







目录
第一题
1.读取lianjia.csv文件里的数据
2.观察结构,调整列索引顺序(Region",“Garden”,“Layout”,“Floor”,“Year”,“Size”,“Elevator”,“Direction”,“Renovation”,“Price”)
3.增加一个列关于目前状况(state),是否卖出状态随机设定
4.查找楼层低的房子(这里提取低楼层)
5.电梯这列存在缺失值,想办法处理下缺失值
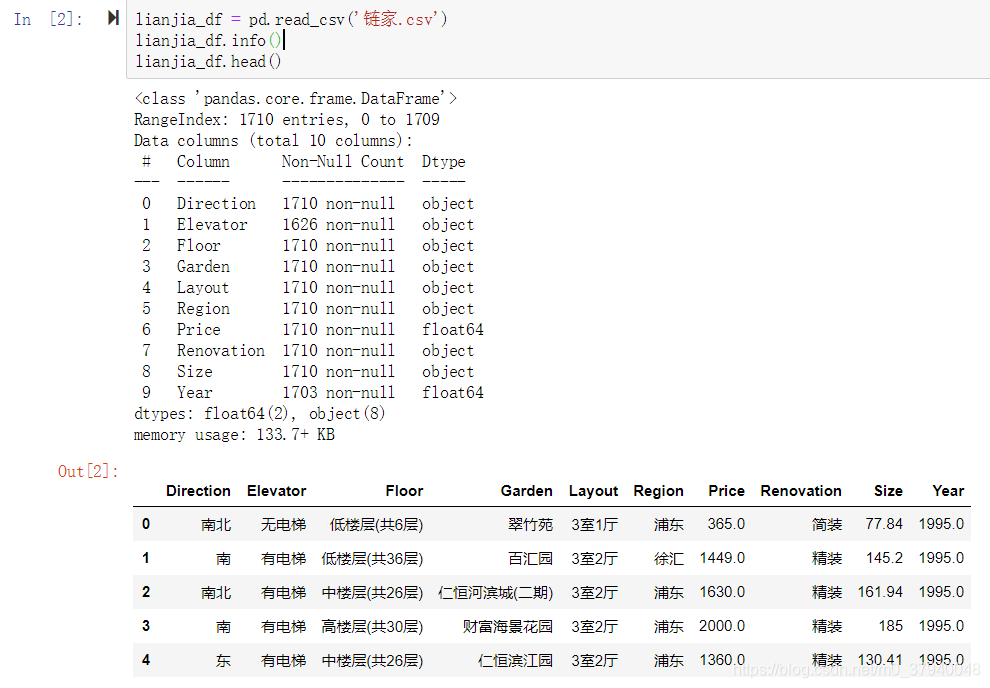
1.读取lianjia.csv文件里的数据
- 代码
import numpy as np
import pandas as pd
lianjia_df = pd.read_csv('链家.csv')
print(lianjia_df.info())
print(lianjia_df.head())
- 运行结果
2.观察结构,调整列索引顺序
- 代码
lianjia_df = lianjia_df.reindex(columns=["Region","Garden","Layout","Floor","Year","Size","Elevator","Direction","Renovation","Price"])
print(lianjia_df)
- 运行结果

3.增加一个列关于目前状况(state),是否卖出状态随机设定
- 代码
lianjia_df['state'] = np.random.choice(['on sell','sold out'],size=(1710))
print(lianjia_df)
- 运行结果

4.查找楼层低的房子(这里提取低楼层)
- 代码
# 方法1
print(lianjia_df[lianjia_df['Floor'].str.contains('低楼层')])
# 方法2
lianjia_df['Floor_height'] = lianjia_df['Floor'].replace('\(.*?\)','',regex=True)
print(lianjia_df[lianjia_df['Floor_height'] == '低楼层'])
- 运行结果


5.电梯这列存在缺失值,想办法处理下缺失值
- 代码
lianjia_df.dropna(inplace=True)
print(lianjia_df.info())
print(lianjia_df)
- 运行结果
















 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









