- 博客(41)
- 收藏
- 关注
 RSS订阅
RSS订阅原创 03雷达的有源干扰分类
它对雷达产生干扰的机理是:当连续的高速调频信号扫过接收机的窄通带时,在接收机的输出端便形成一个冲击脉冲。噪声调频信号的带宽与调制信号的幅度成正比,因此,改变调频噪声的幅度即可改变噪声调频信号的带宽,以便灵活地产生窄带瞄频干扰(干扰带宽几到十几兆赫)、窄带阻塞干扰(干扰带宽几十兆赫)、宽带阻塞干扰(干扰带宽大于 100兆赫)。噪声干扰一般是连续干扰,为使噪声干扰压制有用信号,要求进入雷达接收机的干扰信号功率大于有用信号功率一定倍数,因此要求所辐射的干扰故耗费的功率较大信号在角度、频率、时间上与雷达信号一致。
2026-01-05 19:38:30
 950
950
 1
1
原创 01雷达信号分选
相比之下,基于深度学习的分选方法可结合雷达信号的调制特性,灵活选取并组合不同网络模块,深入挖掘信号的周期性特征及潜在规律,从而实现更高效、鲁棒的分选效果。预分选主要基于射频(RF)、脉宽(PW)、到达角(DOA)等多维特征,采用聚类算法对混杂脉冲流进行初步分离,以降低主分选阶段的计算复杂度。主分选则依托到达时间(TOA)这一一维特征,通常包括脉冲重复间隔(PRI)估计与脉冲序列搜索两个步骤,进一步实现对各雷达脉冲序列的精确分离,为后续的调制识别与功能分析提供支撑,完成脉冲的最终分选。
2026-01-04 19:01:26
400
原创 java蓝桥11-20题总结
看上图我们可以知道 当运算到第三十四行的时候,就已经出现了大于10亿的值,位置是第16位,所以我们可以求得,每一次运算最多运算16个数值(杨辉三角对称原因,只求一半)那第n行:arr【n】=arr【n】+arr【n-1】;arr【n-1】=arr【n-1】+arr【n-2】…那arr【2】初始状态为0,是不是就可以写成:arr【2】=arr【2】+arr【1】?第二行的第二列的1,是不是等于第一行的第二列的0+第一行第一列的1?那就是0+arr[1]对吧,也就是arr【2】=0+arr【1】;
2023-10-30 17:02:32
312
原创 java蓝桥杯前10题总结
1.取整百的思想:System.out.println((((int)sum + 100)/100*100));2.小数点后几位四舍五入,使用c思想 System.out.printf(“%.2f”,sum/n);在java中没有连等,所以无法使用a == b == c,只用使用a == b && b == c。//计算出来是负数,因为是大整数,使用L表示long类型。2.当前的数,一定是已经组装不了了,所以最后需要-1,才能满足题目要求。1.上方和左方多一行的思想!1.使用了个很大的数,作为循环条件。
2023-10-21 14:25:30
449
原创 算法-动态规划-java
备忘录法也是比较好理解的,创建了一个n+1大小的数组来保存求出的斐波拉契数列中的每一个值,在递归的时候如果发现前面fib(n)的值计算出来了就不再计算,如果未计算出来,则计算出来后保存在Memo数组中,下次在调用fib(n)的时候就不会重新递归了。比如上面的递归树中在计算fib(6)的时候先计算fib(5),调用fib(5)算出了fib(4)后,fib(6)再调用fib(4)就不会在递归fib(4)的子树了,因为fib(4)的值已经保存在Memo[4]中。上面的递归树中的每一个子节点都会执行一次,
2023-10-19 16:39:51
526
原创 深度学习之图像分割—— deeplabv3基本思想和网络结构以及论文补充
真正采用的膨胀系数应该是图中的rate乘上Multi-Grid参数,比如Block4中rate=2,Multi-Grid=(1, 2, 4)那么真正采用的膨胀系数是2 x (1, 2, 4)=(2, 4, 8)。首先回顾下上篇博文中讲的DeepLab V2中的ASPP结构,DeepLab V2中的ASPP结构其实就是通过四个并行的膨胀卷积层,每个分支上的膨胀卷积层所采用的膨胀系数不同(注意,这里的膨胀卷积层后没有跟BatchNorm并且使用了偏执Bias)。接着通过add相加的方式融合四个分支上的输出。
2023-02-20 10:36:15
2082
2
原创 【计算机视觉全套教程】笔记总结
1.感知上的本质区别2.视角变化3.光照变化4.尺度变化5.形态变化6.背景混淆干扰7.遮挡8.类内物体的外观差异张量:高维数组边缘提取除了横向和纵向(单向求导),最难的是斜边(两个方向上的求导)σ在高斯滤波中代表的是均值,它的大小决定着是瘦高还是扁平这里引进了梯度的概念二阶导数。
2023-02-19 14:23:48
1291
3
原创 深度学习之图像分割—— deeplabv2基本思想和网络结构以及论文补充
下图是原论文中介绍ASPP的示意图,就是在backbone输出的Feature Map上并联四个分支,每个分支的第一层都是使用的膨胀卷积,但不同的分支使用的膨胀系数不同(即每个分支的感受野不同,从而具有解决目标多尺度的问题)。下图有画出更加详细的ASPP结构(这里是针对VGG网络为例的),将Pool5输出的特征层(这里以VGG为例)并联4个分支,每个分支分别通过一个3x3的膨胀卷积层,1x1的卷积层,1x1的卷积层(卷积核的个数等于num_classes)。这是一篇2016年发布在CVPR上的文章。
2023-02-19 14:19:23
1335
原创 深度学习之图像分割—— SegNet基本思想和网络结构以及论文补充
也就是每次Pooling,都会保存通过max选出的权值在2x2 filter中的相对位置,对于上图的6来说,6在粉色2x2 filter中的位置为(1,1)(index从0开始),黄色的3的index为(0,0)。,即卷积后保持图像原始尺寸;在网络框架中,SegNet,最后一个卷积层会输出所有的类别(包括other类),网络最后加上一个softmax层,由于是end to end, 所以softmax需要求出所有每一个像素在所有类别最大的概率,最为该像素的label,最终完成图像像素级别的分类。
2023-02-18 14:44:05
9804
原创 深度学习之图像分割—— u2-net基本思想和网络结构以及论文补充
@[toc]## u2-net的引入针对的任务是SOD任务(显著性目标检测)### 1.什么是SOD任务==特点==:只有前景和背景### 2.网络结构#### 1.主要思想==*
2023-02-18 10:40:31
2554
原创 深度学习之图像分割—— u-net基本思想和网络结构以及论文补充
@[toc]## u-net的引入Unet 发表于 2015 年,属于 FCN 的一种变体。Unet 的初衷是为了解决生物医学图像的问题,由于效果确实很好后来也被广泛的应用在语义分割的各个方向,如卫星图像分割,工业瑕疵检测等。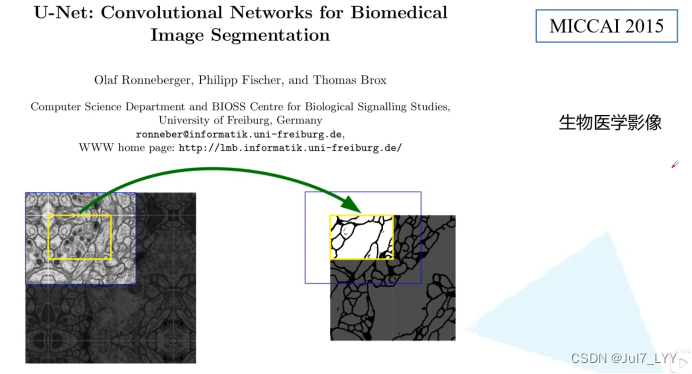### 1.主要思想Unet 跟 FCN 都是 Encoder-Decoder 结构,结构简单但很有效。1.Enco
2023-02-18 10:13:38
1768
原创 深度学习之图像分割(三)—— 空洞卷积/膨胀卷积(霹雳吧啦wz)
Gridding effect:没有用到范围内的所有像素值,而只使用到了一部分。非零元素中间有0元素(没有使用到的元素),因此一定会失去一部分信息。Mi就等于第i层两个非零元素之间的距离,ri就等于第i层的膨胀系数。我们的目标是M2≤K。根据三个膨胀系数,计算值是否合适。2.保持原输入特征图W、H(一般通过padding)
2023-02-17 20:40:46
3311
原创 深度学习之图像分割—— FCN基本思想和网络结构以及论文补充
FCN-32s通过一系列的卷积下采样得到特征层,特征层的channel为21,因为在当年使用的数据集还是PASCAL VOC(有20个类别,加上背景一共有21个类别)。再经过上采样得到一个和原图同样大小的一个特征图(channels=21),该特征图的每个pixel都有21个值,对这21个值进行softmax处理,得到该像素针对每一个类别的预测概率,取概率最大的类别作为该像素的预测类别。全连接层计算对应某个结点的输出,将该结点与上一层每个结点的权重与输入对应结点的数值进行相乘再求和,得到对应结点的输出。
2023-02-12 21:40:20
1834
4
原创 深度学习之图像分割(二)—— 转置卷积(霹雳吧啦wz)
1.上采样(填充,使输出结果大于输入结果,实现一个上采样)2.转置卷积不是卷积的逆运算3.转置卷积也是卷积。
2023-02-12 16:47:57
1213
原创 深度学习之图像分割(一)—— 前言(霹雳吧啦wz)
每一种不同的物体对应的都有一种颜色,例如人对应的就是粉红色使用调色板模式存储,图片是一通道,但是每个像素都对应一个颜色(0~255)像素0对应的是(0,0,0)黑色像素1对应的是(127,0,0)深红色像素255对应的是(224,224,129)目标边缘真实和预测面积的交集比上他们面积的并集。
2023-02-12 15:56:22
728
原创 【目标检测】yolov3基本思想和网络结构以及论文补充
模型在 ImageNet 数据集上进行推理,按照置信度排序总共生成 5 个标签。按照第一个标签预测计算正确率,即为 Top-1 正确率;前五个标签中只要有一个是正确的标签,则视为正确预测,称为 Top-5 正确率。
2023-02-10 14:17:51
830
原创 【目标检测】yolov2基本思想和网络结构以及论文补充
YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进。其中识别更多对象也就是扩展到能够检测9000种不同对象,称之为YOLO9000。相较于 YOLOv1 能达到的45 FPS以及63.4 mAP,YOLOv2 在 PASCAL VOC 数据集上达到了78.6的 mAP 以及 40FPS,其中输入为544×544。比较常用的还是 YOLOv2 416 × 416输入。
2023-02-09 19:59:02
1073
1
原创 【目标检测】RetinaNet基本思想和网络结构以及论文补充
roi是在原图中的感兴趣区域,可以理解为目标检测的候选框也就是region of proposals,我们将原图进行特征提取的时候,就会提取到相应的feature map。那么相应的ROI就会在feature map上有映射,这个映射过程就是roipooling的一部分,一般ROI的步骤会继续进行max pooling,进而得到我们需要的feature map,送入后面继续计算。
2023-02-08 17:56:38
683
1
原创 【目标检测】SSD基本思想和网络结构以及论文补充
由于使用全连接层提取特征,所以提取的是全图的特征,所以一张图像中只能包含一个目标,如果有多个目标,提取出来的特征就不准确,影响最后的预测。
2023-02-08 16:03:29
1473
原创 【目标检测】Faster RCNN基本思想和网络结构以及论文补充
Faster RCNN 是作者 Ross Girshick 继 RCNN 和 Fast RCNN后的又一力作。同样使用 VGG16作为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。在2015年的ILSVRC以及cOco竞赛中获得多个项目的第一名。anchor不是候选框(Proposal),后面会提到二者的区别。我们在特征图中找一个点,就可以在原图中找到对应的一个像素点,以该像素点为中心,画出9个不同大小和长宽比的框,称为anchor。
2023-01-17 15:58:39
908
原创 【目标检测】Fast RCNN基本思想和网络结构以及论文补充
Fast R-CNN是作者Ross Girshick继R-CNN后的又一力作。同样使用VGG16作为网络的backbone,与R-CNN相比训练时间快9倍,测试推理时间快213倍,准确率从62%提升至66%(再Pascal VOC数据集上)。这里与RCNN有明显的不同,RCNN是独立的四步,这里只有两步,所以大大加快了训练速度。
2023-01-17 11:15:53
689
原创 【目标检测】】RCNN基本思想和网络结构以及论文补充
R-CNN系列(R-CNN,fast-RCNN,faster-RCNN)是使用深度学习进行物体检测的鼻祖论文,其中fast-RCNN 以及faster-RCNN都是延续R-CNN的思路。R-CNN新提出了CNN卷积特征提取方法和微调。R-CNN全称region with CNN features,其实它的名字就是一个很好的解释。用CNN提取出Region Proposals中的featues,然后进行SVM分类与bbox的回归(定位置)。【RCNN网络结构】
2023-01-17 11:13:52
464
原创 1*1卷积层的作用,以及与全连接层的关系
1* 1 卷积的作用是让网络根据需要能够更灵活地控制数据的通道数(即实现不同通道之间的信息交互),通过1* 1卷积,可以将不同分支的feature map通道数调整到需要的大小,也可以升维。但是如果特征图大小不是1* 1,而是w* h的话,那么1* 1的卷积输出就不是一个值而是w* h的一个矩阵。(1* 1不需要输入map固定,但fc需要)全连接层的输入尺寸是固定的,因为全连接层的参数个数取决于图像大小,需要预先设定好,而卷积层的输入尺寸是任意的,因为卷积核的参数个数与图像大小无关。
2023-01-12 19:43:47
1797
原创 【机器学习】经典目标检测算法:RCNN、Fast RCNN、 Faster RCNN 基本思想和网络结构介绍
R-CNN系列(R-CNN,fast-RCNN,faster-RCNN)是使用深度学习进行物体检测的鼻祖论文,其中fast-RCNN 以及faster-RCNN都是延续R-CNN的思路。R-CNN全称region with CNN features,其实它的名字就是一个很好的解释。用CNN提取出Region Proposals中的featues,然后进行SVM分类与bbox的回归(定位置)。【RCNN网络结构】重要思想:(1)通过专门模板去生成候选框(RPN),寻找前景以及调整边界框(基于锚框)(2)
2022-12-04 22:02:20
7100
1
原创 【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记(目标检测、锚框)
1.锚框的作用对于目标检测任务,有这样一种经典解决方案:遍历输入图像上所有可能的像素框,然后选出正确的目标框,并对位置和大小进行调整就可以完成目标检测任务。这些进行预测的像素框就叫锚框。这些锚框通常都是方形的。同时,为了增加任务成功的几率,通常会在同一位置设置不同宽高比的锚框。2.特征图中的锚框如果按照上述方案不加改变的执行,即使是一张图片所产生的锚框将多到我们难以承受的地步。对于一个224x224的图片,假设每个位置设置3个不同尺寸的先验框,那么就有224x224x3=150528个锚框;
2022-12-01 22:45:37
1376
原创 【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记(微调)
1.微调通过使用在大数据上得到的预训练模型来初始化权重来提高精度2.预训练模型质量非常重要3.微调通常速度更快、精度更高。
2022-11-25 10:52:21
897
原创 【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记(图像增广)
1.图像增广基于现有的训练数据生成随机图像,来提高模型的范化能力。2.为了在预测过程中得到确切的结果,我们通常对训练样本只进行图像增广,而在预测过程中不使用随机操作的图像增广。(训练有,预测无)3.深度学习框架提供了许多不同的图像增广方法,这些方法可以被同时应用。(多种增强共同使用)1.翻转2.裁剪3.过滤和锐化4.模糊5.旋转,平移,剪切,缩放6.色彩7.亮度8.均匀和高斯噪声。
2022-11-24 21:11:59
340
原创 【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记Batch Normalization(批量归一化)
【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记(批量归一化)
2022-11-22 16:42:58
680
原创 【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记(googlenet)
【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记(googlenet)
2022-11-21 20:10:51
923
原创 【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记(VGG、NIN)
在很多代码中在预处理的阶段会在rgb上减去这三个值,这三个值分别对应这imgnet图像数据集的所有图片的rgb三个通道的均值。(1)NIN直接不要全连接层【使用1*1的卷积代替】(2)这里的全连接是对像素进行的全连接。全连接层会引起参数非常的多,参数多带来的问题【基本上所有的参数都在全连接层】(1)更多的全连接层【太贵】(2)更多的卷积层(3)讲卷积层组合成块。(1)占用很大内存(2)占用很大的带宽(3)很容易过拟合。全局池化层的含义是:池化层的高宽是等于输入的高宽的。(3)亮点:通过堆叠三个3。
2022-11-21 09:53:22
502
原创 【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记(Alexnet)
【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记(Alexnet)
2022-11-20 17:45:42
911
原创 【机器学习】《动手学深度学习 PyTorch版》李沐深度学习笔记(神经网络卷积池化)
(含有全连接层的网络输入数据的大小应该是固定的,这是因为全连接层和前面一层的连接的参数数量需要事先确定,不像卷积核的参数个数就是卷积核大小,前层的图像大小不管怎么变化,卷积核的参数数量也不会改变,但全连接的参数是随前层大小的变化而变的,如果输入图片大小不一样,那么全连接层之前的feature map也不一样,那全连接层的参数数量就不能确定, 所以必须实现固定输入图像的大小。6.计算输出的高度核宽度:输出的高度=输入的高度-核的高度+1 输出的宽度=输入的宽度-核的宽度+1。
2022-11-19 20:02:08
901
原创 【Google、edge通用】解决jupyter notebook打不开无反应 浏览器未启动的问题
6.在记事本按ctrl+F 输入"NotebookApp.browser",找到"# c.NotebookApp.browser = ‘’"这行代码。4.在开始菜单输入edge(google),找到edge(google)并右击,点击打开文件位置(下边以edge为例)7.保存并关闭记事本,在通过菜单打开时,就可以自动弹出jupyter notebook了。方法一:复制网址,即可直接打开。5.右键属性,复制目标内容位置。
2022-11-19 19:08:49
4817
3
![]()
空空如也
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人