







一、下载安装Anaconda
1.请到Free Download | Anaconda下载Anaconda的最新版本。
参考官方文档:Installing on Linux — Anaconda documentation
详细教程可参考如何安装Python运行环境Anaconda?_腾讯视频
二、安装中的一些问题
1.在安装时,会选择anaconda路径,主要不要含有空格。
2.建议仅为 Just Me 安装,这会将 Anaconda Distribution 安装到当前用户帐户。仅当需要为计算机上的所有用户帐户安装(这需要 Windows 管理员权限)时,才为“所有用户”选择安装。
3.在“Advanced Installation Options”中不要勾选“Add Anaconda to my PATH environment variable.”(“添加Anaconda至我的环境变量。”)。因为如果勾选,则将会影响其他程序的使用。如果使用Anaconda,则通过打开Anaconda Navigator或者在开始菜单中的“Anaconda Prompt”(类似macOS中的“终端”)中进行使用。
4. 除非你打算使用多个版本的Anaconda或者多个版本的Python,否则便勾选“Register Anaconda as my default Python 3.7”。
三、根据需求安装一些环境依赖包
1.提供一个比较简单的方法:下载链接下的压缩包,
thttps://github.com/wshuyi/demo-python-scrape-webpage-with-requests-html/archive/master.zip![]() https://github.com/wshuyi/demo-python-scrape-webpage-with-requests-html/archive/master.zip里面有两个Pipfile开头的文件,它们就是 pipenv 的设置文档。
https://github.com/wshuyi/demo-python-scrape-webpage-with-requests-html/archive/master.zip里面有两个Pipfile开头的文件,它们就是 pipenv 的设置文档。
然后打开终端,用cd命令进入该演示目录
然后用终端下载pipenv
pip install pipenv这里安装的,是一个优秀的 Python 软件包管理工具 pipenv 。安装后,请执行:
pipenv installpipenv 工具会依照pipenv 的设置文档,自动为我们安装所需要的全部依赖软件包。
2.遇到一些特殊需求时用到的软件包
在线安装:
(1)打开Anaconda Prompt,就是Anaconda的命令行
conda install pkgname #其中pkgname为包名(2)当找不到包的时候,执行如下命令:
conda install -c conda-forge pkgname #其中pkgname为包名本地安装:
(1)从github(或者其他来源)中下载zip,解压后里面有一个setup.py的文件,在命令行中进入解压路径,输入
python setup.py install然后会出现dist文件夹,其中会生成一个.tar.gz类型文件。
(2)下载.tar.gz类型文件
conda install --use-local pkg其中pkg为绝对路径。
三、使用Anaconda完成第一个机器学习案例
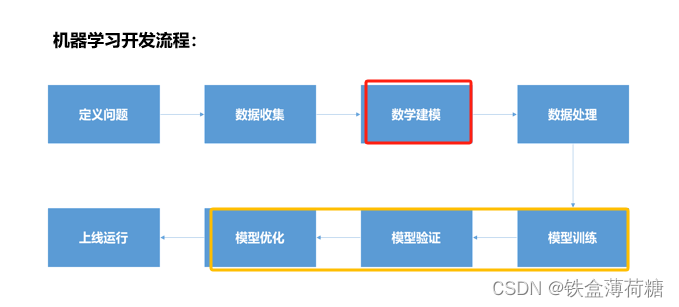
经典案例:波士顿房价模型
1、定义问题:波士顿房价预估项目的需求
项目需求:波士顿房地产市场竞争激烈,而你想成为该地区最好的房地产经纪人。为了更好地与同行竞争,你决定运用机器学习的一些基本概念,帮助客户为自己的房产定下最佳售价。你的任务是用可用的工具进行统计分析,并基于分析建立优化模型。这个模型将用来为你的客户评估房产的最佳售价。
通过项目需求,我们可以抽象出以下项目需求:
需要找到影响波士顿房价的各个因素
2、数据收集:得到波士顿房价历史数据
我们使用scikit learn提供的博士房价数据集,该数据集收集了波士顿房屋这些数据于1978年开始统计,共506个数据点,涵盖了麻省波士顿不同郊区房屋14种特征的信息。
| 数据集名称 | 数据类型 | 特征数 | 实例数 | 值缺失 | 相关任务 |
| 波士顿房价数据集 | 数值型或类别型 | 13 | 506 | 无 | 描述性分析、预测性分析 |
数据集属性描述:
| No | 属性 | 数据类型 | 字段描述 |
| 1 | CRIM | Float | 城镇人均犯罪率 |
| 2 | ZN | Float | 占地面积超过2.5万平方英尺的住宅用地比例 |
| 3 | INDUS | Float | 城镇非零售业务地区的比例 |
| 4 | CHAS | Integer | 查尔斯河虚拟变量 (= 1 如果土地在河边;否则是0) |
| 5 | NOX | Float | 一氧化氮浓度(每1000万份) |
| 6 | RM | Float | 平均每居民房数 |
| 7 | AGE | Float | 在1940年之前建成的所有者占用单位的比例 |
| 8 | DIS | Float | 与五个波士顿就业中心的加权距离 |
| 9 | RAD | Integer | 辐射状公路的可达性指数 |
| 10 | TAX | Float | 每10,000美元的全额物业税率 |
| 11 | PTRATIO | Float | 城镇师生比例 |
| 12 | B | Float | 1000(Bk - 0.63)^ 2其中Bk是城镇黑人的比例 |
| 13 | LSTAT | Float | 人口中地位较低人群的百分数 |
| 14 | MEDV | Float | (目标变量/类别属性)以1000美元计算的自有住房的中位数 |
3、数学建模:建立波士顿房价数学模型
依据scikit learn提供的数据集,我们建立14个输入维度1个输出维度的数学模型。
注:在初次建立模型时,通常将能考虑到的维度都用于构建模型,当使用初次模型进行训练后,根据特征权重可以对模型进行优化,重新构造模型。相关代码如下:
import pandas as pd
import numpy as np
from sklearn.metrics import r2_score
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor, RidgeCV, LogisticRegression
lb = load_boston()
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.2) 4、数据处理:
在引入数据后,我们要将引入的数据进行数据处理,包括使数据结构处理、数据标准化处理等,相关代码如下:
# 说明一下:fit_transform与transform都要求操作2D数据,而此时的y_train与y_test都是1D的,因此需要调用reshape(-1,1),例如:[1,2,3]变成[[1],[2],[3]]
y_train = y_train.reshape(-1, 1)
y_test = y_test.reshape(-1, 1)
# 进行标准化
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
5、模型训练、验证、优化
将训练集和测试集的数据处理完毕后,我们使用scikit learn提供的算法进行训练及验证,相关代码如下:
# 正规方程预测
lr = LinearRegression()
lr.fit(x_train, y_train)
print("r2 score of Linear regression is",r2_score(y_test,lr.predict(x_test)))
#岭回归
cv = RidgeCV(alphas=np.logspace(-3, 2, 100))
cv.fit (x_train , y_train)
print("r2 score of Linear regression is",r2_score(y_test,cv.predict(x_test)))
#梯度下降
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
print("r2 score of Linear regression is",r2_score(y_test,sgd.predict(x_test)))
拓展:最后代码运行过程中出现了警告
使用sklearn训练模型出现【DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().】
数据转换警告:当需要一维数组时,传递了列向量y。请将Y的形状更改为(n_samples,),例如使用ravel()。
1.解决思路
该问题是警告,不处理亦可运行程序,只需理解一下即可!建议以后使用此类方法,要规范使用!
fit()第二个参数(也就是label)必须是(n.)格式的,而传入的是(n,1)格式的,所以需要将他转换。
2.解决方法
修改为这样
#clf.fit(X.T,Y.T);
clf.fit(X.T,Y.T.ravel());四、Anaconda Prompt常用语句
1.查看存在的环境:conda info -e
2.创建新环境:conda create -n 环境名 python=python的版本号
3.切换到某个环境:conda activate 环境名
执行以下命令:
4.查看环境中已安装的包:conda list
5.在环境中安装包:pip install 包名
6.删除包:pip unstall 包名
7.删除环境:conda env remove -n 环境名
















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









