







 本文深入探讨了内点法在优化问题中的应用,包括障碍函数法和原始对偶法两种主要方法。介绍了这两种方法的基本原理、中央路径的概念及其在算法中的作用。
本文深入探讨了内点法在优化问题中的应用,包括障碍函数法和原始对偶法两种主要方法。介绍了这两种方法的基本原理、中央路径的概念及其在算法中的作用。
在面对无约束的优化命题时,我们可以采用牛顿法等方法来求解。而面对有约束的命题时,我们往往需要更高级的算法。单纯形法(Simplex Method)可以用来求解带约束的线性规划命题(LP),与之类似的有效集法(Active Set Method)可以用来求解带约束的二次规划(QP),而内点法(Interior Point Method)则是另一种用于求解带约束的优化命题的方法。而且无论是面对LP还是QP,内点法都显示出了相当的极好的性能,例如多项式的算法复杂度。本文主要介绍两种内点法,障碍函数法(Barrier Method)和原始对偶法(Primal-Dual Method)。其中障碍函数法的内容主要来源于Stephen Boyd与Lieven Vandenberghe的Convex Optimization一书,原始对偶法的内容主要来源于Jorge Nocedal和Stephen J. Wright的Numerical Optimization一书(第二版)。
为了便于与原书对照理解,后面的命题与公式分别采用了对应书中的记法,并且两者方法针对的是不同的命题。两种方法中的同一变量可能在不同的方法中有不同的意义,如 μ 。在介绍玩两种方法后会有一些比较。
障碍函数法(Barrier Method)
对于障碍函数法,我们考虑一个一般性的优化命题:
minsubject tof0(x)fi(x)≤0,i=1,...,mAx=b(1)
这里
f0,...,fm:Rn→R
是二阶可导的凸函数。同时我也要求命题是有解的,即最优解
x∗
存在,且其对应的目标函数为
p∗
。此外,我们还假设原命题是可行的(feasible)。此时,存在最优的对偶变量
λ∗
和
ν∗
,与原始变量
x∗
一道,满足如下的KKT条件:
∇f0(x∗)+∑i=1mλ∗ifi(x∗)+ATν∗Ax∗fi(x)λ∗λ∗ifi(x∗)=0=b≤0,i=1,...,m≥0=0,i=1,...,m(2)
其中,
λ∗ifi(x∗)=0
被称为Complementary Condition。
我们可以看出,KKT条件中的不等式使得对KKT系统的求解难以为继,因此Barrier Method的思想就是通过在原始的目标函数中添加一个障碍函数(也可以理解成惩罚函数)来代替约束条件中的不等式约束。也就是说,把命题(1)变成下面的样子:
minsubject tof0(x)+∑i=1mI−(fi(x))Ax=b(3)
然后我们再考虑
I−(u)
这个函数究竟选择什么样的一种函数好呢,其实最好是像一堵墙的一样的函数,在没有违反约束时,函数值为0,当违反约束时,函数值为正无穷,就像下图中红色虚线这样一个函数
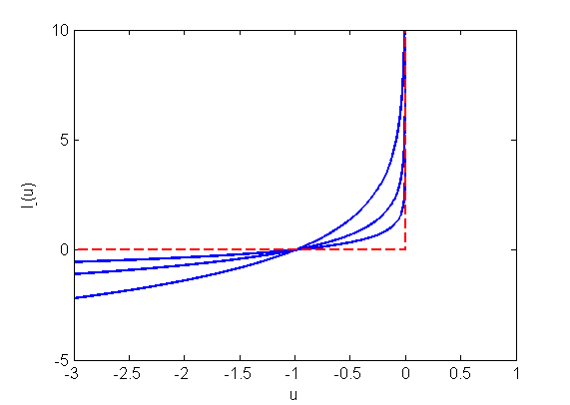
但是很可惜,红色虚线的这个函数在某些点上是不可导的,因此并不适用,那么下面的想法就是用类似的函数,比如上图中的几条蓝色曲线表示的函数来近似这个函数。这样一个近似的函数的表达式如下:
I^−(u)=−(1/t)log(−u)
其中
t
是用于调整近似程度的参数,从上图可以看出,
minsubject tof0(x)+∑i=1m−(1/t)log(−fi(x))Ax=b(4)
这里我们定义如下的对数障碍(logarithmic barrier):
ϕ(x)=−∑i=1mlog(−fi(x))(5)
因此,我们后面的讨论就集中与下面这个命题:
minsubject totf0(x)+ϕ(x)Ax=b(6)
Central Path
针对(6)中不同的 t>0 值,我们定义 x∗(t) 为相应优化命题的解。那么,central path 就是指所有点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









