







目录
写在前面:
我们一般看K线图时通过视觉判断波段具有很强的主观性,所以通过代码找到的波段并不能满足所有人的需求。大家有自己特定波段述求的,可以自行修改代码。
寻找波段分两大步骤,本篇文章是第一步骤——寻找所有的转折点,即所有的峰值和谷值,也可以理解为所有的高点和低点。
需要考虑的几种K线图情况:
1 巨大宽幅波动
2 窄幅波动
3 极窄幅横盘
4 缓慢下跌
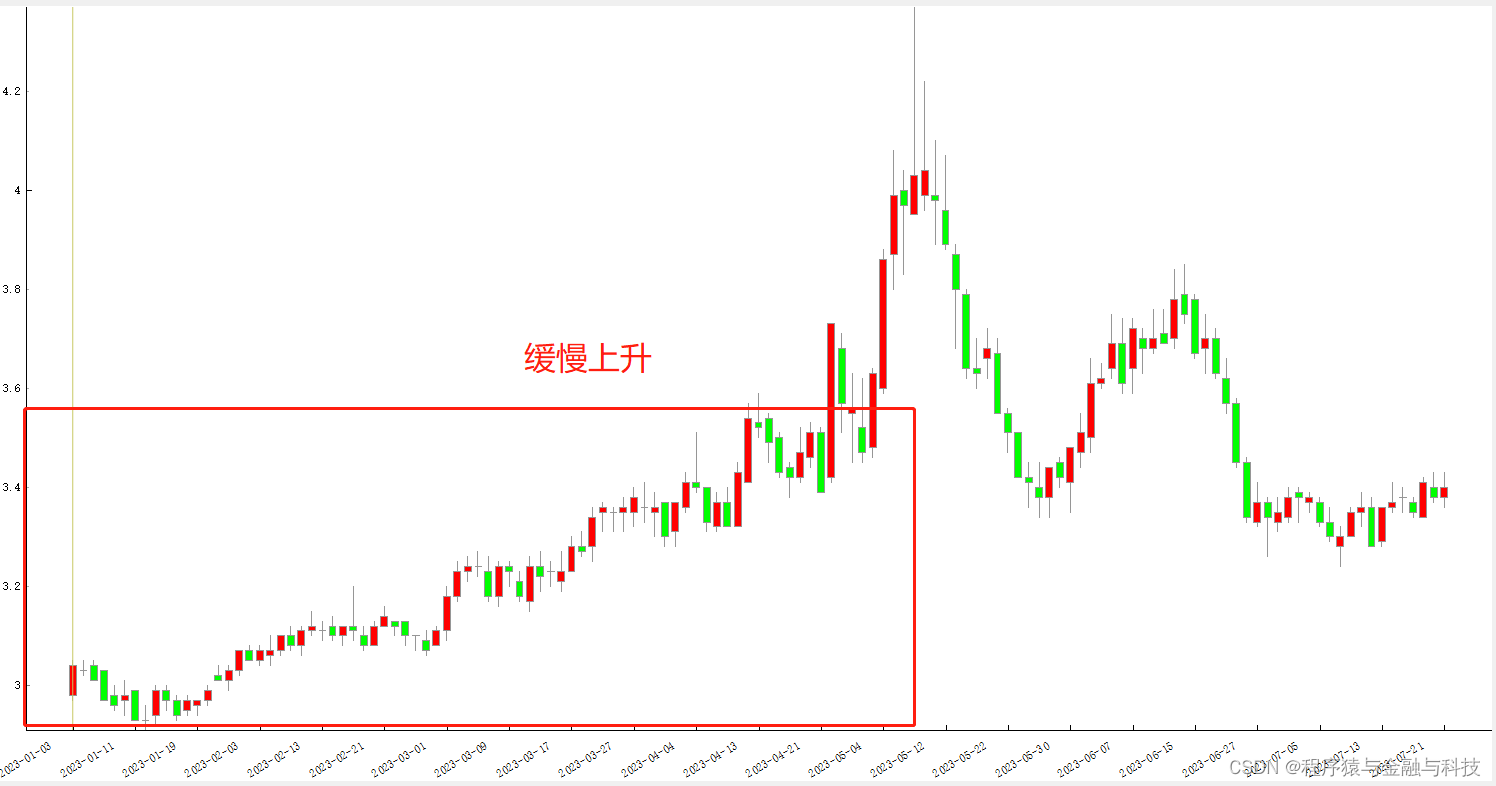
5 缓慢上升
PS:下面找了大致的K线图
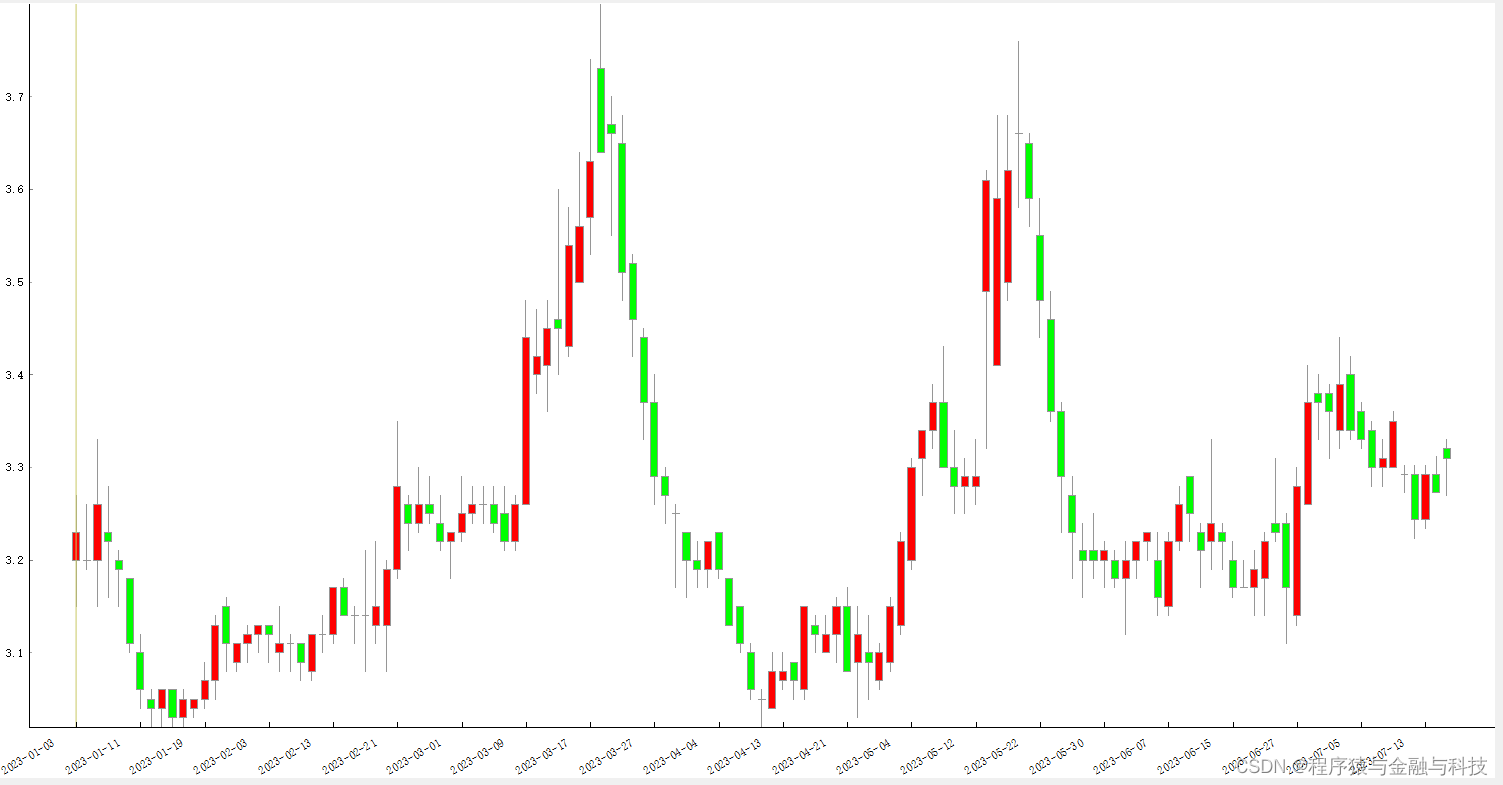
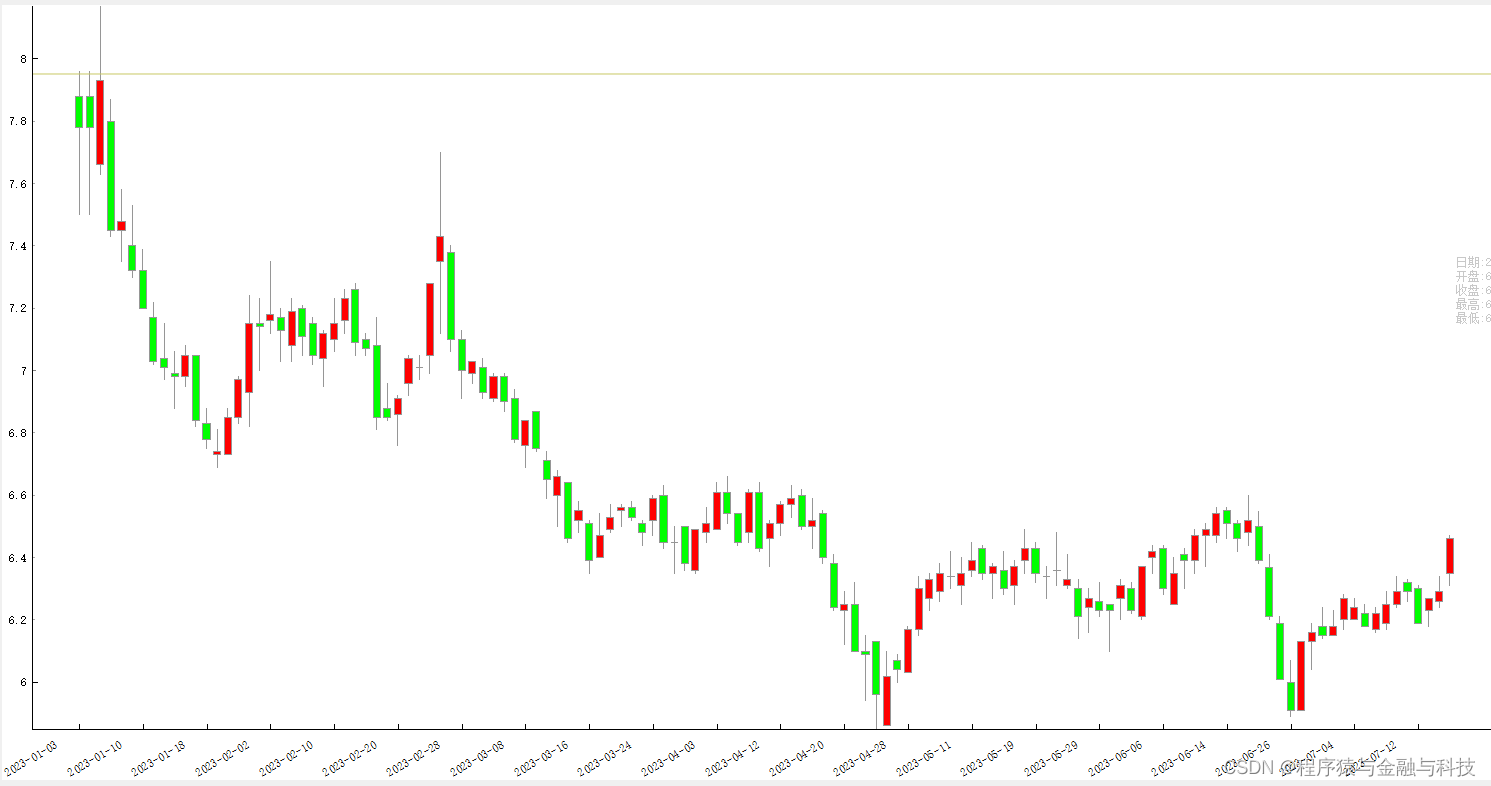
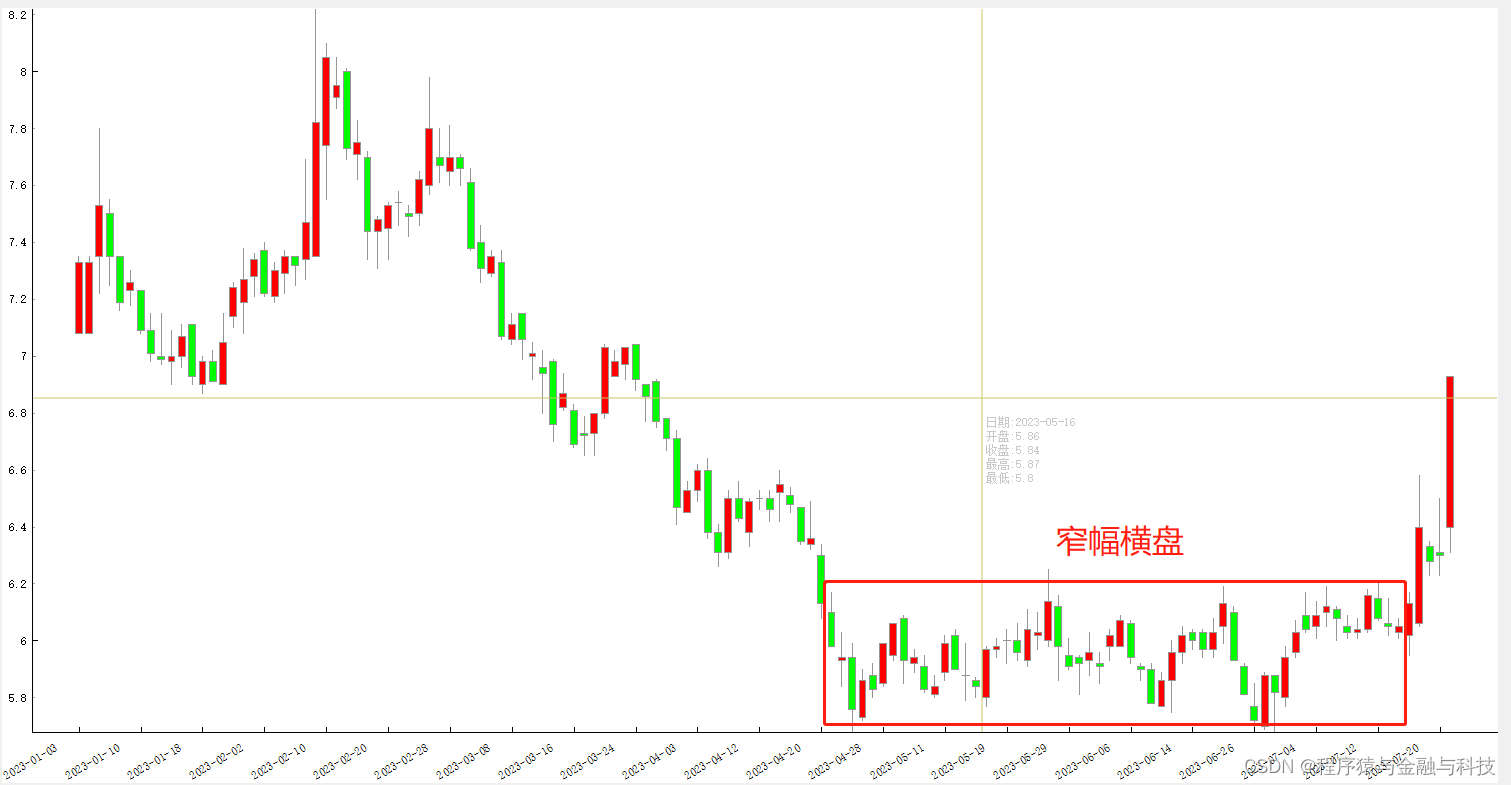
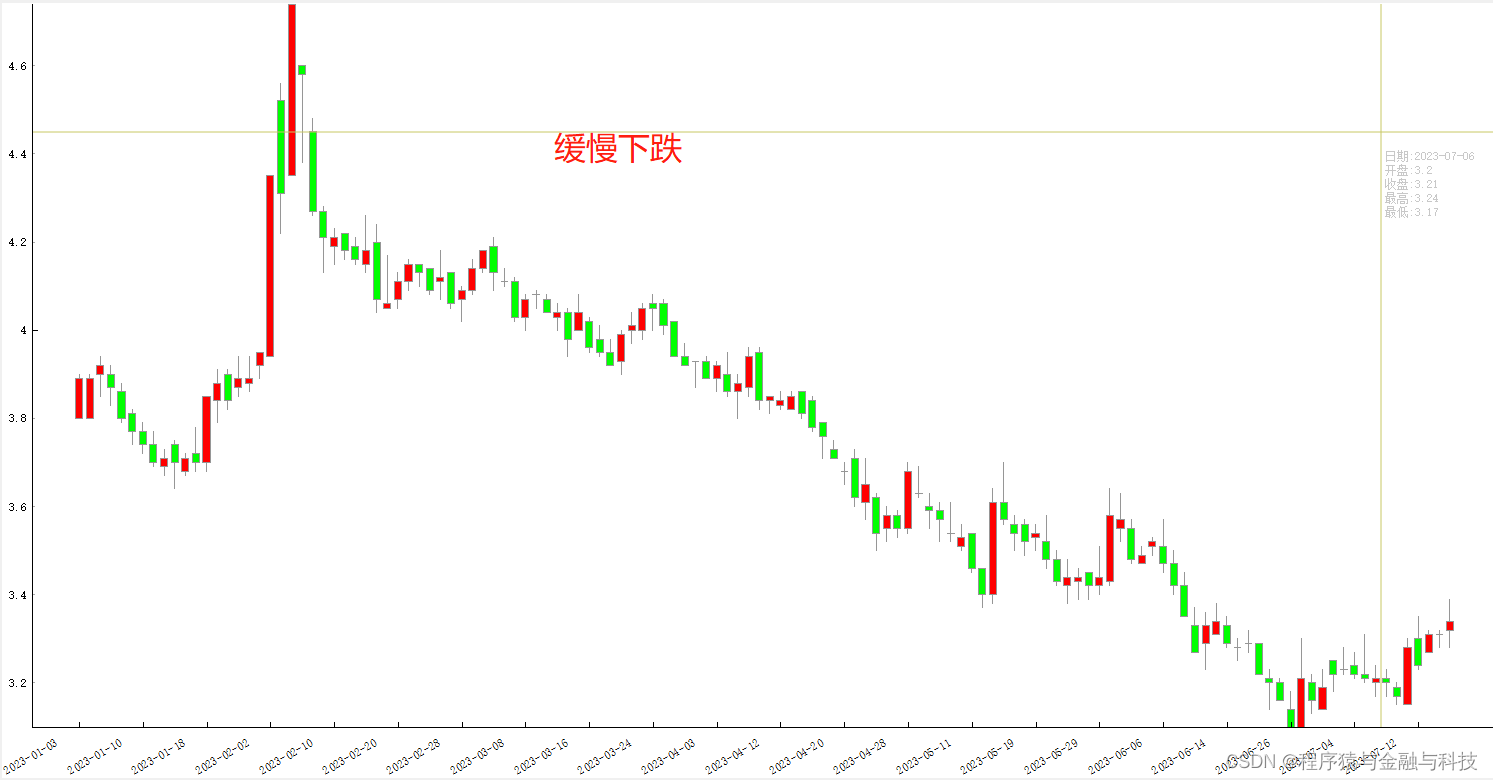
寻找所有转折点逻辑:
1 时间区间取今年年内的日K线
2 从最近的时间往前寻找,从K线图看就是从最右端向左边开始寻找
3 从右到左,遇到凸起点记录为峰(高点),遇到凹点记录为谷(低点),直到K线走完
4 代码逻辑上,使用pandas的cummax()寻找峰,cummin()寻找谷
5 循环交替寻找,找峰后找谷,再找峰再找谷。。。,每找到第一个峰或谷就返回,下回从上一次返回的点开始寻找
代码:
寻找转折点方法:找到第一个转折点就返回
def caculate_turning_point(pre_df,start_x,y_col,x_col,mark):
'''
计算转折点
:param pre_df: 要计算的数据
:param start_x: 起点
:param y_col: y的列名
:param x_col: x的列名
:param mark:True=峰 False=谷
:return: 第一个转折点 [x_val,y_val,mark]
'''
df = pre_df.loc[pre_df[x_col]<start_x].copy()
if mark:
# 峰值
df['p0'] = df[y_col].cummax()
df['p1'] = df['p0'] - df['p0'].shift(1)
df['p2'] = 1
df.loc[df['p1'] != 0, 'p2'] = 0
df['p3'] = 0
df.loc[(df['p2'] == 0) & (df['p2'].shift(-1) == 1), 'p3'] = 1
df_p = df.loc[df['p3']==1].copy()
if len(df_p)<=0:
return [None,None,mark]
else:
p_i = df_p.iloc[0][x_col]
p_y = df_p.iloc[0][y_col]
return [p_i,p_y,mark]
pass
else:
# 谷值
df['l0'] = df[y_col].cummin()
df['l1'] = df['l0'] - df['l0'].shift(1)
df['l2'] = 1
df.loc[df['l1'] != 0, 'l2'] = 0
df['l3'] = 0
df.loc[(df['l2'] == 0) & (df['l2'].shift(-1) == 1), 'l3'] = 1
df_l = df.loc[df['l3'] == 1].copy()
if len(df_l) <= 0:
return [None, None, mark]
else:
l_i = df_l.iloc[0][x_col]
l_y = df_l.iloc[0][y_col]
return [l_i, l_y, mark]
pass
pass
循环寻找峰谷方法
def circle_find(start_mark,i_start,pre_df,py_col,ly_col,x_col)->List:
res_list = []
i = i_start
while True:
if i<=0:
break
if start_mark:
# 峰值
res_one = caculate_turning_point(pre_df,i,py_col,x_col,start_mark)
else:
# 谷值
res_one = caculate_turning_point(pre_df,i,ly_col,x_col,start_mark)
if not res_one[0]:
break
res_list.append(res_one)
i = res_one[0]
start_mark = not start_mark
pass
return res_list
主方法
def enter_main(daily_file_path,start_date,end_date):
# 1 截取要计算的时间区间对应的日数据
df = pd.read_csv(daily_file_path,encoding='utf-8')
df['o_date'] = pd.to_datetime(df['tradeDate'])
df = df.loc[(df['o_date']>=start_date) & (df['o_date']<=end_date)].copy()
df = df.loc[df['openPrice']>0].copy()
df['o'] = df['openPrice'] * df['accumAdjFactor']
df['c'] = df['closePrice'] * df['accumAdjFactor']
df['h'] = df['highestPrice'] * df['accumAdjFactor']
df['l'] = df['lowestPrice'] * df['accumAdjFactor']
df = df.loc[:,['tradeDate','o','c','h','l']].copy()
# 2 逆序,并设置索引字段
df['i_row'] = [i for i in range(len(df))]
i_row_list = df['i_row'].values.tolist()
i_row_list.reverse()
df['i_row_r'] = i_row_list
h_list = df['h'].values.tolist()
h_list.reverse()
df['hr'] = h_list
l_list = df['l'].values.tolist()
l_list.reverse()
df['lr'] = l_list
# 3 从最新日期往前寻找所有转折点,即所有的峰谷值
res_list = []
i_len = len(i_row_list)
p_first = caculate_turning_point(df,i_len,'hr','i_row_r',True)
l_first = caculate_turning_point(df,i_len,'lr','i_row_r',False)
if p_first[0]<l_first[0]:
# 第一个
res_list.append(l_first)
res_list.append(p_first)
# 谷开始
res_list00 = circle_find(False, p_first[0], df, 'hr', 'lr', 'i_row_r')
pass
else:
# 第一个
res_list.append(p_first)
res_list.append(l_first)
# 峰开始
res_list00 = circle_find(True, l_first[0], df, 'hr', 'lr', 'i_row_r')
pass
res_list.extend(res_list00)
df_pv = pd.DataFrame(columns=['x','y','mark'],data=res_list)
return df_pv.loc[:,['x','y']].values.tolist()调用计算:
if __name__ == '__main__':
file_path = r'D:/600959.csv'
res = enter_main(file_path,'2023-01-01','2023-07-31')
print(res)返回:
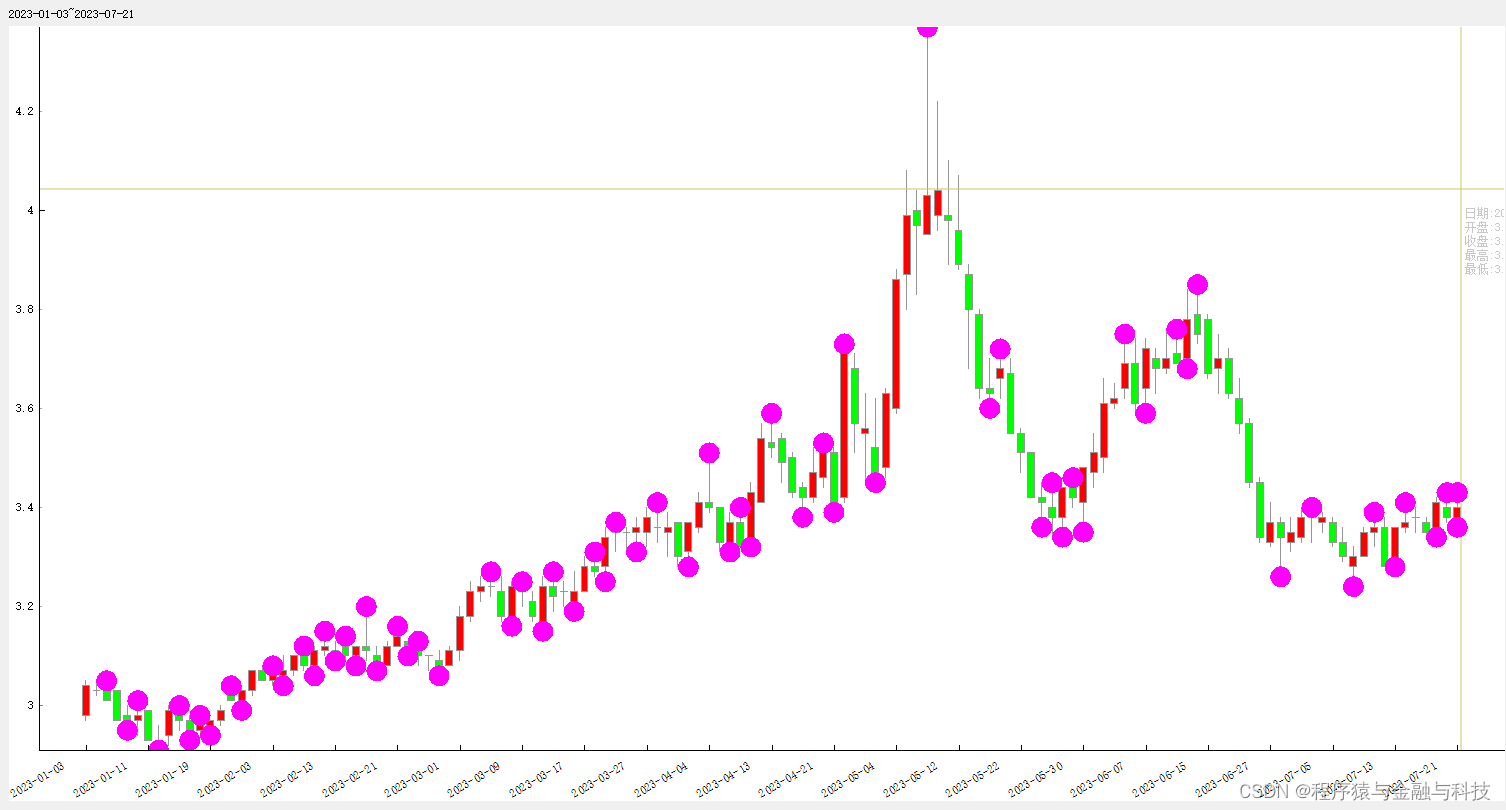
[[132.0, 3.43], [132.0, 3.36], [131.0, 3.43], [130.0, 3.34], [127.0, 3.41], [126.0, 3.28], [124.0, 3.39], [122.0, 3.24], [118.0, 3.4], [115.0, 3.26], [107.0, 3.85], [106.0, 3.68], [105.0, 3.76], [102.0, 3.59], [100.0, 3.75], [96.0, 3.35], [95.0, 3.46], [94.0, 3.34], [93.0, 3.45], [92.0, 3.36], [88.0, 3.72], [87.0, 3.6], [81.0, 4.37], [76.0, 3.45], [73.0, 3.73], [72.0, 3.39], [71.0, 3.53], [69.0, 3.38], [66.0, 3.59], [64.0, 3.32], [63.0, 3.4], [62.0, 3.31], [60.0, 3.51], [58.0, 3.28], [55.0, 3.41], [53.0, 3.31], [51.0, 3.37], [50.0, 3.25], [49.0, 3.31], [47.0, 3.19], [45.0, 3.27], [44.0, 3.15], [42.0, 3.25], [41.0, 3.16], [39.0, 3.27], [34.0, 3.06], [32.0, 3.13], [31.0, 3.1], [30.0, 3.16], [28.0, 3.07], [27.0, 3.2], [26.0, 3.08], [25.0, 3.14], [24.0, 3.09], [23.0, 3.15], [22.0, 3.06], [21.0, 3.12], [19.0, 3.04], [18.0, 3.08], [15.0, 2.99], [14.0, 3.04], [12.0, 2.94], [11.0, 2.98], [10.0, 2.93], [9.0, 3.0], [7.0, 2.91], [5.0, 3.01], [4.0, 2.95], [2.0, 3.05]]
在【PyQt5开发验证K线视觉想法工具V1.0】中查看效果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









