






某直聘的职位信息爬取
通过搜索功能,获取搜索的url,请求搜索URL后,获取对应公司的职位信息列表,再通过职位信息列表构造职位信息的完整URL,进而请求获取职位信息详情
搜索公司
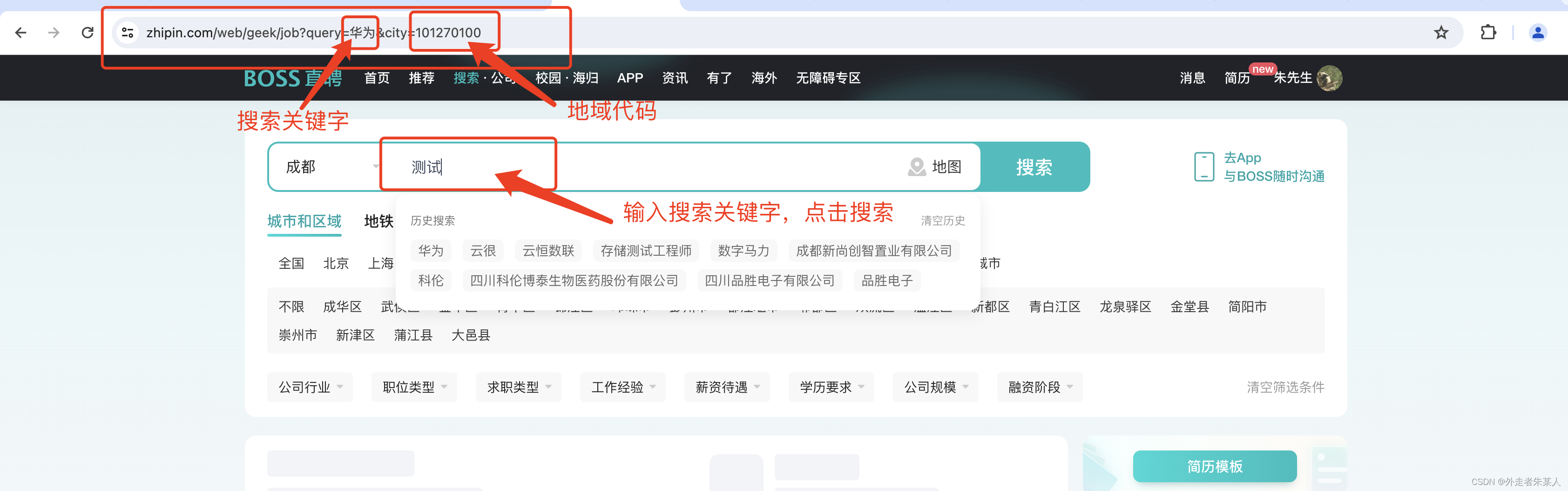
然后使用selenium进行构造后的链接请求
driver.get('https://www.zhipin.com/web/geek/job?query=华为&city=101270100')
获取到请求数据后,通过lxml的etree对获取后对数据进行解析,通过xpath工具对获取后信息进行解析。
res = driver.page_source
html = etree.HTML(res)
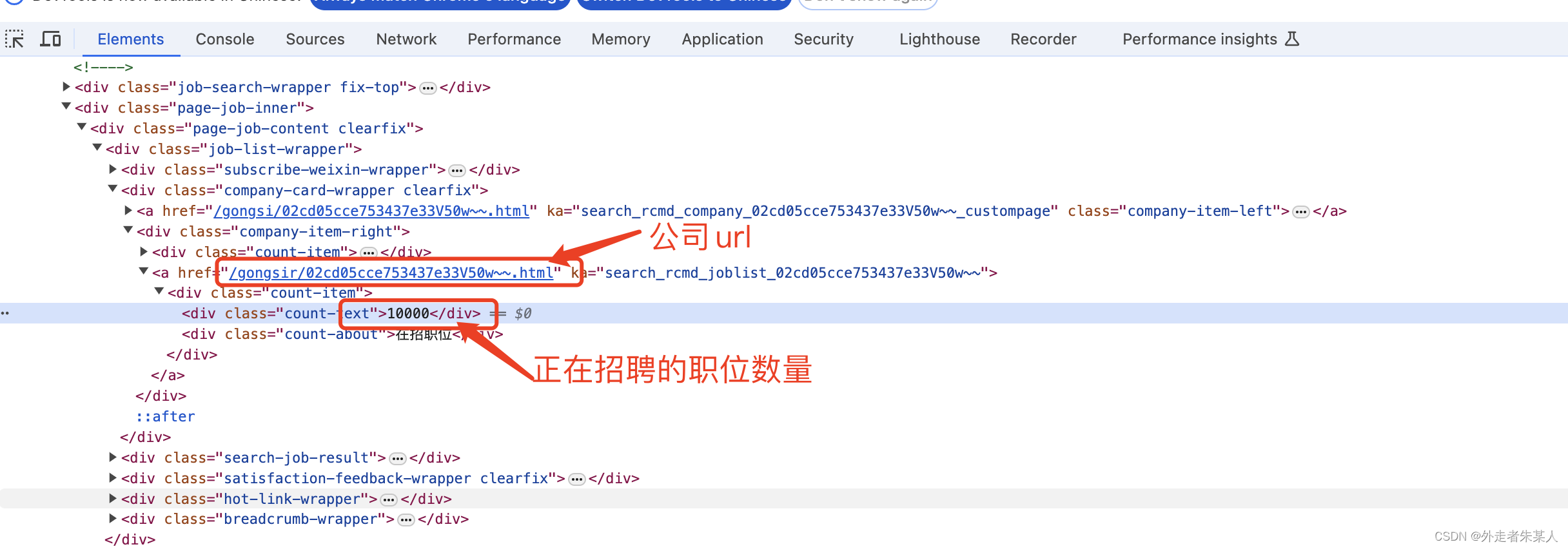
company_url = html.xpath('//div[@class="company-item-right"]/a/@href')
job_num = html.xpath('//div[@class="company-item-right"]/a/div[@class="count-item"]/div[@class="count-text"]/text()')
其中的company_url是拿到对应的公司的职位信息链接。job_num拿到的是该公司正在招聘的职位个数
职位详情获取
上一步中,拿到了公司url后,使用浏览器请求后,能发现公司正在招聘的职位详情,包括职位名称,职位要求,技能描述等
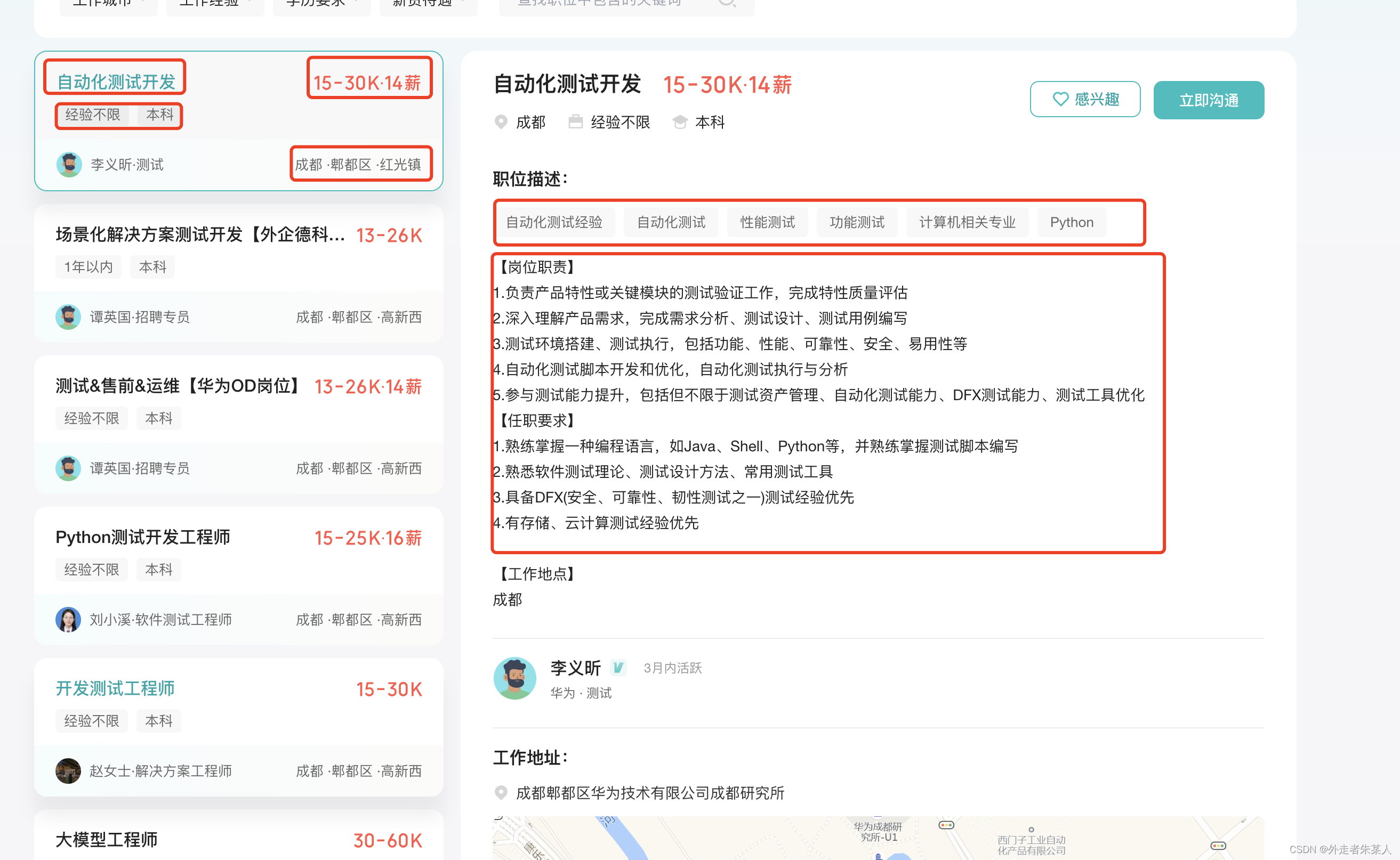
这个时候你会发现这只是第一页的职位信息,打开控制台,通过点击翻页操作,能看到对应职位信息的接口。
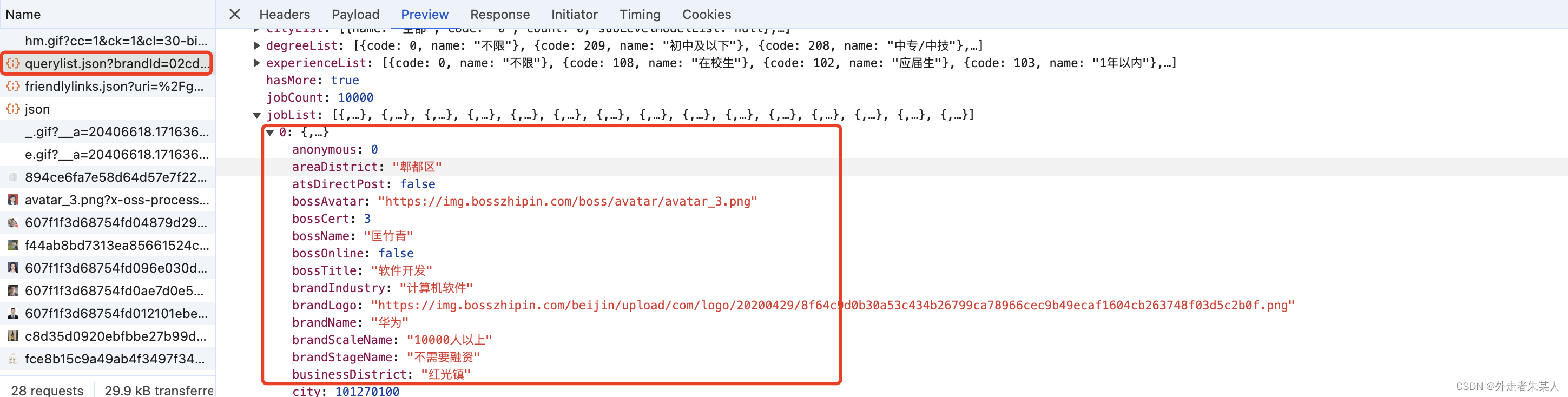
看到职位信息接口后,分析接口的参数构造。https://www.zhipin.com/wapi/zpgeek/brand/job/querylist.json?brandId=02cd05cce753437e33V50w~~&page=2&pageSize=15&positionLv1=&city=°ree=&experience=&salary=&query=
get请求,其中有个一个brandId的参数代表第一步中获取公司链接里面的类似公司Id,page为当前的页数,pageSize为每页展示的数量。则只需要通过解析公司url地址获取公司Id,再通过全部职位数量除以每页展示的数量,计算得出总的页数。
company_id = company_url[0].split('/')[-1].split('.')[0]
pages = int(int(job_num) / 15) + 1
最后通过构造url,得到每页的职位信息的接口连接,使用requests请求即可。
url = "https://www.zhipin.com/wapi/zpgeek/brand/job/querylist.json?brandId={}&page={}&pageSize=15&positionLv1=&city=°ree=&experience=&salary=&query=".format(company_id,page)
最后就是解析接口返回的数据。
岗位要求信息获取
通过上一步的接口请求操作,会发现接口里面并没有岗位要求,岗位描述这些信息。这个时候,单击任意一个职位进去后,会发现请求的连接里面有一个职位id,与上一步的接口返回的数据里面保持一致
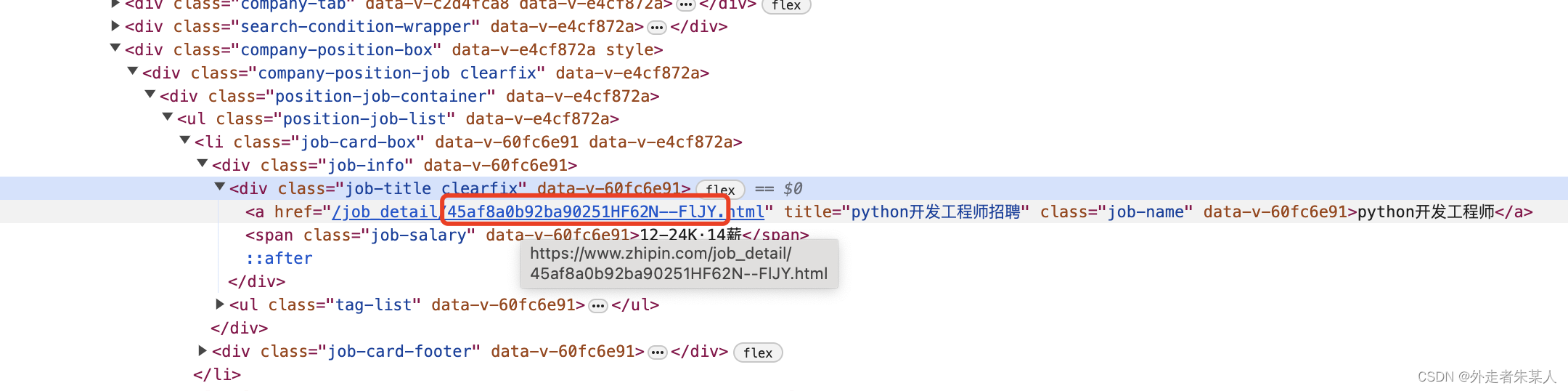
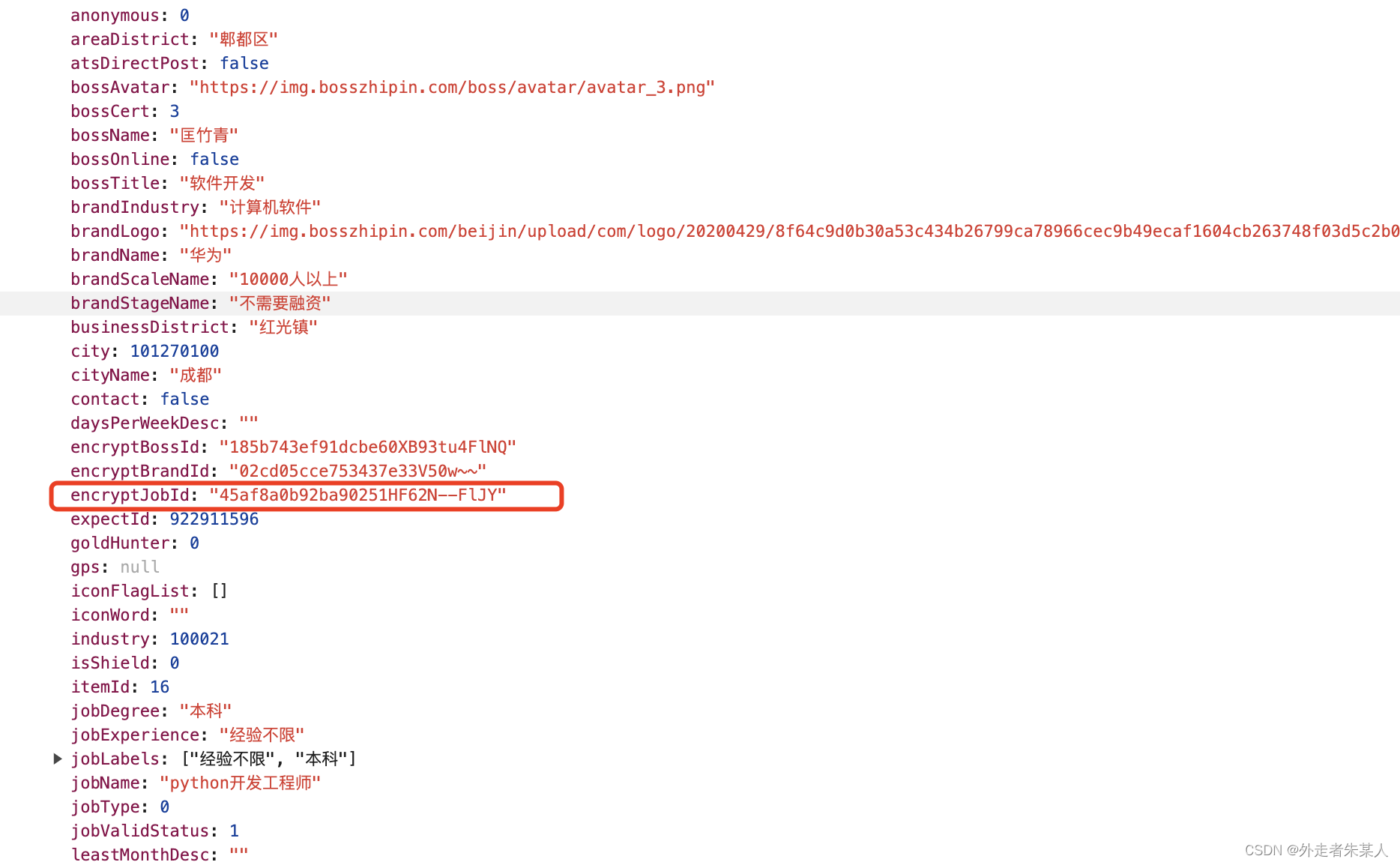
所以通过上一步的接口数据的解析,获取到职位id后,再进行url的拼接,获取到完整的职位信息链接后,再使用
selenium进行请求,获取到职位详情。
job_url = "https://www.zhipin.com/job_detail/{}.html".format(job["encryptJobId"])
driver.get(job_url)
time.sleep(5)
res = driver.page_source
html = etree.HTML(res)
job_sub = '\n'.join(html.xpath("//div[@class='job-sec-text']/text()"))
完整代码展示
from selenium import webdriver
import time
import requests
from lxml import etree
driver = webdriver.Chrome()
driver.get('https://www.zhipin.com/web/geek/job?query=华为&city=101270100')
time.sleep(5)
title = driver.title
res = driver.page_source
html = etree.HTML(res)
company_url = html.xpath('//div[@class="company-item-right"]/a/@href')
job_num = html.xpath('//div[@class="company-item-right"]/a/div[@class="count-item"]/div[@class="count-text"]/text()')
if job_num:
job_num = job_num[0]
if company_url:
company_id = company_url[0].split('/')[-1].split('.')[0]
pages = int(int(job_num) / 15) + 1
for page in range(1, pages + 1):
company_url_info = "https://www.zhipin.com" + company_url[0] + "?page=" + str(page)
url = "https://www.zhipin.com/wapi/zpgeek/brand/job/querylist.json?brandId={}&page={}&pageSize=15&positionLv1=&city=°ree=&experience=&salary=&query=".format(company_id,page)
payload = {}
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9',
'priority': 'u=1, i',
'referer': company_url_info,
'sec-ch-ua': '"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
}
response = requests.request("GET", url, headers=headers, data=payload)
data = response.json()
job_info = html.xpath("//ul[@class='position-job-list']/li")
for job in data["zpData"]["jobList"]:
job_url = "https://www.zhipin.com/job_detail/{}.html".format(job["encryptJobId"])
driver.get(job_url)
time.sleep(5)
res = driver.page_source
html = etree.HTML(res)
job_sub = '\n'.join(html.xpath("//div[@class='job-sec-text']/text()"))
print(job_sub)
job_name = job["jobName"]
salary = job["salaryDesc"]
experience = job["jobExperience"]
education = job["jobDegree"]
print(job_name, salary, experience, education, job_url)
else:
job_num = 0
代码获取
我会把完整的代码打包上传到gitee平台中,有需要的同学可以下载下来尝试一下。
git@gitee.com:fridge1/spider.git

















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









