







数据结构是一张抽象数据类型,由数据存储方式和操作决定数据结构。与线性表类似,我们可以有两种存储方式,但由于对操作的限定:先进后出,使得操作实现的效果不同于一般线性表。
其实栈是对线性表的一种约束,更细化数据结构(封装操作更精确,更利用用户的使用),比如想实现先进后出,若利用线性表也是可以的,但用户得次次指定元素的位置,用户得知道当前数据结构中元素的个数。对于用户来说,这样的数据结构不方便。栈和队列就是针对常用的场景而设计出的数据结构,面对具体的场景,选择这些数据结构会更加方便。
栈是仅允许在表尾进行删除插入操作的线性表

栈只是对线性表插入删除的位置进行了限制,但多个元素进栈出栈时机没有限制,几个元素就有可能有多个出栈可能性。
ADT(仅是对表尾进行操作,与线性表的抽象数据类型相比较,其余元素位置就不需要关注了)

顺序栈的实现
使用数组存储数据元素,选择数组的末尾元素作为栈顶,首个元素作为栈底。栈顶使用栈顶元素在数组中的位置来表示,与线性表相比,顺序栈结构中仍旧保留了数组,但将线性表的长度换为栈顶变量。

const int MAXSIZE = 20;
template<typename T>
class ArrayStack {
int top;
T data[MAXSIZE];
public:
ArrayStack() {
top = -1;
}
bool push(const T & item)
{
if (top < MAXSIZE - 1)
{
data[++top] = item;
return true;
}
else
return false;
}
bool pop(T & ele) {
if (top == -1)
return false;
else {
ele = data[top--];
return true;
}
}
bool get_top(T & ele ) {
if (top == -1)
return false;
else {
ele = data[top];
return true;
}
}
bool isempty() {
return (top == -1) ? 1 : 0;
}
bool isfull() {
return (top == MAXSIZE - 1) ? 1 : 0;
}
int get_length() {
return top + 1;
}
void clear() {
top = -1;
}
};
#include "stdafx.h"
#include"ArrayStack.h"
#include<iostream>
using namespace std;
int main()
{
ArrayStack<int >a;
cout << "input element numbers ,which is less than 20:" << endl;
int n;
cin >> n;
for(int i=0;i<n;i++)
{
a.push(i);
}
int x;
if (a.get_top(x))
cout << x << endl;
for (int i = 0; i < n / 2; i++)
a.pop(x);
cout << x << endl;
cout << a.get_length() << endl;
if (a.get_top(x))
cout << x << endl;
cin.get();
cin.get();
return 0;
}
顺序栈另一种存储方式:两栈共享空间方式(弱化顺序栈遭受数组大小的限制)
顺序栈由于只在栈尾对数据元素进行操作,不涉及数据元素挪动。但是还有一个问题,数组大小是固定的。针对这个问题,提出两栈共享一个数组想法。这就要求栈中的数据元素属于同一种。可以充分使用数组大小,而不会出现两个栈两个数组,一个栈满了,另一个栈空着却不能用的尴尬。
设计思路:数组大小是一定的,可以使得两个栈从固定的端点向中间聚集,所以相对于数组来说,一个栈的栈顶指针值为n(空栈);另一个栈顶指针值为-1(空栈),这样就不会浪费数组空间。
假设数组大小为n,栈满的条件:top1+1==top2
设计数据结构时,要区分两个栈的栈顶,虽然存在一个数组中但是是两个栈,因此插入删除元素时需要区分操作对象。更适合两个栈一个呈增长趋势一个呈消退趋势。
const int MAXSIZE = 100;
template <typename T>
class ArrayStack {
T data[MAXSIZE];
int top1;
int top2;
public:
ArrayStack() {
top1 = -1;
top2 = MAXSIZE;
}
bool push(const T & ele,int top) {
if (top1 + 1 == top2)
return false;
if (top == 1) {
data[++top1] = ele;
}
if (top == 2) {
data[--top2] = ele;
}
return true;
}
bool pop(T & ele, int top) {
if (top == 1) {
if (top1 == -1) {
return false;
}
else {
ele = data[top1--];
return true;
}
}
else if (top == 2) {
if (top2 == MAXSIZE)
{
return false;
}
else {
ele = data[top2++];
return true;
}
}
else
return false;
}
bool get_top(T & ele,int top) {
if (top == 1) {
if (top1 == -1)
return false;
else {
ele = data[top1];
return true;
}
}
else if (top == 2)
{
if (top2 == MAXSIZE)
return false;
else {
ele = data[top2];
return true;
}
}
else
return false;
}
int stack1_len() {
return top1 + 1;
}
int stack2_len() {
return MAXSIZE - top2;
}
};
#include "stdafx.h"
#include"ArrayStack2.h"
#include<iostream>
using namespace std;
int main()
{
ArrayStack <int>a;
cout << "input stack1 and stack2 numbers:";
int n,m;
cin >> n>>m;
for (int i = 0; i < n; i++) {
a.push(i, 1);
}
for (int i = 0; i < m; i++) {
a.push(i, 2);
}
int x;
if (a.get_top(x, 1))
cout << x << endl;
if (a.get_top(x, 2))
cout << x << endl;
cout << a.stack1_len() << endl;
cout << a.stack2_len() << endl;
for (int i = 0; i < n; i++)
if (a.pop(x, 1))
cout << x << " ";
cout << endl;
for(int i=0;i<m;i++)
if (a.pop(x, 2))
cout << x << " ";
cout << endl;
cin.get();
cin.get();
return 0;
}
链栈:
单链表,有一个头指针,而对于栈来说,需要一个栈顶指针,不如就把栈顶指针和头指针合并到一起!通过头指针可以找到线性表的所有元素,只要我们想就可以在创建链栈的时候,利用栈顶指针找到线性表所有的元素,且栈顶指针满足先进后出。第二个不同点在于,栈顶指针含义是指向栈尾元素,头指针通常指向头结点,在使用栈顶指针代替头指针时,舍弃头结点。第三个不同点,单链表所有的操作都是要求指定元素位置,但是栈的特殊定义使得不需要指明位置,通通在栈顶指针处。
//链栈的实现没有必要尝试双向和循环 这是由栈的定义所限制的 先进后出 仅由表尾控制
template <typename T>
struct Node {
T data;
Node<T> *next;
};
template<typename T>
class StackList {
Node<T> * top;
int length;
public:
StackList() {
top = nullptr;
length = 0;
}
StackList(int n) {
length = n;
top = nullptr;
for (int i = 0; i < n; i++) {
Node<T> *q = new Node<T>;
q->data = i;
q->next = top;
top = q;
}
}
void clear() {
while (top) {
Node <T> *p = top->next;
top = p;
delete p;
}
length = 0;
}
bool get_top(T &ele) {
if (top) {
ele = top->data;
return true;
}
else
return false;
}
void push(const T & ele) {
Node<T > *p = new Node<T>;
p->data = ele;
p->next = top;
top = p;
length++;
}
bool pop(T &ele) {
if (top) {
Node<T > *p = top->next;
ele = top->data;
top = p;
length--;
delete p;
return true;
}
else
return false;
}
int get_len()
{
return length;
}
};
#include "stdafx.h"
#include"StackList.h"
#include<iostream>
using namespace std;
int main()
{
StackList<int > a(6);
a.push(1);
int x;
if (a.get_top(x))
cout << x << endl;
cout << a.get_len() << endl;
if (a.pop(x))
cout << x << endl;
cin.get();
return 0;
}
栈的一个典型应用:函数调用时利用栈存储变量及返回地址
栈的第二个应用:
算术四则运算,主要矛盾:不是完全按照从左至右的次序优先级递减,而是先乘除后加减、括号优先级最高,出现多个成对括号,左侧优先级高于右侧。两个问题:加减乘除运算和括号运算。
关于一个四则运算的表达式,有数值有符号;而我们知道数据结构是同种数据元素的集合。
为解决四则运算问题需要两个栈,一个栈存的是符号,一个栈存的是数值!存储运算符的栈,帮助我们确定了各部分运算次序;存储数值的栈帮助我们存储计算的中间结果,能够帮助我们确定正确找到进行计算时正确的操作数!
之前说过栈出入的位置是一定的但时机没有任何要求!结合具体的问题,我们设定规则确定入栈出栈的时机!四则运算中,结合运算符的优先级确定出了入栈出栈的时机以达到正确的结果。
数据元素加上出入栈的时机能帮助我们进行一些达到希望的效果:正确的后缀表达式,计算中间值!
栈这种数据结构在存储数据外,限制了元素的先进后出(入栈出栈,入栈出栈总是在栈尾进行,但是入栈出栈的时机和入栈出栈的元素个数是根据题目条件来决定,能够达到多种数据次序的排列组合),利用这种操作来获得正确的数据元素(过滤+次序),而入栈出栈时机则是根据题目背景确定。
后缀表达式:运算符在操作数之后,所有的计算按运算符出现的顺序,严格从左向右进行(不再考虑运算符的优先规则)。不断将中间计算结果入栈 ,运算符只和前两个数据元素相关,栈中存储了很多数值,但每次进行运算时只要最后进栈的两个元素,何时出栈由四则运算表达式中是数值还是符合来决定。
计算后缀表达式的结果为什么需要栈?
3 3 2 4 * + 5 / 5 * +
计算机处理后缀表达式的算法:遍历整个表达式,遇见数据元素入栈,遇见运算符则弹出两个元素计算结果后再放入栈中,直到栈为空,为什么使用栈呢?因为涉及到将计算结果再次入栈,符合先进后出,只在一端对元素进行操作。
中缀表达式转为后缀表达式+计算机计算后置表示式算法,这两个过程要一同思考!
3+((3+2*4)/5)5
有没有一种方法帮助我们来确定各部分运算次序?先算括号内的,括号内的再按乘除高于加减次序确定,因此我的计算次序为:24=8;
3+8=11;
11/5=11/5;
11/5*5=11
3+11=14
3 3 2 4 * + 5 / 5 * +
转后缀表达式的过程需要同时思考括号和乘除运算规则确定出表示式各部分的计算次序
队列
队列是在允许在一端进行插入,另一端进行删除的线性表。

类似的,队列至少有两种存储方式:顺序和链式。
注意在上面的逻辑结构中,数据成员是不确定的,这个是根据选择的存储结构和数据结构特点来确定的。
顺序存储的队列也称为循环队列:
为何设置队头队尾指针?
对比顺序栈,由于仅在栈尾插入删除,需要一个标记表明数组末尾元素的位置,这个位置是变化的,因此需要设置一个变量来存储这个变化的末尾位置。队列,队尾位置也需要一个变量来存储,队头呢?如果我们采用默认位置为0的下标存储队头元素,那么删除元素,队列元素总是得挪动,时间复杂度高。若采用类似队尾指针的方式,采用一个变量存储当前队头元素位置,那么在出队时我们无需挪动所有的元素了。

为何采用循环结构?
如果不采用循环结构,数组前面有空余,但队尾指针却无法指向这些位置,因此采用循环结构。
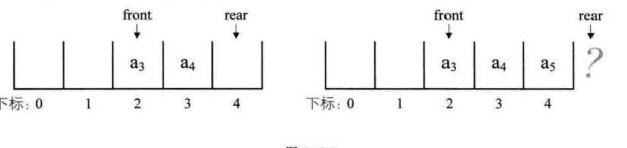
为何在还有一个空余空间时队列表示为满?
为了区分队空和队满的判断条件,队空时:队头指针等于队尾指针,队满时:(队尾指针+1)%空间大小==队头
循环队列长度:
区分rear和front相对大小,可分为两种情况:
front<rear:rear-front
front>rear:maxsize-front+rear
综合考虑:(maxsize-front+rear)%maxsize
const int MAXSIZE = 20;
template<class T>
class queue {
T data[MAXSIZE];
int rear;
int front;
public:
queue() {
rear = front = 0;
}
bool enqueue(const T &ele) {
if ((rear + 1) % MAXSIZE == front)
return false;
data[rear] = ele;
rear = (rear + 1) % MAXSIZE;
return true;
}
bool dequeue(T & ele) {
if (rear == front)
return false;
ele = data[front];
front = (front + 1) % MAXSIZE;
return true;
}
bool get_head(T &ele) {
if (front == rear)
return false;
ele = data[front];
return true;
}
int get_len() {
return (rear + MAXSIZE - front) % MAXSIZE;
}
};
#include "stdafx.h"
#include"queue1.h"
#include<iostream>
using namespace std;
int main()
{
queue<int> a;
a.enqueue(1);
a.enqueue(3);
int x;
if (a.get_head(x))
cout << x << endl;
if (a.dequeue(x))
cout << x << endl;
cout << a.get_len() << endl;
if (a.get_head(x))
cout << x << endl;
cin.get();
return 0;
}
链队列:
想想链队列所需的数据成员,由于存储空间是动态分配的,因此不需要提前分配存储空间,但是为了进行插入删除操作(因操作需要而添加的数据成员),需要队头指针和队尾指针。
链队列通常会包含一个头结点,为了统一插入删除操作,如果不加头结点,对于插入操作,需要多一个判断条件,判断front指针是否空,为空则需要修改front指针;对于删除操作,需要判断队列是否为空,为空修改rear指针;而对于一般的删除操作我们是不需要修改rear指针,插入操作是不需要修改front指针,没有头结点我们就需要考虑边界条件。而有了头结点,插入操作,不再需要插入第一个元素时是否需要修改front指针,因为front指针将始终指向头结点,我们只需要关心尾指针,但是删除时还是得考虑何时修改尾指针。(对于线性链表,无论是在头部中间尾部位置的插入删除操作都是一样的,找到要插入位置的前一个元素,操作统一代码简洁,如果不用头结点,同样地做法找到要插入位置的前一个元素,但是,需要考虑特殊的几种情况!第一次插入,最后一个元素的删除)
有了头结点,队头指针始终指向头结点。
template <typename T>
struct Node {
T data;
Node<T> *next;
};
template <class T>
class ListQueue {
Node<T> *front;
Node<T> *rear;
public:
ListQueue() {
front = new Node<T>;
front->next = nullptr;
rear = front;
}
~ListQueue() {
delete front;
}
void enqueue(const T & ele) {
Node<T> *temp = new Node<T>;
temp->next = nullptr;
temp->data = ele;
rear->next = temp;
rear = temp;
}
bool dequeue(T &ele) {
if (front == rear)
return false;
Node<T> *t=front->next;
ele=t->data;
front->next = t->next;
if (front->next==nullptr)//删除的元素是末尾元素
rear = front;
delete t;
return true;
}
bool get_head(T &ele) {
if (front == rear)
return false;
ele = front ->next->data;
return true;
}
int get_len() {
Node<T> *p = front->next;
int j = 0;
while (p)
{
j++;
p = p->next;
}
return j;
}
};
#include "stdafx.h"
#include"listqueue.h"
#include<iostream>
using namespace std;
int main()
{
ListQueue<int> q;
for(int i=0;i<10;i++)
q.enqueue(i);
cout << q.get_len() << endl;
int x;
if (q.get_head(x))
cout << x << endl;
for (int i = 0; i < 5; i++)
{
q.dequeue(x);
cout << x << endl;
}
if (q.get_head(x))
cout << x << endl;
cin.get();
return 0;
}
总结栈和队列在顺序存储上提高性能的一些思想:
两个同种类型的栈共享数组空间,循环队列(不浪费空间同时改进删除操作挪动元素的时间复杂度)














 3368
3368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









