







文章目录
一、服务器配置
[root@localhost ~]# cat /etc/centos-release
CentOS Linux release 7.9.2009 (Core)
[root@localhost ~]# cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
2
[root@localhost ~]# cat /proc/cpuinfo| grep "cpu cores"| uniq
cpu cores : 10
[root@localhost ~]# cat /proc/cpuinfo| grep "processor"| wc -l
40
You have new mail in /var/spool/mail/root
[root@localhost ~]# cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
40 Intel(R) Xeon(R) Silver 4210 CPU @ 2.20GHz
[root@localhost ~]# free -g
total used free shared buff/cache available
Mem: 125 26 23 2 75 96
Swap: 0 0 0
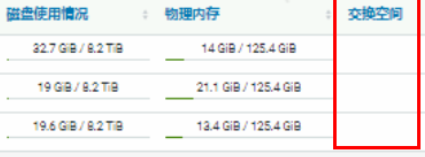
Cloudera Manager主页–》主机–》所有主机–》选择其中一台主机可查看详细信息:

二、准备工作
2.1 修改主机名
hostnamectl set-hostname node01
hostnamectl set-hostname node02
hostnamectl set-hostname node03
三台服务器都操作:
vim /etc/hosts
# 增加以下内容:
192.168.42.131 node01
192.168.42.132 node02
192.168.42.133 node03
2.2 关闭防火墙
systemctl stop firewalld.service
# 设置开机不启动:
systemctl disable firewalld.service
# 查看防火墙状态
firewall-cmd --state
2.3 关闭 Selinux
# 查看SELinux状态:如果SELinux status参数为enabled即为开启状态
sestatus
# 临时关闭,不用重启机器
setenforce 0
# 永久关闭
vim /etc/selinux/config
# 修改如下配置项:
SELINUX=disabled
2.4 关闭 THP
如果不关闭 THP,Hadoop 的系统 CPU 使用率很高。
# 查看:
[root@bigdata-platform-1 ~]# cat /sys/kernel/mm/transparent_hugepage/defrag
[always] madvise never
[root@bigdata-platform-1 ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
# 关闭:
vim /etc/rc.d/rc.local
# 在文末加入一段代码:
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
# 保存退出,然后赋予rc.local文件执行权限:
chmod +x /etc/rc.d/rc.local
2.5 文件描述符配置
Linux 操作系统会对每个进程能打开的文件数进行限制(某用户下某进程),Hadoop 生态系统的很多组件一般都会打开大量的文件,因此要调大相关参数(生产环境必须调大,学习环境稍微大点就可以)。检查文件描述符限制数,可以用如下命令检查当前用户下一个进程能打开的文件数:
ulimit -Sn
1024
ulimit -Hn
4096
建议的最大打开文件描述符数为10000或更多:
vim /etc/security/limits.conf
# 直接添加内容:
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
三台机器重启生效:reboot
[root@bigdata-platform-1 ~]# getenforce
Disabled
[root@bigdata-platform-1 ~]# ulimit -Sn
65536
[root@bigdata-platform-1 ~]# ulimit -Hn
65536
[root@bigdata-platform-1 ~]# cat /sys/kernel/mm/transparent_hugepage/defrag
always madvise [never]
[root@bigdata-platform-1 ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]
2.6 关闭 swap
关闭 swap(避免交换内存,默认是开启,如果你内存不够,那么他就会先写到磁盘上,然后释放的时候,会将磁盘中的内存加载到内存中,如果磁盘中消耗的资源大于内存,结果就是宕机,关闭后,相当于是一种保护策略)
临时关闭:
swapoff -a
# 临时开启
# swapon -a
永久关闭:
vim /etc/fstab
# 注释掉 swap 这一行
# /dev/mapper/centos-swap swap swap defaults 0 0
注意:如果服务器内存不够用,关闭 Swap 不是一种好的选择,可能会导致服务器卡死连接不上,这时打开 Swap 其实是一种保护机制。
2.7 配置 SSH 免密登录
[root@node01 ~]# ssh-keygen
[root@node02 ~]# ssh-copy-id root@node02
[root@node03 ~]# ssh-copy-id root@node03
三、制作本地 Yum 源
[root@node01 yum.repos.d]# mount -o loop /home/xiaoqiang/CentOS-7-x86_64-DVD-2009.iso /home/xiaoqiang/centosiso/
mount: /dev/loop0 is write-protected, mounting read-only
[root@node01 yum.repos.d]# vim centos-local.repo
[Centos7-Local]
name=centos yum
baseurl=file:///home/xiaoqiang/centosiso
enabled=1
gpgcheck=0
[root@node01 yum.repos.d]# yum clean all && yum makecache
Loaded plugins: fastestmirror, langpacks
Cleaning repos: Centos7-Local
Cleaning up list of fastest mirrors
Loaded plugins: fastestmirror, langpacks
Determining fastest mirrors
Centos7-Local | 3.6 kB 00:00:00
(1/4): Centos7-Local/group_gz | 153 kB 00:00:00
(2/4): Centos7-Local/filelists_db | 3.3 MB 00:00:00
(3/4): Centos7-Local/primary_db | 3.3 MB 00:00:00
(4/4): Centos7-Local/other_db | 1.3 MB 00:00:00
Metadata Cache Created
其他两台服务器也执行上面的操作;
3.1 安装 httpd 服务
[root@node01 yum.repos.d]# yum -y install httpd httpd-devel
# 启动httpd
[root@node01 yum.repos.d]# systemctl start httpd
# 配置开机自启
[root@node01 yum.repos.d]# systemctl enable httpd
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
3.2 安装 yum-utils、createrepo
[root@node01 yum.repos.d]# yum -y install yum-utils createrepo
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
Package yum-utils-1.1.31-54.el7_8.noarch already installed and latest version
Package createrepo-0.9.9-28.el7.noarch already installed and latest version
Nothing to do
3.3 安装 NTP 服务(所有服务器)
目前这三台服务器的时间不同步
[root@node01 yum.repos.d]# date
Sat Dec 23 00:30:49 CST 2023
[root@node02 ~]# date
Sat Dec 23 00:43:00 CST 2023
[root@node03 ~]# date
Fri Dec 22 14:48:17 CST 2023
三台服务器执行以下操作:
[root@node01 yum.repos.d]# yum -y install ntp ntpdate
# 启动NTP服务
[root@node01 yum.repos.d]# systemctl start ntpd
[root@node02 yum.repos.d]# yum -y install ntp ntpdate
[root@node02 yum.repos.d]# systemctl start ntpd
[root@node03 yum.repos.d]# yum -y install ntp ntpdate
[root@node03 yum.repos.d]# systemctl start ntpd
首先手动设置主节点时间为当前时间:
[root@node01 yum.repos.d]# date -s "2023-12-22 17:42:00"
主节点执行以下操作:
[root@node01 yum.repos.d]# sudo systemctl enable ntpd && sudo ntpdate -u 192.168.42.131 && sudo hwclock --systohc && sudo systemctl status ntpd
23 Dec 00:51:08 ntpdate[5240]: no server suitable for synchronization found
由于这三台服务器不联网,所以需要修改 ntp 配置文件:
[root@node01 yum.repos.d]# vim /etc/ntp.conf
# 修改前
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
# 修改后
server 127.127.1.0 prefer
# 重启 ntp 服务器
[root@node01 yum.repos.d]# systemctl restart ntpd
[root@node01 yum.repos.d]# ntpdate -u 192.168.42.131
22 Dec 17:39:47 ntpdate[5609]: adjust time server 192.168.42.131 offset -0.000008 sec
[root@node01 yum.repos.d]# sudo systemctl status ntpd
● ntpd.service - Network Time Service
Loaded: loaded (/usr/lib/systemd/system/ntpd.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2023-12-22 17:39:35 CST; 1min 4s ago
Process: 5602 ExecStart=/usr/sbin/ntpd -u ntp:ntp $OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 5605 (ntpd)
Tasks: 1
CGroup: /system.slice/ntpd.service
└─5605 /usr/sbin/ntpd -u ntp:ntp -g
Dec 22 17:39:35 node01 ntpd[5605]: Listen normally on 3 enp94s0f3 10.8.0.6 UDP 123
Dec 22 17:39:35 node01 ntpd[5605]: Listen normally on 4 virbr0 192.168.122.1 UDP 123
Dec 22 17:39:35 node01 ntpd[5605]: Listen normally on 5 lo ::1 UDP 123
Dec 22 17:39:35 node01 ntpd[5605]: Listen normally on 6 enp94s0f3 fe80::caba:c33:2794:1634 UDP 123
Dec 22 17:39:35 node01 ntpd[5605]: Listening on routing socket on fd #23 for interface updates
Dec 22 17:39:35 node01 ntpd[5605]: 0.0.0.0 c016 06 restart
Dec 22 17:39:35 node01 ntpd[5605]: 0.0.0.0 c012 02 freq_set kernel 0.000 PPM
Dec 22 17:39:35 node01 ntpd[5605]: 0.0.0.0 c011 01 freq_not_set
Dec 22 17:39:35 node01 systemd[1]: Started Network Time Service.
Dec 22 17:39:36 node01 ntpd[5605]: 0.0.0.0 c514 04 freq_mode
[root@node02 yum.repos.d]# vim /etc/ntp.conf
# 修改为以下的值
server 192.168.42.131 iburst
# 和主节点时间同步
[root@node02 yum.repos.d]# ntpdate -u 192.168.42.131
22 Dec 17:48:35 ntpdate[5491]: step time server 192.168.42.131 offset -28393.197027 sec
[root@node03 yum.repos.d]# vim /etc/ntp.conf
# 修改为以下的值
server 192.168.42.131 iburst
# 和主节点时间同步
[root@node03 yum.repos.d]# ntpdate -u 192.168.42.131
22 Dec 17:50:44 ntpdate[5414]: step time server 192.168.42.131 offset 7289.785005 sec
四、安装 JDK 和 Mysql
4.1 配置 YUM 源
将安装所需文件上传到 192.168.42.131 服务器上
在每台服务器上,将这两个文件 cloudera-manager.repo、RPM-GPG-KEY-cloudera 拷贝到 /etc/yum.repos.d 目录下:
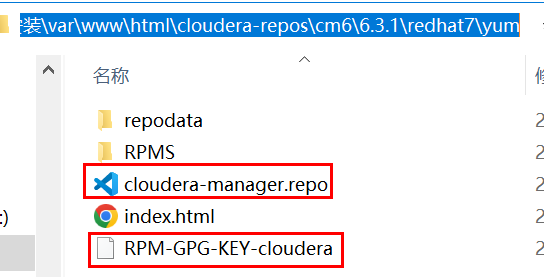
[root@node01 yum.repos.d]# cat cloudera-manager.repo
[cloudera-manager]
name=Cloudera Manager 6.3.1
baseurl=http://192.168.42.131:8900/cloudera-repos/cm6/6.3.1/redhat7/yum/
gpgkey=http://192.168.42.131:8900/cloudera-repos/cm6/6.3.1/redhat7/yum/RPM-GPG-KEY-cloudera
gpgcheck=1
enabled=1
autorefresh=0
type=rpm-md
注意:url 里面千万别写成 https,否则会报错:
[root@node01 yum.repos.d]# sudo yum install oracle-j2sdk1.8
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
https://192.168.42.131:8900/cloudera-repos/cm6/6.3.1/redhat7/yum/repodata/repomd.xml: [Errno 14] curl#35 - "SSL received a record that exceeded the maximum permissible length."
Trying other mirror.
One of the configured repositories failed (Cloudera Manager 6.3.1),
and yum doesn't have enough cached data to continue. At this point the only
safe thing yum can do is fail. There are a few ways to work "fix" this:
1. Contact the upstream for the repository and get them to fix the problem.
2. Reconfigure the baseurl/etc. for the repository, to point to a working
upstream. This is most often useful if you are using a newer
distribution release than is supported by the repository (and the
packages for the previous distribution release still work).
3. Run the command with the repository temporarily disabled
yum --disablerepo=cloudera-manager ...
4. Disable the repository permanently, so yum won't use it by default. Yum
will then just ignore the repository until you permanently enable it
again or use --enablerepo for temporary usage:
yum-config-manager --disable cloudera-manager
or
subscription-manager repos --disable=cloudera-manager
5. Configure the failing repository to be skipped, if it is unavailable.
Note that yum will try to contact the repo. when it runs most commands,
so will have to try and fail each time (and thus. yum will be be much
slower). If it is a very temporary problem though, this is often a nice
compromise:
yum-config-manager --save --setopt=cloudera-manager.skip_if_unavailable=true
failure: repodata/repomd.xml from cloudera-manager: [Errno 256] No more mirrors to try.
https://192.168.42.131:8900/cloudera-repos/cm6/6.3.1/redhat7/yum/repodata/repomd.xml: [Errno 14] curl#35 - "SSL received a record that exceeded the maximum permissible length."
4.2 安装 JDK(所有主机)
[root@node01]# cd /etc/yum.repos.d
[root@node01 yum.repos.d]# sudo rpm --import RPM-GPG-KEY-cloudera
[root@node01 yum.repos.d]# sudo yum install oracle-j2sdk1.8
[root@node01 yum.repos.d]# cat >> /etc/profile <<EOF
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export CLASSPATH=\$CLASSPATH:\$JAVA_HOME/lib:\$JAVA_HOME/jre/lib
export PATH=\$JAVA_HOME/bin:\$JAVA_HOME/jre/bin:\$PATH:\$HOMR/bin
EOF
[root@node01 yum.repos.d]# java -version
openjdk version "1.8.0_262"
OpenJDK Runtime Environment (build 1.8.0_262-b10)
OpenJDK 64-Bit Server VM (build 25.262-b10, mixed mode)
[root@node01 yum.repos.d]# source /etc/profile
[root@node01 yum.repos.d]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
4.3 安装 Mysql-5.7(主节点)
注:还有一种思路就是将 Mysql 安装在同一网段集群以外的另一台机器上(前提是有这样的条件,比如我这次安装集群只有三台服务器供调用就不符合条件),这样就可以防止当某台节点压力过大挂了后,又导致mysql挂,而mysql又是其他节点的元数据,引起都挂的情况。
# 解压 Mysql 压缩包
[root@node01 huiq]# tar xvf mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar
mysql-community-libs-5.7.27-1.el7.x86_64.rpm
mysql-community-embedded-devel-5.7.27-1.el7.x86_64.rpm
mysql-community-libs-compat-5.7.27-1.el7.x86_64.rpm
mysql-community-devel-5.7.27-1.el7.x86_64.rpm
mysql-community-embedded-compat-5.7.27-1.el7.x86_64.rpm
mysql-community-common-5.7.27-1.el7.x86_64.rpm
mysql-community-client-5.7.27-1.el7.x86_64.rpm
mysql-community-server-5.7.27-1.el7.x86_64.rpm
mysql-community-test-5.7.27-1.el7.x86_64.rpm
mysql-community-embedded-5.7.27-1.el7.x86_64.rpm
# 安装 Mysql
[root@node01 huiq]# yum -y install libaio net-tools *.rpm
# 配置 Mysql
[root@node01 huiq]# echo character-set-server=utf8 >> /etc/my.cnf
# 启动 Mysql 服务
[root@node01 huiq]# systemctl start mysqld
[root@node01 huiq]# systemctl enable mysqld
# 获取 Mysql 密码
[root@node01 huiq]# grep password /var/log/mysqld.log | sed 's/.*\(............\)$/\1/'
ru6m&lbucf#U
创建数据库并授权
mysql> show databases;
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'Xiaoqiang2023!';
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE DATABASE amon DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE DATABASE rman DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE DATABASE hue DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE DATABASE metastore DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE DATABASE sentry DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE DATABASE nav DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE DATABASE navms DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE DATABASE oozie DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
mysql> GRANT ALL ON scm.* TO 'scm'@'%' IDENTIFIED BY 'Xiaoqiang2023!@2023';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> GRANT ALL ON amon.* TO 'amon'@'%' IDENTIFIED BY 'Xiaoqiang2023!@2023';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> GRANT ALL ON rman.* TO 'rman'@'%' IDENTIFIED BY 'Xiaoqiang2023!@2023';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> GRANT ALL ON hue.* TO 'hue'@'%' IDENTIFIED BY 'Xiaoqiang2023!@2023';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> GRANT ALL ON metastore.* TO 'hive'@'%' IDENTIFIED BY 'Xiaoqiang2023!@2023';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> GRANT ALL ON sentry.* TO 'sentry'@'%' IDENTIFIED BY 'Xiaoqiang2023!@2023';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> GRANT ALL ON nav.* TO 'nav'@'%' IDENTIFIED BY 'Xiaoqiang2023!@2023';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> GRANT ALL ON navms.* TO 'navms'@'%' IDENTIFIED BY 'Xiaoqiang2023!@2023';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> GRANT ALL ON oozie.* TO 'oozie'@'%' IDENTIFIED BY 'Xiaoqiang2023!@2023';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
配置 JDBC 驱动包:
[root@node01 huiq]# tar zxvf mysql-connector-java-5.1.46.tar.gz
[root@node01 huiq]# cd mysql-connector-java-5.1.46
[root@node01 mysql-connector-java-5.1.46]# cp mysql-connector-java-5.1.46-bin.jar /usr/share/java/mysql-connector-java.jar
[root@node01 mysql-connector-java-5.1.46]# scp mysql-connector-java-5.1.46-bin.jar 10.8.0.7:/usr/share/java
[root@node01 mysql-connector-java-5.1.46]# scp mysql-connector-java-5.1.46-bin.jar 10.8.0.8:/usr/share/java
注意:这个传到其他两台服务器的时候也要改名成 mysql-connector-java.jar,要不然后面会报错:JDBC driver connot be found. Unable to find the JDBC database jar on host : node03
五、安装 Cloudera-Manager
[root@node01 huiq]# yum -y install cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server
初始化 scm 库
[root@node01 huiq]# /opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm scm 'Xiaoqiang2023!@2023'
[root@node01 huiq]# /opt/cloudera/cm/schema/scm_prepare_database.sh mysql amon amon 'Xiaoqiang2023!@2023'
[root@node01 huiq]# /opt/cloudera/cm/schema/scm_prepare_database.sh mysql rman rman 'Xiaoqiang2023!@2023'
[root@node01 huiq]# sudo /opt/cloudera/cm/schema/scm_prepare_database.sh mysql hue hue 'Xiaoqiang2023!@2023'
[root@node01 huiq]# /opt/cloudera/cm/schema/scm_prepare_database.sh mysql metastore hive 'Xiaoqiang2023!@2023'
[root@node01 huiq]# /opt/cloudera/cm/schema/scm_prepare_database.sh mysql sentry sentry 'Xiaoqiang2023!@2023'
[root@node01 huiq]# /opt/cloudera/cm/schema/scm_prepare_database.sh mysql nav nav 'Xiaoqiang2023!@2023'
[root@node01 huiq]# /opt/cloudera/cm/schema/scm_prepare_database.sh mysql navms navms 'Xiaoqiang2023!@2023'
[root@node01 huiq]# /opt/cloudera/cm/schema/scm_prepare_database.sh mysql oozie oozie 'Xiaoqiang2023!@2023'
启动 Cloudera Manager 服务
[root@node01 huiq]# sudo systemctl start cloudera-scm-server
查看日志
[root@node01 huiq]# tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log
# 出现 Started Jetty server,代表启动成功。
查看端口
[root@node01 huiq]# netstat -lntup |grep 7180
tcp 0 0 0.0.0.0:7180 0.0.0.0:* LISTEN 24801/java
六、访问 Cloudera Manager
6.1 HDFS、Yarn 开启 HA
6.1.1 HDFS开启HA
一开始的状态:
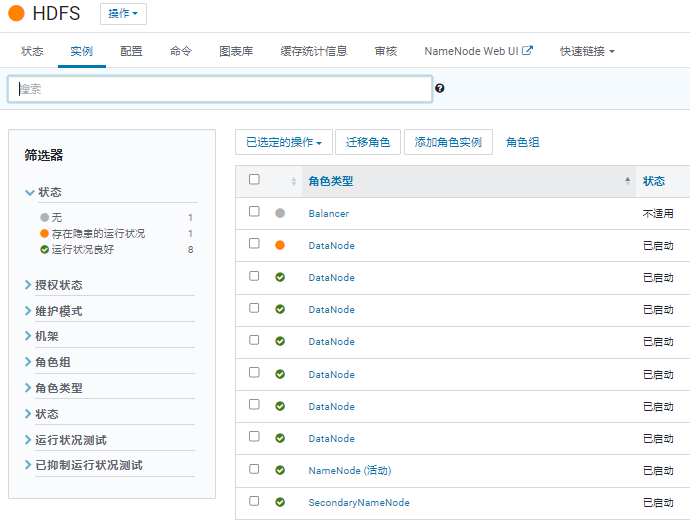
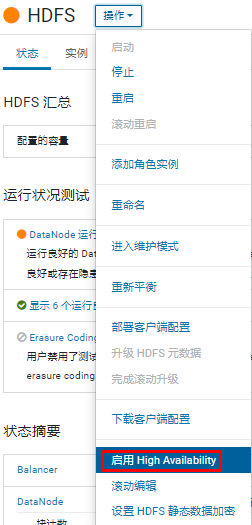
进入 hdfs 组件,在 “操作” 中启用 HA
输入 Nameservice 名称,如果公司有多个集群,Nameservice 名称不要设置重复了,Nameservice 用来标识由2个 NameNode 组成的单个 HDFS 实例。
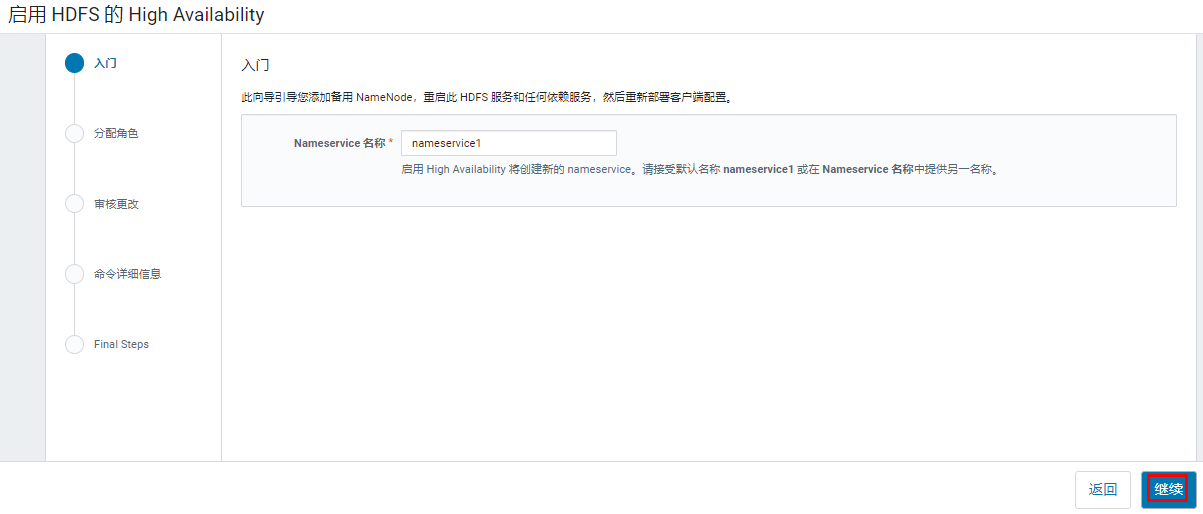
设置新 Namenode 和 JournalNode 角色运行的主机,此时已经有一台 NameNode,需要再选一台主机运行 NameNode,JournalNode 一般是3个节点。
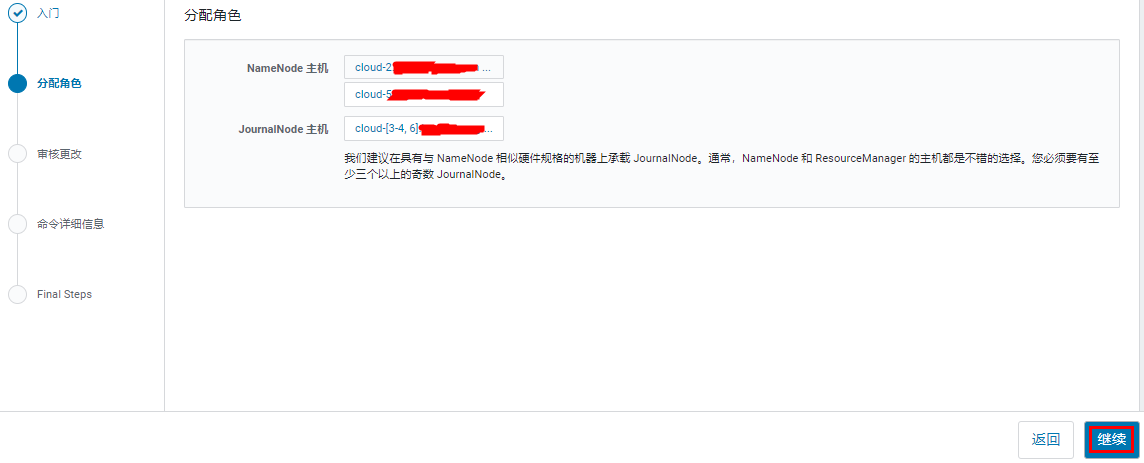
设置 NameNode 和 JournalNode 的数据目录,这里应该可以先创建一个 NameNode 的主机模板,写多个目录,来做数据目录冗余。
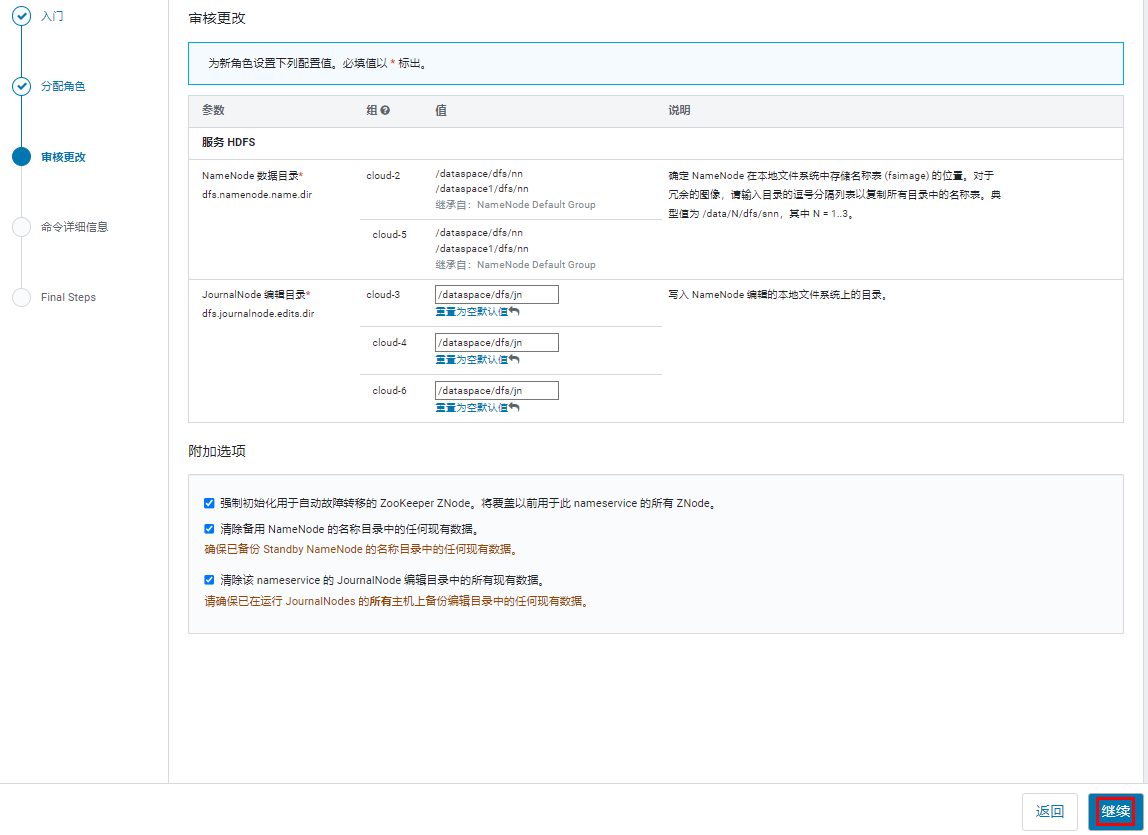
随后等待集群服务自动重启。下面这个因为原先的 NameNode 的目录已经存在了,不为空,所以告警了,但是不影响,可以继续操作。
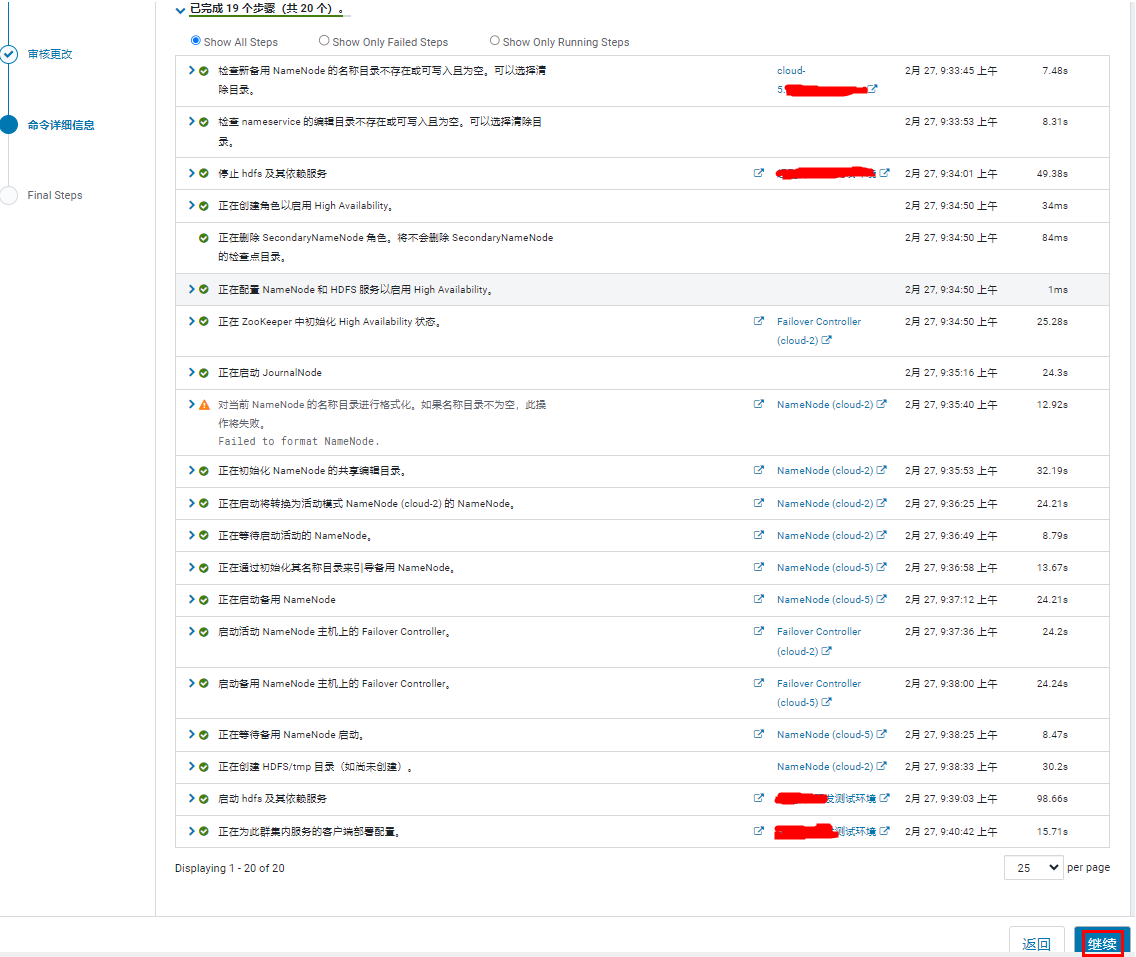
HA 开启完成。
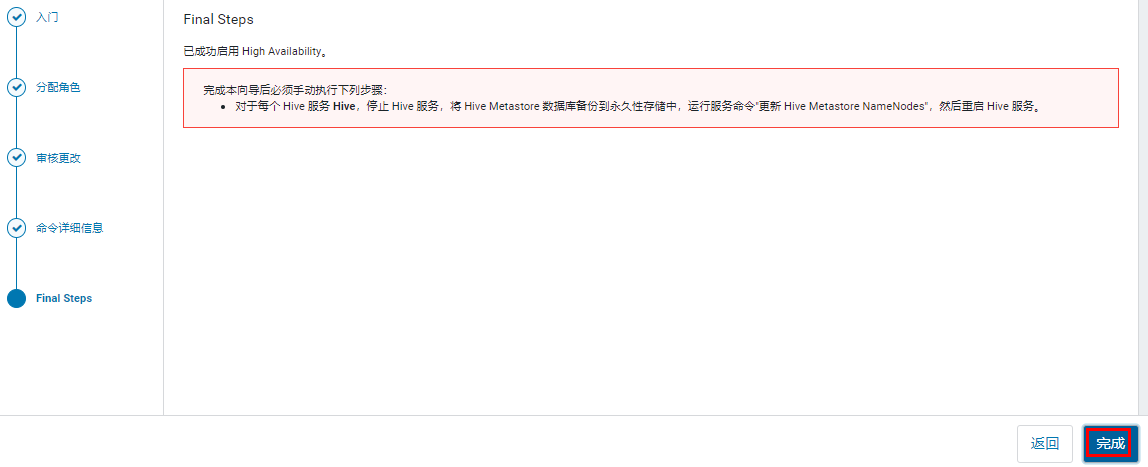
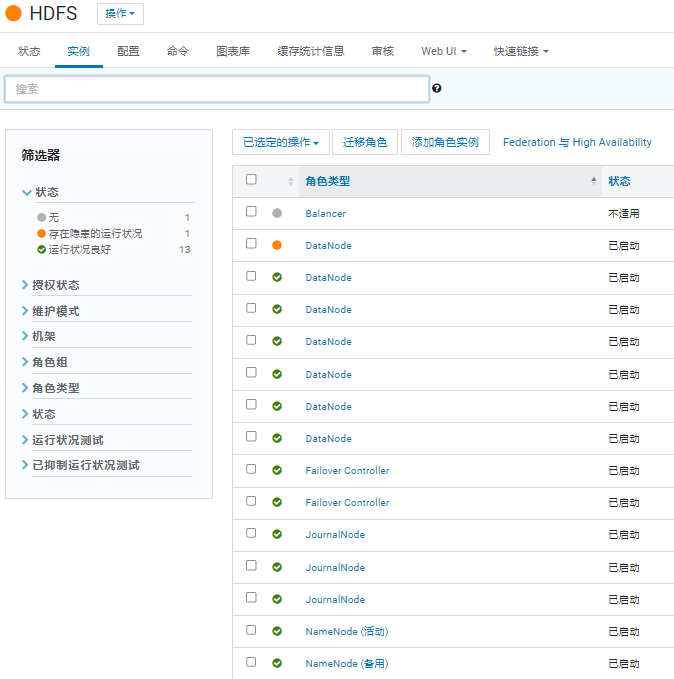
查看。
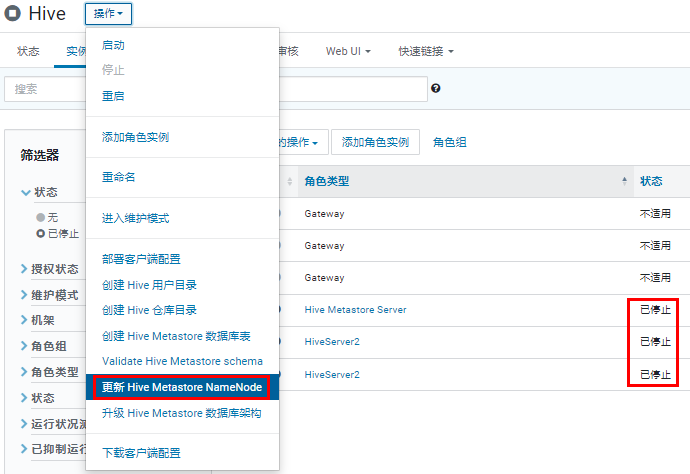
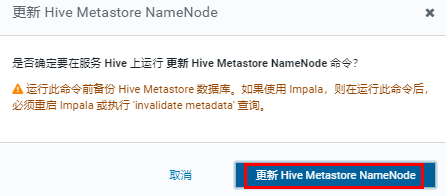
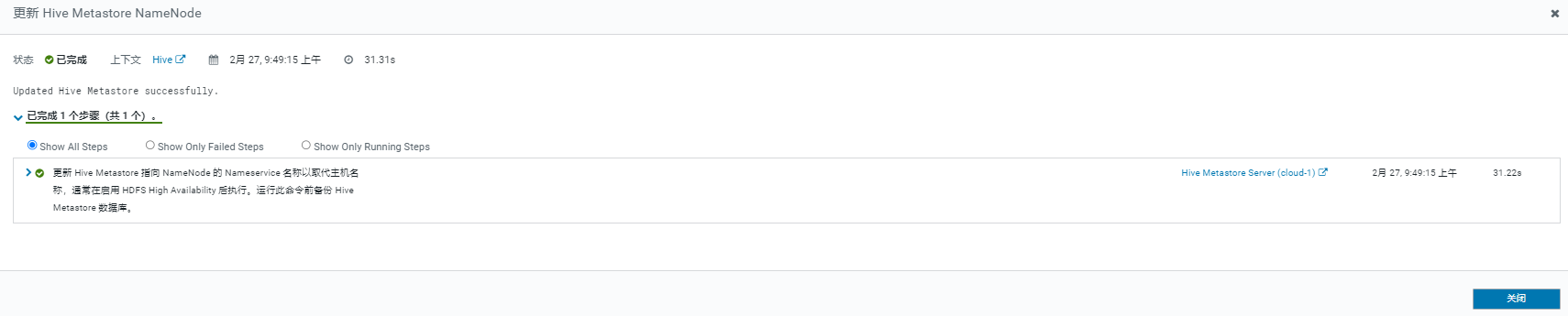
处理上面的提示,更新 Hive Metastore NameNode。
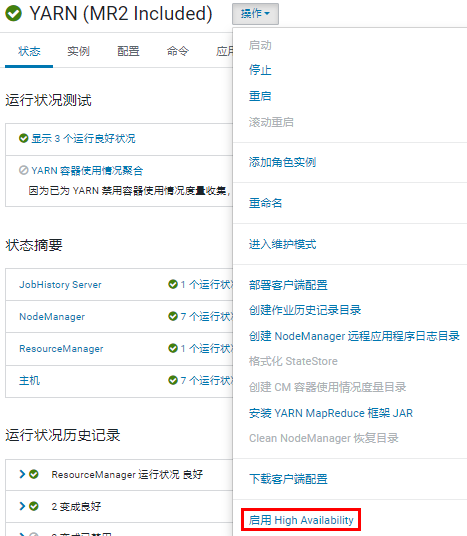
6.1.2 Yarn 开启 HA
在 yarn 组件的 “操作” 中开启 HA。
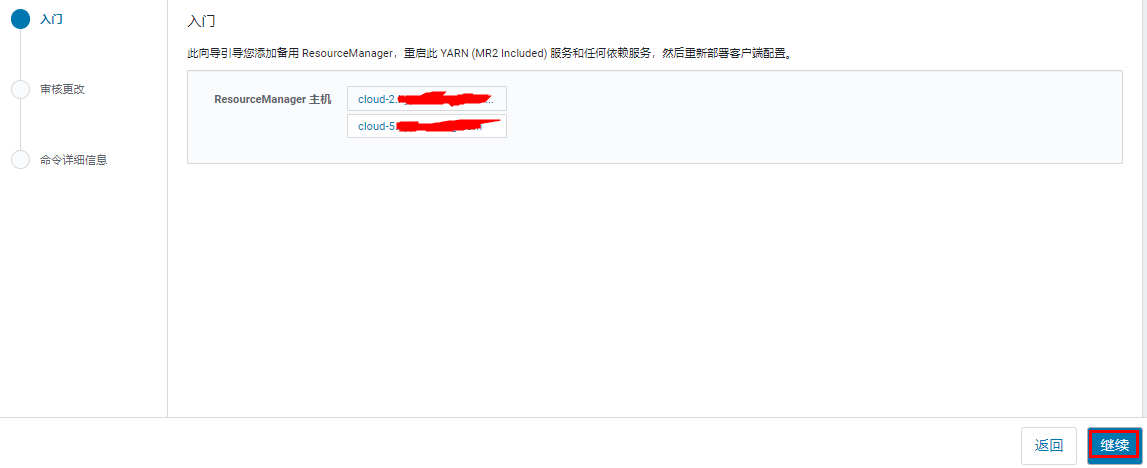
选择运行备用 ResourceManager 的主机。
等待开启完成,此过程会重启 yarn。
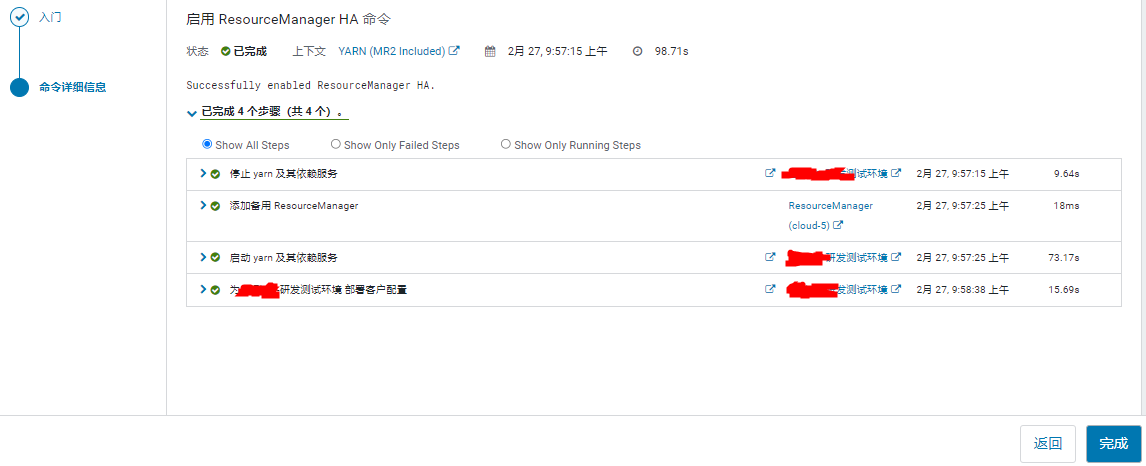
查看:
七、集群异常信息解决
7.1 不正规迁移 var 目录引起的问题
[root@node01 ~]# systemctl status mysqld
● mysqld.service - MySQL Server
Loaded: loaded (/usr/lib/systemd/system/mysqld.service; enabled; vendor preset: disabled)
Active: activating (auto-restart) (Result: exit-code) since Wed 2023-12-27 09:37:32 CST; 4ms ago
Docs: man:mysqld(8)
http://dev.mysql.com/doc/refman/en/using-systemd.html
Process: 39421 ExecStart=/usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid $MYSQLD_OPTS (code=exited, status=1/FAILURE)
Process: 39391 ExecStartPre=/usr/bin/mysqld_pre_systemd (code=exited, status=0/SUCCESS)
Dec 27 09:37:32 node01 systemd[1]: Failed to start MySQL Server.
Dec 27 09:37:32 node01 systemd[1]: Unit mysqld.service entered failed state.
Dec 27 09:37:32 node01 systemd[1]: mysqld.service failed.
7.2 不正规迁移 dfs 目录引起的问题
7.2.1 HDFS 数据存储更换目录
一开始自己折腾了半天感觉不对(一开始直接把三个目录 dfs/dn、dfs/nn、dfs/snn 一次性都修改了,但发现服务起不来,再改回去好像还是不行),后来又参考了这篇文章感觉还规范点吧:CDH集群 HDFS数据存储 更换目录,最后虽然成功更换了 HDFS 的存储目录,但是 Hbase 却一直报下面这个错。
7.2.2 HBase Master is initializing
hbase(main):005:0> count 'HEHE_T'
org.apache.hadoop.hbase.client.RetriesExhaustedException: Failed after attempts=8, exceptions:
Thu Jan 11 21:13:56 CST 2024,RpcRetryingCaller{globalStartTime=1704978836376, pause=100, maxAttempts=8}, org.apache.hadoop.hbase.NotServingRegionException: org.apache.hadoop.hbase.NotServingRegionException: HEHE_T,,1704728167655.04d0a0ad18b6d5cd5e7b8ca1745e5e08. is not online on bigdata-3,16020,1704978461112
at org.apache.hadoop.hbase.regionserver.HBegionServer.getRegionByEncodedName(HRegionServer.java:3328)
at org.apache.hadoop.hbase.regionserver.HRegionServer.getRegion(HRegionserver java:3305)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegion(RSRpcServices.java:1428)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.newRegionScanner(RSRpcServices.java:2962)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:3299)
at org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:42002)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304)
Thu Jan 11 21:13:56 CST 2024,RpcRetryingCaller{globalStartTime=1704978836376, pause=100, maxAttempts=8}, org.apache.hadoop.hbase.NotServingRegionException: org.apache.hadoop.hbase.NotServingRegionException: HEHE_T,,1704728167655.04d0a0ad18b6d5cd5e7b8ca1745e5e08. is not online on bigdata-3,16020,1704978461112
at org.apache.hadoop.hbase.regionserver.HBegionServer.getRegionByEncodedName(HRegionServer.java:3328)
at org.apache.hadoop.hbase.regionserver.HRegionServer.getRegion(HRegionserver java:3305)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegion(RSRpcServices.java:1428)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.newRegionScanner(RSRpcServices.java:2962)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:3299)
at org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:42002)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304)
......
尝试过的方法:直接删除 zookeeper 里的 hbase 目录重启 Hbase 后还是报上面的错并不好使。(参考:Hbase报错: Master is initializing,解决)
有机会可以尝试下这个解决办法:记一次服务器异常掉电,导致HBase Master is initializing 问题处理
由于目前我搭的这个集群不是正式环境,数据量不多也不重要,于是我选择了比较危险但快速的方法。一开始我是将 hdfs 上的 /hbase 目录整体移动,但发现 Master 进程起不来了,于是又移回去,只将 /hbase/data 目录移动,然后重启 Hbase 好使,只不过 Hbase 以前的所有数据都没有了需要重新来过(生产环境慎用),最直观的展现就是使用 list 命令输出结果为空,但重新建表重新插入数据不会再报上面的错了。
八、经验之谈
1. 各组件数据目录的修改
在前期安装组件的时候最好就把相应的路径修改到存储空间充足的地方,比如 /var、/tmp、/dfs 目录,一开始我安装组件的时候没管都直接默认了但后面由于前面三个目录都是在挂载到了 /dev/mapper/centos-root目录下,该目录只有50G,后面随着存储数据量的增长,最终由于存储空间不够导致集群出现了各种问题,而且在这个时候才修改相应的路径走了不少弯路也(像前面 7.1 小节),最后将相应的目录修改到了 /dev/mapper/centos-home 8T 的磁盘下,即相应的目录前面增加了 home 目录,最终效果为 /home/var、/home/tmp、/home/dfs。















 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











