






第十九章: 非线性规划的内点法
文章目录
现已证实, 内点法不仅在线性规划上, 在非线性规划问题上也同样有出色的表现. 与积极集SQP算法一起, 它们是当前公认的求解大规模非线性规划最有力的算法. 一些关键的概念, 诸如原始-对偶迭代步, 可以直接从线性规划的情形拿过来. 但与此同时也产生了一些新的挑战, 包括 如何处理非凸性质、如何在非线性性存在时更新障碍因子(即之前的惩罚因子)以及如何保证算法收敛到解. 本章我们介绍两种已在实际应用中有较好表现的内点法.
- 第一类算法可视为是线性和二次规划内点法的直接拓展. 它们使用线搜索强制收敛, 利用数值线性代数的方法(如矩阵分解)计算迭代步.
- 第二类的方法则使用二次模型定义迭代步, 并包含了信赖域的约束以增强稳定性.
这两种算法分别与线搜索和信赖域SQP算法具有相似的渐进性质.
非线性优化的障碍函数法(barrier methods)于上世纪六十年代被提出, 但在之后的近20年内淡出. 而内点法在线性规划上的成功应用则再次点燃了研究者们对它们在非线性情形研究的热情. 到上世纪九十年代末期, 已有对于非线性规划的新一代的算法和软件产生. 数值实验表明内点法在大型问题上往往要快于积极集SQP算法, 尤其是在自由变量的数目比较大的时候. 它们可能还不是很鲁棒, 但关于它们的设计和实施上的改进一直在进行. 现在, "内点法"和"障碍函数法"这两个词往往不加分别地互用.
在第十四章和第十六章, 我们分别讨论了线性规划和二次规划的内点法. 读者并不需要提前看过这两章. 本章的第一部分是关于KKT条件和牛顿法, 而第二部分则与第十八章SQP对应.
本章考虑的问题可写成如下形式: min x , s f ( x ) s u b j e c t t o c E ( x ) = 0 , c I ( x ) − s = 0 , s ≥ 0. \begin{array}{rl}\min\limits_{x,s} & f(x)\\\mathrm{subject\,to} & c_E(x)=0,\\& c_I(x)-s=0,\\&s\ge0.\end{array} x,sminsubjecttof(x)cE(x)=0,cI(x)−s=0,s≥0.其中向量 c I ( x ) c_I(x) cI(x)从标量函数 c i ( x ) , i ∈ I c_i(x),i\in\mathcal{I} ci(x),i∈I构建; c E ( x ) c_E(x) cE(x)类似. 注意我们引入了松弛变量 s s s将不等式约束 c I ( x ) ≥ 0 c_I(x)\ge0 cI(x)≥0转换成了等式约束. 我们用 l l l表示等式约束数量, m m m表示不等式约束数量.
1. 两种解释
内点法有两种解释的方式. 一种是连续方法(可见第十四章), 一种是障碍函数法.
1.1 连续/同伦方法的观点
非线性规划的KKT条件为 ∇ f ( x ) − A E T ( x ) y − A I T ( x ) z = 0 , S z − μ e = 0 , c E ( x ) = 0 , c I ( x ) − s = 0 , \begin{aligned}\nabla f(x)-A_E^T(x)y-A_I^T(x)z&=0,\\Sz-\mu e&=0,\\c_E(x)&=0,\\c_I(x)-s&=0,\end{aligned} ∇f(x)−AET(x)y−AIT(x)zSz−μecE(x)cI(x)−s=0,=0,=0,=0,其中 μ = 0 , s ≥ 0 , z ≥ 0 \mu=0,s\ge0,z\ge0 μ=0,s≥0,z≥0. 这里 A E ( x ) , A I ( x ) A_E(x),A_I(x) AE(x),AI(x)分别是 c E , c I c_E,c_I cE,cI的Jacobi阵, y , z y,z y,z为对应的Lagrange乘子. 我们定义 S , Z S,Z S,Z分别为向量 s , z s,z s,z生成的对角阵.
这里, 互补松弛条件( μ = 0 \mu=0 μ=0)以及界约束 s ≥ 0 , z ≥ 0 s\ge0,z\ge0 s≥0,z≥0会引入组合方面的困难. 可见第十五章例1. 我们可令 μ \mu μ严格大于0, 绕过这个问题, 从而强制 s , z s,z s,z取正值. 同伦(或连续)方法就是对一列正参数 { μ k } : μ k → 0 \{\mu_k\}:\mu_k\to0 {μk}:μk→0(近似)求解一系列的扰动KKT方程, 同时保持 s , z > 0 s,z>0 s,z>0. 我们希望, 在极限状态下, 我们能得到一满足KKT条件的解. 进一步地, 通过要求迭代点减小价值函数(或被滤子所接受), 则最终收敛到的就是极小点而不仅仅是KKT点.
同伦方法是局部意义的算法. 假设解 ( x ∗ , s ∗ , y ∗ , z ∗ ) (x^*,s^*,y^*,z^*) (x∗,s∗,y∗,z∗)满足LICQ、严格互补松弛条件和二阶充分性条件, 则在其一邻域内, 对所有充分大的 μ \mu μ, 系统将会有局部的唯一解, 我们以 ( x ( μ ) , s ( μ ) , y ( μ ) , z ( μ ) ) (x(\mu),s(\mu),y(\mu),z(\mu)) (x(μ),s(μ),y(μ),z(μ))表示. 由这些点构成的轨迹被称为原始-对偶中心路径, 它随 μ → 0 \mu\to0 μ→0收敛于 ( x ∗ , s ∗ , y ∗ , z ∗ ) (x^*,s^*,y^*,z^*) (x∗,s∗,y∗,z∗).
1.2 障碍函数的观点
第二种内点法的解释考虑障碍问题(barrier problem) min x , s f ( x ) − μ ∑ i = 1 m log s i s u b j e c t t o c E ( x ) = 0 , c I ( x ) − s = 0 , \begin{array}{rl}\min\limits_{x,s} & f(x)-\mu\sum\limits_{i=1}^m\log s_i\\\mathrm{subject\,to} & c_E(x)=0,\\& c_I(x)-s=0,\end{array} x,sminsubjecttof(x)−μi=1∑mlogsicE(x)=0,cI(x)−s=0,其中 μ \mu μ为正参数. 因为障碍项 − μ ∑ i = 1 m log s i -\mu\sum_{i=1}^m\log s_i −μ∑i=1mlogsi的存在, 我们不需要考虑 s ≥ 0 s\ge0 s≥0. 事实上, 障碍项能够避免 s s s的分量离0太近. 障碍问题同样也避免了非线性规划的组合困难, 但它在 μ > 0 \mu>0 μ>0的解并不与非线性规划的解契合, 这点与同伦方法相同. 障碍函数法就是对一列正障碍因子 { μ k } : μ k → 0 \{\mu_k\}:\mu_k\to0 {μk}:μk→0, (近似)求解一系列障碍问题.
1.3 两种观点的比较
为比较两种观点, 我们将障碍问题的KKT条件写出: ∇ f ( x ) − A E T ( x ) y − A I T ( x ) z = 0 , − μ S − 1 e + z = 0 , c E ( x ) = 0 , c I ( x ) − s = 0. \begin{aligned}\nabla f(x)-A_E^T(x)y-A_I^T(x)z&=0,\\-\mu S^{-1}e+z&=0,\\c_E(x)&=0,\\c_I(x)-s&=0.\end{aligned} ∇f(x)−AET(x)y−AIT(x)z−μS−1e+zcE(x)cI(x)−s=0,=0,=0,=0.注意这与扰动KKT方程只有第二个等式不同. 这里在 s → 0 s\to0 s→0时会趋向非线性. 为使用牛顿法, 我们有必要将第二行的有理式转变成二次方程. 于是左乘 S S S(这不会改变KKT系统的解, 因为 S S S的对角元都是正数), 就与扰动KKT方程相同了.
"内点"这个词是因为早期的障碍函数法并不使用松弛变量, 且假设初始点对不等式约束 c i ( x ) ≥ 0 , i ∈ I c_i(x)\ge0,i\in\mathcal{I} ci(x)≥0,i∈I是可行的. 这些算法使用障碍函数 f ( x ) − μ ∑ i ∈ I log c i ( x ) f(x)-\mu\sum\limits_{i\in\mathcal{I}}\log c_i(x) f(x)−μi∈I∑logci(x)防止迭代点从由不等式约束定义的可行域中脱离. 我们将在第6节讨论这个障碍函数. 而大多数现代的内点法都是不可行方法(它们可从任意点 x 0 x_0 x0出发), 并只保证迭代点位于 s ≥ 0 , z ≥ 0 s\ge0,z\ge0 s≥0,z≥0张成区域的内部. 不过, 它们可以在一个可行点产生后, 保证后续所有的迭代点都是可行的.
之后我们将说明同伦和障碍函数的观点都是有用的. 具体来说, 同伦的观点给出了原始-对偶方向的定义, 而障碍函数的观点则有助于设计全局收敛的迭代.
2. 一个基本的内点法算法
将牛顿法应用于扰动KKT方程, 我们有 [ ∇ x x 2 L O − A E T ( x ) − A I T ( x ) O Z O S A E ( x ) O O O A I ( x ) − I O O ] [ p x p s p y p z ] = − [ ∇ f ( x ) − A E T ( x ) y − A I T ( x ) z S z − μ e c E ( x ) c I ( x ) − s ] , \begin{bmatrix}\nabla^2_{xx}\mathcal{L} & O & -A_E^T(x) & -A_I^T(x)\\O & Z & O & S\\\ A_E(x) & O & O & O\\A_I(x) & -I & O & O\end{bmatrix}\begin{bmatrix}p_x\\p_s\\p_y\\p_z\end{bmatrix}=-\begin{bmatrix}\nabla f(x)-A_E^T(x)y-A_I^T(x)z\\Sz-\mu e\\c_E(x)\\c_I(x)-s\end{bmatrix}, ⎣⎢⎢⎡∇xx2LO AE(x)AI(x)OZO−I−AET(x)OOO−AIT(x)SOO⎦⎥⎥⎤⎣⎢⎢⎡pxpspypz⎦⎥⎥⎤=−⎣⎢⎢⎡∇f(x)−AET(x)y−AIT(x)zSz−μecE(x)cI(x)−s⎦⎥⎥⎤,其中 L \mathcal{L} L表示Lagrange函数 L ( x , s , y , z ) = f ( x ) − y T c E ( x ) − z T ( c I ( x ) − s ) . \mathcal{L}(x,s,y,z)=f(x)-y^Tc_E(x)-z^T(c_I(x)-s). L(x,s,y,z)=f(x)−yTcE(x)−zT(cI(x)−s).上述方程称为原始-对偶系统(primal-dual system). 在计算出 p = ( p x , p s , p y , p z ) p=(p_x,p_s,p_y,p_z) p=(px,ps,py,pz)后, 我们就令新迭代点 ( x + , s + , y + , z + ) (x^+,s^+,y^+,z^+) (x+,s+,y+,z+)为 x + = x + α s max p x , s + = s + α s max p s , y + = y + α z max p y , z + = z + α z max p z , \begin{aligned}x^+&=x+\alpha_s^{\max}p_x,\quad s^+=s+\alpha_s^{\max}p_s,\\y^+&=y+\alpha_z^{\max}p_y,\quad z^+=z+\alpha_z^{\max}p_z,\end{aligned} x+y+=x+αsmaxpx,s+=s+αsmaxps,=y+αzmaxpy,z+=z+αzmaxpz,其中 α s max = max { α ∈ ( 0 , 1 ] : s + α p s ≥ ( 1 − τ ) s } , α z max = max { α ∈ ( 0 , 1 ] : z + α p z ≥ ( 1 − τ ) z } , \begin{aligned}\alpha_s^{\max}&=\max\{\alpha\in(0,1]:s+\alpha p_s\ge(1-\tau)s\},\\\alpha_z^{\max}&=\max\{\alpha\in(0,1]:z+\alpha p_z\ge(1-\tau)z\},\end{aligned} αsmaxαzmax=max{α∈(0,1]:s+αps≥(1−τ)s},=max{α∈(0,1]:z+αpz≥(1−τ)z}, τ ∈ ( 0 , 1 ) \tau\in(0,1) τ∈(0,1). 比如可取 τ = 0.995 \tau=0.995 τ=0.995. 上述确定步长 α \alpha α的条件称为是分数到边准则(fraction to the boundary rule), 这使得 s , Z s,Z s,Z不会过快地趋近于它们的下界 0 0 0.
尽管还有许多细节需要考虑, 比如需要处理非凸性和非线性性, 但这种简单的迭代方式提供了现代内点法的基础. 算法其他的主要部分还包括选取障碍因子序列 { μ k } \{\mu_k\} {μk}. Fiacco和McCormick1的方法是固定 μ \mu μ直到KKT条件在一定精度下满足. 另一种就是在每次迭代都对其进行更新. 两者均有各自的优点, 我们将在第3节讨论之.
由于迭代最终收敛到满足二阶充分性条件和严格互补松弛条件的解, 因此原始-对偶矩阵(或KKT矩阵)保持非奇异. 更确切地说, 若 x ∗ x^* x∗为严格互补松弛条件成立的解, 则随着迭代点趋近于 x ∗ x^* x∗, 对每个指标 i i i, s i s_i si或 z i z_i zi有且仅有一个远离0, 这就保证了KKT矩阵的第二行行满秩. 因此, 内点法本身不会有病态或者奇异的问题. 而这一事实也使我们能对其建立快速(超线性)的局部收敛速度定理. 可见第8节.
我们使用以下基于扰动KKT方程的误差函数作为某种形式上的价值函数: E ( x , s , y , z ; μ ) = max { ∥ ∇ f ( x ) − A E ( x ) T y − A I ( x ) T z ∥ , ∥ S z − μ e ∥ , ∥ c E ( x ) ∥ , ∥ c I ( x ) − s ∥ } , \begin{aligned}E(x,s,y,z;\mu)=\max\{\Vert\nabla &f(x)-A_E(x)^Ty-A_I(x)^Tz\Vert,\Vert Sz-\mu e\Vert,\\&\Vert c_E(x)\Vert,\Vert c_I(x)-s\Vert\},\end{aligned} E(x,s,y,z;μ)=max{∥∇f(x)−AE(x)Ty−AI(x)Tz∥,∥Sz−μe∥,∥cE(x)∥,∥cI(x)−s∥},其中 ∥ ⋅ ∥ \Vert\cdot\Vert ∥⋅∥为某一向量范数.
算法1 (Basic Interior-Point Algorithm)
Choose
x
0
x_0
x0 and
s
0
>
0
s_0>0
s0>0, and compute initial values for the multipliers
y
0
y_0
y0 and
z
0
>
0
z_0>0
z0>0.
Select an initial barrier parameter
μ
0
>
0
\mu_0>0
μ0>0 and parameters
σ
,
τ
∈
(
0
,
1
)
\sigma,\tau\in(0,1)
σ,τ∈(0,1).
Set
k
←
0
k\leftarrow 0
k←0
repeat until a stopping test for the nonlinear program is satisfied
\quad\quad
repeat until
E
(
x
k
,
s
k
,
y
k
,
z
k
;
μ
k
)
≤
μ
k
E(x_k,s_k,y_k,z_k;\mu_k)\le\mu_k
E(xk,sk,yk,zk;μk)≤μk
\quad\quad\quad\quad
Solve the perturbed KKT system to obtain the search direction
p
=
(
p
x
,
p
s
,
p
y
,
p
z
)
p=(p_x,p_s,p_y,p_z)
p=(px,ps,py,pz);
\quad\quad\quad\quad
Compute
α
s
max
,
α
z
max
\alpha_s^{\max},\alpha_z^{\max}
αsmax,αzmax;
\quad\quad\quad\quad
Compute
(
x
k
+
1
,
s
k
+
1
,
y
k
+
1
,
z
k
+
1
)
(x_{k+1},s_{k+1},y_{k+1},z_{k+1})
(xk+1,sk+1,yk+1,zk+1);
\quad\quad\quad\quad
Set
μ
k
+
1
←
μ
k
\mu_{k+1}\leftarrow \mu_k
μk+1←μk and
k
←
k
+
1
k\leftarrow k+1
k←k+1;
\quad\quad
end
\quad\quad
Choose
μ
k
∈
(
0
,
σ
μ
k
)
\mu_k\in(0,\sigma\mu_k)
μk∈(0,σμk);
end
每步迭代均更新 μ k \mu_k μk的算法则只需要把算法1中的内循环拿掉, 再把倒数第二行 μ k \mu_k μk的更新方式做一些修正即可.
下面的定理提供了仅计算障碍问题近似解的内点法的理论支撑.
定理1 假设算法1产生了一列迭代点 { x k } \{x_k\} {xk}且 { μ k } → 0 \{\mu_k\}\to0 {μk}→0(即算法的内循环不会无穷地进行下去). 设 f , c f,c f,c为连续可微函数. 则 { x k } \{x_k\} {xk}的所有聚点 x ^ \hat x x^都是可行点. 进一步, 任何满足LICQ的 { x k } \{x_k\} {xk}的聚点 x ^ \hat x x^都是KKT点.
证明: 简单起见, 我们仅证明包含不等式约束的情形, 且以 c c c表示原本的不等式约束 c I c_I cI. 令 x ^ \hat x x^为 { x k } \{x_k\} {xk}的极限点, 且 { x k l } \{x_{k_l}\} {xkl}为相应的收敛子列: { x k l } → x ^ \{x_{k_l}\}\to\hat x {xkl}→x^. 因为 μ k → 0 \mu_k\to0 μk→0, 所以 E E E收敛到0, 于是 ( c k l − s k l ) → 0 (c_{k_l}-s_{k_l})\to0 (ckl−skl)→0. 由 c c c的连续性, 这就表明 c ^ = d e f c ( x ^ ) ≥ 0 \hat c\xlongequal{def} c(\hat x)\ge0 c^defc(x^)≥0(即 x ^ \hat x x^可行)以及 s k l → s ^ = c ^ s_{k_l}\to\hat s=\hat c skl→s^=c^.
现假设在 x ^ \hat x x^处满足LICQ, 考虑积极集 A = { i : c ^ i = 0 } . \mathcal{A}=\{i:\hat c_i=0\}. A={i:c^i=0}.对 i ∉ A i\notin\mathcal{A} i∈/A, 我们有 c ^ i > 0 , s ^ i > 0 \hat c_i>0,\hat s_i>0 c^i>0,s^i>0, 因此由严格互补松弛条件, { z k l } i → 0 \{z_{k_l}\}_i\to0 {zkl}i→0. 由 E E E的定义, 我们有 ∇ f k l − A k l T z k l → 0 \nabla f_{k_l}-A_{k_l}^Tz_{k_l}\to0 ∇fkl−AklTzkl→0, 结合上一段, 有 ∇ f k l − ∑ i ∈ A [ z k l ] i ∇ c i ( x k l ) → 0. \nabla f_{k_l}-\sum_{i\in\mathcal{A}}[z_{k_l}]_i\nabla c_i(x_{k_l})\to0. ∇fkl−i∈A∑[zkl]i∇ci(xkl)→0.由LICQ, 向量 { ∇ c ^ i : i ∈ A } \{\nabla\hat c_i:i\in\mathcal{A}\} {∇c^i:i∈A}线性无关. 于是由 ∇ f ( ⋅ ) , ∇ c ( i ) ( ⋅ ) , i ∈ A \nabla f(\cdot),\nabla c_{(i)}(\cdot),i\in\mathcal{A} ∇f(⋅),∇c(i)(⋅),i∈A的连续性, 正序列 { z k l } \{z_{k_l}\} {zkl}收敛于某个 z ^ ≥ 0 \hat z\ge0 z^≥0. 在上式两端取极限就有 ∇ f ( x ^ ) = ∑ i ∈ A z ^ i ∇ c i ( x ^ ) . \nabla f(\hat x)=\sum_{i\in\mathcal{A}}\hat z_i\nabla c_i(\hat x). ∇f(x^)=i∈A∑z^i∇ci(x^).由积极集和严格互补松弛条件, 还有 c ^ T z ^ = 0 \hat c^T\hat z=0 c^Tz^=0. 证毕.
实用内点法分为两类. 第一类以算法1为基础, 并加入线搜索和控制 s , z s,z s,z下降速率的技术, 且引入对非负曲率的讨论. 第二类可见第5节, 极小化障碍问题的二次模型, 同时受限于信赖域约束. 这两类方法有许多的共同点.
3. 算法1的进一步讨论
现在我们讨论算法1的一些修正和拓展, 以让它能在非线性非凸问题上继续发挥作用.
通常, 原始-对偶系统写作 [ ∇ x x 2 L O A E T ( x ) A I T ( x ) O Σ O − I A E ( x ) O O O A I ( x ) − I O O ] [ p x p s − p y − p z ] = − [ ∇ f ( x ) − A E T ( x ) y − A I T ( x ) z z − μ S − 1 e c E ( x ) c I ( x ) − s ] , \begin{bmatrix}\nabla^2_{xx}\mathcal{L} & O & A_E^T(x) & A_I^T(x)\\O & \Sigma & O & -I\\A_E(x) & O & O & O\\A_I(x) & -I & O & O\end{bmatrix}\begin{bmatrix}p_x\\p_s\\-p_y\\-p_z\end{bmatrix}=-\begin{bmatrix}\nabla f(x)-A_E^T(x)y-A_I^T(x)z\\z-\mu S^{-1}e\\c_E(x)\\c_I(x)-s\end{bmatrix}, ⎣⎢⎢⎡∇xx2LOAE(x)AI(x)OΣO−IAET(x)OOOAIT(x)−IOO⎦⎥⎥⎤⎣⎢⎢⎡pxps−py−pz⎦⎥⎥⎤=−⎣⎢⎢⎡∇f(x)−AET(x)y−AIT(x)zz−μS−1ecE(x)cI(x)−s⎦⎥⎥⎤,其中 Σ = S − 1 Z . \Sigma=S^{-1}Z. Σ=S−1Z.这样我们就可使用对称线性方程的求解器. 每步迭代的计算量就会有所减少.
3.1 原始系统 vs. 原始-对偶系统
如果我们直接对障碍问题的最优性条件应用牛顿法, 之后再对称化迭代矩阵, 我们就会得到类似的系数矩阵, 但此时 Σ = μ S − 2 . \Sigma=\mu S^{-2}. Σ=μS−2.此系统通常称为原始系统(primal system). 这样的命名主要是基于内点法发展的历史.
即使原问题和障碍问题等价, 直接使用牛顿法也通常会产生不同的迭代点. 而原始-对偶系统往往更受青睐. 注意原问题KKT条件的互补松弛条件导数是有界的, 但障碍问题却不具有这样的性质. 进一步地, 关于原始步的分析和一些实验结果都表明, 在某些情形下原始系统将产生破坏 s > 0 , z > 0 s>0,z>0 s>0,z>0约束的迭代步. 从而减缓进程. 可见第6节.
3.2 求解原始-对偶系统
除了计算函数值和导数值的计算量, 内点法的计算花费主要是在求解原始-对偶系统上. 因此高效的(使用稀疏分解或迭代技术的)线性求解器在大型问题的快速求解上至关重要.
- 构造.
由于原始-对偶系统的系数对称矩阵与第十六章中的KKT矩阵很相似, 因此这样的系统可以用第十六章中方法求解. 我们首先用第二行消去 p s p_s ps, 得到 [ ∇ x x 2 L A E T ( x ) A I T ( x ) A E ( x ) O O A I ( x ) O − Σ − 1 ] [ p x − p y − p z ] = − [ ∇ f ( x ) − A E T ( x ) y − A I T ( x ) z c E ( x ) c I ( x ) − μ Z − 1 e ] . \begin{bmatrix}\nabla^2_{xx}\mathcal L & A_E^T(x) & A_I^T(x)\\A_E(x) & O & O\\A_I(x) & O & -\Sigma^{-1}\end{bmatrix}\begin{bmatrix}p_x\\-p_y\\-p_z\end{bmatrix}=-\begin{bmatrix}\nabla f(x)-A_E^T(x)y-A_I^T(x)z\\c_E(x)\\c_I(x)-\mu Z^{-1}e\end{bmatrix}. ⎣⎡∇xx2LAE(x)AI(x)AET(x)OOAIT(x)O−Σ−1⎦⎤⎣⎡px−py−pz⎦⎤=−⎣⎡∇f(x)−AET(x)y−AIT(x)zcE(x)cI(x)−μZ−1e⎦⎤.此系统可用对称不定分解求解: 记此系数矩阵为 K K K, 则对称不定分解计算 P T K P = L B L T P^TKP=LBL^T PTKP=LBLT, 其中 L L L为下三角阵, B B B分块对角, 其中对角块为 1 × 1 1\times 1 1×1或 2 × 2 2\times 2 2×2的子阵. P P P为排列矩阵, 用于权衡稀疏性和数值稳定性.
此系统可进一步用最后一行消去 p z p_z pz, 得到更加约减的系数矩阵 [ ∇ x x 2 L + A I T Σ A I A E T ( x ) A E ( x ) O ] , \begin{bmatrix}\nabla^2_{xx}\mathcal L+A_I^T\Sigma A_I & A_E^T(x)\\A_E(x) & O\end{bmatrix}, [∇xx2L+AITΣAIAE(x)AET(x)O],这步约减在不等式约束很多的时候尤其显著. 尽管 A I T Σ A I A_I^T\Sigma A_I AITΣAI会带来显著的填充, 但这在许多应用中都还是可接受的. 当然最理想的情形是 A I T Σ A I A_I^T\Sigma A_I AITΣAI对角. 不等式约束都是界约束时就是这种情形. - 病态与求解方法.
- 不论是什么形式, 原始-对偶系统都是病态的, 这是因为 Σ \Sigma Σ的某些元素将随着 μ → 0 \mu\to0 μ→0发散到 ∞ \infty ∞, 而其他的则会收敛到 0 0 0. 尽管如此, 由于此病态结构具有特殊形式, 由稳定的直接分解法计算的方向通常还是精确的. 只有当松弛变量 s s s或乘子 z z z非常靠近 0 0 0(或当Hessian阵 ∇ x x 2 L \nabla^2_{xx}\mathcal L ∇xx2L或 A E A_E AE几近亏秩)时才会导致毁灭性的误差. 基于此, 直接分解法被认为是在内点法计算迭代步时最可靠的技术.
- 我们自然也可以使用迭代的技术. 如此一来病态就是个严重的问题, 因此必须使用合适的预处理子. 幸运的是, 这样的预处理子很容易构造. 例如我们在原始-对偶系统里引入
p
~
s
=
S
−
1
p
s
\tilde p_s=S^{-1}p_s
p~s=S−1ps, 在第二个方程上左乘
S
S
S, 将
Σ
\Sigma
Σ转变为
S
Σ
S
S\Sigma S
SΣS. 随着
μ
→
0
\mu\to0
μ→0(且假设
S
Z
≈
μ
I
SZ\approx\mu I
SZ≈μI),
S
Σ
S
S\Sigma S
SΣS就接近于
μ
I
\mu I
μI. 当然还有其他的变尺度方法. 例如引入变量
p
~
s
=
Σ
1
/
2
p
s
\tilde p_s=\Sigma^{1/2}p_s
p~s=Σ1/2ps就得到了完美的预处理子, 而若
p
~
s
=
μ
S
−
1
p
s
\tilde p_s=\sqrt{\mu}S^{-1}p_s
p~s=μS−1ps就将
Σ
\Sigma
Σ转换成
S
Σ
S
/
μ
S\Sigma S/\mu
SΣS/μ, 这在
μ
→
0
\mu\to0
μ→0时收敛到
I
I
I.
我们可以用迭代的方法求解以上任何一个对称不定系统. 这里CG就不太合适了, 毕竟它只适用于正定系统. 我们可以用GMRES, QMR或LSQR. 除了使用预处理缓解由障碍函数带来的病态, 我们还需要处理由Hessian ∇ x x 2 L \nabla^2_{xx}\mathcal L ∇xx2L或Jacobi阵 A E , A I A_E,A_I AE,AI带来的问题. 对此我们很难找到一般性的预处理子.
一种高效的替代方案是使用零空间方法求解原始-对偶系统并将CG用于(正定)既约空间, 如第十六章. 我们可用带约束预处理子的投影CG. 就原始-对偶系统而言, 预处理子有形式 [ G O A E T ( x ) A I T ( x ) O T O − I A E ( x ) O O O A I ( x ) − I O O ] , \begin{bmatrix} G & O & A_E^T(x) & A_I^T(x)\\O & T & O & -I\\A_E(x) & O & O & O\\A_I(x) & -I & O & O\end{bmatrix}, ⎣⎢⎢⎡GOAE(x)AI(x)OTO−IAET(x)OOOAIT(x)−IOO⎦⎥⎥⎤,其中 G G G为稀疏阵, 他在约束的零空间上正定; T T T为对角阵, 等于或近似 Σ \Sigma Σ. 此预处理子保留了 A E , A I A_E,A_I AE,AI, 从而去除了由这些矩阵带来的病态问题.
3.3 更新障碍因子
障碍因子序列 { μ k } \{\mu_k\} {μk}必须收敛于 0 0 0, 从而使我们在极限状态下能得到原问题的解. 若 μ k \mu_k μk下降过慢, 则就需要过多的迭代; 若下降太快, 则 s s s或 z z z的某些分量可能会过早地趋向于 0 0 0, 减缓迭代进程. 下面介绍几种更新 μ k \mu_k μk的高效实用技术.
3.3.1 Fiacco-McCormick策略
在算法1中的Fiacco-McCormick策略是固定障碍因子直到扰动的KKT条件达到一定的精度. 之后障碍因子以如下形式更新: μ k + 1 = σ k μ k , σ k ∈ ( 0 , 1 ) . \mu_{k+1}=\sigma_k\mu_k,\quad\sigma_k\in(0,1). μk+1=σkμk,σk∈(0,1).一些早期的内点法选取 σ k \sigma_k σk为一个常数(比如 0.2 0.2 0.2). 然而让 σ k \sigma_k σk多取几个值应当更好些(比如 0.2 , 0.1 0.2,0.1 0.2,0.1): 当最近几步迭代效果显著时, 就选取较小的值. 进一步, 在解附近令 σ k → 0 \sigma_k\to0 σk→0再让 τ → 1 \tau\to1 τ→1, 我们就有超线性局部收敛速度.
Fiacco-McCormick策略在许多问题上都适用, 但它对初始点、初始障碍因子的选取以及问题的尺度很敏感.
3.3.2 自适应更新策略
自适应的更新策略则在复杂困难的情形更加鲁棒. 这些策略不像Fiacco-McCormick策略, 将根据算法的进程, 在每一步都更新
μ
\mu
μ. 大多这样的策略都基于互补松弛条件, 这如同线性规划的情形(可见第十四章). 它们具有形式
μ
k
+
1
=
σ
k
s
k
T
z
k
m
,
\mu_{k+1}=\sigma_k\frac{s_k^Tz_k}{m},
μk+1=σkmskTzk,这就使得
μ
k
\mu_k
μk能反映问题的尺度. 而我们对于
σ
k
\sigma_k
σk的选取, 则基于最小的互补乘积:
σ
k
=
0.1
min
(
0.05
1
−
ξ
k
ξ
k
,
2
)
3
,
ξ
k
=
min
i
[
s
k
]
i
[
z
k
]
i
(
s
k
)
T
z
k
/
m
.
\sigma_k=0.1\min\left(0.05\frac{1-\xi_k}{\xi_k},2\right)^3,\quad\xi_k=\frac{\min_i[s_k]_i[z_k]_i}{(s^k)^Tz^k/m}.
σk=0.1min(0.05ξk1−ξk,2)3,ξk=(sk)Tzk/mmini[sk]i[zk]i.这里
[
⋅
]
i
[\cdot]_i
[⋅]i表示取出第
i
i
i个分量. 当
ξ
k
≈
1
\xi_k\approx 1
ξk≈1(即所有的对偶乘积就接近它们的平均值), 障碍因子就会剧烈减小.
预估或是测探策略(可见第十四章)亦可以用来给出
σ
k
\sigma_k
σk. 我们首先令
μ
=
0
\mu=0
μ=0计算得到预估(仿射尺度变换)步
(
Δ
x
a
f
f
,
Δ
s
a
f
f
,
Δ
y
a
f
f
,
Δ
z
a
f
f
)
.
(\Delta x^{\mathrm{aff}},\Delta s^{\mathrm{aff}},\Delta y^{\mathrm{aff}},\Delta z^{\mathrm{aff}}).
(Δxaff,Δsaff,Δyaff,Δzaff).之后我们沿此方向探查得到
α
p
a
f
f
,
α
d
a
f
f
\alpha_p^{\mathrm{aff}},\alpha_d^{\mathrm{aff}}
αpaff,αdaff为(不打破
(
s
,
z
)
≥
0
(s,z)\ge0
(s,z)≥0)最大步长. 这些迭代步长都具有显式的表达式(即令
τ
=
1
\tau=1
τ=1). 之后定义
μ
a
f
f
\mu_{\mathrm{aff}}
μaff为
μ
a
f
f
=
(
s
k
+
α
s
a
f
f
Δ
s
a
f
f
)
T
(
z
k
+
α
z
a
f
f
Δ
z
a
f
f
)
m
,
\mu_{\mathrm{aff}}=\frac{(s_k+\alpha_s^{\mathrm{aff}}\Delta s^{\mathrm{aff}})^T(z_k+\alpha_z^{\mathrm{aff}}\Delta z^{\mathrm{aff}})}{m},
μaff=m(sk+αsaffΔsaff)T(zk+αzaffΔzaff),并定义
σ
k
\sigma_k
σk为如下:
σ
k
=
(
μ
a
f
f
s
k
T
z
k
/
m
)
3
.
\sigma_k=\left(\frac{\mu_{\mathrm{aff}}}{s_k^Tz_k/m}\right)^3.
σk=(skTzk/mμaff)3.这种
σ
k
\sigma_k
σk的启发式选取在线性规划问题的内点法中提出, 且同样适用于非线性规划.
3.4 处理非凸与奇异性
由原始-对偶系统定义的方向并不总有较好的效果, 因为它只定位KKT点; 这就意味着它可以趋向极大点或者是其他稳定点. 在第十八章, 我们知道若Hessian阵 W W W在约束的切空间正定, 则对等式约束问题牛顿步对一大类价值函数保证是个下降方向, 同时对于滤子也是个有用的方向. 理由是, 此时的牛顿步可看做是在通过消去线性化约束得到的既约空间上极小化一个凸模型.
而对于原始-对偶系统则类似, p p p为下降方向若 [ ∇ x x 2 L O O Σ ] \begin{bmatrix}\nabla^2_{xx}\mathcal L & O\\O & \Sigma\end{bmatrix} [∇xx2LOOΣ]在 [ A E ( x ) O A I ( x ) − I ] \begin{bmatrix}A_E(x) & O\\A_I(x) & -I\end{bmatrix} [AE(x)AI(x)O−I]的零空间上正定. 第十六章的关于惯性指数的定理3则指出, 若原始-对偶矩阵的惯性指数为 ( n + m , l + m , 0 ) , (n+m,l+m,0), (n+m,l+m,0),则此正定性条件成立. 换句话说, 原始-对偶矩阵要恰好有 n + m n+m n+m个正特征值, l + m l+m l+m个负特征值以及没有0特征值. 而若原始-对偶矩阵没有这样的惯性指数, 我们也可以对它修正. 注意对角阵 Σ \Sigma Σ正定, 而 ∇ x x 2 L \nabla^2_{xx}\mathcal L ∇xx2L可以是不定的. 因此我们以 ∇ x x 2 L + δ I \nabla^2_{xx}\mathcal L+\delta I ∇xx2L+δI代替后者, 其中 δ > 0 \delta>0 δ>0充分大以保证惯性指数条件成立. 这种修正的量事先是未知的, 但我们可以连续增大 δ \delta δ直到条件满足.
我们也必须考虑由 A E A_E AE亏秩带来的奇异性. 我们可以额外再增加一个正则化参数 γ ≥ 0 \gamma\ge0 γ≥0. 最后修正的原始-对偶矩阵为 [ ∇ x x 2 L + δ I O A E ( x ) T A I ( x ) T O Σ O − I A E ( x ) O − γ I O A I ( x ) − I O O ] . \begin{bmatrix}\nabla^2_{xx}\mathcal L +\delta I & O & A_E(x)^T & A_I(x)^T\\O & \Sigma & O & -I\\A_E(x) & O & -\gamma I & O\\A_I(x) & -I & O & O\end{bmatrix}. ⎣⎢⎢⎡∇xx2L+δIOAE(x)AI(x)OΣO−IAE(x)TO−γIOAI(x)T−IOO⎦⎥⎥⎤.一种选取 δ , γ \delta,\gamma δ,γ的程序如下:
程序2 (Inertia Correction and Regularization)
Given the current barrier parameter
μ
\mu
μ, constants
η
>
0
\eta>0
η>0 and
β
<
1
\beta<1
β<1, and the perturbation
δ
o
l
d
\delta_{old}
δold used in the previous interior-point iteration
Factor the modified primal-dual matrix with
δ
=
γ
=
0
\delta=\gamma=0
δ=γ=0.
if the modified primal-dual matrix is nonsingular and its inertia is
(
n
+
m
,
l
+
m
,
0
)
(n+m,l+m,0)
(n+m,l+m,0)
\quad\quad
Compute the primal-dual step; stop;
if the modified primal-dual matrix has zero eigenvalues
\quad\quad
set
γ
←
1
0
−
8
η
μ
β
\gamma\leftarrow10^{-8}\eta\mu^{\beta}
γ←10−8ημβ;
if
δ
o
l
d
=
0
\delta_{old}=0
δold=0
\quad\quad
set
δ
←
1
0
−
4
\delta\leftarrow10^{-4}
δ←10−4;
else
\quad\quad
set
δ
←
δ
o
l
d
/
2
\delta\leftarrow\delta_{old}/2
δ←δold/2;
repeat
\quad\quad
Factor the modified matrix;
\quad\quad
if the inertia is
(
n
+
m
,
l
+
m
,
0
)
(n+m,l+m,0)
(n+m,l+m,0)
\quad\quad\quad\quad
Set
δ
o
l
d
←
δ
\delta_{old}\leftarrow\delta
δold←δ;
\quad\quad\quad\quad
Compute the primal-dual step using the modified matrix; stop;
\quad\quad
else
\quad\quad\quad\quad
Set
δ
←
10
δ
\delta\leftarrow10\delta
δ←10δ;
end (repeat)
程序2需要在内点法的每一次迭代调用, 以强制满足惯性指数条件, 保证非奇异性. 其他的保证修正的矩阵正定性的策略可见第三章.
3.5 步长接收机制: 价值函数与滤子
价值函数或滤子的作用是决定一试探步是否应当被接收. 由于内点法可以看做是求解障碍问题的方法, 因此以障碍函数的形式定义价值函数
ϕ
\phi
ϕ或滤子是合适的. 例如我们可以使用精确价值函数
ϕ
v
(
x
,
s
)
=
f
(
x
)
−
μ
∑
i
=
1
m
log
s
i
+
v
∥
c
E
(
x
)
∥
+
v
∥
c
I
(
x
)
−
s
∥
,
\phi_v(x,s)=f(x)-\mu\sum_{i=1}^m\log s_i+v\Vert c_E(x)\Vert+v\Vert c_I(x)-s\Vert,
ϕv(x,s)=f(x)−μi=1∑mlogsi+v∥cE(x)∥+v∥cI(x)−s∥,其中范数可选比如
l
1
l_1
l1或
l
2
l_2
l2范数. 惩罚因子
v
>
0
v>0
v>0可用第十八章中的策略更新.
在线搜索算法中, 在计算出
p
p
p和最大的步长后, 我们使用回溯线搜索计算步长
α
s
∈
(
0
,
α
s
max
]
,
α
z
∈
(
0
,
α
z
max
]
,
\alpha_s\in(0,\alpha_s^{\max}],\quad\alpha_z\in(0,\alpha_z^{\max}],
αs∈(0,αsmax],αz∈(0,αzmax],以得到价值函数的充分下降或确保为滤子所接收. 于是新的迭代点定义为
x
+
=
x
+
α
s
p
x
,
s
+
=
s
+
α
s
p
s
,
y
+
=
y
+
α
z
p
y
,
z
+
=
z
+
α
z
p
z
.
\begin{aligned}x^+&=x+\alpha_sp_x,\quad s^+=s+\alpha_sp_s,\\y^+&=y+\alpha_zp_y,\quad z^+=z+\alpha_zp_z.\end{aligned}
x+y+=x+αspx,s+=s+αsps,=y+αzpy,z+=z+αzpz.定义滤子需要同时考虑障碍函数
f
(
x
)
−
μ
∑
i
=
1
m
log
s
i
f(x)-\mu\sum_{i=1}^m\log s_i
f(x)−μ∑i=1mlogsi和约束违反度
∥
(
c
E
(
x
)
,
c
I
(
x
)
−
s
)
∥
\Vert(c_E(x),c_I(x)-s)\Vert
∥(cE(x),cI(x)−s)∥. 若
p
p
p不被任何滤子中的元素占优, 则就可被接收. 在特定情形下(比如当前步长过小), 若
p
p
p不被滤子所接收, 我们不会继续减少步长
α
s
\alpha_s
αs, 而是调用可行性恢复阶段.
3.6 拟牛顿近似
原始-对偶矩阵的拟牛顿版本是要用拟牛顿近似 B B B替换 ∇ x x 2 L \nabla^2_{xx}\mathcal L ∇xx2L. 我们可以用BFGS或SR1更新公式, 或是使用有限内存BFGS公式定义 B B B. 我们近似非线性规划Lagrange函数的Hessian而不是障碍函数的Hessian, 是因为后者高度病态且变化迅速.
我们这里用 ( δ x , δ l ) (\delta x,\delta l) (δx,δl)表示拟牛顿更新公式使用的校正对. 在计算从 ( x , s , y , z ) (x,s,y,z) (x,s,y,z)到 ( x + , s + , y + , z + ) (x^+,s^+,y^+,z^+) (x+,s+,y+,z+)的迭代步后, 我们定义 Δ l = ∇ x L ( x + , s + , y + , z + ) − ∇ x L ( x , s + , y + , z + ) , Δ x = x + − x . \begin{aligned}\Delta l&=\nabla_x\mathcal L(x^+,s^+,y^+,z^+)-\nabla_x\mathcal L(x,s^+,y^+,z^+),\\\Delta x&=x^+-x.\end{aligned} ΔlΔx=∇xL(x+,s+,y+,z+)−∇xL(x,s+,y+,z+),=x+−x.为确保BFGS算法产生正定阵, 我们可以选择跳步或阻滞策略. 而SR1更新则必须避免无界情形的发生, 且可能需要修正以使得惯性指数条件成立. 此修正可用程序2实现.
以上得到的拟牛顿矩阵 B B B是稠密的 n × n n\times n n×n矩阵. 对于大型的问题, 有限内存的更新更受青睐. 一种实施有限内存BFGS算法的方式是利用第七章介绍的紧表示. 于是 B B B有形式 B = ξ I + W M W T , B=\xi I+WMW^T, B=ξI+WMWT,其中 ξ > 0 \xi>0 ξ>0为尺度因子, W W W为 n × 2 m ^ n\times 2\hat m n×2m^矩阵, M M M为 2 m ^ × 2 m ^ 2\hat m\times 2\hat m 2m^×2m^对称可逆阵, m ^ \hat m m^为有限内存中储存的校正对的个数. W , M W,M W,M使用前 m ^ \hat m m^次迭代累积的 { Δ l k } , { Δ x k } \{\Delta l^k\},\{\Delta x^k\} {Δlk},{Δxk}产生. 因有限内存矩阵 B B B正定且假定 A E A_E AE满秩, 于是原始-对偶矩阵非奇异, 我们可用Sherman-Morrison-Woodbury公式求解修正原始-对偶方程. 事实上, 修正的原始-对偶矩阵可写为 [ ξ I O A E T A I T O Σ O I A E O O O A I I O O ] + [ W O O O ] [ M W T O O O ] . \begin{bmatrix}\xi I & O & A_E^T & A_I^T\\O & \Sigma & O & I\\A_E & O & O & O\\A_I & I & O & O\end{bmatrix}+\begin{bmatrix}W\\O\\O\\O\end{bmatrix}\begin{bmatrix}MW^T & O & O & O\end{bmatrix}. ⎣⎢⎢⎡ξIOAEAIOΣOIAETOOOAITIOO⎦⎥⎥⎤+⎣⎢⎢⎡WOOO⎦⎥⎥⎤[MWTOOO].
3.7 可行内点法
许多应用中, 我们希望算法产生的所有迭代点对某些或所有的不等式约束都是可行的. 例如当目标函数只有在某些约束满足时才有定义.
内点法提供了推导可行算法的一个天然的框架. 若当前迭代点 x x x满足 c I ( x ) > 0 c_I(x)>0 cI(x)>0, 则我们很容易就能对由原始-对偶方程得到的迭代步修改, 使得下一迭代点满足可行性. 具体说来, 在计算 p p p后, 令 x + = x + p x x^+=x+p_x x+=x+px, 重新定义松弛变量为 s + ← c I ( x + ) , s^+\leftarrow c_I(x^+), s+←cI(x+),并检验 ( x + , s + ) (x^+,s^+) (x+,s+)是否为价值函数 ϕ \phi ϕ接受. 若是, 则定义此试探点为新点; 否则拒绝 p p p, 并以更短的步长计算新试探点. 线搜索中我们采取回溯的策略, 而在信赖域算法中我们减小信赖域的半径重新计算新的 p p p. 我们也会拒绝过于靠近信赖域边界的 x + p x x+p_x x+px, 毕竟这样会大大增加价值函数中的障碍项 − μ ∑ i ∈ I log ( s i ) -\mu\sum_{i\in\mathcal{I}}\log(s_i) −μ∑i∈Ilog(si).
4. 线搜索内点法
我们现在给出对线搜索内点法更加详尽的描述. 我们以 D ϕ v ( x , s ; p ) D\phi_v(x,s;p) Dϕv(x,s;p)表示价值函数 ϕ v \phi_v ϕv在 ( x , s ) (x,s) (x,s)处对方向 p p p的方向导数. 停机准则则基于之前定义的误差函数 E E E.
算法3 (Line Search Interior-Point Algorithm)
Choose
x
0
x_0
x0 and
s
0
>
0
s_0>0
s0>0, and compute initial values for the multipliers
y
0
y_0
y0 and
z
0
>
0
z_0>0
z0>0. If a quasi-Newton approach is used, choose an
n
×
n
n\times n
n×n symmetric and positive definite initial matrix
B
0
B_0
B0. Select an initial barrier parameter
μ
>
0
\mu>0
μ>0, parameters
η
,
σ
∈
(
0
,
1
)
\eta,\sigma\in(0,1)
η,σ∈(0,1), and tolerances
ϵ
μ
\epsilon_{\mu}
ϵμ and
ϵ
t
o
l
\epsilon_{tol}
ϵtol. Set
k
←
0
k\leftarrow 0
k←0.
repeat until
E
(
x
k
,
s
k
,
y
k
,
z
k
;
0
)
≤
ϵ
t
o
l
E(x_k,s_k,y_k,z_k;0)\le\epsilon_{tol}
E(xk,sk,yk,zk;0)≤ϵtol
\quad\quad
repeat until
E
(
x
k
,
s
k
,
y
k
,
z
k
;
μ
)
≤
ϵ
μ
E(x_k,s_k,y_k,z_k;\mu)\le\epsilon_{\mu}
E(xk,sk,yk,zk;μ)≤ϵμ
\quad\quad\quad\quad
Compute the primal-dual direction
p
=
(
p
x
,
p
s
,
p
y
,
p
z
)
p=(p_x,p_s,p_y,p_z)
p=(px,ps,py,pz) from primal-dual system, where the coefficient matrix is modified if necessary;
\quad\quad\quad\quad
Compute
α
s
max
,
α
z
max
\alpha_s^{\max},\alpha_z^{\max}
αsmax,αzmax; Set
p
w
=
(
p
x
,
p
s
)
p_w=(p_x,p_s)
pw=(px,ps);
\quad\quad\quad\quad
Compute step lengths
α
s
,
α
z
\alpha_s,\alpha_z
αs,αz satisfying
ϕ
v
(
x
k
+
α
s
p
x
,
s
k
+
α
s
p
s
)
≤
ϕ
v
(
x
k
,
s
k
)
+
η
α
s
D
ϕ
v
(
x
k
,
s
k
;
p
w
)
;
\phi_v(x_k+\alpha_sp_x,s_k+\alpha_sp_s)\le\phi_v(x_k,s_k)+\eta\alpha_sD\phi_v(x_k,s_k;p_w);
ϕv(xk+αspx,sk+αsps)≤ϕv(xk,sk)+ηαsDϕv(xk,sk;pw);
\quad\quad\quad\quad
Compute
(
x
k
+
1
,
s
k
+
1
,
y
k
+
1
,
z
k
+
1
)
(x_{k+1},s_{k+1},y_{k+1},z_{k+1})
(xk+1,sk+1,yk+1,zk+1);
\quad\quad\quad\quad
if a quasi-Newton approach is used
\quad\quad\quad\quad\quad\quad
update the approximation
B
k
B_k
Bk;
\quad\quad\quad\quad
Set
k
←
k
+
1
k\leftarrow k+1
k←k+1;
\quad\quad
end
\quad\quad
Set
μ
←
σ
μ
\mu\leftarrow\sigma\mu
μ←σμ and update
ϵ
μ
\epsilon_{\mu}
ϵμ;
end
障碍容忍限可以定义成如算法1中的 ϵ μ = μ \epsilon_{\mu}=\mu ϵμ=μ. 此算法框架中我们可以方便地使用自适应更新障碍因子 μ \mu μ的策略. 若价值函数可能会引发Maratos效应, 则需要做二阶校正或采取非单调策略. 我们还可以用滤子替代价值函数.
我们在第7节会看到, 算法3必须加上防护措施才能保证有全局收敛性.
5. 信赖域内点法
我们现在考虑使用信赖域增强收敛性的内点法. 正如在无约束情形中, 信赖域框架给予了Hessian选取很大的自由度, 并且提供了一种处理Jacobi阵和Hessian阵奇异的机制. 当然为此我们需要比线搜索更复杂的迭代过程.
下面要介绍的内点法渐进等价于第4节中的线搜索内点法, 但在两个方面与之有较大的不同. 首先前者不完全是原始-对偶算法, 因为它会先计算变量 ( x , s ) (x,s) (x,s)的迭代步, 再对乘子做更新. 其次, 信赖域算法使用对变量做了尺度变换, 使变量不会跑向可行域的边界. 这使得算法产生的迭代步与线搜索的不同, 且具有更好的收敛性质.
我们首先给出近似求解一个固定障碍问题的信赖域算法. 之后再给出完整的算法.
5.1 求解障碍问题的算法
障碍问题是等式约束的问题, 可用带信赖域约束的SQP求解. 然而直接对障碍问题使用SQP会得到违反松弛变量正约束的迭代步, 且迭代步还会频繁地被信赖域约束截断. 为克服此困难, 我们设计一种针对障碍问题特殊结构的SQP算法.
在 ( x , s ) (x,s) (x,s)处, 对给定的障碍因子 μ \mu μ, 我们首先计算Lagrang乘子估计 ( y , z ) (y,z) (y,z), 再计算近似求解以下子问题的 p = ( p x , p s ) p=(p_x,p_s) p=(px,ps): min p x , p s ∇ f T p x + 1 2 p x T ∇ x x 2 L p x − μ e T S − 1 p s + 1 2 p s T Σ p s s u b j e c t t o A E ( x ) p x + c E ( x ) = r E , A I ( x ) p x − p s + ( c I ( x ) − s ) = r I , ∥ ( p x , S − 1 p s ) ∥ 2 ≤ Δ , p s ≥ − τ s . \begin{array}{rl}\min\limits_{p_x,p_s} & \nabla f^Tp_x + \frac{1}{2}p_x^T\nabla^2_{xx}\mathcal Lp_x-\mu e^TS^{-1}p_s+\frac{1}{2}p_s^T\Sigma p_s\\\mathrm{subject\,to} & A_E(x)p_x+c_E(x)=r_E,\\& A_I(x)p_x-p_s+(c_I(x)-s)=r_I,\\& \Vert(p_x,S^{-1}p_s)\Vert_2\le\Delta,\\&p_s\ge-\tau s.\end{array} px,psminsubjectto∇fTpx+21pxT∇xx2Lpx−μeTS−1ps+21psTΣpsAE(x)px+cE(x)=rE,AI(x)px−ps+(cI(x)−s)=rI,∥(px,S−1ps)∥2≤Δ,ps≥−τs.这里 Σ \Sigma Σ为原始-对偶阵中的子块, 标量 τ ∈ ( 0 , 1 ) \tau\in(0,1) τ∈(0,1)靠近1(如0.995). 不等式约束 p s ≥ − τ s p_s\ge-\tau s ps≥−τs的作用与分数到边准则相同. 理想状态下, 我们希望设 r = ( r E , r I ) = 0 r=(r_E,r_I)=0 r=(rE,rI)=0, 但这可能会使得约束不相容或是减少可行性上可以获得的改进. 因此我们额外地需要再计算 r r r. 可见第十八章算法4.
注意目标函数的选取是基于这样一个事实: 上述子问题前三行的KKT条件与原非线性规划的相同(互补条件差一个尺度变换
S
−
1
S^{-1}
S−1). 因此子问题得到的迭代步与原始-对偶线搜索的关系就像是SQP和第十八章第1节Newton-Lagrange步的关系.
信赖域的约束保证了即使
∇
x
x
2
L
(
x
,
s
,
y
,
z
)
\nabla^2_{xx}\mathcal L(x,s,y,z)
∇xx2L(x,s,y,z)不是正定的, 问题也有有限的解, 因此Hessian阵不需要修改. 另外, 信赖域的构造保证了每一次迭代都有一定的改进. 因为信赖域的形状必须考虑不让松弛变量过早接近0, 所以约束中使用了
S
−
1
S^{-1}
S−1. 这样就限制了
s
s
s中靠近下界0的分量对应的
p
s
p_s
ps. 下面我们还会看到, 这对松弛向量
r
E
,
r
I
r_E,r_I
rE,rI的选取也有重要作用.
我们给出信赖域SQP算法的大概描述. 停机准则以误差函数 E E E定义, 价值函数 ϕ v \phi_v ϕv可用之前的, 使用2-范数.
算法4 (Trust-Region Algorithm for Barrier Problems)
Input parameters:
μ
>
0
,
x
0
,
s
0
>
0
,
ϵ
μ
\mu>0,x_0,s_0>0,\epsilon_{\mu}
μ>0,x0,s0>0,ϵμ, and
Δ
0
>
0
\Delta_0>0
Δ0>0. Compute Lagrange multiplier estimates
y
0
y_0
y0 and
z
0
>
0
z_0>0
z0>0. Set
k
←
0
k\leftarrow 0
k←0.
repeat until
E
(
x
k
,
s
k
,
y
k
,
z
k
;
μ
)
≤
ϵ
μ
E(x_k,s_k,y_k,z_k;\mu)\le\epsilon_{\mu}
E(xk,sk,yk,zk;μ)≤ϵμ
\quad\quad
Compute
p
=
(
p
x
,
p
s
)
p=(p_x,p_s)
p=(px,ps) by approximately solving subproblem.
\quad\quad
if
p
p
p provides sufficient decrease in the merit function
ϕ
v
\phi_v
ϕv
\quad\quad\quad\quad
Set
x
k
+
1
←
x
k
+
p
x
,
s
k
+
1
←
s
k
+
p
s
x_{k+1}\leftarrow x_k+p_x,s_{k+1}\leftarrow s_k+p_s
xk+1←xk+px,sk+1←sk+ps;
\quad\quad\quad\quad
Compute new multiplier estimates
y
k
+
1
,
z
k
+
1
>
0
y_{k+1},z_{k+1}>0
yk+1,zk+1>0 and set
Δ
k
+
1
≥
Δ
k
\Delta_{k+1}\ge\Delta_k
Δk+1≥Δk;
\quad\quad
else
\quad\quad\quad\quad
Define
x
k
+
1
←
x
k
,
s
k
+
1
←
s
k
x_{k+1}\leftarrow x_k,s_{k+1}\leftarrow s_k
xk+1←xk,sk+1←sk, and set
Δ
k
+
1
<
Δ
k
\Delta_{k+1}<\Delta_k
Δk+1<Δk;
\quad\quad
end
\quad\quad
Set
k
←
k
+
1
k\leftarrow k+1
k←k+1;
end (repeat))
算法4用于固定的 μ \mu μ. 而完整的内点法算法则需要 { μ k } → 0 \{\mu_k\}\to0 {μk}→0. 首先我们讨论如何近似求解子问题, 以及如何计算Lagrange乘子估计 ( y k + 1 , z k + 1 ) (y_{k+1},z_{k+1}) (yk+1,zk+1).
5.2 迭代步的计算
因为有非线性约束和下界的存在, 子问题是很难精确求解的. 但我们可以以适当的计算量计算有用的精确解. 由于此法对变量和约束的个数不敏感, 因此这提供了一种大规模情形的实用内点法框架.
首先我们要做变量替换, 使信赖域约束变成球状. 定义 p ~ = [ p x p ~ s ] = [ p x S − 1 p s ] , \tilde p=\begin{bmatrix}p_x\\\tilde p_s\end{bmatrix}=\begin{bmatrix}p_x\\S^{-1}p_s\end{bmatrix}, p~=[pxp~s]=[pxS−1ps],我们可以将子问题写成 min p x , p ~ s ∇ f T p x + 1 2 p x T ∇ x x 2 L p x − μ e T p ~ s + 1 2 p ~ s T S Σ S p ~ s s u b j e c t t o A E ( x ) p x + c E ( x ) = r E , A I ( x ) p x − S p ~ s + ( c I ( x ) − s ) = r I , ∥ ( p x , p ~ s ) ∥ 2 ≤ Δ , p ~ s ≥ − τ e . \begin{array}{rl}\min\limits_{p_x,\tilde p_s} & \nabla f^Tp_x+\frac{1}{2}p_x^T\nabla^2_{xx}\mathcal Lp_x-\mu e^T\tilde p_s+\frac{1}{2}\tilde p_s^TS\Sigma S\tilde p_s\\\mathrm{subject\,to} & A_E(x)p_x+c_E(x)=r_E,\\&A_I(x)p_x-S\tilde p_s+(c_I(x)-s)=r_I,\\&\Vert(p_x,\tilde p_s)\Vert_2\le\Delta,\\&\tilde p_s\ge-\tau e.\end{array} px,p~sminsubjectto∇fTpx+21pxT∇xx2Lpx−μeTp~s+21p~sTSΣSp~sAE(x)px+cE(x)=rE,AI(x)px−Sp~s+(cI(x)−s)=rI,∥(px,p~s)∥2≤Δ,p~s≥−τe.为计算 r E , r I r_E,r_I rE,rI, 我们按第十八章第5节中的策略, 构造附加子问题: min v ∥ A E ( x ) v x + c E ( x ) ∥ 2 2 + ∥ A I ( x ) v x − S v s + ( c I ( x ) − s ) ∥ 2 2 s u b j e c t t o ∥ ( v x , v s ) ∥ 2 ≤ 0.5 Δ , v s ≥ − ( τ / 2 ) e . \begin{array}{rl}\min\limits_v & \Vert A_E(x)v_x+c_E(x)\Vert_2^2+\Vert A_I(x)v_x-Sv_s+(c_I(x)-s)\Vert_2^2\\\mathrm{subject\,to} & \Vert (v_x,v_s)\Vert_2\le0.5\Delta,\\&v_s\ge-(\tau/2)e.\end{array} vminsubjectto∥AE(x)vx+cE(x)∥22+∥AI(x)vx−Svs+(cI(x)−s)∥22∥(vx,vs)∥2≤0.5Δ,vs≥−(τ/2)e.如果我们忽略下界约束, 则这就是个标准的信赖域问题, 我们可用第四章的技术求解. 如果解违反了下界约束, 就进行回溯. 我们不需要精确地求解这个附加子问题, 我们只需要 r E , r I r_E,r_I rE,rI对于约束是可行的.
求解完附加子问题后, 定义 r E = A E ( x ) v x + c E ( x ) , r I = A I ( x ) v x − S v s + ( c I ( x ) − s ) . r_E=A_E(x)v_x+c_E(x),\quad r_I=A_I(x)v_x-Sv_s+(c_I(x)-s). rE=AE(x)vx+cE(x),rI=AI(x)vx−Svs+(cI(x)−s).现在近似求解子问题得到 d ~ \tilde d d~. 由 r E , r I r_E,r_I rE,rI的定义, v v v是等式线性约束的特解. 我们可以用投影CG求解等式约束的二次规划, 而用Steihaug的策略停止迭代: 在CG迭代的过程中, 检测信赖域约束, 若此约束被打破或是遇到了负曲率, 亦或是求得了近似解, 就停止. 若由投影CG得到的解不满足 p ~ s ≥ − τ e \tilde p_s\ge-\tau e p~s≥−τe, 我们就做回溯直到它满足. 计算完 ( p x , p ~ s ) (p_x,\tilde p_s) (px,p~s)后, 再变换回去得到 p p p.
每步投影CG迭代都需要求解线性系统. 对于等式约束的子问题, 投影矩阵为 [ I A ^ T A ^ O ] , A ^ = [ A E ( x ) O A I ( x ) − S ] . \begin{bmatrix}I & \hat A^T\\\hat A & O\end{bmatrix},\quad \hat A=\begin{bmatrix}A_E(x) & O\\A_I(x) & -S\end{bmatrix}. [IA^A^TO],A^=[AE(x)AI(x)O−S].因此尽管此信赖域方法仍然需要求解增广系统, 但这里的系数矩阵要比原始-对偶矩阵简单. 特别地, 我们不需要去分解Hessian阵 ∇ x x 2 L \nabla^2_{xx}\mathcal L ∇xx2L, 因为CG仅需要矩阵-向量乘积.
我们在第3节提到 S Σ S S\Sigma S SΣS的特征值分布要比 Σ \Sigma Σ更紧凑. 因此, CG通常不会被病态所影响, 从而是求解子问题二次规划的可行方法.
5.3 Lagrange乘子估计和步长接收
在迭代点 ( x , s ) (x,s) (x,s)处, 我们选取 ( y , z ) (y,z) (y,z)为最小二乘乘子估计: [ y z ] = ( A ^ A ^ T ) − 1 A ^ [ ∇ f ( x ) − μ e ] . \begin{bmatrix}y\\z\end{bmatrix}=\left(\hat A\hat A^T\right)^{-1}\hat A\begin{bmatrix}\nabla f(x)\\-\mu e\end{bmatrix}. [yz]=(A^A^T)−1A^[∇f(x)−μe].这样估计得到的 z z z可能不总是正的. 为此, 我们重新定义负的分量为 z i ← min ( 1 0 − 3 , μ / s i ) , i = 1 , 2 , … , m . z_i\leftarrow\min(10^{-3},\mu/s_i),\quad i=1,2,\ldots,m. zi←min(10−3,μ/si),i=1,2,…,m.这里 μ / s i \mu/s_i μ/si称作是第 i i i个原始乘子估计, 因为若所有的 z z z的分量都用上述式子定义, 则 Σ \Sigma Σ就变成了原始模式下的 Σ \Sigma Σ.
与标准信赖域方法相同, p p p被接收若 a r e d ( p ) ≥ η p r e d ( p ) , \mathrm{ared}(p)\ge\eta\mathrm{pred}(p), ared(p)≥ηpred(p),其中 a r e d ( p ) = ϕ v ( x , s ) − ϕ v ( x + p x , s + p s ) , \mathrm{ared}(p)=\phi_v(x,s)-\phi_v(x+p_x,s+p_s), ared(p)=ϕv(x,s)−ϕv(x+px,s+ps), η \eta η为 ( 0 , 1 ) (0,1) (0,1)中的常数(比如 η = 1 0 − 8 \eta=10^{-8} η=10−8). 预测下降量为 p r e d ( p ) = q v ( 0 ) − q v ( p ) , \mathrm{pred}(p)=q_v(0)-q_v(p), pred(p)=qv(0)−qv(p),其中 q v ( p ) = ∇ f T p x + 1 2 p x T ∇ x x 2 L p x − μ e T S − 1 p s + 1 2 p s T Σ p s + v m ( p ) , q_v(p)=\nabla f^Tp_x+\frac{1}{2}p_x^T\nabla^2_{xx}\mathcal{L}p_x-\mu e^TS^{-1}p_s+\frac{1}{2}p_s^T\Sigma p_s+vm(p), qv(p)=∇fTpx+21pxT∇xx2Lpx−μeTS−1ps+21psTΣps+vm(p), m ( p ) = ∥ [ A E ( x ) p x + c E ( x ) A I ( x ) p x − p s + c I ( x ) − s ] ∥ 2 . m(p)=\left\Vert\begin{bmatrix}A_E(x)p_x+c_E(x)\\A_I(x)p_x-p_s+c_I(x)-s\end{bmatrix}\right\Vert_2. m(p)=∥∥∥∥[AE(x)px+cE(x)AI(x)px−ps+cI(x)−s]∥∥∥∥2.为确定惩罚因子 v v v的值, 我们要求 v v v充分大使得 p r e d ( p ) ≥ ρ v ( m ( 0 ) − m ( p ) ) , ρ ∈ ( 0 , 1 ) . \mathrm{pred}(p)\ge\rho v(m(0)-m(p)),\quad\rho\in(0,1). pred(p)≥ρv(m(0)−m(p)),ρ∈(0,1).这与第十八章中相同.
5.4 信赖域内点法
现在我们给出求解非线性规划问题信赖域内点法更加详尽的描述. 我们采用Fiacco-McCormick策略更新障碍因子. 停机准则依然考虑误差函数 E E E. 若使用拟牛顿算法, Hessian阵 ∇ x x 2 L \nabla^2_{xx}\mathcal L ∇xx2L就用一对称矩阵近似.
算法5 (Trust-Region Interior-Point Algorithm)
Choose a value for the parameters
η
>
0
,
τ
∈
(
0
,
1
)
,
σ
∈
(
0
,
1
)
,
\eta>0,\tau\in(0,1),\sigma\in(0,1),
η>0,τ∈(0,1),σ∈(0,1), and
ζ
∈
(
0
,
1
)
\zeta\in(0,1)
ζ∈(0,1), and select the stopping telerances
ϵ
μ
,
ϵ
t
o
l
\epsilon_{\mu},\epsilon_{tol}
ϵμ,ϵtol. If a quasi-Newton approach is used, select an
n
×
n
n\times n
n×n symmetric initial matrix
B
0
B_0
B0. Choose initial values for
μ
>
0
,
x
0
,
s
0
>
0
\mu>0,x_0,s_0>0
μ>0,x0,s0>0, and
Δ
0
\Delta_0
Δ0. Set
k
←
0
k\leftarrow 0
k←0.
repeat until
E
(
x
k
,
s
k
,
y
k
,
z
k
;
0
)
≤
ϵ
t
o
l
E(x_k,s_k,y_k,z_k;0)\le\epsilon_{tol}
E(xk,sk,yk,zk;0)≤ϵtol
\quad\quad
repeat until
E
(
x
k
,
s
k
,
y
k
,
z
k
;
μ
)
≤
ϵ
μ
E(x_k,s_k,y_k,z_k;\mu)\le\epsilon_{\mu}
E(xk,sk,yk,zk;μ)≤ϵμ
\quad\quad\quad\quad
Compute Lagrange multipliers by least-squares;
\quad\quad\quad\quad
Compute
∇
x
x
2
L
(
x
k
,
s
k
,
y
k
,
z
k
)
\nabla^2_{xx}\mathcal L(x_k,s_k,y_k,z_k)
∇xx2L(xk,sk,yk,zk) or update a quasi-Newton approximation
B
k
B_k
Bk, and define
Σ
k
\Sigma_k
Σk;
\quad\quad\quad\quad
Compute the normal step
v
k
=
(
v
x
,
v
s
)
v_k=(v_x,v_s)
vk=(vx,vs);
\quad\quad\quad\quad
Compute
p
~
k
\tilde p_k
p~k by applying the projected CG method to the subproblem;
\quad\quad\quad\quad
Obtain the total step
p
k
p_k
pk;
\quad\quad\quad\quad
Update
v
k
v_k
vk;
\quad\quad\quad\quad
Compute
p
r
e
d
k
(
p
k
)
,
a
r
e
d
k
(
p
k
)
\mathrm{pred}_k(p_k),\mathrm{ared}_k(p_k)
predk(pk),aredk(pk);
\quad\quad\quad\quad
if
a
r
e
d
k
(
p
k
)
≥
η
p
r
e
d
k
(
p
k
)
\mathrm{ared}_k(p_k)\ge\eta\mathrm{pred}_k(p_k)
aredk(pk)≥ηpredk(pk)
\quad\quad\quad\quad\quad\quad
Set
x
k
+
1
←
x
k
+
p
x
,
s
k
+
1
←
s
k
+
p
s
x_{k+1}\leftarrow x_k+p_x,s_{k+1}\leftarrow s_k+p_s
xk+1←xk+px,sk+1←sk+ps;
\quad\quad\quad\quad\quad\quad
Choose
Δ
k
+
1
≥
Δ
k
\Delta_{k+1}\ge\Delta_k
Δk+1≥Δk;
\quad\quad\quad\quad
else
\quad\quad\quad\quad\quad\quad
Set
x
k
+
1
=
x
k
,
s
k
+
1
=
s
k
x_{k+1}=x_k,s_{k+1}=s_k
xk+1=xk,sk+1=sk; and choose
Δ
k
+
1
<
Δ
k
\Delta_{k+1}<\Delta_k
Δk+1<Δk;
\quad\quad\quad\quad
end (if)
\quad\quad\quad\quad
Set
k
←
k
+
1
k\leftarrow k+1
k←k+1;
\quad\quad
end
\quad\quad
Set
μ
←
σ
μ
\mu\leftarrow\sigma\mu
μ←σμ and update
ϵ
μ
\epsilon_{\mu}
ϵμ;
end
为避免Maratos效应, 我们可以选择性地加入二阶校正. 障碍因子的更新也可采用自适应的策略.
6. 原始对数障碍函数法
在原始-对偶内点法之前, 障碍函数法是在原始变量 x x x的空间上运行的. 如同第十七章中的二次罚函数法, 这里的目标是要通过求解一系列无约束极小来求解非线性规划问题.
原始障碍函数法在不等式约束问题中更好表述:
min
x
f
(
x
)
,
s
u
b
j
e
c
t
t
o
c
(
x
)
≥
0.
\min\limits_xf(x),\quad\mathrm{subject\,to\,}c(x)\ge0.
xminf(x),subjecttoc(x)≥0.
对数障碍函数则定义为
P
(
x
;
μ
)
=
f
(
x
)
−
μ
∑
i
∈
I
log
c
i
(
x
)
,
P(x;\mu)=f(x)-\mu\sum_{i\in\mathcal{I}}\log c_i(x),
P(x;μ)=f(x)−μi∈I∑logci(x),其中
μ
>
0
\mu>0
μ>0. 我们可以证明在一定条件下,
P
(
x
;
μ
)
P(x;\mu)
P(x;μ)的极小点
x
(
μ
)
x(\mu)
x(μ)在
μ
↓
0
\mu\downarrow0
μ↓0时趋近解. 轨迹
C
p
\mathcal C_p
Cp定义为
C
p
=
d
e
f
{
x
(
μ
)
∣
μ
>
0
}
,
\mathcal C_p\xlongequal{def}\{x(\mu)\mid \mu>0\},
Cpdef{x(μ)∣μ>0},称为原始中心路径(primal central path).
由于 x ( μ ) x(\mu) x(μ)严格落在可行集 { x ∣ c ( x ) > 0 } \{x\mid c(x)>0\} {x∣c(x)>0}中, 原则上我们可以用任何一种无约束极小的算法求之. 但这些都需要一定的修正, 从而能够拒绝离开可行集边界或靠近边界的迭代步.
一种求Lagrange乘子估计的方法基于对 P P P的求导: ∇ x P ( x ; μ ) = ∇ f ( x ) − ∑ i ∈ I μ c i ( x ) ∇ c i ( x ) . \nabla_xP(x;\mu)=\nabla f(x)-\sum_{i\in\mathcal{I}}\frac{\mu}{c_i(x)}\nabla c_i(x). ∇xP(x;μ)=∇f(x)−i∈I∑ci(x)μ∇ci(x).当 x x x靠近 x ( μ ) x(\mu) x(μ)且 μ \mu μ很小时, 最优Lagrange乘子 z i ∗ , i ∈ I z_i^*,i\in\mathcal{I} zi∗,i∈I就可如下估计: z i ∗ ≈ μ / c i ( x ) , i ∈ I . z_i^*\approx\mu/c_i(x),\quad i\in\mathcal{I}. zi∗≈μ/ci(x),i∈I.一种基于原始对数障碍函数的一般算法框架如下.
框架6 (Unconstrained Primal Barrier Method)
Given
μ
0
>
0
\mu_0>0
μ0>0, a sequence
{
τ
k
}
\{\tau_k\}
{τk} with
τ
k
→
0
\tau_k\to0
τk→0, and a starting point
x
0
s
x_0^s
x0s;
for
k
=
0
,
1
,
2
,
…
k=0,1,2,\ldots
k=0,1,2,…
\quad\quad
Find an approximate minimizer
x
k
x_k
xk of
P
(
⋅
;
μ
k
)
P(\cdot;\mu_k)
P(⋅;μk), starting at
x
k
s
x_k^s
xks, and terminating when
∥
∇
P
(
x
k
;
μ
k
)
∥
≤
τ
k
\Vert\nabla P(x_k;\mu_k)\Vert\le\tau_k
∥∇P(xk;μk)∥≤τk;
\quad\quad
Compute Lagrange multipliers
z
k
z_k
zk;
\quad\quad
if final convergence test satisfied
\quad\quad\quad\quad
stop with approximate solution
x
k
x_k
xk;
\quad\quad
Choose new penalty parameter
μ
k
+
1
<
μ
k
\mu_{k+1}<\mu_k
μk+1<μk;
\quad\quad
Choose new starting point
x
k
+
1
s
x_{k+1}^s
xk+1s;
end (for)
原始障碍函数法由Frisch在上世纪五十年代首次提出, 由Fiacco和McCormick在六十年代末分析与推广. 在SQP算法引入后它便淡出了人们的视线, 且由于比之原始-对偶内点法, 它具有诸多缺陷, 于是它再也没有重得重视. 这里最大的缺陷就是 x ( μ ) x(\mu) x(μ)在 μ ↓ 0 \mu\downarrow0 μ↓0时由于 P ( x ; μ ) P(x;\mu) P(x;μ)的非线性性变得越来越难求得.
例1 考虑问题
min
(
x
1
+
0.5
)
2
+
(
x
2
−
0.5
)
2
,
s
u
b
j
e
c
t
t
o
x
1
∈
[
0
,
1
]
,
x
2
∈
[
0
,
1
]
,
\min\,(x_1+0.5)^2+(x_2-0.5)^2,\quad\mathrm{subject\,to\,}x_1\in[0,1],x_2\in[0,1],
min(x1+0.5)2+(x2−0.5)2,subjecttox1∈[0,1],x2∈[0,1],此时原始障碍函数为
P
(
x
;
μ
)
=
(
x
1
+
0.5
)
2
+
(
x
2
−
0.5
)
2
−
μ
[
log
x
1
+
log
(
1
−
x
1
)
+
log
x
2
+
log
(
1
−
x
2
)
]
.
P(x;\mu)=(x_1+0.5)^2+(x_2-0.5)^2-\mu[\log x_1+\log(1-x_1)+\log x_2+\log(1-x_2)].
P(x;μ)=(x1+0.5)2+(x2−0.5)2−μ[logx1+log(1−x1)+logx2+log(1−x2)].次函数在
μ
=
0.01
\mu=0.01
μ=0.01时的等高线如下图所示.
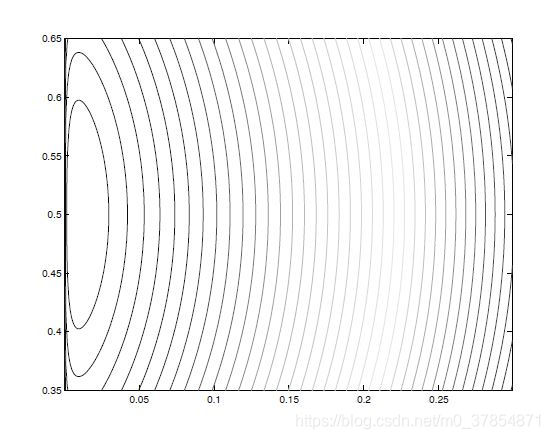
细长的等高线表明问题较为病态, 这使得一些无约束优化的算法表现不好, 比如拟牛顿法、最速下降法和共轭梯度法. 牛顿法对于尺度变换不敏感, 但图中的等高线显然不好用二次模型近似. 这就使得牛顿步不能很好得抓住障碍函数的特质. 因此除非在解的一个小邻域内, 否则牛顿法的收敛速度也不会很快.
为减缓非线性性带来的影响, 我们可以仿照第十七章的做法, 引入额外的变量. 定义 z i = μ / c i ( x ) z_i=\mu/c_i(x) zi=μ/ci(x), 我们就可以将稳定性条件重新写作 ∇ f ( x ) − ∑ i ∈ I z i ∇ c i ( x ) = 0 , C ( x ) z − μ e = 0 , \begin{aligned}\nabla f(x)-\sum_{i\in\mathcal{I}}z_i\nabla c_i(x)&=0,\\C(x)z-\mu e&=0,\end{aligned} ∇f(x)−i∈I∑zi∇ci(x)C(x)z−μe=0,=0,其中 C ( x ) = d i a g ( c 1 ( x ) , c 2 ( x ) , … , c m ( x ) ) C(x)=\mathrm{diag}(c_1(x),c_2(x),\ldots,c_m(x)) C(x)=diag(c1(x),c2(x),…,cm(x)). 注意若我们再额外添加松弛变量, 此系统就等价于扰动KKT条件. 最终若对变量 ( x , s , z ) (x,s,z) (x,s,z)使用牛顿法, 并暂时忽略 s , z ≥ 0 s,z\ge0 s,z≥0, 我们就得到了原始-对偶的构造. 因此事后看来, 我们可以将原始对数障碍函数法转变成原始-对偶线搜索算法或是信赖域算法.
经典的原始障碍函数法的其他缺陷为, 它需要一可行的初始点, 而这在许多情形下是很难得到的. 同时将等式约束包含进原始函数中也比较成问题. 如果采用二次罚项, 则又会有与二次惩罚函数类似的问题.
多年来, 原始障碍函数法的缺陷被归结为 P P P的病态Hessian阵. 注意到 ∇ x x 2 P ( x ; μ ) = ∇ 2 f ( x ) − ∑ i ∈ I μ c i ( x ) ∇ 2 c i ( x ) + ∑ i ∈ I μ c i 2 ( x ) ∇ c i ( x ) ∇ c i ( x ) T . \nabla^2_{xx}P(x;\mu)=\nabla^2f(x)-\sum_{i\in\mathcal{I}}\frac{\mu}{c_i(x)}\nabla^2c_i(x)+\sum_{i\in\mathcal{I}}\frac{\mu}{c_i^2(x)}\nabla c_i(x)\nabla c_i(x)^T. ∇xx2P(x;μ)=∇2f(x)−i∈I∑ci(x)μ∇2ci(x)+i∈I∑ci2(x)μ∇ci(x)∇ci(x)T.将乘子的估计代入并利用Lagrange函数 L ( x , z ) \mathcal L(x,z) L(x,z)的定义, 我们有 ∇ x x 2 P ( x ; μ ) ≈ ∇ x x 2 L ( x , z ∗ ) + ∑ i ∈ I 1 μ ( z i ∗ ) 2 ∇ c i ( x ) ∇ c i ( x ) T . \nabla^2_{xx}P(x;\mu)\approx\nabla^2_{xx}\mathcal L(x,z^*)+\sum_{i\in\mathcal{I}}\frac{1}{\mu}(z_i^*)^2\nabla c_i(x)\nabla c_i(x)^T. ∇xx2P(x;μ)≈∇xx2L(x,z∗)+i∈I∑μ1(zi∗)2∇ci(x)∇ci(x)T.这与二次罚函数的Hessian比较相似. 类似地对 ∇ x x 2 P ( x ; μ ) \nabla^2_{xx}P(x;\mu) ∇xx2P(x;μ)进行分析也会发现它在解 x ( μ ) x(\mu) x(μ)附近随着 μ \mu μ趋于0时会愈发病态.
这种病态会对最速下降法、共轭梯度法或是拟牛顿法的效率造成毁灭性的影响. 因此将这些无约束算法造成的问题归结为病态时正确的. 但牛顿法则是不受尺度影响的, 但它的表现仍然不尽人意. 如上面解释的,此时 P P P的高度非线性性会给牛顿法造成巨大的困难.
7. 全局收敛性质
我们现在讨论原始-对偶内点法的一些全局收敛性质. 定理1是分析的开端. 它给出了由内点法产生的迭代点的聚点时非线性问题的KKT点的条件. 定理1假设对每个 μ k \mu_k μk, 扰动KKT条件都(在一定精度下)被满足. 本节我们就讨论在什么情况下这样的假设时成立的.
我们首先给出一个令人惊叹的事实. 尽管线搜索原始-对偶算法是线性和二次规划全局收敛的内点法的基础, 但在非线性规划中(即使是在非退化的问题上)它并不保证有效.
7.1 线搜索方法的失效
我们在第十一章说到, 当Jacobi阵亏秩时, 非线性方程的牛顿迭代可能会失效. 我们现在讨论内点法的例子. 具体说来, 失效的原因是没有很好地协调步长计算和界的控制.
例2 考虑问题
min
x
s
u
b
j
e
c
t
t
o
c
1
(
x
)
−
s
=
d
e
f
x
2
−
s
1
−
1
=
0
,
c
2
(
x
)
−
s
=
d
e
f
x
−
s
2
−
1
2
=
0
,
s
1
≥
0
,
s
2
≥
0.
\begin{array}{rl}\min & x\\\mathrm{subject\,to} & c_1(x)-s\xlongequal{def}x^2-s_1-1=0,\\&c_2(x)-s\xlongequal{def}x-s_2-\frac{1}{2}=0,\\&s_1\ge0,s_2\ge0.\end{array}
minsubjecttoxc1(x)−sdefx2−s1−1=0,c2(x)−sdefx−s2−21=0,s1≥0,s2≥0.注意不等式约束对
(
x
,
s
)
(x,s)
(x,s)的Jacobi处处是满秩的. 我们使用线搜索内点法, 从初始点
x
(
0
)
x^{(0)}
x(0)出发, 满足
(
s
1
(
0
)
,
s
2
(
0
)
)
>
0
,
c
1
(
x
(
0
)
)
−
s
(
0
)
≥
0
(s_1^{(0)},s_2^{(0)})>0,c_1(x^{(0)})-s^{(0)}\ge0
(s1(0),s2(0))>0,c1(x(0))−s(0)≥0. 下图在
x
−
s
1
x-s_1
x−s1平面上形象地表现了可行域和初始点.
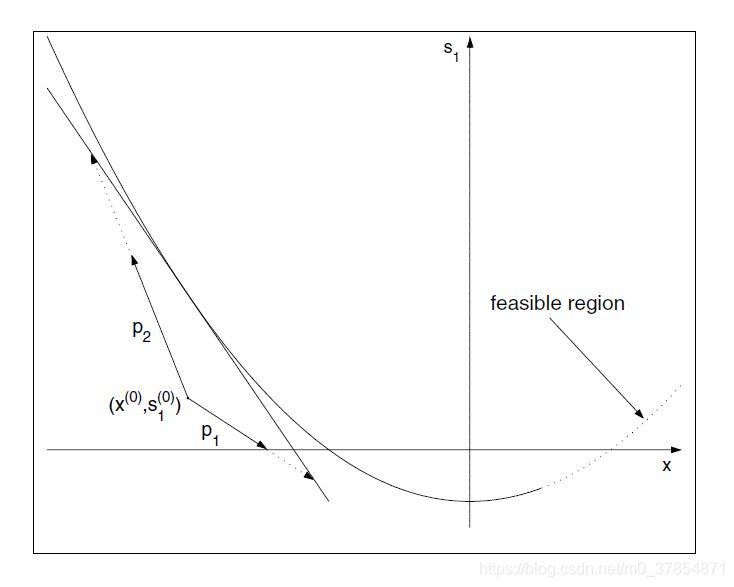
满足线性化约束的原始-对偶步会从 x ( 0 ) x^{(0)} x(0)出发走向抛物线的切线. 图中 p 1 , p 2 p_1,p_2 p1,p2是满足线性化约束的可能的迭代步. 因此性的迭代点 x ( 1 ) x^{(1)} x(1)位于 x ( 0 ) x^{(0)} x(0)和切线之间. 但由于 s 1 s_1 s1必须保持为正, x ( 1 ) x^{(1)} x(1)会位于横轴的上方. 因此从 { ( x , s 1 , s 2 ) : x 2 − s 1 − 1 ≥ 0 , s 1 ≥ 0 } \{(x,s_1,s_2):x^2-s_1-1\ge0,s_1\ge0\} {(x,s1,s2):x2−s1−1≥0,s1≥0}的任何初始点出发, 下一个迭代点都依然在这个区域. 因此 { x ( k ) } \{x^{(k)}\} {x(k)}将永远不会离开此区域, 从而永远不会成为可行点.
这种潜在的收敛还会影响许多产生满足线性化约束方向, 且强制分数到边准则的算法. 价值函数仅能限制步长过长, 无力解决此困境. 而更新 μ \mu μ的策略也无济于事, 因为以上仅用到了线性化的约束.
上例对区域中所有的初始点, 内点法都收敛到 ( − β , 0 , 0 ) , β > 0 (-\beta,0,0),\beta>0 (−β,0,0),β>0. 换句话说, 算法可能收敛到 { ( x , s 1 , s 2 ) : s 1 ≥ 0 , s 2 ≥ 0 } \{(x,s_1,s_2):s_1\ge0,s_2\ge0\} {(x,s1,s2):s1≥0,s2≥0}边界上的一个不可行、非最优(实际上对于可行性度量也非稳定)的点. 这一点障碍函数法可以避免.
此类例子在实际中很少见, 但这表明了从KKT入手是存在理论缺陷的. 这不一定会表现在收敛失效, 更多地可能是在收敛不是那么地高效.
7.2 修正线搜索方法
为克服这一问题, 处理由Hessian和Jacobi阵奇异性带来的困难, 我们必须在某些情形下修改线搜索内点法的搜索方向. 一种方式是惩罚约束. 这样的惩罚-障碍函数法仅在最近提出, 还没有成熟的实施规则.
在实际中应用地较为成功的一种方式是控制步长 α s , α z \alpha_s,\alpha_z αs,αz. 若它们小于给定的阈值, 就不取原始-对偶步, 而是取一步保证能够提升可行性(若可以, 提升最优性). 在滤子法中, 当步长很小时, 我们可以调用可行性恢复阶段, 从而在下一迭代点提升可行性. 一种不同方式则是转而使用信赖域算法, 以信赖域迭代步(算法5)代替原始-对偶步.
以上这些是有理论依据的, 这是因为当线搜索迭代收敛于非稳定点时, 步长 α s , α z \alpha_s,\alpha_z αs,αz将会收敛于0. 从实用的角度来看, 此策略就不总是令人满意. 因为它是在不良迭代步产生后才反应, 而不是直接阻止这样迭代步的产生. 同时, 我们也需要启发式的方法判断步长是否过小. 不过, 下面我们要讨论的信赖域框架, 就总是产生良好的迭代步, 而不需要防护措施.
7.3 信赖域算法的全局收敛性
算法5中的信赖域内点法有良好的全局收敛性. 为说明简单, 我们以不等式约束问题为例分析. 我们先考虑对固定 μ \mu μ的障碍问题的解, 之后再看整个算法.
以下, B k B_k Bk表示Hessian阵 ∇ x x 2 L k \nabla^2_{xx}\mathcal L_k ∇xx2Lk或一拟牛顿近似矩阵. 不可行性度量 h ( x ) = ∥ [ c ( x ) ] − ∥ h(x)=\Vert[c(x)]^{-}\Vert h(x)=∥[c(x)]−∥, 其中 [ y ] = max { 0 , − y } [y]=\max\{0,-y\} [y]=max{0,−y}. 此度量为0当且仅当 x x x为可行点. 注意 h ( x ) 2 h(x)^2 h(x)2可微, 其梯度为 ∇ [ h ( x ) 2 ] = 2 A ( x ) c ( x ) − 1 . \nabla[h(x)^2]=2A(x)c(x)^{-1}. ∇[h(x)2]=2A(x)c(x)−1.我们说序列 { x k } \{x_k\} {xk}渐进可行, 若 c ( x k ) − → 0 c(x_k)^{-}\to0 c(xk)−→0.
定理2 设算法5用于障碍问题, μ \mu μ固定, 内循环 ϵ μ = 0 \epsilon_{\mu}=0 ϵμ=0. 假设序列 { f k } \{f_k\} {fk}下有界且序列 { ∇ f k } , { c k } , { A k } , { B k } \{\nabla f_k\},\{c_k\},\{A_k\},\{B_k\} {∇fk},{ck},{Ak},{Bk}有界. 则下面三种情形必有一个发生:
- 序列 { x k } \{x_k\} {xk}不渐进可行. 此时迭代点趋于不可行性度量 h ( x ) = ∥ c ( x ) − ∥ h(x)=\Vert c(x)^-\Vert h(x)=∥c(x)−∥的稳定点, 这意味着 A k c k − → 0 A_kc_k^-\to0 Akck−→0, 惩罚因子 v k → ∞ v_k\to\infty vk→∞.
- 序列 { x k } \{x_k\} {xk}渐进可行, 但序列 { ( c k , A k ) } \{(c_k,A_k)\} {(ck,Ak)}有聚点 ( γ ˉ , A ˉ ) (\bar\gamma,\bar A) (γˉ,Aˉ)不满足LICQ. 此时也有惩罚因子 v k → ∞ v_k\to\infty vk→∞.
- 序列 { x k } \{x_k\} {xk}渐进可行, 且 { ( c k , A k ) } \{(c_k,A_k)\} {(ck,Ak)}的所有聚点都满足LICQ. 此时对充分大的 k k k, 惩罚因子 v k v_k vk为常数, c k > 0 c_k>0 ck>0. 聚点还满足障碍问题的稳定性条件.
此定理的证明可见Byrd R H, Gilbert J C, Nocedal J2. 此定理给出了KKT条件可能在聚点处不满足的两种情形. 第一种情形中, 在聚点处没有方向可以在一阶上改进可行性. 这种情形是可能的, 这是因为如果没有好的初始点, 局部方法不总是能找到问题的可行点. 第二种情形中, 我们必须记住在某些情形下, 问题的解处不一定有LICQ从而此解不是KKT点. 第三种情形则是我们最想得到的情形. 在实际中, 我们可以通过比如观察惩罚因子 v k v_k vk来控制这种情形.
下面讨论将算法5的完整算法应用到非线性规划问题中. 结合定理1和定理2, 我们知道有以下几种情形可能会发生:
- 对算法产生的某个障碍因子 μ \mu μ, 要么不等式 ∥ c k − s k ∥ ≤ ϵ μ \Vert c_k-s_k\Vert\le\epsilon_{\mu} ∥ck−sk∥≤ϵμ永远不成立, 此时在极限点是 h ( x ) h(x) h(x)的稳定点, 要么 ( c k − s k ) → 0 (c_k-s_k)\to0 (ck−sk)→0, 此时 { ( c k , A k ) } \{(c_k,A_k)\} {(ck,Ak)}有极限点 ( c ˉ , A ˉ ) (\bar c,\bar A) (cˉ,Aˉ), 不满足LICQ;
- 在算法5的每一次外循环中, 内循环退出准则 E ( x k , s k , y k , z k ; μ ) ≤ ϵ μ E(x_k,s_k,y_k,z_k;\mu)\le\epsilon_{\mu} E(xk,sk,yk,zk;μ)≤ϵμ总会成立. 于是迭代点列的所有聚点都是可行的. 进一步, 若有聚点 x ^ \hat x x^满足LICQ, 则 x ^ \hat x x^为非线性规划的KKT点.
8. 超线性收敛性
我们可以使原始-对偶内点法在解附近快速地收敛. 我们只需要仔细地控制障碍因子 μ \mu μ和内循环收敛容忍限 ϵ μ \epsilon_{\mu} ϵμ的下降, 并令 τ \tau τ充分快地收敛到1. 下面我们给出在线搜索迭代中更新这些参数的策略. 这些策略可以方便地扩展到信赖域的框架.
以下我们假设价值函数或滤子是不积极的. 这一假设是现实的, 因为只要小心地实施算法(可能需要二阶校正步或其他的一些策略), 我们就能保证在解附近, 由原始-对偶算法产生的所有迭代点都能被价值函数或滤子所接受.
我们表示原始-对偶迭代点为 v = ( x , s , y , z ) v=(x,s,y,z) v=(x,s,y,z)并定义满原始-对偶步(无回溯)为 v + = v + p , v^+=v+p, v+=v+p,其中 p p p为KKT方程的解. 为构建局部收敛理论, 我们假设迭代点收敛到一个满足一定正则性假设的解.
假设1
- v ∗ v^* v∗为非线性规划的解, 其满足KKT条件.
- Hessian阵 ∇ 2 f ( x ) , ∇ 2 c i ( x ) , i ∈ E ∪ I \nabla^2f(x),\nabla^2c_i(x),i\in\mathcal{E}\cup\mathcal{I} ∇2f(x),∇2ci(x),i∈E∪I在 v ∗ v^* v∗局部Lipschitz连续.
- v ∗ v^* v∗满足LICQ、严格互补松弛条件、二阶充分性条件.
我们假设 v v v为满足内循环终止条件 E ( v , μ ) ≤ ϵ μ E(v,\mu)\le\epsilon_{\mu} E(v,μ)≤ϵμ的点, 障碍因子由 μ \mu μ减少到 μ + \mu^+ μ+. 我们现在讨论如何控制算法3中的参数, 使得以下三个性质在 v ∗ v^* v∗的一邻域成立:
- 迭代点 v + v^+ v+满足分数到边准则, 即 α s max = α z max = 1 \alpha_s^{\max}=\alpha_z^{\max}=1 αsmax=αzmax=1.
- v + v^+ v+满足内循环终止条件, 即 E ( v + ; μ + ) ≤ ϵ μ + E(v^+;\mu^+)\le\epsilon_{\mu^+} E(v+;μ+)≤ϵμ+.
- 迭代点列超线性收敛于 v ∗ v^* v∗.
我们可以令 ϵ μ = θ μ , ϵ μ + = θ μ + , \epsilon_{\mu}=\theta\mu,\quad\epsilon_{\mu^+}=\theta\mu^+, ϵμ=θμ,ϵμ+=θμ+,其中 θ > 0 \theta>0 θ>0, 且设置其他的参数为 μ + = μ 1 + δ , δ ∈ ( 0 , 1 ) ; τ = 1 − μ β , β > δ . \mu^+=\mu^{1+\delta},\delta\in(0,1);\quad\tau=1-\mu^{\beta},\beta>\delta. μ+=μ1+δ,δ∈(0,1);τ=1−μβ,β>δ.当然也有其他的控制参数的方式. 例如, 我们可能更想由KKT条件的满足度(如 E E E)决定 μ \mu μ的改变. 以上三条可证明在 ϵ μ \epsilon_{\mu} ϵμ如上定义, 且以 E ( v ; 0 ) E(v;0) E(v;0)替换上面定义 μ + , τ \mu^+,\tau μ+,τ的 μ \mu μ时, 是成立的.
要满足第二条, μ \mu μ的下降速度是有限度的. 我们可以证明 μ \mu μ不可以快于二次的速度下降, 因为总体的收敛速度不可能快于二次. 自然, 当 τ \tau τ为常数, μ + = σ μ , σ ∈ ( 0 , 1 ) \mu^+=\sigma\mu,\sigma\in(0,1) μ+=σμ,σ∈(0,1)时, 内点法仅为线性收敛.
尽管超线性收敛很好, 但这种收敛往往仅在迭代的最后几步可以观察到.
10. 关于内点法的进一步讨论
一方面, 内点法在大规模的问题上具有优势. 它们在这种问题上往往(但不总是)比积极集法要好. 内点法需要在每次迭代求解一个线性系统, 而此系统的矩阵结构是不变的. 因此我们可以考量这一结构, 设计更好的算法. 直接分解技术和投影CG都是可行的, 这给用户求解问题的自由度带来了许多便利.
另一方面, 内点法不如积极集法, 前者需要在每次迭代考虑所有的约束. 因此原始-对偶迭代在某些问题上可能耗费过大.
内点法的主要缺陷之一是, 它们对于初始点的选取、问题的尺度以及障碍因子 μ \mu μ的更新策略特别敏感. 若迭代点过早地接近了可行域的边界, 内点法就不太容易脱离, 收敛就会比较慢. 不过, 自适应的更新 μ \mu μ的策略已经开始缓解这种敏感性了, 未来将有希望得到更多鲁棒的结果.
A.V. Fiacco and G.P. McCormick, Nonlinear Programming:Sequential Unconstrained Minimization Techniques, John Wiley & Sons, New York, N.Y., 1968. Reprinted by SIAM Publications, 1990. ↩︎
Byrd R H, Gilbert J C, Nocedal J. A Trust Region Method Based on Interior Point Techniques for Nonlinear Programming[J]. 1998. ↩︎

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









