







本人为中科院测地所博士生,所研究专业为自然地理学(遥感数据分析方向),研究课题偏向于深度学习。
由于本人不是计算机专业,故有关计算机配置及操作方面相较于计算机专业人员不是那么专业。所以请各位大牛大神绕道,我这里所做的一些工作比较浅显,仅供需要的各位一起交流。
在深度学习的配置环境过程中,第一步则是需要安装microsoft的visual studio。这个在本人的第一篇博客中已经说明。接下来,在深度学习的过程中,需要用GPU计算加快计算速度。笔者电脑的配置是win10+E5服务器cpu+N卡1070显卡。因此可以安装CUDA。关于CUDA的概念及作用在此我就不再赘述了,各位读者可以自行百度或在NVIDIA官网上查看。在此我贴出的是安装过程。
在配置深度学习的过程中,国外大牛有使用CUDA6.5/7.5/8.0/9.0的,深度学习及显卡计算能力发展快速,CUDA6.5及7.5即将淘汰,或与笔者的1070显卡不兼容(因为10系列采用了全新的帕斯卡架构),为了防止出现一些不兼容的错误及各版本都能计算,我同时安装了主流的CUDA8.0,及与10系列显卡兼容的最新CUDA9.1。
需要注意的第一点是,在配置时,vs2013=Microsoft Visual Studio 12.0,vs2015=Microsoft Visual Studio 14.0。建议CUDA9.1使用VS2015,CUDA8.0使用VS2013。本质上并没有区别,但为了区分方便而已。
需要注意的第二点是,两者可以安装在一台电脑上并不冲突。作者在搜索度娘时有人回答:可以同时安装,但必须先安装低版本(CUDA8.0)再安装高版本(CUDA9.0/9.1),对此笔者并没有证实,不知道所言是否正确。但为了电脑不会出什么差错,我还是先安装了8.0,再安装了9.1.实测并不冲突,可以兼容。
需要注意的第三点是,CUDA8.0对应的cuDNN版本是5.1,CUDA9.0对应的cuDNN7.0。同时,cuDNN可以同时安装在CUDA8.0和9.0中,而cuDNN7.0只能对CUDA9.0及以上适用。
各位读者最好事先在NVIDIA网站注册一个账号,便于下载使用。
先给出官方的CUDA下载地址,
CUDA9.1:https://developer.nvidia.com/cuda-downloads

CUDA8.0:https://developer.nvidia.com/cuda-80-ga2-download-archive

cuDNN7.0:https://developer.nvidia.com/cudnn

如果各位不知道怎么下载,可以去我的网盘查看
CUDA8.0-cuDNN5.1:链接:https://pan.baidu.com/s/1b6D3n4 密码:yhhf
CUDA9.1-cuDNN7.0:链接:https://pan.baidu.com/s/1jHYh67c 密码:jlfn
笔者并不是只安装,而是边安装别配置,这样一步步可以在某一个环节出问题就马上重来,而不用在最后发现出问题了又重新开始。
安装及配置过程本人以CUDA9.1/cuDNN7.0为例,CUDA8.0/cuDNN5.1同理。
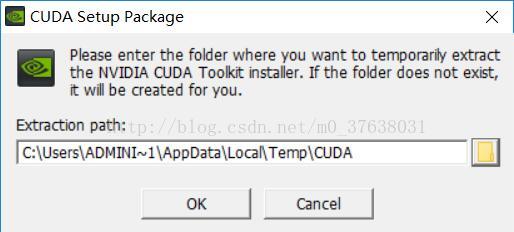
打开CUDA9.1安装文件

安装文件会解压,默认路径为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8705
8705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









