







A triangle list is the simplest, and usually least efficient, way to store and display a set of triangles. The vertex data for each triangle is put in a list, one after another.Each triangle has its own separate set of three vertices, so there is no sharing of vertex data among triangles. A standard way to increase graphics performance is to send groups of triangles that share vertices through the graphics pipeline. Sharing means fewer calls to the vertex shader, so less points and normals need to be transformed.Here we describe a variety of data structures that share vertex information, starting with triangle fans and strips and progressing to more elaborate, and more efficient, forms for rendering surfaces.
三角形列表是存储和显示一组三角形的最简单、通常效率最低的方式。每个三角形的顶点数据一个接一个地放在一个列表中。每个三角形都有自己独立的三个顶点,因此三角形之间不共享顶点数据。提高图形性能的标准方法是通过图形管道发送共享顶点的三角形组。共享意味着对顶点着色器的调用更少,因此需要转换的点和法线更少。在这里,我们描述了共享顶点信息的各种数据结构,从三角形扇形和条带开始,发展到更精细、更有效的表面渲染形式。
16.4.1 Fans
三角形扇形
Figure 16.13 shows a triangle fan. This data structure shows how we can form triangles and have the storage cost be less than three vertices per triangle. The vertex shared by all triangles is called the center vertex and is vertex 0 in the figure. For the starting triangle 0, send vertices 0, 1, and 2 (in that order). For subsequent triangles, the center vertex is always used together with the previously sent vertex and the vertex currently being sent. Triangle 1 is formed by sending vertex 3, thereby creating a triangle defined by vertices 0 (always included), 2 (the previously sent vertex), and 3.Triangle 2 is constructed by sending vertex 4, and so on. Note that a general convex polygon is trivial to represent as a triangle fan, since any of its points can be used as the starting, center vertex.
图16.13显示了一个三角形扇形。这个数据结构展示了我们如何形成三角形,并使每个三角形的存储成本少于三个顶点。所有三角形共有的顶点称为中心顶点,在图中为顶点0。对于起始三角形0,发送顶点0、1和2(按此顺序)。对于后续的三角形,中心顶点总是与先前发送的顶点和当前正在发送的顶点一起使用。通过发送顶点3来形成三角形1,从而创建由顶点0(总是包含)、2(先前发送的顶点)和3定义的三角形。通过发送顶点4来构造三角形2,以此类推。请注意,一般的凸多边形很容易表示为一个三角形扇形,因为它的任何点都可以用作起始的中心顶点。
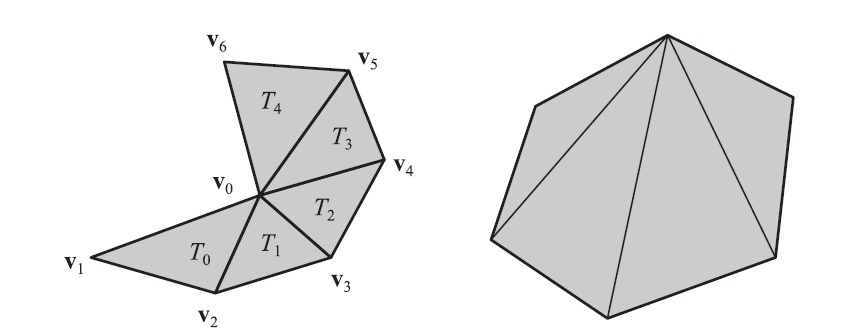
Figure 16.13. The left figure illustrates the concept of a triangle fan. Triangle T0 sends vertices v0 (the center vertex), v1, and v2. The subsequent triangles, Ti (i > 0), send only vertex vi+2. The right figure shows a convex polygon, which can always be turned into one triangle fan.
图16.13。左图说明了三角扇形的概念。三角形T0发送顶点v0(中心顶点)、v1和v2。后续的三角形Ti (i > 0)只发送顶点vi+2。右图是一个凸多边形,它总是可以变成一个三角形的扇形。
A triangle fan of n vertices is defined as an ordered vertex list
n个顶点的三角形扇形被定义为有序顶点列表
where v0 is the center vertex, with a structure imposed upon the list indicating that triangle i is
其中v0是中心顶点,强加在列表上的结构指示三角形i是

where 0 ≤ i < n − 2.
其中0 ≤ i < n − 2.
If a triangle fan consists of m triangles, then three vertices are sent for the first,followed by one more for each of the remaining m − 1 triangles. This means that the average number of vertices, va, sent for a sequential triangle fan of length m, can be expressed as
如果一个三角形扇形由m个三角形组成,则第一个三角形发送三个顶点,随后其余m-1个三角形各发送一个顶点。这意味着为长度为m的连续三角形扇形发送的顶点的平均数va可以表示为
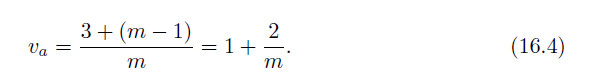
As can easily be seen, va → 1 as m → ∞. This might not seem to have much relevance for real-world cases, but consider a more reasonable value. If m = 5, then va = 1.4, which means that, on average, only 1.4 vertices are sent per triangle.
很容易看出,当m → ∞时,va → 1。这似乎与现实世界的情况没有太大关系,但是考虑一个更合理的值。如果m = 5,那么va = 1.4,这意味着平均来说,每个三角形只发送1.4个顶点。
16.4.2 Strips条带
Triangle strips are like triangle fans, in that vertices in previous triangles are reused.Instead of a single center point and the previous vertex getting reused, it is two vertices of the previous triangle that help form the next triangle. Consider Figure 16.14. If these triangles are treated as a strip, then a more compact way of sending them to the rendering pipeline is possible. For the first triangle (denoted T0), all three vertices (denoted v0, v1, and v2) are sent, in that order. For subsequent triangles in this strip,only one vertex has to be sent, since the other two have already been sent with the previous triangle. For example, sending triangle T1, only vertex v3 is sent, and the vertices v1 and v2 from triangle T0 are used to form triangle T1. For triangle T2, only vertex v4 is sent, and so on through the rest of the strip.
三角形带类似于三角形扇,因为先前三角形中的顶点被重用。不是单个中心点和前一个顶点被重用,而是前一个三角形的两个顶点帮助形成下一个三角形。考虑图16.14。如果这些三角形被视为一个条带,那么将它们发送到渲染管道的更紧凑的方式是可能的。对于第一个三角形(表示为T0),所有三个顶点(表示为v0、v1和v2)都按此顺序发送。对于该条带中的后续三角形,只需发送一个顶点,因为其他两个顶点已经与前一个三角形一起发送了。比如发送三角形T1,只发送顶点v3,用三角形T0的顶点v1和v2组成三角形T1。对于三角形T2,只发送顶点v4,其余部分依此类推。
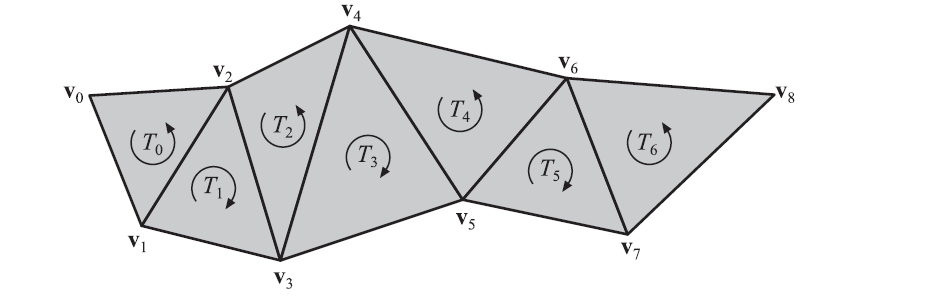
Figure 16.14. A sequence of triangles that can be represented as one triangle strip. Note that the orientation changes from triangle to triangle in the strip, and that the first triangle in the strip sets the orientation of all triangles. Internally, counterclockwise order is kept consistent by traversing vertices [0, 1, 2], [1, 3, 2], [2, 3, 4], [3, 5, 4], and so on.
图16.14。可以表示为一个三角形带的三角形序列。请注意,在条带中,方向会随着三角形的不同而变化,并且条带中的第一个三角形会设置所有三角形的方向。在内部,通过遍历顶点[0,1,2],[1,3,2],[2,3,4],[3,5,4]等,逆时针顺序保持一致。
A sequential triangle strip of n vertices is defined as an ordered vertex list,
n个顶点的连续三角形带被定义为有序顶点列表,

with a structure imposed upon it indicating that triangle i is
一个强加于其上的结构表明三角形i

where 0 ≤ i < n − 2. This sort of strip is called sequential because the vertices are sent in the given sequence. The definition implies that a sequential triangle strip of n vertices has n − 2 triangles.
其中0 ≤ i < n − 2。这种条带称为顺序条带,因为顶点是 按给定顺序发送。这个定义意味着n的连续三角形带 顶点有n − 2个三角形。
The analysis of the average number of vertices for a triangle strip of length m (i.e., consisting of m triangles), also denoted va, is the same as for triangle fans (see Equation 16.4), since they have the same start-up phase and then send only one vertex per new triangle. Similarly, when m → ∞, va for triangle strips naturally also tends toward one vertex per triangle. For m = 20, va = 1.1, which is much better than 3 and is close to the limit of 1.0. As with triangle fans, the start-up cost for the first triangle, always costing three vertices, is amortized over the subsequent triangles.
对长度为m的三角形带(即由m个三角形组成)的平均顶点数的分析(也表示为va)与对三角形扇的分析相同(见方程16.4),因为它们具有相同的启动阶段,然后每个新三角形只发送一个顶点。类似地,当m → ∞时,三角形条带的va自然也趋向于每个三角形一个顶点。对于m = 20,va = 1.1,比3好很多,接近1.0的极限。与三角形风扇一样,第一个三角形的启动成本总是花费三个顶点,在后续三角形中分摊。
The attractiveness of triangle strips stems from this fact. Depending on where the bottleneck is located in the rendering pipeline, there is a potential for saving up to two thirds of the time spent rendering with simple triangle lists. The speedup is due to avoiding redundant operations such as sending each vertex twice to the graphics hardware, then performing matrix transformations, clipping, and other operations on each. Triangle strips are useful for objects such as blades of grass or other objects where edge vertices are not reused by other strips. Because of its simplicity, strips are used by the geometry shader when multiple triangles are output.
三角条的吸引力源于这个事实。根据瓶颈在渲染管道中的位置,使用简单的三角形列表有可能节省多达三分之二的渲染时间。加速是由于避免了冗余操作,例如将每个顶点发送到图形硬件两次,然后对每个顶点执行矩阵变换、裁剪和其他操作。三角形带适用于诸如草叶或其他边顶点不被其他带重用的对象。由于其简单性,当输出多个三角形时,几何着色器使用条带。
There are several variants on triangles strips, such as not imposing a strict sequence on the triangles, or using doubled vertices or a restart index value so that multiple disconnected strips can be stored in a single buffer. There once was considerable research on how best to decompose an arbitrary mesh of triangles into strips [1076].Such efforts have died off, as the introduction of indexed triangle meshes allowed better vertex data reuse, leading to both faster display and usually less overall memory needed.
三角形条带有几种变体,例如不对三角形施加严格的顺序,或者使用双顶点或重新开始索引值,以便多个不连接的条带可以存储在单个缓冲区中。曾经有相当多的研究是关于如何最好地将任意三角形网格分解成条带[1076]。随着索引三角形网格的引入允许更好的顶点数据重用,导致更快的显示和通常更少的总内存需求,这种努力已经逐渐消失。
16.4.3 Triangle Meshes三角形网格
Triangle fans and strips still have their uses, but the norm on all modern GPUs is to use triangle meshes with a single index list (Section 16.3.1) for complex models [1135]. Strips and fans allow some data sharing, but mesh storage allows even more. In a mesh an additional index array keeps track of which vertices form the triangles. In this way, a single vertex can be associated with several triangles.
三角形扇面和条带仍然有其用途,但所有现代GPU上的规范是对复杂模型使用具有单一索引列表的三角形网格(第16.3.1节)[1135]。条带和风扇允许一些数据共享,但网状存储允许更多。在一个网格中,一个额外的索引数组跟踪哪些顶点形成了三角形。这样,一个顶点可以与几个三角形相关联。
The Euler-Poincar´e formula for connected planar graphs [135] helps in determining the average number of vertices that form a closed mesh:
平面连通图的欧拉-庞加莱公式[135]有助于确定 形成闭合网格的平均顶点数:

Here v is the number of vertices, e is the number of edges, f is the number of faces, and g is the genus. The genus is the number of holes in the object. As an example, a sphere has genus 0 and a torus has genus 1. Each face is assumed to have one loop. If faces can have multiple loops, the formula becomes
这里v是顶点数,e是边数,f是面数,g是亏格。亏格是物体上孔洞的数量。例如,球面亏格为0,环面亏格为1。假设每个面都有一个环。如果面可以有多个循环,则公式变为
![]()
where l is the number of loops.
其中l是循环次数。
For a closed (solid) model, every edge has two faces, and every face has at least three edges, so 2e ≥ 3f. If the mesh is all triangles, as the GPU demands, then 2e = 3f. Assuming a genus of 0 and substituting 1.5f for e in the formula yields f ≤ 2v − 4. If all faces are triangles, then f = 2v − 4.
对于封闭(实体)模型,每条边有两个面,每个面至少有三条边,所以2e ≥ 3f。如果网格都是三角形,就像GPU要求的那样,那么2e = 3f。假设亏格为0,用1.5f代替公式中的e,得到f ≤ 2v − 4。如果所有的面都是三角形,那么f = 2v − 4。
For large closed triangle meshes, the rule of thumb then is that the number of triangles is about equal to twice the number of vertices. Similarly, we find that each vertex is connected to an average of nearly six triangles (and, therefore, six edges).The number of edges connected to a vertex is called its valence. Note that the network of the mesh does not affect the result, only the number of triangles does. Since the average number of vertices per triangle in a strip approaches one, and the number of vertices is twice that of triangles, every vertex has to be sent twice (on average) if a large mesh is represented by triangle strips. At the limit, triangle meshes can send 0.5 vertices per triangle.
对于大型闭合三角形网格,经验法则是三角形的数量大约等于顶点数量的两倍。类似地,我们发现每个顶点平均连接近六个三角形(因此,有六条边)。连接到一个顶点的边数叫做它的价数。请注意,网格的网络不会影响结果,只有三角形的数量会影响结果。由于条带中每个三角形的平均顶点数接近1,并且顶点数是三角形的两倍,如果一个大网格由三角形条带表示,则每个顶点必须被发送两次(平均)。在极限情况下,三角形网格可以为每个三角形发送0.5个顶点。
Note that this analysis holds for only smooth, closed meshes. As soon as there are boundary edges (edges not shared between two polygons), the ratio of vertices to triangles increases. The Euler-Poincar´e formula still holds, but the outer boundary of the mesh has to be considered a separate (unused) face bordering all exterior edges.Similarly, each smoothing group in any model is effectively its own mesh, since GPUs need to have separate vertex records with differing normals along sharp edges where two groups meet. For example, the corner of a cube will have three normals at a single location, so three vertex records are stored. Changes in textures or other vertex data can also cause the number of distinct vertex records to increase.
请注意,此分析仅适用于平滑的闭合网格。只要有边界边(两个多边形之间不共享的边),顶点与三角形的比率就会增加。欧拉-庞加莱公式仍然适用,但网格的外部边界必须被视为一个单独的(未使用的)面,与所有外部边接壤。类似地,任何模型中的每个平滑组实际上都是它自己的网格,因为GPU需要有单独的顶点记录,沿着两个组相遇的锐边有不同的法线。例如,一个立方体的角在一个位置有三条法线,所以存储了三条顶点记录。纹理或其他顶点数据的变化也会导致不同顶点记录的数量增加。
Theory predicts we need to process about 0.5 vertices per triangle. In practice, vertices are transformed by the GPU and put in a first-in, first-out (FIFO) cache, or in something approximating a least recently used (LRU) system [858]. This cache holds post-transform results for each vertex run through the vertex shader. If an incoming vertex is located in this cache, then the cached post-transform results can be used without calling the vertex shader, providing a significant performance increase. If instead the triangles in a triangle mesh are sent down in random order, the cache is unlikely to be useful. Triangle strip algorithms optimize for a cache size of two, i.e.,the last two vertices used. Deering and Nelson [340] first explored the idea of storing vertex data in a larger FIFO cache by using an algorithm to determine in which order to add the vertices to the cache.
理论预测我们需要处理每个三角形大约0.5个顶点。在实践中,顶点由GPU转换,并放入先进先出(FIFO)缓存,或类似最近最少使用(LRU)系统[858]。该缓存保存通过顶点着色器运行的每个顶点的变换后结果。如果传入顶点位于该缓存中,则可以使用缓存的变换后结果,而无需调用顶点着色器,从而显著提高性能。相反,如果三角形网格中的三角形是以随机顺序向下发送的,缓存就不太可能有用。三角形条带算法针对大小为2的缓存进行优化,即使用最后两个顶点。迪林和尼尔森[340]首先探索了将顶点数据存储在更大的FIFO缓存中的想法,方法是使用一种算法来确定将顶点添加到缓存的顺序。
FIFO caches are limited in size. For example, the PLAYSTATION 3 system holds about 24 vertices, depending on the number of bytes per vertex. Newer GPUs have not increased this cache significantly, with 32 vertices being a typical maximum.
FIFO缓存的大小是有限的。例如,PLAYSTATION 3系统拥有大约24个顶点,这取决于每个顶点的字节数。较新的GPU没有显著增加这种缓存,32个顶点是典型的最大值。
Hoppe [771] introduces an important measurement of cache reuse, the average cache miss ratio (ACMR). This is the average number of vertices that need to be processed per triangle. It can range from 3 (every vertex for every triangle has to be reprocessed each time) to 0.5 (perfect reuse on a large closed mesh; no vertex is reprocessed). If the cache size is as large as the mesh itself, the ACMR is identical to the theoretical vertex to triangle ratio. For a given cache size and mesh ordering, the ACMR can be computed precisely, so describing the efficiency of any given approach for that cache size.
Hoppe [771]引入了缓存重用的一个重要衡量指标,即平均缓存未命中率(ACMR)。这是每个三角形需要处理的平均顶点数。它的范围可以从3(每个三角形的每个顶点每次都必须重新处理)到0.5(在一个大的闭合网格上完美地重新使用;没有顶点被重新处理)。如果缓存大小与网格本身一样大,则ACMR等于理论上的顶点与三角形之比。对于给定的高速缓存大小和网格排序,可以精确计算ACMR,从而描述对于该高速缓存大小的任何给定方法的效率。
16.4.4 Cache-Oblivious Mesh Layouts16.4.4缓存无关网格布局
The ideal order for triangles in an mesh is one in which we maximize the use of the vertex cache. Hoppe [771] presents an algorithm that minimizes the ACMR for a mesh,but the cache size has to be known in advance. If the assumed cache size is larger than the actual cache size, the resulting mesh can have significantly less benefit. Solving for different-sized caches may yield different optimal orderings. For when the target cache size is unknown, cache-oblivious mesh layout algorithms have been developed that yield orderings that work well, regardless of size. Such an ordering is sometimes called a universal index sequence.
网格中三角形的理想顺序是我们最大限度地利用顶点缓存。Hoppe [771]提出了一种最小化网格ACMR的算法,但是必须预先知道缓存大小。如果假设的缓存大小大于实际的缓存大小,则结果网格的优势会明显减少。求解不同大小的缓存可能会产生不同的最佳排序。当目标高速缓存大小未知时,已经开发了高速缓存无关的网格布局算法,该算法产生工作良好的排序,而不管大小如何。这种排序有时被称为通用索引序列。
Forsyth [485] and Lin and Yu [1047] provide rapid greedy algorithms that use similar principles. Vertices are given scores based on their positions in the cache and by the number of unprocessed triangles attached to them. The triangle with the highest combined vertex score is processed next. By scoring the three most recently used vertices a little lower, the algorithm avoids simply making triangle strips and instead creates patterns similar to a Hilbert curve. By giving higher scores to vertices with fewer triangles still attached, the algorithm tends to avoid leaving isolated triangles behind. The average cache miss ratios achieved are comparable to those of more costly and complex algorithms. Lin and Yu’s method is a little more complex but uses related ideas. For a cache size of 12, the average ACMR for a set of 30 unoptimized models was 1.522; after optimization, the average dropped to 0.664 or lower, depending on cache size.
Forsyth [485]和Lin和Yu [1047]提供了使用类似原理的快速贪婪算法。根据顶点在缓存中的位置以及附加到顶点的未处理三角形的数量给顶点打分。接下来处理具有最高组合顶点分数的三角形。通过将最近使用的三个顶点的得分稍微降低,该算法避免了简单地制作三角形条带,而是创建了类似于希尔伯特曲线的图案。通过给仍然附着较少三角形的顶点更高的分数,该算法倾向于避免留下孤立的三角形。达到的平均高速缓存未命中比率可与更昂贵和复杂的算法相比。林和余的方法稍微复杂一点,但是使用了相关的思想。对于12的缓存大小,一组30个未优化模型的平均ACMR是1.522;优化后,平均值降至0.664或更低,具体取决于缓存大小。
Sander et al. [1544] give an overview of previous work and present their own faster (though not cache-size oblivious) method, called Tipsify. One addition is that they also strive to put the outermost triangles early on in the list, to minimize overdraw (Section 18.4.5). For example, imagine a coffee cup. By rendering the triangles forming the outside of the cup first, the later triangles inside are likely to be hidden from view.
Sander等人[1544]给出了先前工作的概述,并提出了他们自己的更快(虽然不是高速缓存大小无关紧要)的方法,称为Tipsify。另外,他们还努力将最外面的三角形放在列表的最前面,以最小化过度绘制(18.4.5节)。例如,想象一个咖啡杯。通过首先渲染形成杯子外部的三角形,后面的内部三角形可能会隐藏起来。
Storsj¨o [1708] contrasts and compares Forsyth’s and Sander’s methods, and provides implementations of both. He concludes that these methods provide layouts that are near the theoretical limits. A newer study by Kapoulkine [858] compares four cache-aware vertex-ordering algorithms on three hardware vendors’ GPUs. Among his conclusions are that Intel uses a 128-entry FIFO, with each vertex using three or more entries, and that AMD’s and NVIDIA’s systems approximate a 16-entry LRU cache. This architectural difference significantly affects algorithm behavior. He finds that Tipsify [1544] and, to a lesser extent, Forsyth’s algorithm [485] perform relatively well across these platforms.
Storsj o [1708]对比和比较了Forsyth和Sander的方法,并提供了两者的实现。他的结论是,这些方法提供的布局接近理论极限。Kapoulkine的最新研究[858]在三家硬件供应商的GPU上比较了四种缓存感知顶点排序算法。他的结论包括,英特尔使用128个条目的FIFO,每个顶点使用三个或更多条目,AMD和NVIDIA的系统接近16个条目的LRU缓存。这种架构上的差异会显著影响算法行为。他发现Tipsify [1544]和Forsyth的算法[485]在这些平台上表现相对较好。
To conclude, offline preprocessing of triangle meshes can noticeably improve vertex cache performance, and the overall frame rate when this vertex stage is the bottleneck. It is fast, effectively O(n) in practice. There are several open-source versions available [485]. Given that such algorithms can be applied automatically to a mesh and that such optimization has no additional storage cost and does not affect other tools in the toolchain, these methods are often a part of a mature development system.Forsyth’s algorithm appears to be part of the PLAYSTATION mesh processing toolchain, for example. While the vertex post-transform cache has evolved due to modern GPUs’ adoption of a unified shader architecture, avoiding cache misses is still an important concern [530].
总之,三角形网格的离线预处理可以显著提高顶点缓存性能,以及当顶点阶段成为瓶颈时的整体帧速率。在实践中,它是快速、有效的O(n)。有几个开源版本可用[485]。假设这种算法可以自动应用于网格,并且这种优化没有额外的存储成本,并且不影响工具链中的其他工具,则这些方法通常是成熟开发系统的一部分。例如,Forsyth的算法似乎是PLAYSTATION网格处理工具链的一部分。尽管由于现代GPU采用了统一的着色器架构,顶点后转换缓存已经得到了发展,但避免缓存缺失仍然是一个重要的问题[530]。
16.4.5 Vertex and Index Buffers/Arrays顶点和索引缓冲器/阵列
One way to provide a modern graphics accelerator with model data is by using what DirectX calls vertex buffers and OpenGL calls vertex buffer objects (VBOs). We will go with the DirectX terminology in this section. The concepts presented have OpenGL equivalents.
向现代图形加速器提供模型数据的一种方法是使用DirectX所称的顶点缓冲区和OpenGL所称的顶点缓冲对象(VBOs)。在本节中,我们将使用DirectX术语。提出的概念有OpenGL的等价物。
The idea of a vertex buffer is to store model data in a contiguous chunk of memory. A vertex buffer is an array of vertex data in a particular format. The format specifies whether a vertex contains a normal, texture coordinates, a color, or other specific information. Each vertex has its data in a group, one vertex after another. The size in bytes of a vertex is called its stride. This type of storage is called an interleaved buffer. Alternately, a set of vertex streams can be used. For example, one stream could hold an array of positions {p0p1p2 . . .} and another a separate array of normals {n0n1n2 . . .}.In practice, a single buffer containing all data for each vertex is generally more efficient on GPUs, but not so much that multiple streams should be avoided [66, 1494]. The main cost of multiple streams is additional API calls, possibly worth avoiding if the application is CPU-bound but otherwise not significant [443].
顶点缓冲区的概念是将模型数据存储在一个连续的内存块中。顶点缓冲区是特定格式的顶点数据数组。该格式指定顶点是否包含法线、纹理坐标、颜色或其他特定信息。每个顶点都有一组数据,一个接一个。一个顶点的字节数称为它的步幅。这种类型的存储器被称为交叉存取缓冲器。或者,可以使用一组顶点流。例如,一个流可以保存一个位置数组{p0p1p2。。。}和另一个单独的法线数组{n0n1n2。。。}.在实践中,包含每个顶点的所有数据的单个缓冲区通常在GPU上更有效,但也不至于多到应该避免多个流[66,1494]。多流的主要成本是额外的API调用,如果应用程序是CPU受限的,但在其他方面并不重要,则可能值得避免[443]。
Wihlidal [1884] discusses different ways multiple streams can help rendering system performance, including API, caching, and CPU processing advantages. For example,SSE and AVX for vector processing on the CPU are easier to apply to a separate stream. Another reason to use multiple streams is for more efficient mesh updating.If, say, just the vertex location stream is changing over time, it is less costly to update this one attribute buffer than to form and send an entire interleaved stream [1609].
wih lidar[1884]讨论了多个流帮助渲染系统性能的不同方式,包括API、缓存和CPU处理优势。例如,在CPU上进行矢量处理的SSE和AVX更容易应用于单独的流。使用多个流的另一个原因是为了更有效的网格更新。如果,比方说,只有顶点位置流随时间变化,则更新这一个属性缓冲器比形成并发送整个交织流成本更低[1609]。
How the vertex buffer is accessed is up to the device’s DrawPrimitive method.The data can be treated as:
如何访问顶点缓冲区取决于设备的DrawPrimitive方法。 这些数据可以被视为:
1. A list of individual points.
2. A list of unconnected line segments, i.e., pairs of vertices.
3. A single polyline.
4. A triangle list, where each group of three vertices forms a triangle, e.g., vertices [0, 1, 2] form one, [3, 4, 5] form the next, and so on.
5. A triangle fan, where the first vertex forms a triangle with each successive pair of vertices, e.g., [0, 1, 2], [0, 2, 3], [0, 3, 4].
6. A triangle strip, where every group of three contiguous vertices forms a triangle,e.g., [0, 1, 2], [1, 2, 3], [2, 3, 4].
1.单个点的列表。
2.不相连线段的列表,即成对的顶点。
3.一条折线。
4.三角形列表,其中每组三个顶点形成一个三角形,例如,顶点[0,1,2]形成一个,顶点[3,4,5]形成下一个,依此类推。
5.三角形扇形,其中第一个顶点与每对连续的顶点形成一个三角形,例如[0,1,2],[0,2,3],[0,3,4]。
6.一种三角形带,其中每组三个相邻的顶点构成一个三角形,例如[0,1,2],[1,2,3],[2,3,4]。
In DirectX 10 on, triangles and triangle strips can also include adjacent triangle vertices,for use by the geometry shader (Section 3.7).
在DirectX 10上,三角形和三角形条带还可以包括相邻的三角形顶点,供几何着色器使用(第3.7节)。
The vertex buffer can be used as is or referenced by an index buffer. The indices in an index buffer hold the locations of vertices in a vertex buffer. Indices are stored as 16-bit unsigned integers, or 32-bit if the mesh is large and the GPU and API support it (Section 16.6). The combination of an index buffer and vertex buffer is used to display the same types of draw primitives as a “raw” vertex buffer. The difference is that each vertex in the index/vertex buffer combination needs to be stored only once in its vertex buffer, versus repetition that can occur in a vertex buffer without indexing.
顶点缓冲区可以按原样使用,也可以被索引缓冲区引用。索引缓冲区中的索引保存顶点缓冲区中顶点的位置。索引存储为16位无符号整数,如果网格很大并且GPU和API支持,则存储为32位(第16.6节)。索引缓冲区和顶点缓冲区的组合用于显示与“原始”顶点缓冲区相同类型的绘制图元。区别在于索引/顶点缓冲区组合中的每个顶点只需要在其顶点缓冲区中存储一次,而不是在没有索引的顶点缓冲区中重复存储。
The triangle mesh structure is represented by an index buffer. The first three indices stored in the index buffer specify the first triangle, the next three the second, and so on. This arrangement is called an indexed triangle list, where the indices themselves form a list of triangles. OpenGL binds the index buffer and vertex buffer(s) together with vertex format information in a vertex array object (VAO). Indices can also be arranged in triangle strip order, which saves on index buffer space. This format, the indexed triangle strip, is rarely used in practice, in that creating such sets of strips for a large mesh takes some effort, and all tools that process geometry also then need to support this format. See Figure 16.15 for examples of vertex and index buffer structures.
三角形网格结构由索引缓冲区表示。存储在索引缓冲区中的前三个索引指定第一个三角形,接下来的三个指定第二个三角形,依此类推。这种排列称为索引三角形列表,其中索引本身形成一个三角形列表。OpenGL将索引缓冲区和顶点缓冲区以及顶点格式信息绑定在一个顶点数组对象(VAO)中。索引也可以按三角形条带顺序排列,这样可以节省索引缓冲区空间。这种格式,索引三角形条带,很少在实践中使用,因为为大型网格创建这样的条带集需要一些努力,并且所有处理几何图形的工具也需要支持这种格式。见图16.15的顶点和索引缓冲结构的例子。
Which structure to use is dictated by the primitives and the program. Displaying a simple rectangle is easily done with just a vertex buffer using four vertices as a twotriangle tristrip or fan. One advantage of the index buffer is data sharing, as discussed earlier. Another advantage is simplicity, in that triangles can be in any order and configuration, not having the lock-step requirements of triangle strips. Lastly, the amount of data that needs to be transferred and stored on the GPU is usually smaller when an index buffer is used. The small overhead of including an indexed array is far outweighed by the memory savings achieved by sharing vertices.
使用哪种结构由原语和程序决定。显示一个简单的矩形很容易做到,只需要一个顶点缓冲区,使用四个顶点作为两个三角形的三等分线或扇形线。如前所述,索引缓冲区的一个优点是数据共享。另一个优点是简单,因为三角形可以是任何顺序和配置,没有三角形带的锁步要求。最后,当使用索引缓冲区时,需要在GPU上传输和存储的数据量通常较小。共享顶点所节省的内存远远超过了包含索引数组的小开销。
An index buffer and one or more vertex buffers provide a way of describing a polygonal mesh. However, the data are typically stored with the goal of GPU rendering efficiency, not necessarily the most compact storage. For example, one way to store a cube is to save its eight corner locations in one array, and its six different normals in another, along with the six four-index loops that define its faces. Each vertex location is then described by two indices, one for the vertex list and one for the normal list.Texture coordinates are represented by yet another array and a third index. This compact representation is used in many model file formats, such as Wavefront OBJ.On the GPU, only one index buffer is available. A single vertex buffer would store 24 different vertices, as each corner location has three separate normals, one for each neighboring face. The index buffer would store indices defining the 12 triangles forming the surface. Masserann [1135] discusses efficiently turning such file descriptions into compact and efficient index/vertex buffers, versus lists of unindexed triangles that do not share vertices. More compact schemes are possible by such methods as storing the mesh in texture maps or buffer textures and using the vertex shader’s texture fetch or pulling mechanisms, but they come at the performance penalty of not being able to use the post-transform vertex cache [223, 1457].
索引缓冲区和一个或多个顶点缓冲区提供了一种描述多边形网格的方法。然而,数据的存储通常以GPU渲染效率为目标,不一定是最紧凑的存储。例如,存储立方体的一种方法是在一个数组中保存它的八个角位置,在另一个数组中保存它的六个不同的法线,以及定义它的面的六个四索引循环。每个顶点位置由两个索引描述,一个用于顶点列表,一个用于法线列表。纹理坐标由另一个数组和第三个索引来表示。这种紧凑表示用于许多模型文件格式,如波前OBJ。在GPU上,只有一个索引缓冲区可用。单个顶点缓冲区将存储24个不同的顶点,因为每个角位置有三个单独的法线,每个相邻面一个。索引缓冲器将存储定义形成表面的12个三角形的索引。Masserann [1135]讨论了相对于不共享顶点的未索引三角形的列表,有效地将这样的文件描述转变成紧凑和有效的索引/顶点缓冲区。通过将网格存储在纹理图或缓冲纹理中,以及使用顶点着色器的纹理获取或拉取机制等方法,可以实现更紧凑的方案,但它们会带来无法使用变换后顶点缓存的性能损失[223,1457]。
For maximum efficiency, the order of the vertices in the vertex buffer should match the order in which they are accessed by the index buffer. That is, the first three vertices referenced by the first triangle in the index buffer should be first three in the vertex buffer. When a new vertex is encountered in the index buffer, it should then be next in the vertex buffer. Giving this order minimizes cache misses in the pre-transform vertex cache, which is separate from the post-transform cache discussed in Section 16.4.4. Reordering the data in the vertex buffer is a simple operation,but can be as important to performance as finding an efficient triangle order for the post-transform vertex cache [485].
为了获得最高效率,顶点缓冲区中顶点的顺序应该与索引缓冲区访问它们的顺序相匹配。也就是说,索引缓冲区中第一个三角形引用的前三个顶点应该是顶点缓冲区中的前三个。当在索引缓冲区中遇到新的顶点时,它应该是顶点缓冲区中的下一个。给出这种顺序可以最大限度地减少变换前顶点缓存中的缓存缺失,变换前顶点缓存独立于16.4.4节中讨论的变换后缓存。对顶点缓存中的数据进行重新排序是一个简单的操作,但对于性能来说,它与为后变换顶点缓存找到一个有效的三角形顺序一样重要[485]。

Figure 16.15. Different ways of defining primitives, in rough order of most to least memory use from top to bottom: separate triangles, as a vertex triangle list, as triangle strips of two or one data streams, and as an index buffer listing separate triangles or in triangle strip order.
图16.15。定义图元的不同方式,按照从上到下从最大到最小的内存使用的粗略顺序:单独的三角形,作为顶点三角形列表,作为两个或一个数据流的三角形带,以及作为列出单独三角形或按三角形带顺序的索引缓冲区。
There are higher-level methods for allocating and using vertex and index buffers to achieve greater efficiency. For example, a buffer that does not change can be stored on the GPU for use each frame, and multiple instances and variations of an object can be generated from the same buffer. Section 18.4.2 discusses such techniques in depth.
有更高级别的方法来分配和使用顶点和索引缓冲区,以实现更高的效率。例如,可以在GPU上存储不变的缓冲区以供每帧使用,并且可以从同一个缓冲区生成对象的多个实例和变体。18.4.2节深入讨论了这些技术。
The ability to send processed vertices to a new buffer using the pipeline’s stream output functionality (Section 3.7.1) allows a way to process vertex buffers on the GPU without rendering them. For example, a vertex buffer describing a triangle mesh could be treated as a simple set of points in an initial pass. The vertex shader could be used to perform per-vertex computations as desired, with the results sent to a new vertex buffer using stream output. On a subsequent pass, this new vertex buffer could be paired with the original index buffer describing the mesh’s connectivity, to further process and display the resulting mesh.
使用管道的流输出功能(第3.7.1节)将已处理的顶点发送到新缓冲区的能力,允许在GPU上处理顶点缓冲区,而无需渲染它们。例如,描述三角形网格的顶点缓冲区可以被视为初始过程中的一组简单的点。顶点着色器可用于根据需要执行逐顶点计算,使用流输出将结果发送到新的顶点缓冲区。在随后的过程中,这个新的顶点缓冲区可以与描述网格连通性的原始索引缓冲区配对,以进一步处理和显示结果网格。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











