_loss: 0.5780 - val_acc: 0.8716 - val_binary_crossentropy: 0.5780
Epoch 5/20
- 6s - loss: 0.0012 - acc: 0.9999 - binary_crossentropy: 0.0012 - val_loss: 0.6685 - val_acc: 0.8698 - val_binary_crossentropy: 0.6685
Epoch 6/20
- 6s - loss: 2.6833e-04 - acc: 1.0000 - binary_crossentropy: 2.6833e-04 - val_loss: 0.7131 - val_acc: 0.8698 - val_binary_crossentropy: 0.7131
Epoch 7/20
- 6s - loss: 1.5387e-04 - acc: 1.0000 - binary_crossentropy: 1.5387e-04 - val_loss: 0.7402 - val_acc: 0.8706 - val_binary_crossentropy: 0.7402
Epoch 8/20
- 7s - loss: 1.0960e-04 - acc: 1.0000 - binary_crossentropy: 1.0960e-04 - val_loss: 0.7599 - val_acc: 0.8708 - val_binary_crossentropy: 0.7599
Epoch 9/20
- 7s - loss: 8.3779e-05 - acc: 1.0000 - binary_crossentropy: 8.3779e-05 - val_loss: 0.7764 - val_acc: 0.8702 - val_binary_crossentropy: 0.7764
Epoch 10/20
- 7s - loss: 6.6693e-05 - acc: 1.0000 - binary_crossentropy: 6.6693e-05 - val_loss: 0.7897 - val_acc: 0.8706 - val_binary_crossentropy: 0.7897
Epoch 11/20
- 7s - loss: 5.4582e-05 - acc: 1.0000 - binary_crossentropy: 5.4582e-05 - val_loss: 0.8018 - val_acc: 0.8704 - val_binary_crossentropy: 0.8018
Epoch 12/20
- 6s - loss: 4.5420e-05 - acc: 1.0000 - binary_crossentropy: 4.5420e-05 - val_loss: 0.8124 - val_acc: 0.8704 - val_binary_crossentropy: 0.8124
Epoch 13/20
- 6s - loss: 3.8395e-05 - acc: 1.0000 - binary_crossentropy: 3.8395e-05 - val_loss: 0.8218 - val_acc: 0.8706 - val_binary_crossentropy: 0.8218
Epoch 14/20
- 7s - loss: 3.2831e-05 - acc: 1.0000 - binary_crossentropy: 3.2831e-05 - val_loss: 0.8311 - val_acc: 0.8709 - val_binary_crossentropy: 0.8311
Epoch 15/20
- 6s - loss: 2.8250e-05 - acc: 1.0000 - binary_crossentropy: 2.8250e-05 - val_loss: 0.8402 - val_acc: 0.8710 - val_binary_crossentropy: 0.8402
Epoch 16/20
- 7s - loss: 2.4467e-05 - acc: 1.0000 - binary_crossentropy: 2.4467e-05 - val_loss: 0.8478 - val_acc: 0.8711 - val_binary_crossentropy: 0.8478
Epoch 17/20
- 6s - loss: 2.1223e-05 - acc: 1.0000 - binary_crossentropy: 2.1223e-05 - val_loss: 0.8574 - val_acc: 0.8708 - val_binary_crossentropy: 0.8574
Epoch 18/20
- 6s - loss: 1.8474e-05 - acc: 1.0000 - binary_crossentropy: 1.8474e-05 - val_loss: 0.8652 - val_acc: 0.8710 - val_binary_crossentropy: 0.8652
Epoch 19/20
- 7s - loss: 1.6046e-05 - acc: 1.0000 - binary_crossentropy: 1.6046e-05 - val_loss: 0.8739 - val_acc: 0.8709 - val_binary_crossentropy: 0.8739
Epoch 20/20
- 7s - loss: 1.3964e-05 - acc: 1.0000 - binary_crossentropy: 1.3964e-05 - val_loss: 0.8834 - val_acc: 0.8709 - val_binary_crossentropy: 0.8834
2.4绘制训练和交叉验证损失函数
实线为训练集的损失,虚线为测试集的损失.
代码:
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
plot_history([('baseline', baseline_history),
('smaller', smaller_history),
('bigger', bigger_history)])
结果:
你可以看到更大的那个网络很快就过拟合了,导致训练集和交叉验证集损失之间很大的差距.
三.解决过拟合的方法
我们限制模型的复杂程度,使得每一个权值都取得很小的值来防止过拟合.这里我们采用加上权重的方法,这里之前的博客里面介绍了一点关于正则化的知识点,L1范式和L2范式.


更多的关于L2正则化的知识点详见博客逻辑回归
3.1 正则化
代码:
l2_model = keras.models.Sequential([
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation=tf.nn.relu, input_shape=(10000,)),
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
l2_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
l2_model_history = l2_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
结果:
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 3s - loss: 0.5350 - acc: 0.7930 - binary_crossentropy: 0.4948 - val_loss: 0.3815 - val_acc: 0.8759 - val_binary_crossentropy: 0.3382
Epoch 2/20
- 3s - loss: 0.3065 - acc: 0.9098 - binary_crossentropy: 0.2579 - val_loss: 0.3379 - val_acc: 0.8865 - val_binary_crossentropy: 0.2856
Epoch 3/20
- 3s - loss: 0.2574 - acc: 0.9288 - binary_crossentropy: 0.2025 - val_loss: 0.3405 - val_acc: 0.8854 - val_binary_crossentropy: 0.2837
Epoch 4/20
- 3s - loss: 0.2330 - acc: 0.9398 - binary_crossentropy: 0.1745 - val_loss: 0.3546 - val_acc: 0.8822 - val_binary_crossentropy: 0.2952
Epoch 5/20
- 3s - loss: 0.2208 - acc: 0.9449 - binary_crossentropy: 0.1598 - val_loss: 0.3659 - val_acc: 0.8796 - val_binary_crossentropy: 0.3040
Epoch 6/20
- 3s - loss: 0.2079 - acc: 0.9508 - binary_crossentropy: 0.1455 - val_loss: 0.3818 - val_acc: 0.8753 - val_binary_crossentropy: 0.3190
Epoch 7/20
- 3s - loss: 0.2011 - acc: 0.9530 - binary_crossentropy: 0.1373 - val_loss: 0.3948 - val_acc: 0.8732 - val_binary_crossentropy: 0.3303
Epoch 8/20
- 3s - loss: 0.1933 - acc: 0.9572 - binary_crossentropy: 0.1281 - val_loss: 0.4079 - val_acc: 0.8708 - val_binary_crossentropy: 0.3426
Epoch 9/20
- 3s - loss: 0.1877 - acc: 0.9577 - binary_crossentropy: 0.1220 - val_loss: 0.4265 - val_acc: 0.8696 - val_binary_crossentropy: 0.3602
Epoch 10/20
- 3s - loss: 0.1853 - acc: 0.9597 - binary_crossentropy: 0.1184 - val_loss: 0.4403 - val_acc: 0.8652 - val_binary_crossentropy: 0.3731
Epoch 11/20
- 3s - loss: 0.1804 - acc: 0.9614 - binary_crossentropy: 0.1127 - val_loss: 0.4525 - val_acc: 0.8646 - val_binary_crossentropy: 0.3843
Epoch 12/20
- 3s - loss: 0.1769 - acc: 0.9623 - binary_crossentropy: 0.1086 - val_loss: 0.4727 - val_acc: 0.8614 - val_binary_crossentropy: 0.4042
Epoch 13/20
- 3s - loss: 0.1753 - acc: 0.9636 - binary_crossentropy: 0.1060 - val_loss: 0.4768 - val_acc: 0.8626 - val_binary_crossentropy: 0.4073
Epoch 14/20
- 3s - loss: 0.1665 - acc: 0.9672 - binary_crossentropy: 0.0971 - val_loss: 0.4856 - val_acc: 0.8586 - val_binary_crossentropy: 0.4167
Epoch 15/20
- 3s - loss: 0.1607 - acc: 0.9701 - binary_crossentropy: 0.0919 - val_loss: 0.5003 - val_acc: 0.8600 - val_binary_crossentropy: 0.4314
Epoch 16/20
- 3s - loss: 0.1595 - acc: 0.9703 - binary_crossentropy: 0.0902 - val_loss: 0.5131 - val_acc: 0.8570 - val_binary_crossentropy: 0.4437
Epoch 17/20
- 3s - loss: 0.1573 - acc: 0.9704 - binary_crossentropy: 0.0878 - val_loss: 0.5246 - val_acc: 0.8560 - val_binary_crossentropy: 0.4548
Epoch 18/20
- 3s - loss: 0.1563 - acc: 0.9703 - binary_crossentropy: 0.0863 - val_loss: 0.5418 - val_acc: 0.8557 - val_binary_crossentropy: 0.4713
Epoch 19/20
- 3s - loss: 0.1544 - acc: 0.9716 - binary_crossentropy: 0.0838 - val_loss: 0.5507 - val_acc: 0.8575 - val_binary_crossentropy: 0.4798
Epoch 20/20
- 3s - loss: 0.1545 - acc: 0.9706 - binary_crossentropy: 0.0831 - val_loss: 0.5633 - val_acc: 0.8535 - val_binary_crossentropy: 0.4914代码:
plot_history([('baseline', baseline_history),
('l2', l2_model_history)])
结果:可以从下图看到交叉验证集和训练集的误差已经缩小了,所以L2是可以防止过拟合现象的.
3.2 dropout
怎么理解呢,就是丢弃某些值,比如当前的层的输出结果是[1.2,3,1,5],但是经过dropout之后,我可能变成了[0,3,0,5],丢弃了其中的一部分的值.丢弃率是表示多少部分被设置成了0,经常被设置在0.2-0.5之间.但是注意在测试集上是不进行丢弃步骤的,这一点很重要.
tf.keras中可以通过增加一个drpout层来完成.
代码:
dpt_model = keras.models.Sequential([
keras.layers.Dense(16, activation=tf.nn.relu, input_shape=(10000,)),
keras.layers.Dropout(0.5),
keras.layers.Dense(16, activation=tf.nn.relu),
keras.layers.Dropout(0.5),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
dpt_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
dpt_model_history = dpt_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
结果:
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 3s - loss: 0.6018 - acc: 0.6622 - binary_crossentropy: 0.6018 - val_loss: 0.4610 - val_acc: 0.8504 - val_binary_crossentropy: 0.4610
Epoch 2/20
- 3s - loss: 0.4479 - acc: 0.8009 - binary_crossentropy: 0.4479 - val_loss: 0.3292 - val_acc: 0.8827 - val_binary_crossentropy: 0.3292
Epoch 3/20
- 3s - loss: 0.3560 - acc: 0.8566 - binary_crossentropy: 0.3560 - val_loss: 0.2883 - val_acc: 0.8881 - val_binary_crossentropy: 0.2883
Epoch 4/20
- 3s - loss: 0.2964 - acc: 0.8896 - binary_crossentropy: 0.2964 - val_loss: 0.2763 - val_acc: 0.8879 - val_binary_crossentropy: 0.2763
Epoch 5/20
- 3s - loss: 0.2570 - acc: 0.9084 - binary_crossentropy: 0.2570 - val_loss: 0.2769 - val_acc: 0.8878 - val_binary_crossentropy: 0.2769
Epoch 6/20
- 3s - loss: 0.2210 - acc: 0.9227 - binary_crossentropy: 0.2210 - val_loss: 0.2834 - val_acc: 0.8855 - val_binary_crossentropy: 0.2834
Epoch 7/20
- 3s - loss: 0.1917 - acc: 0.9341 - binary_crossentropy: 0.1917 - val_loss: 0.3031 - val_acc: 0.8828 - val_binary_crossentropy: 0.3031
Epoch 8/20
- 3s - loss: 0.1667 - acc: 0.9441 - binary_crossentropy: 0.1667 - val_loss: 0.3225 - val_acc: 0.8824 - val_binary_crossentropy: 0.3225
Epoch 9/20
- 3s - loss: 0.1506 - acc: 0.9482 - binary_crossentropy: 0.1506 - val_loss: 0.3467 - val_acc: 0.8818 - val_binary_crossentropy: 0.3467
Epoch 10/20
- 3s - loss: 0.1359 - acc: 0.9556 - binary_crossentropy: 0.1359 - val_loss: 0.3641 - val_acc: 0.8807 - val_binary_crossentropy: 0.3641
Epoch 11/20
- 3s - loss: 0.1241 - acc: 0.9600 - binary_crossentropy: 0.1241 - val_loss: 0.3722 - val_acc: 0.8786 - val_binary_crossentropy: 0.3722
Epoch 12/20
- 3s - loss: 0.1122 - acc: 0.9637 - binary_crossentropy: 0.1122 - val_loss: 0.4168 - val_acc: 0.8774 - val_binary_crossentropy: 0.4168
Epoch 13/20
- 3s - loss: 0.0999 - acc: 0.9679 - binary_crossentropy: 0.0999 - val_loss: 0.4307 - val_acc: 0.8775 - val_binary_crossentropy: 0.4307
Epoch 14/20
- 3s - loss: 0.0945 - acc: 0.9694 - binary_crossentropy: 0.0945 - val_loss: 0.4617 - val_acc: 0.8756 - val_binary_crossentropy: 0.4617
Epoch 15/20
- 3s - loss: 0.0836 - acc: 0.9732 - binary_crossentropy: 0.0836 - val_loss: 0.4721 - val_acc: 0.8759 - val_binary_crossentropy: 0.4721
Epoch 16/20
- 3s - loss: 0.0796 - acc: 0.9740 - binary_crossentropy: 0.0796 - val_loss: 0.5044 - val_acc: 0.8748 - val_binary_crossentropy: 0.5044
Epoch 17/20
- 3s - loss: 0.0744 - acc: 0.9757 - binary_crossentropy: 0.0744 - val_loss: 0.5055 - val_acc: 0.8746 - val_binary_crossentropy: 0.5055
Epoch 18/20
- 3s - loss: 0.0698 - acc: 0.9776 - binary_crossentropy: 0.0698 - val_loss: 0.5496 - val_acc: 0.8753 - val_binary_crossentropy: 0.5496
Epoch 19/20
- 3s - loss: 0.0668 - acc: 0.9774 - binary_crossentropy: 0.0668 - val_loss: 0.5589 - val_acc: 0.8740 - val_binary_crossentropy: 0.5589
Epoch 20/20
- 3s - loss: 0.0637 - acc: 0.9795 - binary_crossentropy: 0.0637 - val_loss: 0.5666 - val_acc: 0.8733 - val_binary_crossentropy: 0.5666代码:
plot_history([('baseline', baseline_history),
('dropout', dpt_model_history)])
结果展示:














 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









