



台湾大学林轩田老师在coursera上的两门机器 学习的课程受到广泛好评,学习中写点笔记防止偷懒
分享一下在网上找到的pdf版课件:链接:http://pan.baidu.com/s/1c2fDHPe 密码:6hgz
【Lecture 1】The Learning Problem
什么是机器 学习:improving some performance measure with experience computed from data
即:data—>ML—>improved performance measure
什么时候适合使用机器 学习:
1. exists some ‘underlying pattern’ to be learned
2.but no programmable (easy) definition
3.somehow there is data about the pattern
机器 学习模型:
式中,D是已有的数据集(training examples),(x1,y1),··· ,(xN,yN),其中x是输入,y是输出
H是由g的所有可能结果组成的集合(hypothesis set)
A是机器 学习的算 法(learning algorithm)
g是机器 学习得到的最接近f的一个结果(hypothesis)
f是由x到y的目标函数,反映了机器学到的underlying pattern
那么也可以说,机器 学习就是:以已有的数据集为依据,运用算 法A从hypothesis set中选出最优的一个h作为目标函数f的估计
【Lecture 2】Learning to Answer Yes/No
这一讲讨论二元分类,y=1或y=-1
一个得到hypothesis set的方法:perceptron(感知器)求H中的每一个元素hh写成向量表达式:
h以作图的形式:
假如输入向量x是n维,那么在n维坐标系中,可以把向量x定位到一个点;
如果x对应的输出y为正,就在x这个点处画一个圈,如果x对应的输出y为负,就在x这个点处画一个叉;
h是什么?h是对x的加权值求符号,正负分界点为0,所以h体现在图中就是w'x=0的一个超平面,平面的位置随权重w变化而变化。如果是二维平面中就是一条直线,课程中主要以二维为例
为什么这条线与w垂直?因为这条线满足w'x=0,而内积为0的两个向量垂直
Perceptron Learning Algorithm(PLA)
H的组成元素h有无限多种,如何从其中选出最接近目标函数f的一个?
如果把所有h都计算一遍再从中选择是不现实的。采用的方法是:从某一个w开始,得到一个相应的h,如果这个h不是最接近f的,那就修正它让它变得更好,直到最后得到一个最接近f的结果。
那么有三个问题:
1.怎么判断最接近f?让h在已有的数据集上与f相同。具体做法是用h计算一个点,如果结论不等于y就进行修正,然后算下一个点,直到所有点的结果都等于对应的y
2.初始的w?不妨都取0表示一开始什么都未知
3.怎么修正h?由向量的几何关系可知,如果实际的y=1而计算结果-1,说明w和x的夹角太大,可以把w修正为w+x;如果实际的y=-1而计算结果1,说明w和x的夹角太小,可以把w修正为w-x。两种情况可以统一写为w=w+y*x
这个算 法叫做Perceptron Learning Algorithm(PLA)
例题:根据PLA的如下规则,下面哪一个式子是正确的?
Answer: 3
因为w(t+1)=w(t)+y*x,所以y*w(t+1)*x=y*[w(t)+y*x]*x >y*w(t)*x
这个式子的成立说明w=w+y*x确实对h有修正作用。因为,y*w*x=y*(w*x),w*x是什么?是x的加权值,取符号得到h;题中的式子说明w*x这个数乘上y后会变大;可能有这个数为正而y为负和这个数为负而y为正两种情况,乘积都为负,乘积变大意味着绝对值减小,这个数在向y值倾斜。
证明PLA会终止
把满足PLA终止条件的数据集D称为线性可分(Linear Separable)
如果D线性可分,那么存在w(f),对所有n成立:
因此
推论1:w(f)和w的内积越来越大
推论2: w增长不会太快
因为w需要修正时成立:
所以
这两个推论结合起来说明w越来越接近w(f)
因为
内积增大的同时w增长不会太快,说明夹角在减小
并且w接近w(f)的过程会终止,即PLA会终止,修正更新的过程最多只用T次
证明(使用了递归):
因为向量标准化后值为1,所以左式值为1,可以看出T有上限
作如下定义:
上式可化简为:
如果D不是线性可分的怎么办
假设杂讯很小,并找一个最符合数据集D的g,也就是找一个让y不等于w'x的点的个数最少的w
使用一种算 法叫Pocket Algorithm,做法是:从某一个w出发,每一次按照PLA算 法得到下一个w就把两者进行比较,保留在D上犯错误更少的那一个,不断迭代直到达到规定次数
在一开始的时候,我们并不知道D是不是线性可分,即使是线性可分也不知道T要用多久。如果D实际上是线性可分的,那么使用Pocket Algorithm比直接使用PLA要花更多时间,原因有两个,一是需要保存当前最好的w和犯错误次数,二是每次迭代中要把所有点计算一遍并与上一次比较犯错误次数
【Lecture 3】Types of Learning
不同类型的输出空间y
1. binary classification: y = {−1, +1}
2. multiclass classification: y = {1, 2, ···, K}
3. regression: y = R
4. structured learning: y = structures
不同类型的数据标签y(n)
1. supervised: 每一个x(n)都给出对应的y(n)
2. unsupervised: 没有给出y(n)
3. semi-supervised: 一部分给出y(n)
4. reinforcement: implicit y(n) by goodness(y ̃n),告诉每一个输出它是好还是不好

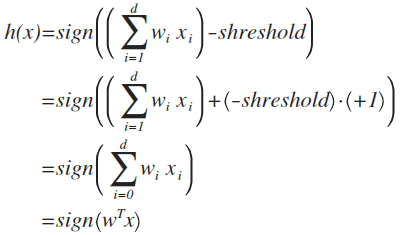
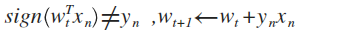
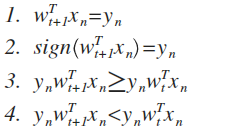
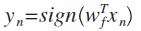
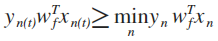
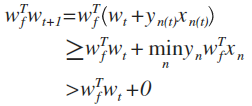
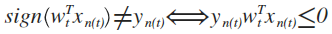
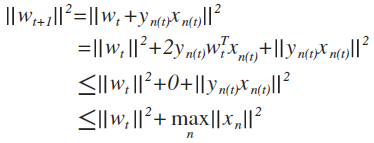
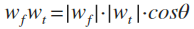
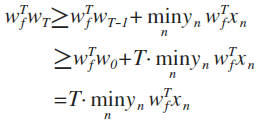
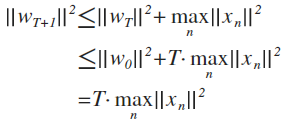
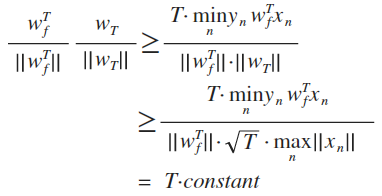

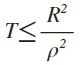
不同类型的学习方式f
1. batch learning: 批量,填鸭式
2. online learning: 一点一点地给数据,PLA和reinforcement learning都适合这种方式
3. active learning: 机器主动询问某些x(n)的y(n)应该是什么
不同类型的输入空间x
1. concrete features: sophisticated (and related) physical meaning
2. raw features: simple physical meaning
3. abstract features: no (or little) physical meaning

















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









