







24ORDER: OpenWorld Object Detection on Road Scenes

发表于NeurIPS 2021
Code: 没有
摘要
对象检测是自主导航系统中的一个关键组件,可以对道路场景中的对象进行定位和分类。现有的目标检测方法是根据道路场景中存在的固定数量的已知类别进行训练和推断的。然而,在现实世界或开放世界的道路场景中,在推理时,我们会遇到检测模型在训练时没有看到的未知对象。因此,我们提出道路场景的开放世界对象检测(ORDER)来解决上述道路场景的问题。
- 首先,我们引入 Feature-Mix 来提高目标检测器的未知目标检测能力。 Feature-Mix 扩大了潜在特征空间中已知类和未知类之间的差距,有助于改进未知对象检测。
- 接下来,我们发现与通用对象数据集相比,道路场景数据集包含大量小对象,并且具有更高的类内边界框尺度变化,这使得检测已知和未知对象具有挑战性。
- 我们提出了一种新颖的损失:焦点回归损失,通过惩罚更多的小边界框并根据对象大小动态改变损失,来共同解决小目标检测和类内边界框的问题。此外,通过curriculum学习改进了小物体的检测。
介绍
大背景
OWOD问题
小背景
我们发现 ORE 框架在应用于具有挑战性的领域(例如道路场景数据集)时表现不佳。挑战包括: a) 未知物体难以检测; b)小对象(来自已知和未知集合)的比例很重要(图 1 [b]),以及 c)存在类内尺度变化(图 1 [a])。在道路场景数据集中发现类内尺度变化的问题非常明显。诸如 MS-COCO 和 PASCAL-VOC 之类的通用数据集由靠近对象捕获的图像组成,从而导致规模变化较小。类似地,在航空目标检测数据集 [28] 中,目标是在明显的高海拔地区捕获的,从而导致一致的类内目标大小。

图 1:(a):我们可以在汽车和行人类别等一些类别中显着观察到类内和类间的尺度变化。 这个问题在道路场景数据集中很突出。(b):显示 BDD 和 IDD 中边界框区域的分布,我们注意到小边界框比大边界框相对更多。
解决办法
我们提出了解决上述问题的道路场景开放世界对象检测 (ORDER)。
- 我们引入了受 Open-Mix [30] 启发的 Feature-Mix,在其中我们结合了多个未知和已知类实例来改进未知对象识别。需要注意的是,Open-Mix 采用已知和未知的单个实例,因此,它不能组合通常存在于道路场景中的多个未知和已知类实例。 Feature-Mix 通过在特征级别混合未知和已知类实例来克服 Open-Mix 的限制,允许它混合已知和未知类的多个实例。
- 接下来,我们提出了通过包含边界框区域来处理类内变化的焦点回归损失,并通过对小边界框的惩罚多于对大边界框的惩罚来改进小目标检测。我们通过以curriculum方式训练 ORDER 框架来进一步改进小目标检测。改进小目标检测和处理类内变化减少了已知类被检测为未知的机会,并改进了已知目标检测。
方法
ORDER 使用 Faster-RCNN [7] 检测器,该检测器被相应地模制以检测已知和未知物体。 它由三个输出头组成:基于能量的分类头、焦点回归头和特征混合头。 基于能量的分类头和焦点回归头用于通过使用 L c l f L_{clf} Lclf 和 L u n k L_{unk} Lunk 来学习区分已知和未知特征。 焦点回归头学习对象边界框。 图 2 显示了 ORDER 框架的管道。 ORDER 框架的灵感来自 ORE [10],但是,它在我们为处理道路场景数据集中存在的挑战而引入的新组件方面有很大不同。 我们将详细讨论 ORDER 框架的关键创新。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5zdy60iQ-1652850941062)(http://qiniu.ruixu.top/1650372454653----24ORDER-OpenWorld%20Object%20Detection%20on%20Road%20Scenes.png)]](https://img-blog.csdnimg.cn/5294e24239ab455f9886c59f464c6f6e.png)
Feature-Mix
我们提出了一种特征混合方法,通过结合已知类的知识来改进未知类的识别。 Feature-Mix 背后的关键直觉是混合已知和未知的特征,并抑制已知特征引起的激活,从而最大化已知和未知特征之间的潜在差异。
我们通过使用感兴趣区域 (RoI) 池化输出特征 f f f 来开始特征混合公式,该输出特征 f f f 由已知类特征 f k f_{k} fk 和未知类特征 f unk f_{\text {unk }} funk 组成。我们通过以下方式混合已知和未知特征:
f mix = λ f k + ( 1 − λ ) f unk , f_{\text {mix }}=\lambda f_{k}+(1-\lambda) f_{\text {unk }}, fmix =λfk+(1−λ)funk ,
其中 λ \lambda λ从用 α \alpha α 和 β \beta β 参数化的 beta distribution中采样。
beta distribution是啥子?
现在,未知分类器 C unk C_{\text {unk }} Cunk 利用 f mix f_{\text {mix }} fmix 来识别通过使用损失 L unk L_{\text {unk }} Lunk 训练的未知对象:
L u n k = − y log ( softmax ( C u n k ( f m i x ) ) ) y = argmax ( log ( softmax ( C u n k ( f m i x ) ) ) ) L_{un k}=-y \log \left(\operatorname{softmax}\left(C_{un k}\left(f_{m i x}\right)\right)\right) \\ y=\operatorname{argmax}\left(\log \left(\operatorname{softmax}\left(C_{un k}\left(f_{m i x}\right)\right)\right)\right) Lunk=−ylog(softmax(Cunk(fmix)))y=argmax(log(softmax(Cunk(fmix))))
y y y 代表真实标签。我们使用一个小的保留验证集,如 ORE [10] 中提出的,由已知和未知的数据样本组成来训练 Feature-Mix。
这种训练得时候看过未知类还是挺奇怪得哈?应该在完全未知的类上再测一下,这样比较有说服力。
Focal Regression Loss
流行的检测方法使用 Smooth-L1 [20] 和 Generalized Intersection over Union (GIoU) [21] loss 进行边界框回归。然而,这些损失并没有明确地包含道路场景数据集中突出的类内尺度变化的知识。我们引入了焦点回归损失 ( L f R e g ) \left(L_{f R e g}\right) (LfReg),它解决了以下问题:a) 通过对小边界框进行更多惩罚来检测小物体 b) 通过包含边界框信息来进行类内变化。
我们通过将调节分量 ( 1 − I o U ) γ ∗ (1-I o U)^{\gamma^{*}} (1−IoU)γ∗ 添加到平方 I o U I o U IoU 损失来制定 L f R e g L_{f R e g} LfReg,其中 γ ∗ ∈ [ 0 , ∞ ) \gamma^{*} \in[0, \infty) γ∗∈[0,∞) 是一个聚焦参数。 L f R e g L_{f Re g} LfReg 可以表示为:
L f R e g = ( 1 − I o U ) γ ∗ ∥ 1 − I o U ∥ 2 2 L_{f R e g}=(1-I o U)^{\gamma^{*}}\|1-I o U\|_{2}^{2} LfReg=(1−IoU)γ∗∥1−IoU∥22
A r b b o x x g t ^ \hat{A r_{b b o x x_{gt}}} Arbboxxgt^ 和 A r b b o x A r_{b b o x} Arbbox 分别表示逆归一化和非归一化边界框区域。逆归一化为小边界框提供大值,为大边界框提供小值。 A r b b o x ^ \hat{A r_{b b o x}} Arbbox^ 将图像区域 A r I m g A r_{I m g} ArImg 除以 A r b b o x g t ⋅ γ ∗ A r_{b b o x_{g t}} \cdot \gamma^{*} Arbboxgt⋅γ∗ 由可调参数 γ \gamma γ 和逆归一化边界框区域的双对数。我们将双对数应用于逆归一化边界框区域,因为 a) 当逆归一化边界框区域很小时,它可以防止 γ ∗ \gamma^{*} γ∗ 的过冲,b) 它可以平滑逆归一化边界框的变化区域使训练更加稳定。请注意,对于小边界框, γ ∗ \gamma^{*} γ∗ 的值会很高,与易于检测的大边界框相比,会导致更多的惩罚。
Curriculum Training
检测较小的对象 [9] 比检测具有较大尺寸的对象实例更难。在 BDD 和 IDD 等自主导航数据集中,小物体的比例非常重要。 1. 根据[24],较小的对象被认为比较大的对象更难学习。因此,我们采用课程学习 [ 1 ; 6 ] [1 ; 6] [1;6] 策略逐步训练网络从简单样本(大对象)到困难样本(小对象)。我们根据边界框区域将训练数据集分为三组:
S easy S_{\text {easy }} Seasy 、 S medium S_{\text {medium }} Smedium 和 S hard S_{\text {hard }} Shard 。对于单个任务 T i , i ∈ { 1 , 2 , 3 } T_{i}, i \in\{1,2,3\} Ti,i∈{1,2,3},我们分三个步骤训练检测模型,可以表示为: T i = { S easy I 1 ; if A r b b o x < A r easy S easy + S medium I 2 ; if A r box < A r medium S easy + S medium + S hard I 3 T_{i}= \begin{cases} S_{\text {easy}} & I_{1} ; \text { if } A r_{b b o x}<A r_{\text {easy }} \\ S_{\text {easy }}+S_{\text {medium }} & I_{2} ; \text { if } A r_{\text {box }}<A r_{\text {medium }} \\ S_{\text {easy }}+S_{\text {medium }}+S_{\text {hard }} & I_{3}\end{cases} Ti=⎩⎪⎨⎪⎧SeasySeasy +Smedium Seasy +Smedium +Shard I1; if Arbbox<Areasy I2; if Arbox <Armedium I3
I 1 、 I 2 I_{1}、I_{2} I1、I2 和 I 3 I_{3} I3 是训练每组集合的迭代次数。 A r easy A r_{\text {easy }} Areasy 和 A r medium A r_{\text {medium }} Armedium 是选择大、中边界框的区域阈值。
实验
图
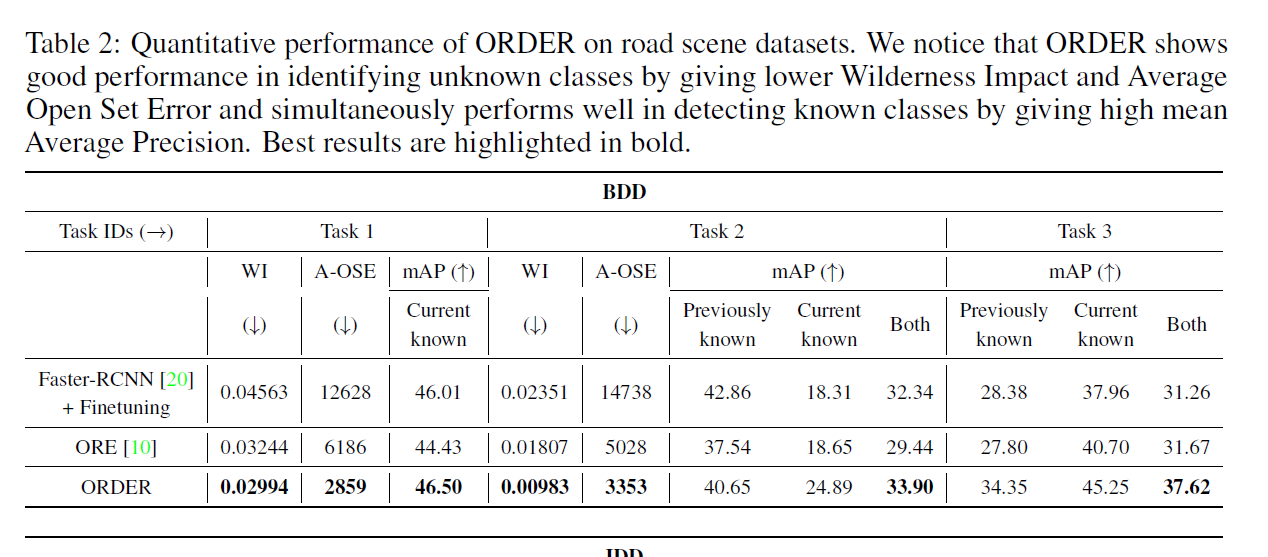

可以看出,的确比ORE分得更开。














 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









