






feature co-action
特征间的联合效应。例如一个点击历史中有泳衣的女性用户很有可能会点击推荐给她的泳镜,因为“泳衣”和“泳镜”之间是有联系的。特征co-action可以对于一系列原始特征子图进行建模。如果子图中只有两个特征,那么特征co-action等价于为两个特征ID的边建模。
以往研究工作对于feature co-action的建模方法可以分为以下三类:基于聚合的方法研究如何将用户的历史行为序列聚合起来用到ctr预估中。
以往工作中研究feature co-action的可以分为三类。基于聚合的方法重点在于学习如何将用户的行为序列聚合起来学习对CTR预估有帮助的表达。这类方法利用feature co-action来为序列中的每个用户行为的权重建模。加权后的用户行为序列进行sum pooling来表达用户兴趣;第二种是基于图的方法,它们将特征视为节点。在这类方法中feature co-action作为边的权重。与上面两种方法不同,组合embedding方法通过显式组合特征embedding来建模feature co-action。
尽管上述方法都对CTR预估课题的发展起到了推动作用,它们也都有各自的不足。聚合类的方法和基于图的方法通过边的权重来建模feature co-action,然而边仅仅用来做信息的聚合而非信息增强。embedding组合的方法将两个特征的embedding拼接在一起来为feature co-action建模。这种方法的一个主要缺点就是embedding既要负责表示学习又要负责建模co-action,这两者有可能存在冲突,从而伤害模型性能。
本文会论述feature co-action的重要性。然后我们会回顾现有的为feature co-action建模的方法,说明它们的效果并不能超过我们的笛卡尔积baseline (? 这就证明了现有的CTR预估模型并不能完全发掘原始feature co-action的潜力。
基于以上观察,我们提出了一个轻量的模型Co-Action Network (CAN),来为原始特征的co-action建模。CAN能够有效学习到feature co-action,提升模型的性能并且减少计算和存储的消耗。
我们在公开数据集和生产环境都进行了实验,均取得了很好的效果。目前CAN已经在阿里巴巴的广告系统部署上线,并且带来了平均12%的CTR增长以及8%的RPM(千次展示收入)提升。
本文还介绍了在生产环境部署CAN的相关技术。
相关工作
tbc
CTR预估中的feature co-action方法回顾
CTR预估中的feature co-action
在广告系统中,用户
u
u
u点击广告
m
m
m的CTR
y
^
\hat{y}
y^是通过以下方式计算的:
y
^
=
D
N
N
(
E
(
u
1
)
,
.
.
.
,
E
(
u
i
)
,
E
(
m
1
)
,
.
.
.
,
E
(
m
j
)
)
\hat{y} = DNN(E(u_1), ..., E(u_i), E(m_1), ..., E(m_j))
y^=DNN(E(u1),...,E(ui),E(m1),...,E(mj))其中
{
u
1
,
.
.
.
,
u
i
}
\{u_1, ..., u_i\}
{u1,...,ui}是用户特征,包括用户的浏览历史,点击历史,用户画像特征等,
{
m
1
,
.
.
.
,
m
i
}
\{m_1, ..., m_i\}
{m1,...,mi}是item特征。
E
(
⋅
)
∈
R
d
E(\cdot) \in R^d
E(⋅)∈Rd表示稀疏ID特征的embedding。除这些一元项,一些工作也将特征的交互输入DNN:
y
^
=
D
N
N
(
E
(
u
1
)
,
.
.
.
,
E
(
u
i
)
,
E
(
m
1
)
,
.
.
.
,
E
(
m
j
)
,
{
F
(
m
i
,
u
j
)
}
i
,
j
)
\hat{y} = DNN(E(u_1), ..., E(u_i), E(m_1), ..., E(m_j), \{F(m_i, u_j)\}_{i, j})
y^=DNN(E(u1),...,E(ui),E(m1),...,E(mj),{F(mi,uj)}i,j) 其中
F
F
F表示用户和item特征的交互。特征交互为模型性能带来了提升,说明不同group的特征的结合提供了额外信息。对这一现象基于直觉的解释是在CTR预估中,某些特征结合后与label有了更强的联系。以用户点击行为为例,用户的点击历史与用户将要点击的item间有很强的联系,因此用户点击历史和target item的组合是CTR预估中一个有效的共现特征。我们把这种与label有很强关联的特征交互叫做feature co-action。
回顾以往的深度学习方法,可以发现有些方法虽然没有将组合特征作为输入,但它们也可以学习到特征间的交互。例如DIN和DIEN利用attention机制来学习用户行为特征和item间的交互。然而这种方法的不足在于它仅限于学习与用户兴趣序列相关的特征交互,并且交互信息是通过低维的embedding来学习的,有可能丢失大量的原始信息。
最直接的学习特征交互的方法是为每个特征组合直接学习一个embedding,例如直接对特征做笛卡尔积。然而这种方法存在参数爆炸问题。并且这种方法在包含同一个特征的多个特征组合中不存在信息共享,这也限制了模型的性能。
还有一些工作试图利用特殊的模型结构来为特征交互建模。然而大部分这些结构都interact with each other without any difference between the representation of feature groups (?
Co-action network
本文提出了co-action network (CAN)来有效抓住特征field间的交互信息。收到将特征组合直接按笛卡尔积编码的启发,CAN引入了一个可插拔的模块,叫做co-action单元。co-action单元的作用是扩大参数空间,并且利用这些参数来建模feature co-action。具体来说,co-action单元有效利用了一边的参数来构建一个MLP,然后将它应用到另一边。这样的特征交叉范式使得模型更加灵活。一方面,增加参数维度意味着增加MLP的参数和层数。另一方面,与相同特征不同组合间没有任何信息共享的笛卡尔积相比,co-action单元对参数的利用更加充分,因为MLP是直接用特征embedding构建起来的。为了在模型中引入高阶信息,我们引入了多阶的增强,以显式地为co-action单元构建多项式输入。多阶信息能够增强模型的非线性,并且能够更好地对feature co-action进行评估。此外,我们提出了embedding独立,组合独立和order独立来通过扩展参数空间确保学习的独立性。
整体结构
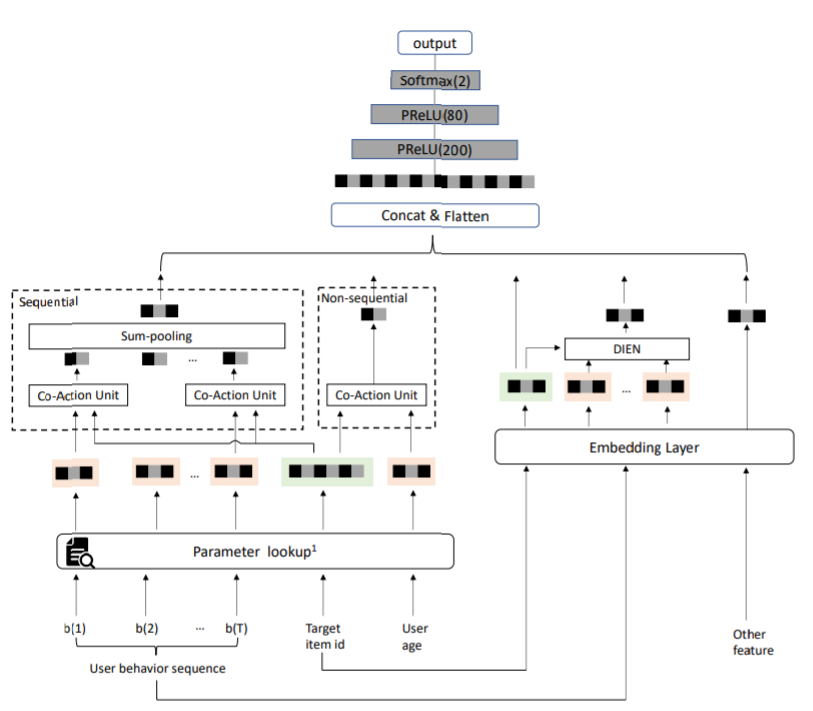
CAN的整体结构如上图所示。用户和target item以两种形式输入CAN。第一种形式:用户和target item的所有特征(
x
u
s
e
r
x_{user}
xuser,
x
i
t
e
m
x_{item}
xitem)都被编码成低维向量,然后分别拼接成
e
i
t
e
m
e_{item}
eitem和
e
u
s
e
r
e_{user}
euser。第二种形式是
x
u
s
e
r
x_{user}
xuser和
x
i
t
e
m
x_{item}
xitem中的部分特征被选出来映射成co-action单元中的参数
P
u
s
e
r
P_{user}
Puser和
P
i
t
e
m
P_{item}
Pitem。co-action单元的运算定义为
H
(
P
u
s
e
r
,
P
i
t
e
m
)
H(P_{user}, P_{item})
H(Puser,Pitem),它其实是一个MLP,这个MLP的参数是从
P
i
t
e
m
P_{item}
Pitem转化而来,输入是由
P
u
s
e
r
P_{user}
Puser转换而来。
CAN的最终结构可以定义为:
y
^
=
D
N
N
(
e
i
t
e
m
,
e
u
s
e
r
,
H
(
x
u
s
e
r
,
x
i
t
e
m
,
Θ
C
A
N
)
,
Θ
D
N
N
)
\hat{y} = DNN(e_{item}, e_{user}, H(x_{user}, x_{item}, \Theta_{CAN}), \Theta_{DNN})
y^=DNN(eitem,euser,H(xuser,xitem,ΘCAN),ΘDNN)然后我们的loss就是
y
^
\hat{y}
y^和label的交叉熵。
Co-action unit
Co-action单元的具体结构如下图所示。
P
i
t
e
m
∈
R
M
×
T
P_{item} \in R^{M \times T}
Pitem∈RM×T被用来做
M
L
P
c
a
n
MLP_{can}
MLPcan每层的weight和bias,
P
u
s
e
r
∈
R
M
×
D
P_{user} \in R^{M \times D}
Puser∈RM×D被喂给
M
L
P
c
a
n
MLP_{can}
MLPcan来输出
H
H
H。其中
M
M
M表示ID的数量,
D
D
D和
T
T
T分别表示向量的维度,其中
D
<
T
D < T
D<T。事实上也可以将user特征作为参数,item特征作为输入,然而在广告系统中,候选item通常是所有item的一个很小的子集,数量远少于用户点击历史。因此我们选择
P
i
t
e
m
P_{item}
Pitem作为参数。
P
u
s
e
r
P_{user}
Puser的维度与
M
L
P
c
a
n
MLP_{can}
MLPcan的输入维度相同,
P
i
t
e
m
P_{item}
Pitem的维度较高。在下面部分我们进行了简化,用
P
i
t
e
m
∈
R
T
P_{item} \in R^T
Pitem∈RT和
P
u
s
e
r
∈
R
D
P_{user} \in R^D
Puser∈RD分别表示某个item特征ID和user特征ID的参数,
P
i
t
e
m
P_{item}
Pitem通过reshape后被切分成所有
M
L
P
c
a
n
MLP_{can}
MLPcan层的权重矩阵和bias向量:
P
i
t
e
m
=
c
o
n
c
a
t
e
n
a
t
e
(
{
f
l
a
t
t
e
n
(
w
(
i
)
)
,
b
i
}
i
=
0
,
.
.
.
,
K
−
1
)
P_{item} = concatenate(\{flatten(w^{(i)}), b^i\}_{i=0, ..., K-1})
Pitem=concatenate({flatten(w(i)),bi}i=0,...,K−1)
∣
P
i
t
e
m
∣
=
∑
i
=
1
K
∣
w
(
i
)
∣
+
∣
b
(
i
)
∣
|P_{item}| = \sum^K_{i=1} |w^{(i)}| + |b^{(i)}|
∣Pitem∣=i=1∑K∣w(i)∣+∣b(i)∣其中
w
(
i
)
w^{(i)}
w(i)和
b
(
i
)
b^{(i)}
b(i)表示
M
L
P
c
a
n
MLP_{can}
MLPcan的第
i
i
i层的weight和bias,
∣
⋅
∣
|\cdot|
∣⋅∣表示矩阵或向量的维度。
接下来,feature co-action的计算为:
h
(
0
)
=
P
u
s
e
r
h^{(0)} = P_{user}
h(0)=Puser
h
(
i
)
=
σ
(
w
(
i
−
1
)
)
⊗
h
(
i
−
1
)
+
b
(
i
−
1
)
h^{(i)} = \sigma(w^{(i-1)}) \otimes h^{(i-1)} + b^{(i-1)}
h(i)=σ(w(i−1))⊗h(i−1)+b(i−1)
H
(
P
u
s
e
r
,
P
i
t
e
m
)
=
h
(
K
)
,
i
∈
1
,
2
,
.
.
.
,
K
−
1
H(P_{user}, P_{item}) = h^{(K)}, i \in 1, 2, ..., K-1
H(Puser,Pitem)=h(K),i∈1,2,...,K−1其中
⊗
\otimes
⊗和
σ
\sigma
σ分别表示矩阵乘法和激活函数。对于点击历史一类的序列化特征,co-action单元分别应用到每一个item,然后再将整个序列的co-action结构进行sum-pooling。
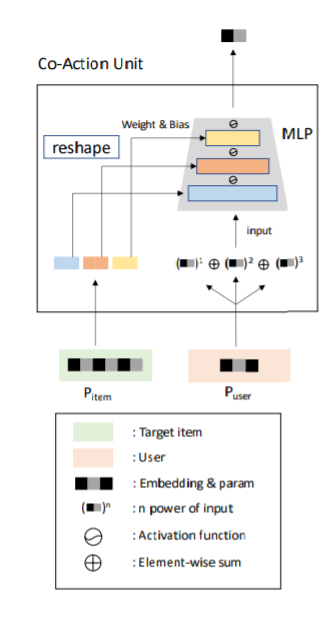
我们提出的这个co-action单元至少有3个优点:第一,与以往方法在不同形式的跨field交互中用相同隐藏向量不同,co-action单元充分利用了DNN的计算能力,并且利用动态的参数和输出来对两个特征进行耦合,这使得两个field的特征的更新能力更强,并且能够避免梯度耦合。第二,我们的方法减少了参数数量。如果我们用embedding的笛卡尔积来表示feature co-action,那么参数量级是
O
(
N
2
×
D
)
O(N^2 \times D)
O(N2×D),而通过co-action单元,参数量级就变成了
O
(
N
×
T
)
O(N \times T)
O(N×T),参数量减少不仅能提升训练阶段的效果,而且也能减轻线上系统的负担。第三,co-action单元对新特征组合的泛化能力更强。给出一对新的特征组合,co-action单元依旧能够正常工作。
CAN多阶增强
前面提到的feature co-action是由一阶的特征学到的,然而特征间的交互也有可能是高阶交互。此时我们可以通过将co-action单元输入改成多项式来引入高阶信息:
H
(
P
u
s
e
r
,
P
i
t
e
m
)
=
∑
c
=
1
C
M
L
P
c
a
n
(
(
P
u
s
e
r
c
)
)
≈
M
L
P
c
a
n
(
∑
c
=
1
C
(
P
u
s
e
r
)
c
)
H(P_{user}, P_{item}) = \sum^C_{c=1}MLP_{can}((P_{user}^c)) \approx MLP_{can}(\sum^C_{c=1}(P_{user})^c)
H(Puser,Pitem)=c=1∑CMLPcan((Puserc))≈MLPcan(c=1∑C(Puser)c)其中
C
C
C代表阶数。值得注意的是,当
C
=
1
C=1
C=1时我们利用SeLU作为激活函数,而对于高阶项我们利用Tanh作为激活函数。
多级独立
tbc















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









