







重要说明:本文从网上资料整理而来,仅记录博主学习相关知识点的过程,侵删。
一、参考资料
深度学习之图像分割—— SegNet基本思想和网络结构以及论文补充
二、相关介绍
1. 上采样(Upsampling)
关于上采样的详细介绍,请参考另一篇博客:Upsampling上采样相关技术
3. 转置卷积(Transposed Convolution)
关于转置卷积的详细介绍,请参考另一篇博客:深入浅出理解转置卷积Conv2DTranspose
三、SegNet网络模型
1. SegNet的创新点
SegNet与U-net网络相似,主要的区别是提出了最大池化索引,通过记录池化的位置,在上采样时恢复特征信息。具体来说,SegNet在进行池化操作时,记录池化所取值的位置,在上采样时直接用当时记录的位置进行反池化(UpPool),这样做的作用是更好的保留边界特征信息。
2. 池化索引(pooling indices)
2.1 最大池化(Max-Pooling)
Pooling 在CNN中是使得图片缩小一半的手段,通常有Max-Pooling与Average-Pooling两种 Pooling 方式,下图所示的是Max-Pooling。Max-Pooling 是使用一个2x2的filter,取出这4个权重最大的一个,原图大小为4x4,Pooling 之后大小为2x2,原图左上角粉色的四个数,最后只剩最大的6,这就是max的意思。

2.2 池化索引的原理
SegNet是如何记录池化位置的呢?答案就是通过池化索引(pooling indices)。
在SegNet中的 Pooling 与传统 Pooling 多了一个index功能,也就是每次 Pooling,都会保存通过max选出的权值在2x2 filter中的相对位置,对上图的6来说,6在粉色2x2 filter中的位置为(1, 1)(index从0开始),黄色的3的index为(0, 0)。同时,从网络框架图可以看到绿色的 pooling 与红色的 upsampling 通过 pool indices 相连,实际上是 pooling 后的indices输出到对应的 upsampling(由于网络结构是对称的,因此第1次的 pooling 对应最后1次的 upsamping,如此类推)。
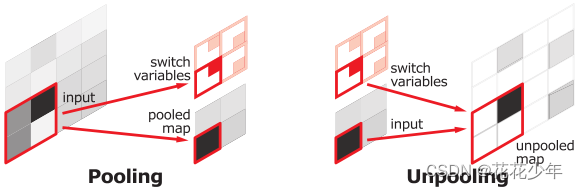
Upsamping 就是 Pooling 的逆过程,index在 Upsampling 过程中发挥作用,Upsamping使得图片尺寸变大2倍。我们清楚的知道 Pooling 之后,每个filter会丢失了3个权重,这些权重是无法复原的,但是在 Upsamping 层中可以得到在 Pooling 中相对 Pooling filter 的位置。所以Upsampling 中先对输入的特征图放大两倍,然后把输入特征图的数据根据 Pooling indices 放入,如下图所示,Unpooling 对应上述的 Upsampling,switch variables 对应 Pooling indices。
2.3 SegNet与FCN对比
对比FCN可以发现,SegNet在 Unpooling 时用index信息,直接将数据放回对应位置,后面再接Conv训练学习。这个上采样不需要训练学习(只是占用了一些存储空间)。而FCN利用转置卷积(Transposed Convolution)对 feature map 进行 upsampling,这一过程需要学习,同时将encoder阶段对应的 feature map 做通道降维,使得通道维度和 upsampling 相同,这样就能做像素相加(Add),得到最终的decoder输出。

3. SegNet网络结构
SegNet是基于Encoder-Decoder的网络结构,Encoder的backbone采用VGG-16(去除FC层)。SegNet网络结构,如下图所示:

在Encoder过程中,通过卷积提取特征,SegNet使用 padding=same 的卷积,即执行卷积操作后保持图像原始尺寸;在Decoder过程中,同样使用使用 padding=same 的卷积对缩小后的特征图进行上采样,不过卷积的作用是为了丰富上采样的图像信息,使得在Encoder的Pooling过程丢失的信息可以通过学习通过Decoder得到。然后对上采样后的图像进行卷积处理,来完善图像中物体的几何形状,将encoder中获得的特征还原到原来图像的具体的像素点上。最后利用 soft-max 多分类器对Decoder输出的特征图进行逐像素分类(pixel-wise classification)。
4. SegNet性能对比

从上面表格中可以看出:
- SegNet比FCN和DeepLabv1慢,因为SegNet包含解码器架构。它比DeconvNet更快,因为它没有全连接层。
- SegNet在训练和测试期间的内存要求都很低。并且模型尺寸比FCN和DeconvNet小得多。
四、相关经验
(TensorFlow)代码实现
github代码:Tensorflow-SegNet
















 4060
4060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











