






SenseVoice介绍
SenseVoice 专注于高精度多语言语音识别、情感辨识和音频事件检测
多语言识别: 采用超过 40 万小时数据训练,支持超过 50 种语言,识别效果上优于 Whisper 模型。
富文本识别:具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。
支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。
高效推理: SenseVoice-Small 模型采用非自回归端到端框架,推理延迟极低,10s 音频推理仅耗时 70ms,15 倍优于 Whisper-Large。
微调定制: 具备便捷的微调脚本与策略,方便用户根据业务场景修复长尾样本问题。
服务部署: 具有完整的服务部署链路,支持多并发请求,支持客户端语言有,python、c++、html、java 与 c# 等。
github地址:
https://github.com/FunAudioLLM/SenseVoice/blob/main/README_zh.md
本文将使用Anaconda虚拟环境启动项目。
Anaconda介绍
conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换。
Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等。
下载地址:https://www.anaconda.com/download-success
没有注册账号的可以使用任一邮箱注册即可,流程简便不在此赘述。
下载如下图安装包即可,下载后安装时间会有点长。
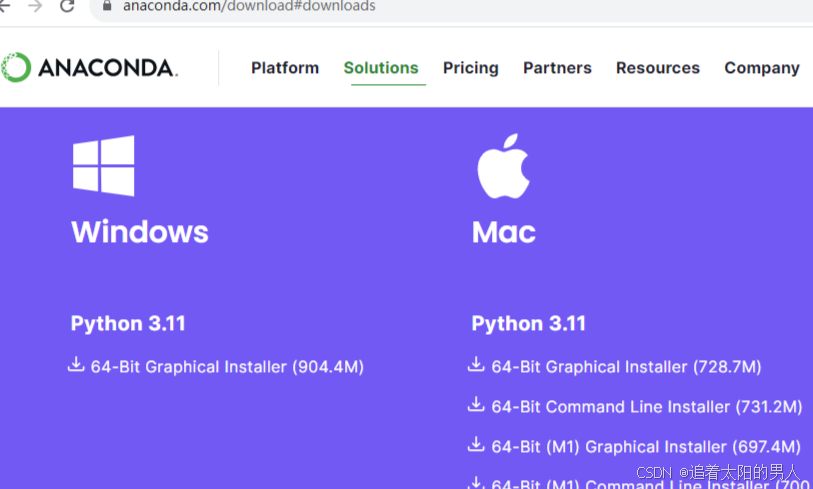
安装后进行命令行检查:打开终端,输入conda --version或which conda命令,如果系统返回Conda的版本信息或路径,则表示Conda已安装。
Conda部署SenseVoice
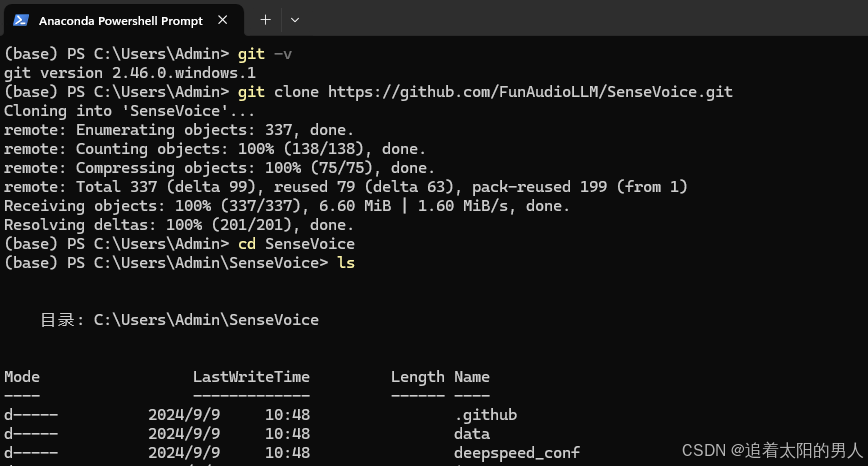
克隆仓库
git clone https://github.com/FunAudioLLM/SenseVoice.git
cd SenseVoice
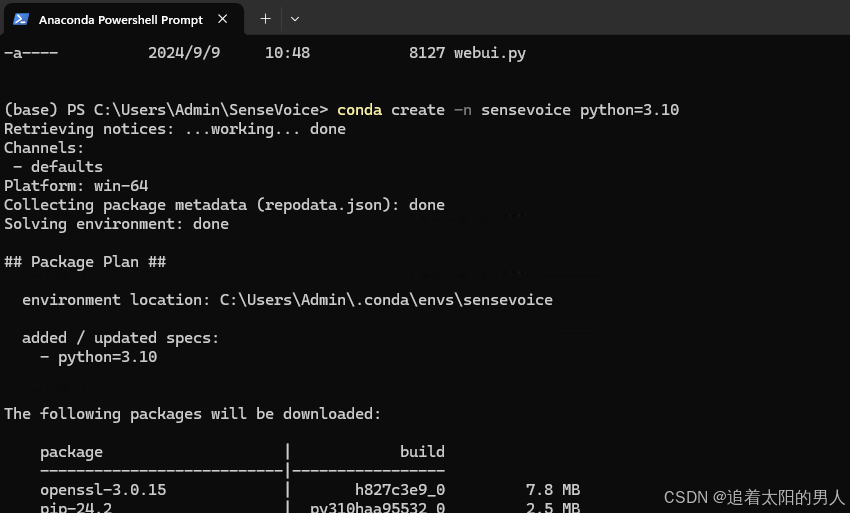
使用conda创建一个虚拟环境
conda create -n sensevoice python=3.10
进入新的虚拟环境并安装项目依赖
conda activate sensevoice
pip install -r requirements.txt
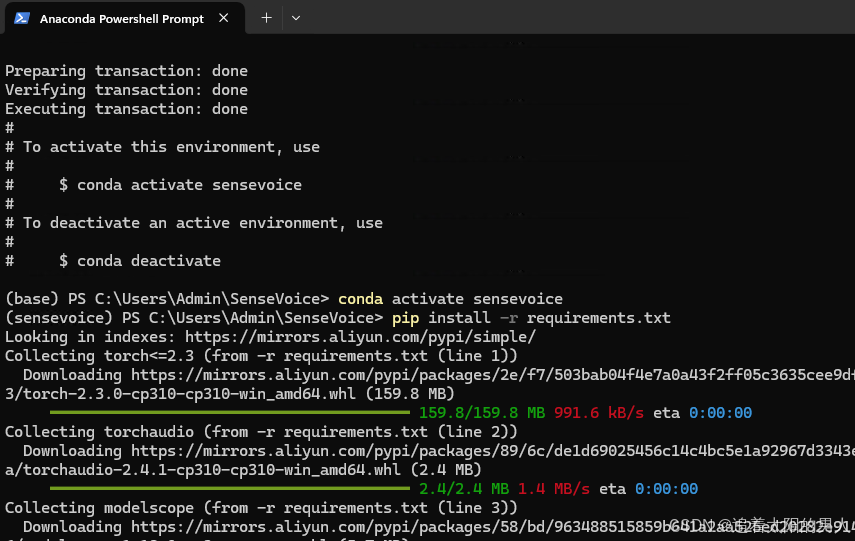
安装好依赖后启动项目
python webui.py
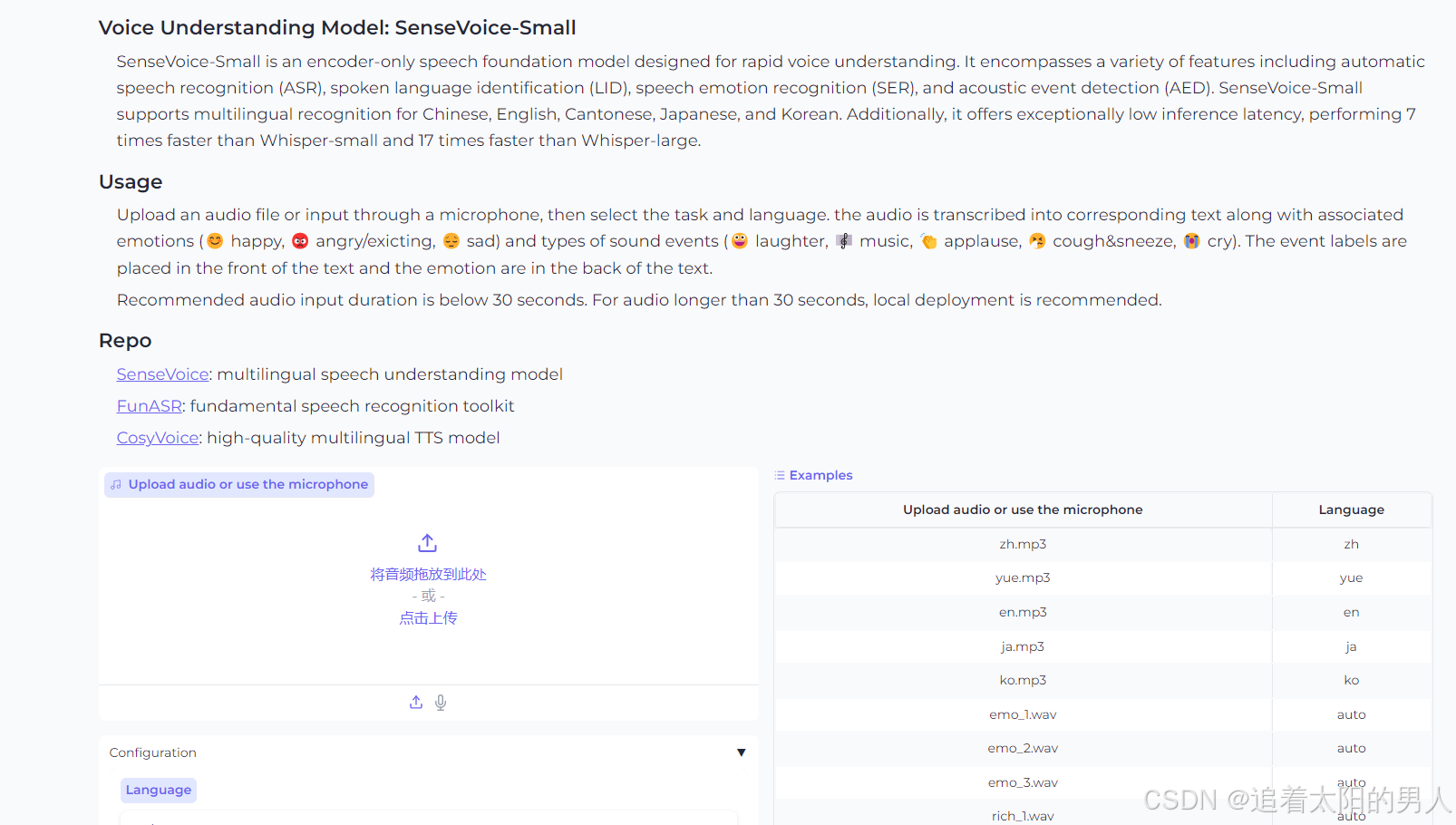
在控制台可以看到输入如下日志即为启动成功。

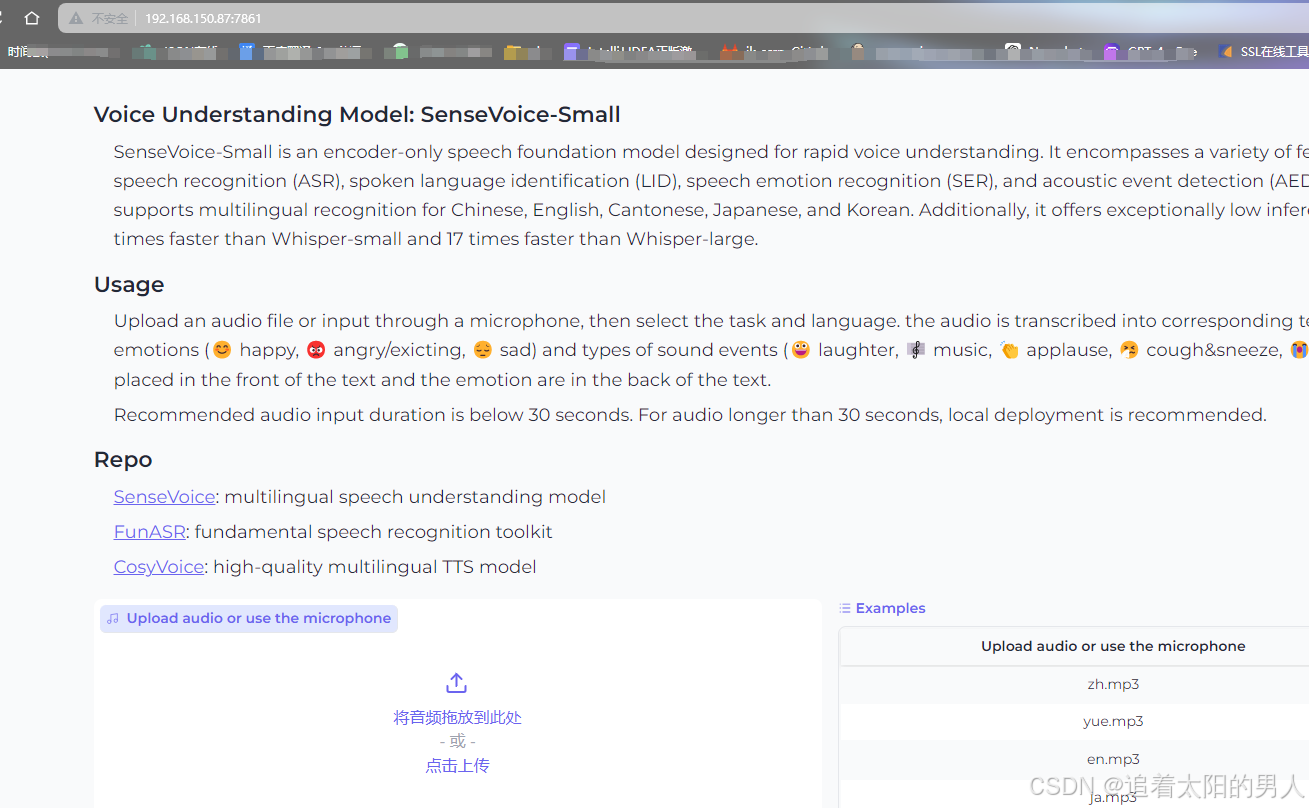
打开日志中的地址即可进入web页面,可以进行上传音频文件,点击下方的start按钮即可开始转义。
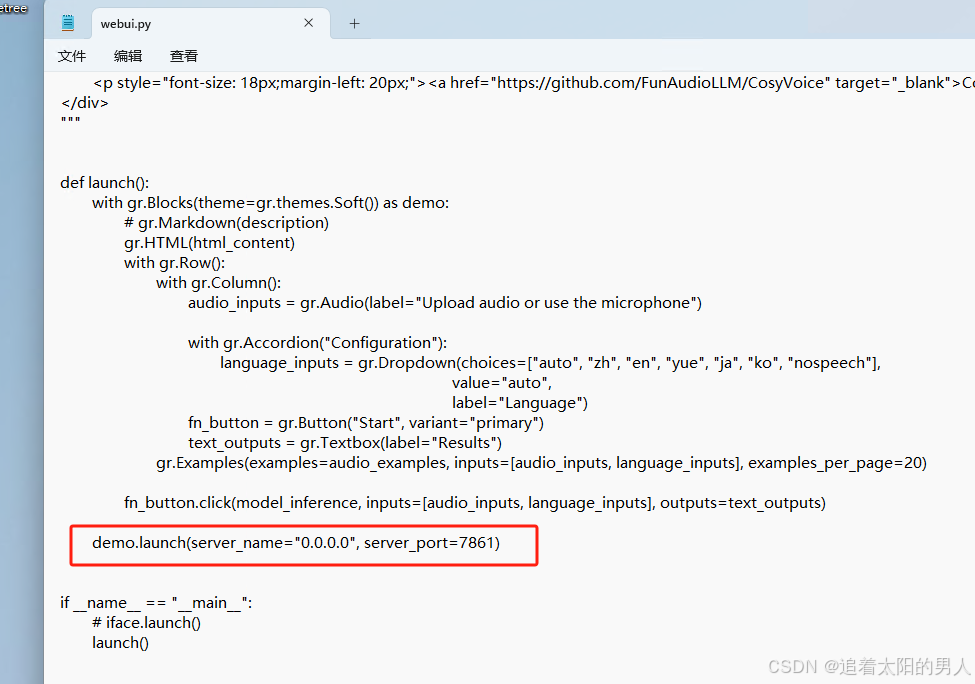
开放访问及端口修改
该项目若不修改ip及端口,则只能在本机测试,若使用0.0.0.0的ip,则可以使用内网ip进行访问。
编辑webui.py文件,增加launch方法传参重启即可。
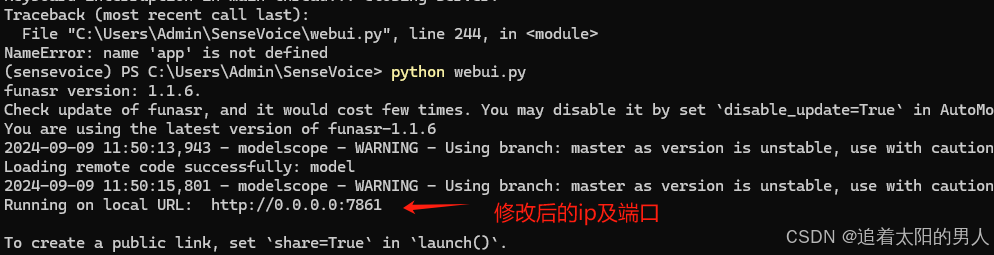
通过内网ip访问成功

















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









