







文章目录
首先调大虚拟机内存为6G左右:

一、安装atlas
cd apache-atlas-sources-2.1.0/
mvn clean -DskipTests package -Pdist,external-hbase-solr -Denforcer.skip=true
# 由于atlas只提供源码,所以需要我们先将源码编译后,再将压缩包上传到服务器
tar -zxvf distro/target/apache-atlas-2.1.0-server.tar.gz
1.集成 Hbase:
root@ubuntu:/opt/bigdata-packages/atlas# vim apache-atlas-2.1.0/conf/atlas-application.properties
# 修改 atlas 存储数据主机
atlas.graph.storage.hostname=127.0.0.1:2181
root@ubuntu:/opt/bigdata-packages/atlas# ln -s /opt/bigdata-packages/hbase/hbase-2.0.6/conf/ /opt/bigdata-packages/atlas/apache-atlas-2.1.0/conf/hbase/
root@ubuntu:/opt/bigdata-packages/atlas# vim apache-atlas-2.1.0/conf/atlas-env.sh
#添加HBase配置文件路径
export HBASE_CONF_DIR=/opt/bigdata-packages/hbase/hbase-2.0.6/conf
2.集成 Solr:
root@ubuntu:/opt/bigdata-packages/atlas# vim apache-atlas-2.1.0/conf/atlas-application.properties
# 修改配置为
atlas.graph.index.search.solr.zookeeper-url=127.0.0.1:2181
# 将 Atlas 自带的 Solr 文件夹拷贝到外部 Solr 集群的各个节点。
root@ubuntu:/opt/bigdata-packages/atlas# cp -r apache-atlas-2.1.0/conf/solr/ /opt/bigdata-packages/solr/solr-8.9.0
# 修改拷贝过来的配置文件名称为atlas_conf
root@ubuntu:/opt/bigdata-packages/solr/solr-8.9.0# mv solr atlas_conf
# 在Cloud模式下,启动Solr(需要提前启动Zookeeper集群),并创建collection
root@ubuntu:/opt/bigdata-packages/solr/solr-8.9.0# bin/solr create -c vertex_index -d atlas_conf -shards 3 -replicationFactor 2 -force
root@ubuntu:/opt/bigdata-packages/solr/solr-8.9.0# bin/solr create -c edge_index -d atlas_conf -shards 3 -replicationFactor 2 -force
root@ubuntu:/opt/bigdata-packages/solr/solr-8.9.0# bin/solr create -c fulltext_index -d atlas_conf -shards 3 -replicationFactor 2 -force
注:如果需要删除vertex_index、edge_index、fulltext_index等collection可以执行如下命令:bin/solr delete -c ${collection_name}
验证创建collection成功:访问 http://192.168.223.128:8983/solr/#/~cloud 看到如下图显示:

遇到的问题:创建collection的时候可能会报错:Unable to read additional data from server sessionid 0x17c831dd49f0009, likely server has closed socket。

可能的原因:我这里zookeeper装的是单节点的,zookeeper有个选举算法,当整个集群超过半数机器宕机,zookeeper会认为集群处于不可用状态。一般至少需要三个zk才可以,一般是2n+1的数量部署。目前来看collection都已近创建成功了,不知道zookeeper单节点有没有问题,先往后走吧,不行的话再改成三个节点的吧。

3.集成 Kafka:
root@ubuntu:/opt/bigdata-packages/atlas# vim apache-atlas-2.1.0/conf/atlas-application.properties
# 修改配置为
atlas.notification.embedded=false
atlas.kafka.data=/opt/bigdata-packages/atlas/apache-atlas-2.1.0/data/kafka
atlas.kafka.zookeeper.connect=localhost:2181
atlas.kafka.bootstrap.servers=localhost:9092
atlas.kafka.zookeeper.session.timeout.ms=4000
atlas.kafka.zookeeper.connection.timeout.ms=2000
atlas.kafka.enable.auto.commit=true
# 创建Topic
root@ubuntu:/opt/bigdata-packages/atlas# kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 3 --topic _HOATLASOK
root@ubuntu:/opt/bigdata-packages/atlas# kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 3 --topic ATLAS_ENTITIES
root@ubuntu:/opt/bigdata-packages/atlas# kafka-topics.sh --list --zookeeper 127.0.0.1:2181
ATLAS_ENTITIES
_HOATLASOK
4.集成 Hive:
root@ubuntu:/opt/bigdata-packages/atlas# vim apache-atlas-2.1.0/conf/atlas-application.properties
# 添加如下配置
atlas.hook.hive.synchronous=false
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=10000
atlas.cluster.name=primary
# 上传apache-atlas-2.1.0-hive-hook.tar.gz文件
sftp:/opt/bigdata-packages/atlas> put D:\huiq\workspace\apache-atlas-sources-2.1.0\distro\target\apache-atlas-2.1.0-hive-hook.tar.gz
Uploading apache-atlas-2.1.0-hive-hook.tar.gz to remote:/opt/bigdata-packages/atlas/apache-atlas-2.1.0-hive-hook.tar.gz
sftp: sent 10.7 MB in 1.20 seconds
root@ubuntu:/opt/bigdata-packages/atlas# tar -zxvf apache-atlas-2.1.0-hive-hook.tar.gz
# 剪切 hook 和 hook-bin 目录到到/opt/bigdata-packages/atlas/apache-atlas-2.1.0 文件夹中
root@ubuntu:/opt/bigdata-packages/atlas# mv apache-atlas-hive-hook-2.1.0/hook-bin/ apache-atlas-2.1.0
root@ubuntu:/opt/bigdata-packages/atlas# mv apache-atlas-hive-hook-2.1.0/hook apache-atlas-2.1.0
# 将 atlas-application.properties 配置文件加入到 atlas-plugin-classloader-2.1.0.jar 中
root@ubuntu:/opt/bigdata-packages/atlas# zip -u apache-atlas-2.1.0/hook/hive/atlas-plugin-classloader-2.1.0.jar apache-atlas-2.1.0/conf/atlas-application.properties
adding: apache-atlas-2.1.0/conf/atlas-application.properties (deflated 66%)
root@ubuntu:/opt/bigdata-packages/atlas# cp apache-atlas-2.1.0/conf/atlas-application.properties ../hive/apache-hive-3.1.2-bin/conf/
# 在hive-site.xml 文件中设置 Atlas hook
root@ubuntu:/opt/bigdata-packages/atlas# vim ../hive/apache-hive-3.1.2-bin/conf/hive-site.xml
# 添加如下配置
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
# 修改hive-env.sh
root@ubuntu:/opt/bigdata-packages/atlas# vim ../hive/apache-hive-3.1.2-bin/conf/hive-env.sh
# 添加如下配置
export HIVE_AUX_JARS_PATH=/opt/bigdata-packages/atlas/apache-atlas-2.1.0/hook/hive
5.Atlas 其他配置:
root@ubuntu:/opt/bigdata-packages/atlas# vim apache-atlas-2.1.0/conf/atlas-application.properties
# 修改配置为
atlas.rest.address=http://localhost:21000
atlas.server.run.setup.on.start=false
atlas.audit.hbase.zookeeper.quorum=localhost:2181
# 记录性能指标,进入 conf 路径,修改当前目录下的 atlas-log4j.xml,去掉如下代码的注释
root@ubuntu:/opt/bigdata-packages/atlas# vim apache-atlas-2.1.0/conf/atlas-log4j.xml
<appender name="perf_appender" class="org.apache.log4j.DailyRollingFileAppender">
<param name="file" value="${atlas.log.dir}/atlas_perf.log" />
<param name="datePattern" value="'.'yyyy-MM-dd" />
<param name="append" value="true" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d|%t|%m%n" />
</layout>
</appender>
<logger name="org.apache.atlas.perf" additivity="false">
<level value="debug" />
<appender-ref ref="perf_appender" />
</logger>
二、使用atlas
1.启动 Atlas:
# 其他组件已经启动
root@ubuntu:/opt/bigdata-packages/atlas# jps
5856 Kafka
3409 ResourceManager
2518 QuorumPeerMain
4087 HMaster
3098 SecondaryNameNode
2906 DataNode
3564 NodeManager
2749 NameNode
4238 HRegionServer
49071 Jps
root@ubuntu:/opt/bigdata-packages/atlas/apache-atlas-2.1.0/bin# python2.7 atlas_start.py
starting atlas on host localhost
starting atlas on port 21000
........................................................................................................................................................
Apache Atlas Server started!!!
root@ubuntu:/opt/bigdata-packages/atlas/apache-atlas-2.1.0/bin# jps
5856 Kafka
3409 ResourceManager
74674 Jps
2518 QuorumPeerMain
50646 HRegionServer
74503 Atlas
3098 SecondaryNameNode
2906 DataNode
3564 NodeManager
2749 NameNode
50495 HMaster
访问atlas:等待时间大概2分钟,http://192.168.223.128:21000/,账户:admin,密码:admin


遇到的问题:默认安装了Python 3.6.9版本,启动报错:SyntaxError: Missing parentheses in call to 'print'. Did you mean print("Apache Atlas Server stopped!!!\n")

解决:安装Python 2.7.14版本后再启动。
2.安装示例(quick start):
Atlas安装包中提供两个项目的示例,如果你是想学习,这两个示例是很好的入门:
root@ubuntu:/opt/bigdata-packages/atlas/apache-atlas-2.1.0/bin# python2.7 quick_start.py
root@ubuntu:/opt/bigdata-packages/atlas/apache-atlas-2.1.0/bin# python2.7 quick_start_v1.py

3.相关概念:
- Type:元数据类型定义,这里可以是表,列,视图,物化视图等,还可以细分hive表(hive_table),hbase表(hbase_table)等,甚至可以是一个数据操作行为,比如定时同步从一张表同步到另外一张表这个也可以描述为一个元数据类型,atlas自带了很多类型,但是可以通过调用api自定义类型。
- Classification:分类,通俗点就是给元数据打标签,分类是可以传递的,比如user_view这个视图是基于user这个表生成的,那么如果user打上了HR这个标签,user_view也会自动打上HR的标签,这样的好处就是便于数据的追踪。
- GLOSSARY:词汇表,GLOSSARY包含两个概念,Category(类别)和Term(术语),Category表示一组Term的集合,术语为元数据提供了别名,以便用户更好的理解数据,举个例子,有个pig的表,里面有个猪肾的字段,但很多人更习惯叫做猪腰子,那么就可以给猪肾这个字段加一个Term,不仅更好理解,也更容易搜索到。
- Entity:实体,表示具体的元数据,Atlas管理的对象就是各种Type的Entity。
- Lineage:数据血缘,表示数据之间的传递关系,通过Lineage我们可以清晰的知道数据的从何而来又流向何处,中间经过了哪些操作。
4.UI界面:
- Entity主界面:这里可以查看Entity详细信息,可以查看和添加分类,术语,查看和定义一些属性,标签。

- 血缘关系:表
sales_fact经过loadSalesDaily操作后生成表sales_fact_daily_mv,再经过loadSalesMonthly后生成表sales_fact_monthly_mv,我们可以看下sales_fact_monthly_mv的血缘图,可以发现该表源头数据不仅来自sales_fact还来自于time_dim。


- 关联关系:可以查询表包含的列,数据库,来源,去向,存储,点击上面切换视图可以切换到图形模式。


- 审计线索:记录对该对象的操作记录。

5.导入hive表:
atlas可以通过brige将元数据从数据库系统导入到atlas中,并且支持自动更新,目前从源码上看atlas支持的产品如下:
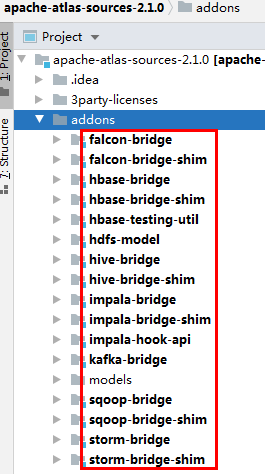
可以看到目前支持falcon,hbase,hive,impala,kafka,sqoop,storm数据库的导入,并且atlas自带有hive相关元数据类型:

# 启动 import-hive.sh脚本
root@ubuntu:/opt/bigdata-packages/atlas/apache-atlas-2.1.0/hook-bin# ./import-hive.sh
。。。。。。内容太多省略
Hive Meta Data imported successfully!!!
















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











