









这里所关注的问题:根据图像是否包含某个特定物体来分类图像、分类场景、分类材质
分类:提取图像(描述)特征、训练分类器(机器学习方法)、验证分类器
一、一起聊聊图像的特征提取吧!(更关注的是全局信息,而不是局部,比如布局等,所以经典的SIFT失效啦,但在构建视觉词典的时候还是能用到SIFT的)
方法一:GIST特征
32个gabor filter(8个orientation ,4 个scale),将卷积结果分为16个region,每个region求一个平均值,最终形成一个32*16=512维的特征向量,能表示梯度信息。
GIST特征常用来表示场景
方法二:visual word
图像特征由多个patch来描述,生成图像关于不同patch个数的直方图作为图像特征描述子
创建词典:由多个patch的sift描述子构成(每个patch有一个描述子),通过k-means方法,获得类型相似的patch描述子
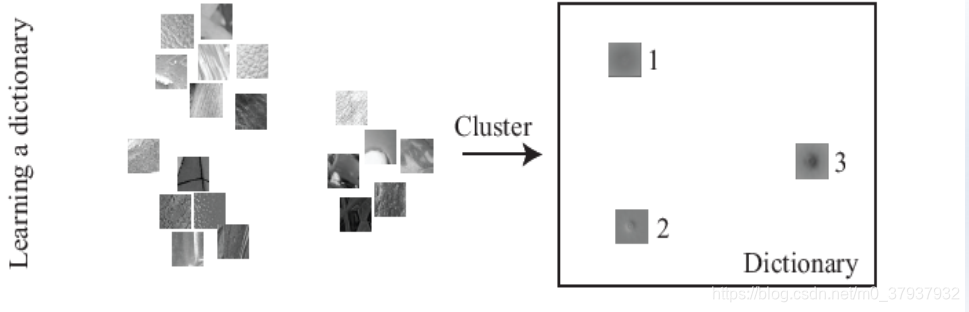
生成图像的直方图:给定一个图像,提取所有特征点,特征点与其周围的像素点形成patch,特征点的sift描述子可作为patch的描述,依次与词典中patch做距离运算进行聚类,记录最近的类,为其个数加1。最终可以得到图像关于词典中特征出现个数的向量描述。
存在的问题:全局的统计信息,无法区分位置信息
Spatial pyramids 空间金字塔(构建多尺度金字塔 ,对visual word的改进)
多尺度体现在把图像分为不同个数的块(1、4、16块,在每个块上计算基于visual word的特征表示)
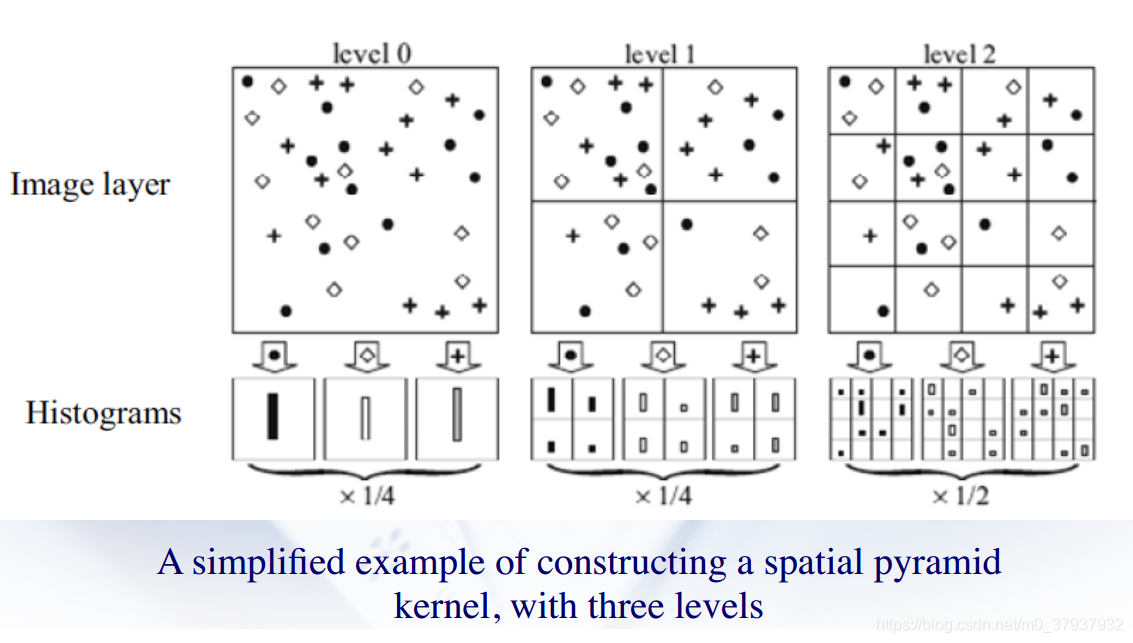
通常获取的特征向量维数太大,需要降维处理,因而引出数据降维
二、得到的特征向量太大了运算不好,于是乎人们提出了降维!
PCA:
选取使得样本间的方差最大的投影子空间
选取k个主要的投影子空间,得到k维的数据。
存在问题:仅仅是重建数据,对分类无益,引出了LDA,我们是对特征数据降维处理,自然是希望降维后的数据能保持区分性
LDA:
投影子空间使得类间差别最大,类内差别最小
终于获得了图像完美的数据特征(运算量可接受),下一步就可以训练分类器啦,然后分类图像。














 2843
2843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









