










sparkSubmit
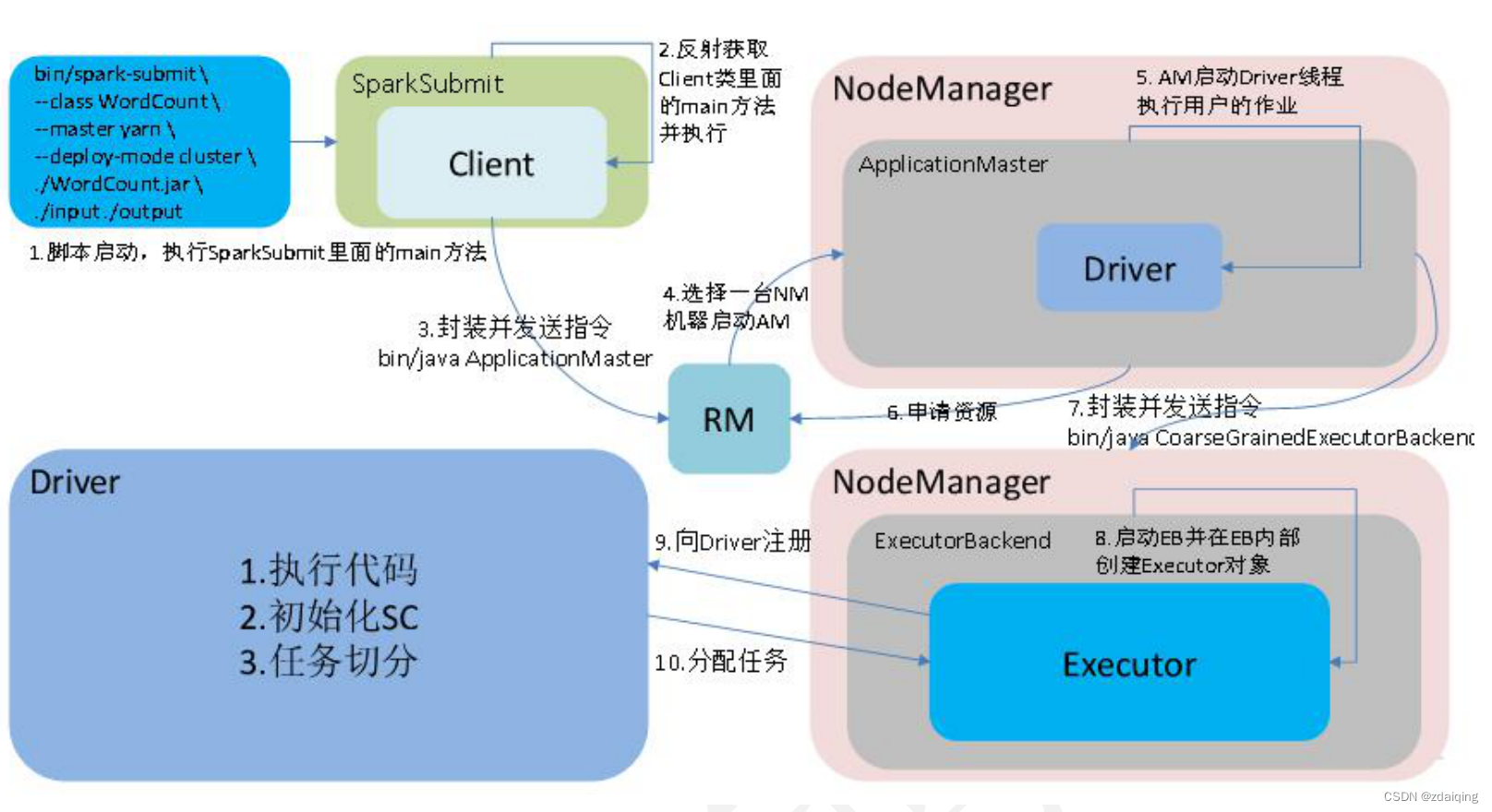
1.spark-cluster任务提交流程图
2.sparkSubmit源码
2.1.main
启动sparkSubmit的JVM进程后,调用sparkSubmit伴生对象的main方法;
object SparkSubmit extends CommandLineUtils with Logging {
override def main(args: Array[String]): Unit = {
//实例化sparkSubmit对象
val submit = new SparkSubmit() {
self =>
//重写参数解析方法
override protected def parseArguments(args: Array[String]): SparkSubmitArguments = {
//封装spark提交参数
new SparkSubmitArguments(args) {
override protected def logInfo(msg: => String): Unit = self.logInfo(msg)
override protected def logWarning(msg: => String): Unit = self.logWarning(msg)
}
}
override protected def logInfo(msg: => String): Unit = printMessage(msg)
override protected def logWarning(msg: => String): Unit = printMessage(s"Warning: $msg")
//重写doSubmit方法
override def doSubmit(args: Array[String]): Unit = {
try {
//调用SparkSubmit的doSubmit方法
super.doSubmit(args)
} catch {
case e: SparkUserAppException =>
exitFn(e.exitCode)
}
}
}
//调用重写后的doSubmit
submit.doSubmit(args)
}
}
2.1.1.SparkSubmitArguments spark提交参数类
该类用于封装spark提交时的参数;
通过解析命令行、默认配置文件、env中的参数,使用以spark.开头的参数填充对象属性值;保证重要参数不为空;
private[deploy] class SparkSubmitArguments(args: Seq[String], env: Map[String, String] = sys.env)
extends SparkSubmitArgumentsParser with Logging {
//以下时支持封装的参数
var master: String = null
var deployMode: String = null
var executorMemory: String = null
var executorCores: String = null
var totalExecutorCores: String = null
var propertiesFile: String = null
var driverMemory: String = null
var driverExtraClassPath: String = null
var driverExtraLibraryPath: String = null
var driverExtraJavaOptions: String = null
var queue: String = null
var numExecutors: String = null
var files: String = null
var archives: String = null
var mainClass: String = null
var primaryResource: String = null
var name: String = null
var childArgs: ArrayBuffer[String] = new ArrayBuffer[String]()
var jars: String = null
var packages: String = null
var repositories: String = null
var ivyRepoPath: String = null
var ivySettingsPath: Option[String] = None
var packagesExclusions: String = null
var verbose: Boolean = false
var isPython: Boolean = false
var pyFiles: String = null
var isR: Boolean = false
var action: SparkSubmitAction = null
val sparkProperties: HashMap[String, String] = new HashMap[String, String]()
var proxyUser: String = null
var principal: String = null
var keytab: String = null
private var dynamicAllocationEnabled: Boolean = false
// Standalone cluster mode only
var supervise: Boolean = false
var driverCores: String = null
var submissionToKill: String = null
var submissionToRequestStatusFor: String = null
var useRest: Boolean = false // used internally
//解析spark提交时的命令行参数
parse(args.asJava)
//解析spark 默认参数文件中的参数
mergeDefaultSparkProperties()
//从sparkProperties中移除不是以spark.开头的参数
ignoreNonSparkProperties()
//从sparkProperties和env中获取数据填充SparkSubmitArguments对象的属性值,没有的置空
loadEnvironmentArguments()
//重要参数校验
validateArguments()
}
2.2.SparkSubmit.doSubmit方法
private[spark] class SparkSubmit extends Logging {
def doSubmit(args: Array[String]): Unit = {
//初始化日志记录;同时标记日志记录是否需要在应用程序启动之前重置
val uninitLog = initializeLogIfNecessary(true, silent = true)
//调用main方法中实例化sparkSubmit对象时重写的参数解析方法,解析并封装spark提交参数
val appArgs = parseArguments(args)
if (appArgs.verbose) {
logInfo(appArgs.toString)
}
appArgs.action match {
//提交逻辑
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
case SparkSubmitAction.PRINT_VERSION => printVersion()
}
}
}
2.3.SparkSubmit.submit
调用SparkSubmit.runMain方法;
private[spark] class SparkSubmit extends Logging {
private def submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
//定义包含针对代理者的runMain方法
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(args, uninitLog)
}
})
} catch {
case e: Exception =>
if (e.getStackTrace().length == 0) {
error(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
} else {
throw e
}
}
} else {
//调用SparkSubmit.runMain方法;
runMain(args, uninitLog)
}
}
if (args.isStandaloneCluster && args.useRest) {
try {
logInfo("Running Spark using the REST application submission protocol.")
doRunMain()
} catch {
case e: SubmitRestConnectionException =>
logWarning(s"Master endpoint ${args.master} was not a REST server. " +
"Falling back to legacy submission gateway instead.")
args.useRest = false
submit(args, false)
}
} else {
doRunMain()
}
}
}
2.4.SparkSubmit.runMain
准备环境
根据main Class构造SparkApplication
启动SparkApplication
private[spark] class SparkSubmit extends Logging {
private def runMain(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
//准备提交申请的环境
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
//让主类在启动日志系统后重新初始化日志系统
if (uninitLog) {
Logging.uninitialize()
}
if (args.verbose) {
logInfo(s"Main class:\n$childMainClass")
logInfo(s"Arguments:\n${childArgs.mkString("\n")}")
// sysProps may contain sensitive information, so redact before printing
logInfo(s"Spark config:\n${Utils.redact(sparkConf.getAll.toMap).mkString("\n")}")
logInfo(s"Classpath elements:\n${childClasspath.mkString("\n")}")
logInfo("\n")
}
//开启类加载器线程
val loader =
if (sparkConf.get(DRIVER_USER_CLASS_PATH_FIRST)) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
//加载jar包
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
var mainClass: Class[_] = null
try {
//通过反射实例化mainClass类
//yarn-cluster模式下,mainClss=org.apache.spark.deploy.yarn.YarnClusterApplication
mainClass = Utils.classForName(childMainClass)
} catch {
case e: ClassNotFoundException =>
logWarning(s"Failed to load $childMainClass.", e)
if (childMainClass.contains("thriftserver")) {
logInfo(s"Failed to load main class $childMainClass.")
logInfo("You need to build Spark with -Phive and -Phive-thriftserver.")
}
throw new SparkUserAppException(CLASS_NOT_FOUND_EXIT_STATUS)
case e: NoClassDefFoundError =>
logWarning(s"Failed to load $childMainClass: ${e.getMessage()}")
if (e.getMessage.contains("org/apache/hadoop/hive")) {
logInfo(s"Failed to load hive class.")
logInfo("You need to build Spark with -Phive and -Phive-thriftserver.")
}
throw new SparkUserAppException(CLASS_NOT_FOUND_EXIT_STATUS)
}
//根据mainClass类实例化application
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.newInstance().asInstanceOf[SparkApplication]
} else {
// SPARK-4170
if (classOf[scala.App].isAssignableFrom(mainClass)) {
logWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
new JavaMainApplication(mainClass)
}
@tailrec
def findCause(t: Throwable): Throwable = t match {
case e: UndeclaredThrowableException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: InvocationTargetException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: Throwable =>
e
}
try {
//调用application的start方法
//yarn-cluster模式下,调用org.apache.spark.deploy.yarn.YarnClusterApplication类的start方法
app.start(childArgs.toArray, sparkConf)
} catch {
case t: Throwable =>
throw findCause(t)
}
}
}
2.4.1.mainClass的确定
sparkSubmit.runMain()—>SparkSubmit.prepareSubmitEnvironment()—>SparkSubmit.YARN_CLUSTER_SUBMIT_CLASS
private[spark] class SparkSubmit extends Logging {
private def runMain(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
}
private[deploy] def prepareSubmitEnvironment(
args: SparkSubmitArguments,
conf: Option[HadoopConfiguration] = None)
: (Seq[String], Seq[String], SparkConf, String) = {
if (isYarnCluster) {
childMainClass = YARN_CLUSTER_SUBMIT_CLASS
}
}
}
object SparkSubmit extends CommandLineUtils with Logging {
private[deploy] val YARN_CLUSTER_SUBMIT_CLASS =
"org.apache.spark.deploy.yarn.YarnClusterApplication"
}
3.sparkSubmit总结
解析命令行、默认配置文件、env中参数;
准备提交application的环境;
获取main Class,反射构造SparkApplication,启动SparkApplication;
4.参考资料
spark源码之任务提交流程
Spark源码系列(一):Spark作业提交流程
spark提交流程-源码分析
Spark内核之YARN Cluster模式源码详解(Submit详解)
Spark源码解析之——YARN Cluster模式















 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









