






逻辑回归解决的是分类问题,它的本质是给了
X,y,来求解θ
,和线性回归很像。逻辑回归也是
Xθ
进行预测,预测的值可以理解为概率,在0~1之间,比如可以将>0.5的值归为1,<0.5的归为0。
总之,逻辑回归和线性回归都是为了得到
θ
(
θ
是个香饽饽~),得到了之后,一个用来分类,一个用来预测。下面详解。
逻辑回归
比如打算把一群sample分成2类,分别用0,1代表负样本和正样本,即
y⊂
{0, 1},那么之前的
h(x)
就显得不那么合适了,因为他可能会得到任意值,为了使
h(x)⊂[0,1]
,就需要对它进行变形。
令
h(x)=g(θTx)=11+e−θTx
,其中
g(x)
如下图所示:
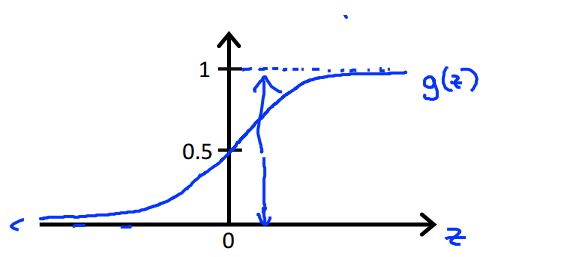
这样,
h(x)
就回到了[0,1]之间,就可以用差的平方计算
J(θ)
,如下
J(θ)=1m∑mi=112(hθ(x(i))−y(i))2(1)
但是由于新的
h(x)
的原因,
J(θ)
是非凸函数(左下图),我们想得到凸函数(右下图):
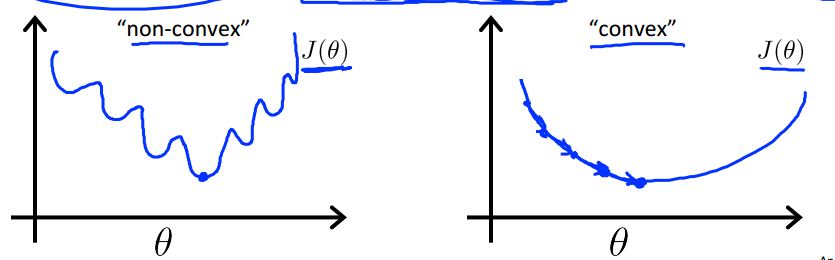
这样梯度下降很可能落到局部最优点中。
为了解决这个问题,我们将
J(θ)
变成
意义如下图所示:
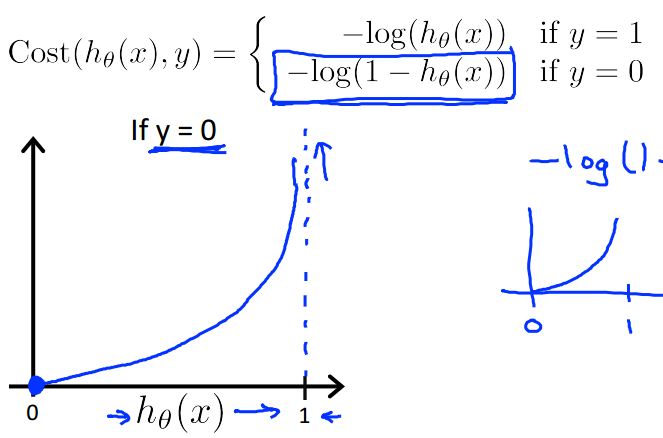
就是说,如果预测了1但结果是0,就会有很大的代价,造成
J(θ)
很大;另一种情况同理。
我们知道,我们的目的是为了通过
θ
的变化让
J
变得尽量小,所以梯度下降的新
θ
如下所示,这里其实是整个算法的核心。
这里我没有仔细推公式,有怀疑利用新的
J(θ)
得到的
θ
的梯度真的张这个样子?因为如果终止条件是迭代次数的话,最最重要的就是
θ
的变化。
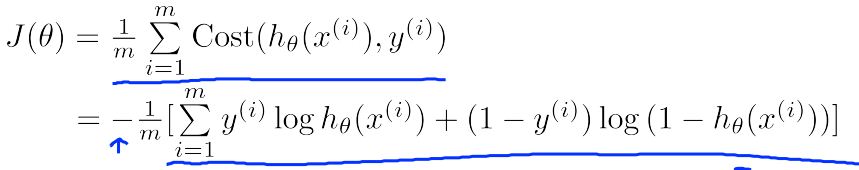

关于决策边界
实际上就是 θx=y 得到的线,既然参数 θ 得到了,自然可以画出线来,就像让你画 y=ax+b 已知a,b一样。
多分类问题
利用逻辑回归如何解决多分类问题?
其实思路很简单,比如现在要分成3个类,那么就训练出3个
h(x),也就是3个θ
,最后有新的数据来了分别带入,看看哪个的
h(x)
(概率)更高。
正则项
为了防止过拟合,如下图
最左边的是欠拟合,也就是说得到的
J
会比较大;中间的不错,嗯;最右边的就是过拟合了,从训练数据的
J
看上去很理想,但是对于新的一组数据,其并不能有这么好的效果。
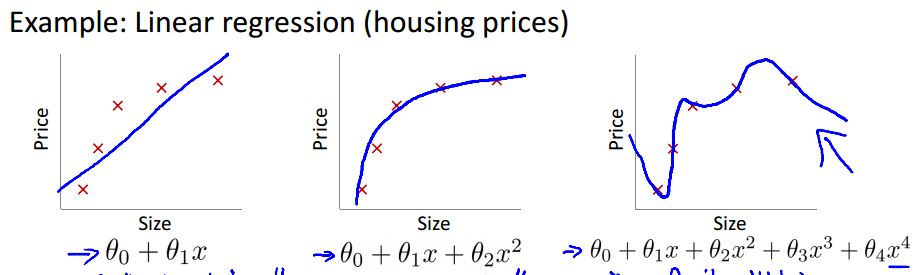
为了解决这个问题,就应该尽量让后面的高次项小一些,这样图像看上去会“正常”些。
对于线性回归,可以给
J
加上正则项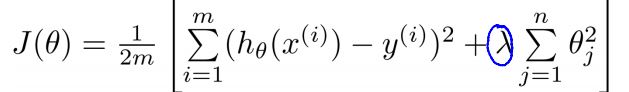
直观的理解就是如果后面的权重大的话,会贡献更大的代价,其新的
θ
如下
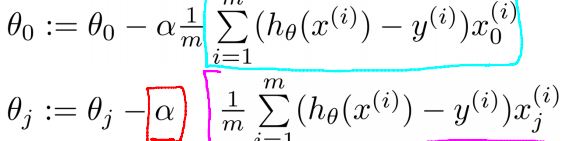
如果以迭代次数为终止条件,这是最最重要的一步,因为此时
J
只是顺带计算一下让我们看看下降的效果。
对于逻辑回归来说,
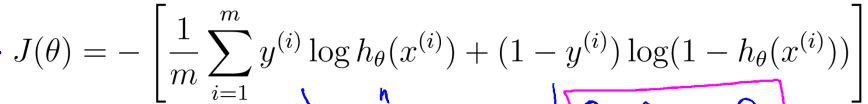
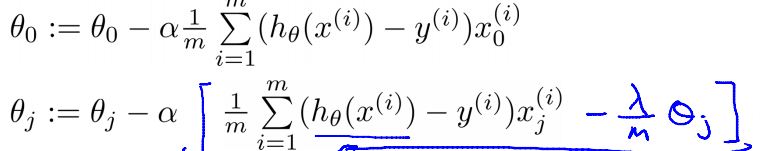
总结
其实逻辑回归与线性回归算法过程很相似,一个用预测值分类,一个用预测值预测。
下面以带正则项的逻辑回归为例,附上主要过程:
while(满足迭代条件){
计算 θnew
计算 J(θ)
}















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









