







前言
进程休眠与唤醒也是内核管理的重要一部分。本是进程调度相关内容,笔者在此单拎出来进行梳理。同样的,主要对比 linux0.12 与 linux2.6 之间的差异。
流程梳理
自然地,让一个进程休眠,我们只需要将其状态更改为TASK_INTERRUPTIBLE或者TASK_UNINTERRUPTIBLE,接着再执行调度程序 schedule() 即可。由于调度程序只会调度状态为TASK_RUNNING的进程,因此被修改的进程不会被调度,看上去就像"休眠"了。而唤醒则更简单,只需要将待唤醒进程状态改为 TASK_RUNNING 即可,等待调度就能够被“唤醒”。
然而,由于休眠可能是为了等待某一类资源的使用或者某一条件的满足,当多个进程同时请求某类资源而都进入休眠状态时,需要使用一个等待队列进行管理。因此,我们可以简单地认为,实现进程的休眠和唤醒需要:
- 设计一个等待队列,用于关联正在休眠的进程
- 修改进程状态并执行调度
Linux0.12
该版本通过sleep_on()与wake_up()进行进程的休眠与唤醒。代码中没有显式地使用一个等待队列关联休眠进程,而是通过指针直接串联task_struct结构体来实现。其原理在《Linux内核完全注释》中有详细说明,如下:
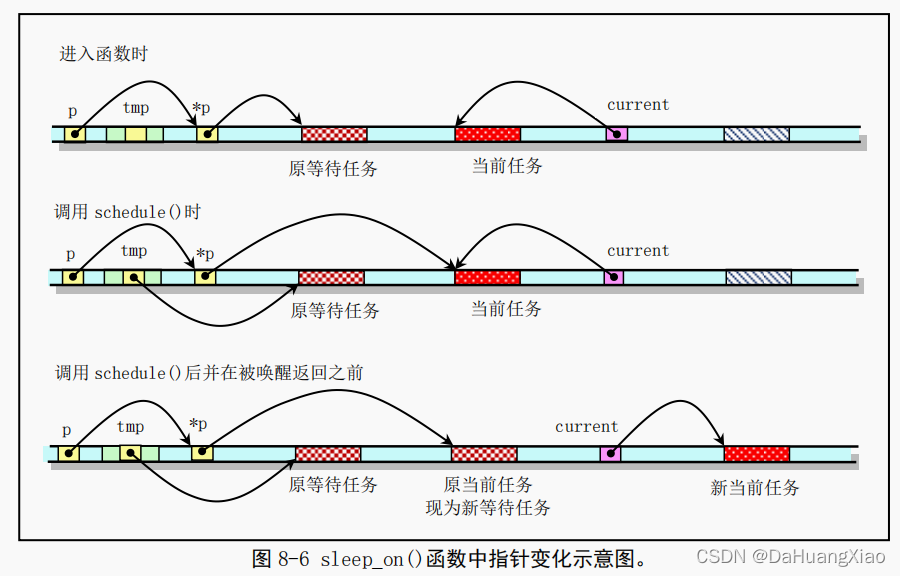
当刚进入该函数时,队列头指针*p 指向已经在等待队列中等待的任务结构(进程描述符)。当然,在系统刚开始执行时,等待队列上无等待任务。因此上图中原等待任务在刚开始时不存在,此时*p 指向NULL。通过指针操作,在调用调度程序之前,队列头指针指向了当前任务结构,而函数中的临时指针 tmp 指向了原等待任务。在执行调度程序并在本任务被唤醒重新返回执行之前,当前任务指针被指向新的当前任务,并且 CPU 切换到该新的任务中执行。这样本次 sleep_on()函数的执行使得 tmp 指针指向队列中队列头指针指向的原等待任务,而队列头指针则指向此次新加入的等待任务,即调用本函数的任务。
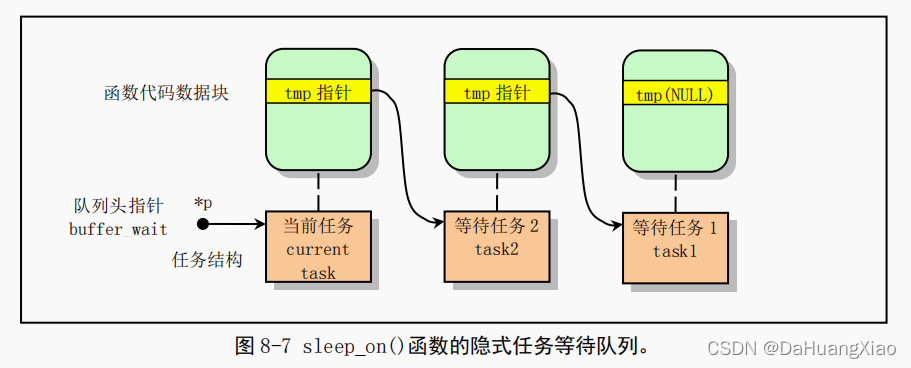
从而通过堆栈上该临时指针 tmp 的链接作用,在几个进程为等待同一资源而多次调用该函数时,内核程序就隐式地构筑出一个等待队列,参见图 8-7 中的等待队列示意图。图中示出了当向队列头部插入第三个任务时的情况。从图中我们可以更容易理解 sleep_on()函数的等待队列形成过程。
linux-0.12\kernel\sched.c
void sleep_on(struct task_struct **p)
{
__sleep_on(p,TASK_UNINTERRUPTIBLE);
}
static inline void __sleep_on(struct task_struct **p, int state)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp = *p;
*p = current;
current->state = state;
repeat: schedule();
if (*p && *p != current) {
(**p).state = 0;
current->state = TASK_UNINTERRUPTIBLE;
goto repeat;
}
if (!*p)
printk("Warning: *P = NULL\n\r");
if (*p = tmp)
tmp->state=0;
}
通过wake_up()唤醒时,只需要修改对应进程状态
void wake_up(struct task_struct **p)
{
if (p && *p) {
if ((**p).state == TASK_STOPPED)
printk("wake_up: TASK_STOPPED");
if ((**p).state == TASK_ZOMBIE)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









