






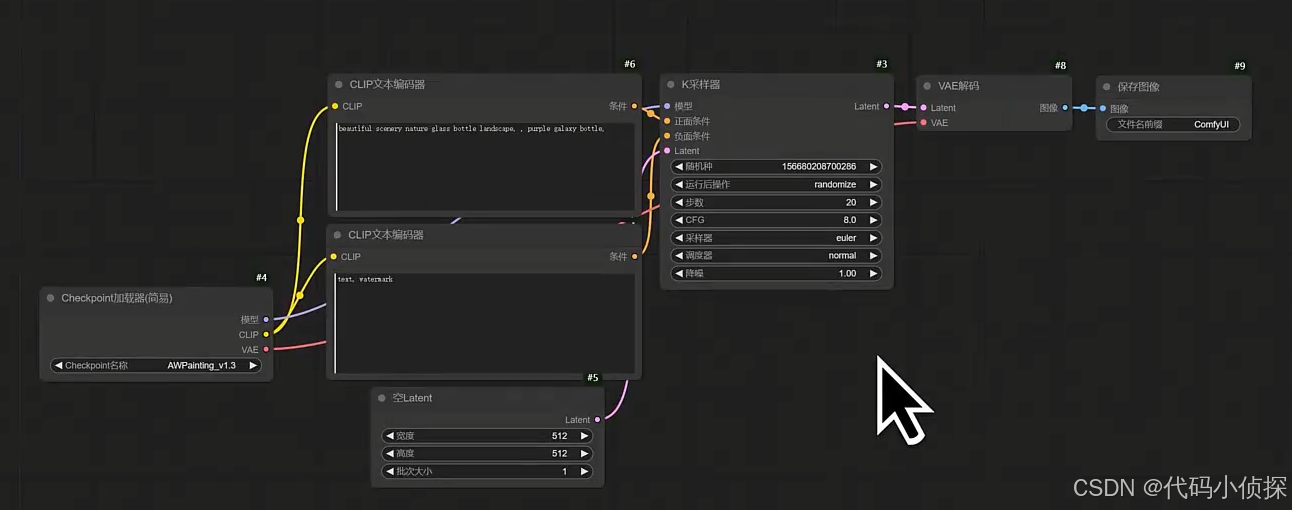
LIbLibAI的基础工作流是一个典型的文本到图像生成流程,基于Stable Diffusion等扩散模型的架构。以下是各步骤的详细说明:
- Checkpoint加载器(简易)— 加载大模型的一个地方
-
功能:加载预训练的扩散模型权重(如Stable Diffusion的.ckpt或.safetensors文件)
-
作用:作为整个流程的核心模型基础,决定了生成图像的风格和能力(如写实/动漫等)
-
特点:提供简化的界面操作,用户只需选择模型文件即可完成加载
- CLIP文本编码器
-
原理:将输入的文本提示(Prompt)转换为CLIP模型能理解的768维嵌入向量
-
关键作用:建立文本与图像语义的关联,指导生成过程的方向
-
处理流程:文本→分词→通过CLIP的Transformer编码→文本嵌入向量
- K采样器
-
核心算法:执行扩散模型的迭代去噪过程(如DDPM、DDIM或Karras方法)
-
重要参数:
-
采样步骤(步数)(Steps):20-30步常见
-
引导比例(CFG Scale):7-12典型值
-
随机种子(Seed):控制生成结果的可重复性
- 所有参数和“种子值”相同,那生成的图像也是一样的
-
工作机制:在潜在空间逐步去除噪声,将随机噪声转化为与文本匹配的潜在表示
-
- Latent(潜在空间)
-
技术特征:
-
使用VAE的编码器将图像压缩到低维空间(如512×512→64×64×4)
-
在潜在空间进行生成运算,大幅降低计算资源消耗
-
-
优势:相比直接处理像素空间,计算效率提升约4倍
- VAE解码
-
功能实现:将64×64的潜在表示解码为512×512的RGB图像
-
技术细节:
-
通过变分自编码器的解码器重建细节 -
可能包含后处理(如超分辨率增强)
- 保存图像
-
输出处理:
-
支持常见格式(PNG/JPG等) -
可附加元数据(如生成参数、种子值) -
扩展功能:可配置批量保存、自动命名规则等
工作流逻辑:文本输入→模型加载→文本编码(CLIP)→潜在空间迭代去噪→潜在解码→像素输出。整个过程在保持Stable Diffusion核心机制的同时,通过模块化设计简化用户操作,适合快速图像生成需求。潜在空间操作和CLIP引导机制的结合,实现了高效的文本到图像转换。

















 1980
1980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









