







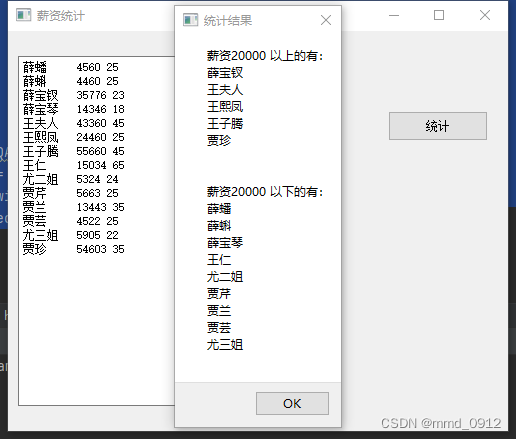
1.qt统计人员薪资信息界面
薛蟠 4560 25
薛蝌 4460 25
薛宝钗 35776 23
薛宝琴 14346 18
王夫人 43360 45
王熙凤 24460 25
王子腾 55660 45
王仁 15034 65
尤二姐 5324 24
贾芹 5663 25
贾兰 13443 35
贾芸 4522 25
尤三姐 5905 22
贾珍 54603 35
from PySide2.QtWidgets import QApplication, QMainWindow, QPushButton, QPlainTextEdit,QMessageBox
class Stats():
def __init__(self):
self.window = QMainWindow()
self.window.resize(500, 400)
self.window.move(300, 300)
self.window.setWindowTitle('薪资统计')
self.textEdit = QPlainTextEdit(self.window)
self.textEdit.setPlaceholderText("请输入薪资表")
self.textEdit.move(10, 25)
self.textEdit.resize(300, 350)
self.button = QPushButton('统计', self.window)
self.button.move(380, 80)
self.button.clicked.connect(self.handleCalc)
def handleCalc(self):
info = self.textEdit.toPlainText()
# 薪资20000 以上 和 以下 的人员名单
salary_above_20k = ''
salary_below_20k = ''
for line in info.splitlines():
if not line.strip():
continue
parts = line.split(' ')
# 去掉列表中的空字符串内容
parts = [p for p in parts if p]
name,salary,age = parts
if int(salary) >= 20000:
salary_above_20k += name + '\n'
else:
salary_below_20k += name + '\n'
QMessageBox.about(self.window,
'统计结果',
f'''薪资20000 以上的有:\n{salary_above_20k}
\n薪资20000 以下的有:\n{salary_below_20k}'''
)
app = QApplication([])
stats = Stats()
stats.window.show()
app.exec_()
呈现效果:
2. BMI----身高体重指数(18.5-23.9-28)
def achieve_bmi(name):
height = input("please input your height:")
weight = input("please input your weight:")
bmi = int(weight) / ((float(height) / 100) ** 2)
if bmi < 18.5:
print("{} are slim".format(name))
elif 18.5 <= bmi < 24:
print("{} are normal".format(name))
elif 24 <= bmi < 28:
print("{} are overweight".format(name))
else:
print("{} are too fat".format(name))
if __name__ == '__main__':
name = input("please input your name:")
achieve_bmi(name)
3. 简单购物车设计,程序执行时会列出所有商品,读者可以选择商品,如果所输入的商品在列表中则加入购物车,如果输入Q或q,则结束购物
message = "czy store"
products = ["dl", "cpp", "python", "opencv"]
storecar = []
print(message, '\n', products, '\n')
while True:
msg = input("please input your product(q=quit):")
if msg == 'q' or msg == 'Q':
break
else:
if msg in products:
storecar.append(msg)
print("your purchase list is:",storecar)
4. 成绩排序
# /bin/bash
5. 读一篇文章,并按这篇文章中的文字出现频率排序
import calendar
for name in sorted(players.keys()) # 根据字典键排序
newList = sorted(noodles.items(), key = lambda item:item[1])
ret_vaule = dict.get(key[,default=None])
a = {1, 2, 3}
b = {2, 4, 6}
ab = a&b = a.intersection(b)
c = a|b = a.union(b)
d = a - b = a.difference(b)
None 独立成为一个数据类型,NoneType
lott = random.sample(range(1,50), 7) #
random.choice(a)
time.sleep(1) #让工作暂停
time.asctime() #列出系统当前时间
time.localtime() #列出当地时间:年月日时分秒星期几第几天夏令时间
for i in range(3):
random.shuffle(a)
print(calendar.isleap(2020)) #是否闰年
print(calendar.month(2020,1))
print(calendar.calendar(2020))

在这里插入代码片
6. 抽奖代码
7. 实现一个简单的计算器
import sys
import re
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import QMainWindow
class Calculator_Window(QMainWindow):
def setupUi(self, CalculatorWindow):
CalculatorWindow.setObjectName("Calculator")
CalculatorWindow.resize(500, 800)
# 1: 先打一条显示器
self.showEdit = QtWidgets.QLineEdit(CalculatorWindow)
self.showEdit.setGeometry(QtCore.QRect(20, 40, 300, 60))
# 2: 打一个 九宫格 ,并把相应的数字打 [ 先打一个主框,左九宫格,右+-*/, 然后用窗口添加该主框 ]
self.containerWidget = QtWidgets.QWidget(CalculatorWindow)
self.containerWidget.setObjectName("containerWidget")
# 3: 1 - 9 数字的布局
self.gridLayoutWidget = QtWidgets.QWidget(self.containerWidget)
self.gridLayoutWidget.setGeometry(QtCore.QRect(20, 100, 300, 500))
self.gridLayoutWidget.setObjectName("gridLayoutWidget")
self.gridLayout = QtWidgets.QGridLayout(self.gridLayoutWidget)
self.gridLayout.setContentsMargins(0, 0, 0, 0) # 这里的 setContentsMargins 是左, 上, 右, 下
self.gridLayout.setObjectName("gridLayout")
self.btn_nmb_1 = QtWidgets.QPushButton(self.gridLayoutWidget)
self.btn_nmb_1.setObjectName("btn_nmb_1")
self.gridLayout.addWidget(self.btn_nmb_1, 0, 0, 1, 1)
self.btn_nmb_2 = QtWidgets.QPushButton(self.gridLayoutWidget)
self.btn_nmb_2.setObjectName("btn_nmb_2")
self.gridLayout.addWidget(self.btn_nmb_2, 0, 1, 1, 1)
self.btn_nmb_3 = QtWidgets.QPushButton(self.gridLayoutWidget)
self.btn_nmb_3.setObjectName("btn_nmb_3")
self.gridLayout.addWidget(self.btn_nmb_3, 0, 2, 1, 1)
self.btn_nmb_4 = QtWidgets.QPushButton(self.gridLayoutWidget)
self.btn_nmb_4.setObjectName("btn_nmb_4")
self.gridLayout.addWidget(self.btn_nmb_4, 1, 0, 1, 1)
self.btn_nmb_5 = QtWidgets.QPushButton(self.gridLayoutWidget)
self.btn_nmb_5.setObjectName("btn_nmb_5")
self.gridLayout.addWidget(self.btn_nmb_5, 1, 1, 1, 1)
self.btn_nmb_6 = QtWidgets.QPushButton(self.gridLayoutWidget)
self.btn_nmb_6.setObjectName("btn_nmb_6")
self.gridLayout.addWidget(self.btn_nmb_6, 1, 2, 1, 1)
self.btn_nmb_7 = QtWidgets.QPushButton(self.gridLayoutWidget)
self.btn_nmb_7.setObjectName("btn_nmb_7")
self.gridLayout.addWidget(self.btn_nmb_7, 2, 0, 1, 1)
self.btn_nmb_8 = QtWidgets.QPushButton(self.gridLayoutWidget)
self.btn_nmb_8.setObjectName("btn_nmb_8")
self.gridLayout.addWidget(self.btn_nmb_8, 2, 1, 1, 1)
self.btn_nmb_9 = QtWidgets.QPushButton(self.gridLayoutWidget)
self.btn_nmb_9.setObjectName("btn_nmb_9")
self.gridLayout.addWidget(self.btn_nmb_9, 2, 2, 1, 1)
# + - * / 的垂直布局
self.verticalLayoutWidget = QtWidgets.QWidget(self.containerWidget)
self.verticalLayoutWidget.setGeometry(QtCore.QRect(340, 100, 70, 450))
self.verticalLayoutWidget.setObjectName("verticalLayoutWidget")
self.verticalLayout = QtWidgets.QVBoxLayout(self.verticalLayoutWidget)
self.verticalLayout.setContentsMargins(0, 0, 0, 0)
self.verticalLayout.setObjectName("verticalLayout")
self.btn_add = QtWidgets.QPushButton(self.verticalLayoutWidget)
self.btn_add.setObjectName("btn_add")
self.verticalLayout.addWidget(self.btn_add)
self.btn_minus = QtWidgets.QPushButton(self.verticalLayoutWidget)
self.btn_minus.setObjectName("btn_minus")
self.verticalLayout.addWidget(self.btn_minus)
self.btn_multiply = QtWidgets.QPushButton(self.verticalLayoutWidget)
self.btn_multiply.setObjectName("btn_multiply")
self.verticalLayout.addWidget(self.btn_multiply)
self.btn_divide = QtWidgets.QPushButton(self.verticalLayoutWidget)
self.btn_divide.setObjectName("btn_divide")
self.verticalLayout.addWidget(self.btn_divide)
self.btn_equal = QtWidgets.QPushButton(self.verticalLayoutWidget)
self.btn_equal.setObjectName("btn_equal")
self.verticalLayout.addWidget(self.btn_equal)
CalculatorWindow.setCentralWidget(self.containerWidget) # 窗口添加该主框
self.retranslateUi(CalculatorWindow) # 设置文字的的函数
QtCore.QMetaObject.connectSlotsByName(CalculatorWindow) # 连接到指定的槽
def retranslateUi(self, CalculatorWindow):
_translate = QtCore.QCoreApplication.translate
CalculatorWindow.setWindowTitle("计算器")
self.showEdit.setText(_translate("CalculatorWindow", " 1 + 1 = 2")) # 显示框
# 1 - 9 按钮上的数字填充
self.btn_nmb_1.setText(_translate("CalculatorWindow", "1"))
self.btn_nmb_2.setText(_translate("CalculatorWindow", "2"))
self.btn_nmb_3.setText(_translate("CalculatorWindow", "3"))
self.btn_nmb_4.setText(_translate("CalculatorWindow", "4"))
self.btn_nmb_5.setText(_translate("CalculatorWindow", "5"))
self.btn_nmb_6.setText(_translate("CalculatorWindow", "6"))
self.btn_nmb_7.setText(_translate("CalculatorWindow", "7"))
self.btn_nmb_8.setText(_translate("CalculatorWindow", "8"))
self.btn_nmb_9.setText(_translate("CalculatorWindow", "9"))
# + - * / 的字符填充
self.btn_add.setText(_translate("CalculatorWindow", "+"))
self.btn_minus.setText(_translate("CalculatorWindow", "-"))
self.btn_multiply.setText(_translate("CalculatorWindow", "*"))
self.btn_divide.setText(_translate("CalculatorWindow", "/"))
self.btn_equal.setText(_translate("CalculatorWindow", "="))
# 给每个按钮的点击事件,统一处理
self.btn_nmb_1.clicked.connect(self.btnClick)
self.btn_nmb_2.clicked.connect(self.btnClick)
self.btn_nmb_3.clicked.connect(self.btnClick)
self.btn_nmb_4.clicked.connect(self.btnClick)
self.btn_nmb_5.clicked.connect(self.btnClick)
self.btn_nmb_6.clicked.connect(self.btnClick)
self.btn_nmb_7.clicked.connect(self.btnClick)
self.btn_nmb_8.clicked.connect(self.btnClick)
self.btn_nmb_9.clicked.connect(self.btnClick)
self.btn_add.clicked.connect(self.btnClick)
self.btn_minus.clicked.connect(self.btnClick)
self.btn_multiply.clicked.connect(self.btnClick)
self.btn_divide.clicked.connect(self.btnClick)
self.btn_equal.clicked.connect(self.btnClick)
showString = ' '
nmb1 = 0 # 第一个数字
nmbOprerator = ''
nmb2 = 0 # 第二个数字
nmb3 = 0 # 第三个数字
def btnClick(self): # 统一处理按钮事件; 思路:数字 + 符号 字符串 = 这种格式
sender = self.sender()
senderText = sender.text()
self.valueNmb(str(senderText))
def valueNmb(self, senderText): # 对按下的按钮进行计算
if (senderText == "+" or senderText == "-" or senderText == "*" or senderText == "/"):
self.showString += " " + senderText + " "
self.nmb1 = re.sub(r'\D', "", self.showString) # 取符号前面的数字为 nmb1
self.nmbOprerator = senderText
self.showRes(str(self.nmb1) + " " + self.nmbOprerator + " ")
elif (senderText == "="):
self.showString += senderText
nmb2Index = self.showString.find(self.nmbOprerator) + 1 # +1 是因为把 + - * / 的符号去掉
self.nmb2 = self.showString[nmb2Index: -1]
self.nmb3 = self.switchCal(int(self.nmb1), str(self.nmbOprerator), int(self.nmb2))
self.showRes(str(self.nmb1) + " " + self.nmbOprerator + " " + str(self.nmb2) + " = " + str(self.nmb3))
else:
self.showString += senderText
self.showRes(self.showString)
def switchCal(self, nmb1, nmbOprerator, nmb2): # nmb3 进行计算
nmb1 = int(nmb1)
nmb2 = int(nmb2)
if (nmbOprerator == "+"):
return nmb1 + nmb2
elif (nmbOprerator == "-"):
return nmb1 - nmb2
elif (nmbOprerator == "*"):
return nmb1 * nmb2
elif (nmbOprerator == "/"):
return nmb1 / nmb2
else:
return 0
def showRes(self, string): # 按钮改变显示的内容
self.showEdit.setText(string)
if __name__ == "__main__":
app = QtWidgets.QApplication(sys.argv)
widget = QtWidgets.QMainWindow()
window = Calculator_Window()
window.setupUi(widget)
widget.show()
sys.exit(app.exec())
8. 创建一个密码生成器
import random
import string
def generate_password(length):
# 定义密码中包含的字符集
chars = string.ascii_letters + string.digits + string.punctuation
# 生成随机密码
password = ''.join(random.choice(chars) for i in range(length))
return password
# 生成一个长度为10的随机密码
password = generate_password(10)
print(password)
9.创建一个简单的文本编辑器
import tkinter as tk
from tkinter import filedialog, Text, Menu
class TextEditor:
def __init__(self, master):
self.master = master
master.title("Simple Text Editor")
master.geometry("400x300")
self.text_frame = tk.Frame(master)
self.text_frame.pack(fill=tk.BOTH, expand=1)
self.text_area = Text(self.text_frame)
self.text_area.pack(fill=tk.BOTH, expand=1)
self.menu_bar = Menu(master)
master.config(menu=self.menu_bar)
self.file_menu = Menu(self.menu_bar, tearoff=0)
self.file_menu.add_command(label="New", command=self.new_file)
self.file_menu.add_command(label="Open", command=self.open_file)
self.file_menu.add_command(label="Save", command=self.save_file)
self.file_menu.add_command(label="Exit", command=master.quit)
self.menu_bar.add_cascade(label="File", menu=self.file_menu)
def new_file(self):
self.text_area.delete("1.0", tk.END)
def open_file(self):
file_path = filedialog.askopenfilename()
if file_path:
with open(file_path, "r") as file:
content = file.read()
self.text_area.insert(tk.END, content)
def save_file(self):
file_path = filedialog.asksaveasfilename()
if file_path:
with open(file_path, "w") as file:
content = self.text_area.get("1.0", tk.END)
file.write(content)
root = tk.Tk()
editor = TextEditor(root)
root.mainloop()
10.实现一个命令行翻译工具
在这里插入代码片
11.实现一个天气查询工具
在这里插入代码片
12.实现一个电子邮件发送工具
13.实现一个日历应用
14.实现一个简单的任务管理器
15.实现一个音乐播放器
16.实现一个简单的图像处理工具
17.实现一个简单的网站爬虫
18.实现一个简单的网络速度测试工具
import time
import socket
# 目标服务器地址和端口号
server_address = ('www.baidu.com', 80)
# 测试下载速度
def test_download_speed():
print('开始下载速度测试...')
start_time = time.time()
downloaded_bytes = 0
block_size = 1024 * 1024 # 1MB
data = b''
while True:
try:
# 连接服务器
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect(server_address)
# 下载数据块
while len(data) < block_size:
received_bytes = s.recv(block_size - len(data))
if not received_bytes:
break
data += received_bytes
downloaded_bytes += len(data)
elapsed_time = time.time() - start_time
download_speed = downloaded_bytes / elapsed_time / 1024 / 1024 # MB/s
print(f'下载速度:{download_speed:.5f} MB/s')
except KeyboardInterrupt:
break
except Exception as e:
print(f'下载速度测试出错:{e}')
break
print('下载速度测试完成。')
# 测试上传速度
def test_upload_speed():
print('开始上传速度测试...')
start_time = time.time()
uploaded_bytes = 0
block_size = 1024 * 1024 # 1MB
data = b'x' * block_size # 填充数据块
while True:
try:
# 连接服务器
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect(server_address)
# 上传数据块
s.sendall(data)
uploaded_bytes += len(data)
elapsed_time = time.time() - start_time
upload_speed = uploaded_bytes / elapsed_time / 1024 / 1024 # MB/s
print(f'上传速度:{upload_speed:.2f} MB/s')
except KeyboardInterrupt:
break
except Exception as e:
print(f'上传速度测试出错:{e}')
break
print('上传速度测试完成。')
if __name__ == '__main__':
test_download_speed() # 先测试下载速度,再测试上传速度(可根据需要调整顺序)
test_upload_speed() # 先测试下载速度,再测试上传速度(可根据需要调整顺序)
19.实现一个简单的数据可视化工具
20.实现一个简单的数据分析工具
21.实现一个简单的人脸检测工具
import cv2
# 加载Haar Cascade分类器
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 读取图像
img = cv2.imread('image.jpg')
# 将图像转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
# 在人脸周围绘制矩形框
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示结果图像
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
22.实现一个简单的数字识别工具
23.实现一个简单的自然语言处理工具
24.实现一个简单的机器学习模型
25.实现一个简单的深度学习模型
26.实现一个简单的推荐系统
27.实现一个简单的聊天机器人
28.实现一个简单的游戏
29. 实现一个简单的数据结构
30. 实现一个简单的算法
31. 实现一个简单的网络应用
32. 实现一个简单的图形用户界面
33. 实现一个简单的数据库应用
34. 实现一个简单的文件处理工具
35. 实现一个简单的进程管理工具
36. 实现一个简单的线程管理工具
37. 实现一个简单的并发编程工具
38. 实现一个简单的异步编程工具
39. 实现一个简单的数据存储工具
40. 实现一个简单的数据读取工具
41. 实现一个简单的数据清洗工具
42. 实现一个简单的数据转换工具
43. 实现一个简单的数据备份工具
44. 实现一个简单的数据恢复工具
45. 实现一个简单的数据安全工具
46. 实现一个简单的网络安全工具
47. 实现一个简单的密码管理工具
48. 实现一个简单的网络监控工具
49. 实现一个简单的数据加密工具
50. 实现一个简单的数据解密工具
51. 实现一个简单的压缩工具
52. 实现一个简单的解压工具
53. 实现一个简单的文件传输工具
54. 实现一个简单的协议分析工具
55. 实现一个简单的音频处理工具
56. 实现一个简单的视频处理工具
57.将图片转换为视频
import os
import cv2
from PIL import Image
def unlock_movie(path):
cap = cv2.VideoCapture(path)
suc = cap.isOpened()
frame_count = 0
while suc:
frame_count += 1
suc, frame = cap.read()
params = []
params.append(2) # params.append(1)
cv2.imwrite('frames\\%d.jpg' % frame_count, frame, params)
cap.release()
print('unlock movie: ', frame_count)
def jpg_to_video(path, fps):
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
images = os.listdir('frames')
image = Image.open('frames/' + images[0])
vw = cv2.VideoWriter(path, fourcc, fps, image.size)
os.chdir('frames')
for i in range(len(images)):
# Image.open(str(image)+'.jpg').convert("RGB").save(str(image)+'.jpg')
jpgfile = str(i + 1) + '.jpg'
try:
new_frame = cv2.imread(jpgfile)
vw.write(new_frame)
except Exception as exc:
print(jpgfile, exc)
vw.release()
print(path, 'Synthetic success!')
if __name__ == '__main__':
PATH_TO_MOVIES = os.path.join('test_movies', 'beautiful_mind2.mp4')
PATH_TO_OUTCOME = os.path.join('detection_movies', 'beautiful_mind2_detection_1.avi')
unlock_movie(PATH_TO_MOVIES)
jpg_to_video(PATH_TO_OUTCOME, 24)
58.图片画框
import os
import cv2
f = open('eval.txt','r')
path = '/data/mmdetection/data/images'
pathresult = './result'
jpg_list = f.readlines()
path2 = []
for jpg in jpg_list:
txt_list = jpg.strip().split(',')
if(txt_list[1] not in path2):
image = cv2.imread(os.path.join(path,txt_list[1]))
cv2.rectangle(image,(int(txt_list[4]),int(txt_list[5])),(int(txt_list[6]),int(txt_list[7])),(0,250,0),4)
cv2.putText(image, txt_list[2], (int(txt_list[4]), int(txt_list[5])), cv2.FONT_HERSHEY_COMPLEX , 2, (0,0,250), 3)
cv2.imwrite('./result/{}'.format(txt_list[1]), image)
path2.append(txt_list[1])
else:
image = cv2.imread(os.path.join(pathresult,txt_list[1]))
cv2.rectangle(image,(int(txt_list[4]),int(txt_list[5])),(int(txt_list[6]),int(txt_list[7])),(0,250,0),4)
cv2.putText(image, txt_list[2], (int(txt_list[4]), int(txt_list[5])), cv2.FONT_HERSHEY_COMPLEX , 2, (0,0,250), 3)
cv2.imwrite('./result/{}'.format(txt_list[1]), image)
59.利用opencv根据视频帧数获取指定时间段的视频
import cv2
print(cv2.__version__)
videoCapture = cv2.VideoCapture('3.mp4')
fps = 10
size = (1920,1080)
videoWriter0 =cv2.VideoWriter('det.avi',cv2.VideoWriter_fourcc('X','V','I','D'),fps,size)
i = 0
while True:
success,frame = videoCapture.read()
if success:
i += 1
print('i = ',i)
if(25*4095 <= i <= 25*4162):
videoWriter0.write(frame)
else:
print('end')
break
60.实现VOC数据集转化为COCO数据集
# -*- coding:utf-8 -*-
# !/usr/bin/env python
import argparse
import json
import matplotlib.pyplot as plt
import skimage.io as io
import cv2
from labelme import utils
import numpy as np
import glob
import PIL.Image
import os,sys
class PascalVOC2coco(object):
def __init__(self, xml=[], save_json_path='./new.json'):
'''
:param xml: 所有Pascal VOC的xml文件路径组成的列表
:param save_json_path: json保存位置
'''
self.xml = xml
self.save_json_path = save_json_path
self.images = []
self.categories = []
self.annotations = []
# self.data_coco = {}
self.label = []
self.annID = 1
self.height = 0
self.width = 0
self.ob = []
self.save_json()
def data_transfer(self):
for num, json_file in enumerate(self.xml):
# 进度输出
sys.stdout.write('\r>> Converting image %d/%d' % (
num + 1, len(self.xml)))
sys.stdout.flush()
self.json_file = json_file
#print("self.json", self.json_file)
self.num = num
#print(self.num)
path = os.path.dirname(self.json_file)
#print(path)
path = os.path.dirname(path)
print(path)
# path=os.path.split(self.json_file)[0]
# path=os.path.split(path)[0]
obj_path = glob.glob(os.path.join(path, 'SegmentationObject', '*.png'))
#print(obj_path)
with open(json_file, 'r') as fp:
#print(fp)
flag = 0
for p in fp:
#print(p)
# if 'folder' in p:
# folder =p.split('>')[1].split('<')[0]
f_name = 1
if 'filename' in p:
self.filen_ame = p.split('>')[1].split('<')[0]
print(self.filen_ame)
f_name = 0
self.path = os.path.join(path, 'SegmentationObject', self.filen_ame.split('.')[0] + '.png')
#if self.path not in obj_path:
# break
if 'width' in p:
self.width = int(p.split('>')[1].split('<')[0])
#print(self.width)
if 'height' in p:
self.height = int(p.split('>')[1].split('<')[0])
self.images.append(self.image())
#print(self.image())
if flag == 1:
self.supercategory = self.ob[0]
if self.supercategory not in self.label:
self.categories.append(self.categorie())
self.label.append(self.supercategory)
# 边界框
x1 = int(float(self.ob[-4]));
y1 = int(float(self.ob[-3]));
x2 = int(float(self.ob[-2]));
y2 = int(float(self.ob[-1]));
self.rectangle = [x1, y1, x2, y2]
self.bbox = [x1, y1, x2 - x1, y2 - y1] # COCO 对应格式[x,y,w,h]
self.annotations.append(self.annotation())
self.annID += 1
self.ob = []
flag = 0
elif f_name == 1:
if 'name' in p:
self.ob.append(p.split('>')[1].split('<')[0])
if 'xmin' in p:
self.ob.append(p.split('>')[1].split('<')[0])
if 'ymin' in p:
self.ob.append(p.split('>')[1].split('<')[0])
if 'xmax' in p:
self.ob.append(p.split('>')[1].split('<')[0])
if 'ymax' in p:
self.ob.append(p.split('>')[1].split('<')[0])
flag = 1
'''
if '<object>' in p:
# 类别
print(next(fp))
d = [next(fp).split('>')[1].split('<')[0] for _ in range(7)]
self.supercategory = d[0]
if self.supercategory not in self.label:
self.categories.append(self.categorie())
self.label.append(self.supercategory)
# 边界框
x1 = int(d[-4]);
y1 = int(d[-3]);
x2 = int(d[-2]);
y2 = int(d[-1])
self.rectangle = [x1, y1, x2, y2]
self.bbox = [x1, y1, x2 - x1, y2 - y1] # COCO 对应格式[x,y,w,h]
self.annotations.append(self.annotation())
self.annID += 1
'''
sys.stdout.write('\n')
sys.stdout.flush()
def image(self):
image = {}
image['height'] = self.height
image['width'] = self.width
image['id'] = self.num + 1
name1111,name2222 = os.path.split(self.json_file)
name3333,name4444 = os.path.splitext(name2222)
name5555 = name3333 + ".jpg"
image['file_name'] = name5555
return image
def categorie(self):
categorie = {}
categorie['supercategory'] = self.supercategory
categorie['id'] = len(self.label) + 1 # 0 默认为背景
categorie['name'] = self.supercategory
return categorie
def annotation(self):
annotation = {}
# annotation['segmentation'] = [self.getsegmentation()]
annotation['segmentation'] = [list(map(float, self.getsegmentation()))]
annotation['iscrowd'] = 0
annotation['image_id'] = self.num + 1
# annotation['bbox'] = list(map(float, self.bbox))
annotation['bbox'] = self.bbox
annotation['category_id'] = self.getcatid(self.supercategory)
annotation['id'] = self.annID
return annotation
def getcatid(self, label):
for categorie in self.categories:
if label == categorie['name']:
return categorie['id']
return -1
def getsegmentation(self):
try:
mask_1 = cv2.imread(self.path, 0)
mask = np.zeros_like(mask_1, np.uint8)
rectangle = self.rectangle
mask[rectangle[1]:rectangle[3], rectangle[0]:rectangle[2]] = mask_1[rectangle[1]:rectangle[3],
rectangle[0]:rectangle[2]]
# 计算矩形中点像素值
mean_x = (rectangle[0] + rectangle[2]) // 2
mean_y = (rectangle[1] + rectangle[3]) // 2
end = min((mask.shape[1], int(rectangle[2]) + 1))
start = max((0, int(rectangle[0]) - 1))
flag = True
for i in range(mean_x, end):
x_ = i;
y_ = mean_y
pixels = mask_1[y_, x_]
if pixels != 0 and pixels != 220: # 0 对应背景 220对应边界线
mask = (mask == pixels).astype(np.uint8)
flag = False
break
if flag:
for i in range(mean_x, start, -1):
x_ = i;
y_ = mean_y
pixels = mask_1[y_, x_]
if pixels != 0 and pixels != 220:
mask = (mask == pixels).astype(np.uint8)
break
self.mask = mask
return self.mask2polygons()
except:
return [0]
def mask2polygons(self):
contours = cv2.findContours(self.mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) # 找到轮廓线
bbox=[]
for cont in contours[1]:
[bbox.append(i) for i in list(cont.flatten())]
# map(bbox.append,list(cont.flatten()))
return bbox # list(contours[1][0].flatten())
# '''
def getbbox(self, points):
# img = np.zeros([self.height,self.width],np.uint8)
# cv2.polylines(img, [np.asarray(points)], True, 1, lineType=cv2.LINE_AA) # 画边界线
# cv2.fillPoly(img, [np.asarray(points)], 1) # 画多边形 内部像素值为1
polygons = points
mask = self.polygons_to_mask([self.height, self.width], polygons)
return self.mask2box(mask)
def mask2box(self, mask):
'''从mask反算出其边框
mask:[h,w] 0、1组成的图片
1对应对象,只需计算1对应的行列号(左上角行列号,右下角行列号,就可以算出其边框)
'''
# np.where(mask==1)
index = np.argwhere(mask == 1)
rows = index[:, 0]
clos = index[:, 1]
# 解析左上角行列号
left_top_r = np.min(rows) # y
left_top_c = np.min(clos) # x
# 解析右下角行列号
right_bottom_r = np.max(rows)
right_bottom_c = np.max(clos)
# return [(left_top_r,left_top_c),(right_bottom_r,right_bottom_c)]
# return [(left_top_c, left_top_r), (right_bottom_c, right_bottom_r)]
# return [left_top_c, left_top_r, right_bottom_c, right_bottom_r] # [x1,y1,x2,y2]
return [left_top_c, left_top_r, right_bottom_c - left_top_c,
right_bottom_r - left_top_r] # [x1,y1,w,h] 对应COCO的bbox格式
def polygons_to_mask(self, img_shape, polygons):
mask = np.zeros(img_shape, dtype=np.uint8)
mask = PIL.Image.fromarray(mask)
xy = list(map(tuple, polygons))
PIL.ImageDraw.Draw(mask).polygon(xy=xy, outline=1, fill=1)
mask = np.array(mask, dtype=bool)
return mask
# '''
def data2coco(self):
data_coco = {}
data_coco['images'] = self.images
data_coco['categories'] = self.categories
data_coco['annotations'] = self.annotations
return data_coco
def save_json(self):
self.data_transfer()
self.data_coco = self.data2coco()
# 保存json文件
json.dump(self.data_coco, open(self.save_json_path, 'w'), indent=4) # indent=4 更加美观显示
xml_file = glob.glob('./Annotations/*.xml')
PascalVOC2coco(xml_file, 'train.json')
61.爬取猫眼电影
from urllib import request
import time
import re
import pymongo
class MaoyanSpider(object):
def __init__(self):
self.baseurl = 'https://maoyan.com/board/4?offset='
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
}
# 爬取页数计数
self.page = 1
self.conn = pymongo.MongoClient('localhost', 27017)
self.db = self.conn['maoyandb']
self.myset = self.db['filmset']
# 获取页面
def get_page(self,url):
req = request.Request(url,headers=self.headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 直接调用解析函数
self.parse_page(html)
# 解析页面
def parse_page(self,html):
# 正则解析
p = re.compile('<div class="movie-item-info">.*?title="(.*?)".*?class="star">(.*?)</p>.*?releasetime">(.*?)</p>',re.S)
r_list = p.findall(html)
# r_list : [('霸王别姬','张国荣','1993'),(),()]
self.write_mongo(r_list)
# 保存数据(从终端输出)
def write_mongo(self, r_list):
for rt in r_list:
film = {
'名称': rt[0].strip(),
'主演': rt[1].strip(),
'时间': rt[2].strip()
}
self.myset.insert_one(film)
# 主函数
def main(self):
# 用range函数可获取某些查询参数的值
for offset in range(0, 41, 10):
url = self.baseurl + str(offset)
self.get_page(url)
print('第%d页爬取成功' % self.page)
self.page += 1
time.sleep(1)
if __name__ == '__main__':
spider = MaoyanSpider()
spider.main()
from urllib import request
import re
import time
import random
import pymysql
class MaoyanSpider(object):
def __init__(self):
self.base_url = 'https://maoyan.com/board/4?offset={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
}
self.page = 1
self.db = pymysql.connect(
'localhost', 'root', '123456', 'maoyandb', charset='utf8'
)
self.cursor = self.db.cursor()
def get_pages(self, url):
req = request.Request(url, headers=self.headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
self.parse_page(html)
def parse_page(self, html):
pattern = re.compile('<a href.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>', re.S)
results = pattern.findall(html)
self.write_sql(results)
def write_sql(self, results):
data_list = []
for film in results:
L = [
film[0].strip(),
film[1].strip(),
film[2].strip()[5:15]]
data_list.append(L)
ins = 'insert into filmset values(%s,%s,%s)'
self.cursor.executemany(ins, data_list)
self.db.commit()
def main(self):
# 用range函数可获取某些查询参数的值
for offset in range(0, 41, 10):
url = self.base_url.format(str(offset))
self.get_pages(url)
print('第%d页爬取成功' % self.page)
self.page += 1
time.sleep(random.randint(1, 2))
self.cursor.close()
self.db.close()
if __name__ == '__main__':
spider = MaoyanSpider()
spider.main()
from urllib import request
import time
import re
import csv
class MaoyanSpider(object):
def __init__(self):
self.baseurl = 'https://maoyan.com/board/4?offset='
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
}
# 爬取页数计数
self.page = 1
# 获取页面
def get_page(self,url):
req = request.Request(url,headers=self.headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 直接调用解析函数
self.parse_page(html)
# 解析页面
def parse_page(self,html):
# 正则解析
p = re.compile('<div class="movie-item-info">.*?title="(.*?)".*?class="star">(.*?)</p>.*?releasetime">(.*?)</p>',re.S)
r_list = p.findall(html)
self.write_page(r_list)
# 保存数据
def write_page(self,r_list):
film_list = []
with open('maoyanfilm.csv','a') as f:
writer = csv.writer(f)
for rt in r_list:
film = ( rt[0].strip(),rt[1].strip(),rt[2].strip() )
film_list.append(film)
writer.writerows(film_list)
# 主函数
def main(self):
# 用range函数可获取某些查询参数的值
for offset in range(0,41,10):
url = self.baseurl + str(offset)
self.get_page(url)
print('第%d页爬取成功' % self.page)
self.page += 1
time.sleep(1)
if __name__ == '__main__':
spider = MaoyanSpider()
spider.main()
62.图像量化
import numpy as np
import scipy.misc as sm
import scipy.ndimage as sn
import sklearn.cluster as sc
import matplotlib.pyplot as mp
# 通过K均值聚类量化图像中的颜色
def quant(image, n_clusters):
x = image.reshape(-1, 1)
model = sc.KMeans(n_clusters=n_clusters)
model.fit(x)
y = model.labels_
centers = model.cluster_centers_.ravel()
return centers[y].reshape(image.shape)
original = sm.imread('../data/lily.jpg', True)
quant4 = quant(original, 4)
quant3 = quant(original, 3)
quant2 = quant(original, 2)
mp.figure('Image Quant', facecolor='lightgray')
mp.subplot(221)
mp.title('Original', fontsize=16)
mp.axis('off')
mp.imshow(original, cmap='gray')
mp.subplot(222)
mp.title('Quant-4', fontsize=16)
mp.axis('off')
mp.imshow(quant4, cmap='gray')
mp.subplot(223)
mp.title('Quant-3', fontsize=16)
mp.axis('off')
mp.imshow(quant3, cmap='gray')
mp.subplot(224)
mp.title('Quant-2', fontsize=16)
mp.axis('off')
mp.imshow(quant2, cmap='gray')
mp.tight_layout()
mp.show()
63.kmeans
import numpy as np
import sklearn.cluster as sc
import matplotlib.pyplot as mp
x=np.loadtxt('multiple3.txt',delimiter=',')
model = sc.KMeans(n_clusters=6)
model.fit(x)
centers=model.cluster_centers_
n=500
l,r=x[:,0].min()-1,x[:,0].max()+1
b,t=x[:,1].min()-1,x[:,1].max()+1
grid_x=np.meshgrid(np.linspace(l,r,n),np.linspace(b,t,n))
flat_x=np.column_stack((grid_x[0].ravel(),grid_x[1].ravel()))
flat_y=model.predict(flat_x)
grid_y=flat_y.reshape(grid_x[0].shape)
pred_y=model.predict(x)
mp.figure('kmeans',facecolor='lightgray')
mp.title('Kmeans',fontsize=20)
mp.xlabel('x',fontsize=20)
mp.ylabel('y',fontsize=20)
mp.tick_params(labelsize=10)
mp.pcolormesh(grid_x[0],grid_x[1],grid_y,cmap='gray')
mp.scatter(x[:,0],x[:,1],c=pred_y,cmap='brg',s=80)
mp.scatter(centers[:,0],centers[:,1],marker='+',c='gold',s=1000,linewidth=1)
mp.show()
# 手撕
import numpy as np
import matplotlib.pyplot as plt
# 加载数据
def loadDataSet(fileName):
data = np.loadtxt(fileName,delimiter=',')
return data
# 欧氏距离计算
def distEclud(x,y):
return np.sqrt(np.sum((x-y)**2)) # 计算欧氏距离
# 为给定数据集构建一个包含K个随机质心的集合
def randCent(dataSet,k):
m,n = dataSet.shape
centroids = np.zeros((k,n))
for i in range(k):
index = int(np.random.uniform(0,m)) #
centroids[i,:] = dataSet[index,:]
return centroids
# k均值聚类
def KMeans(dataSet,k):
m = np.shape(dataSet)[0] #行的数目
# 第一列存样本属于哪一簇
# 第二列存样本的到簇的中心点的误差
clusterAssment = np.mat(np.zeros((m,2)))
clusterChange = True
# 第1步 初始化centroids
centroids = randCent(dataSet,k)
while clusterChange:
clusterChange = False
# 遍历所有的样本(行数)
for i in range(m):
minDist = 100000.0
minIndex = -1
# 遍历所有的质心
#第2步 找出最近的质心
for j in range(k):
# 计算该样本到质心的欧式距离
distance = distEclud(centroids[j,:],dataSet[i,:])
if distance < minDist:
minDist = distance
minIndex = j
# 第 3 步:更新每一行样本所属的簇
if clusterAssment[i,0] != minIndex:
clusterChange = True
clusterAssment[i,:] = minIndex,minDist**2
#第 4 步:更新质心
for j in range(k):
pointsInCluster = dataSet[np.nonzero(clusterAssment[:,0].A == j)[0]] # 获取簇类所有的点
centroids[j,:] = np.mean(pointsInCluster,axis=0) # 对矩阵的行求均值
print("Congratulations,cluster complete!")
return centroids,clusterAssment
def showCluster(dataSet,k,centroids,clusterAssment):
m,n = dataSet.shape
if n != 2:
print("数据不是二维的")
return 1
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
if k > len(mark):
print("k值太大了")
return 1
# 绘制所有的样本
for i in range(m):
markIndex = int(clusterAssment[i,0])
plt.plot(dataSet[i,0],dataSet[i,1],mark[markIndex])
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
# 绘制质心
for i in range(k):
plt.plot(centroids[i,0],centroids[i,1],mark[i])
plt.show()
dataSet = loadDataSet("multiple3.txt")
k = 4
centroids,clusterAssment = KMeans(dataSet,k)
showCluster(dataSet,k,centroids,clusterAssment)
- mixup
import matplotlib.pyplot as plt
import matplotlib.image as Image
import cv2
im1 = Image.imread("cat1.jpg")
im1 = im1/255.
im2 = Image.imread("cat2.jpg")
im2 = im2/255.
lam= 4*0.1
im_mixup = (im1*lam+im2*(1-lam))
cv2.imwrite('mixup.jpg', im_mixup)
plt.imshow(im_mixup)
plt.show()
##way 2
#!/usr/bin/env python
#coding:utf-8
import cv2
import sys
import os
import random
import numpy as np
from PIL import Image
from io import BytesIO
import xml.etree.ElementTree as ET
from xml.etree.ElementTree import Element
def aHash(img):
# 均值哈希算法
# 缩放为8*8
img = cv2.resize(img, (8, 8))
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# s为像素和初值为0,hash_str为hash值初值为''
s = 0
hash_str = ''
# 遍历累加求像素和
for i in range(8):
for j in range(8):
s = s+gray[i, j]
# 求平均灰度
avg = s/64
# 灰度大于平均值为1相反为0生成图片的hash值
for i in range(8):
for j in range(8):
if gray[i, j] > avg:
hash_str = hash_str+'1'
else:
hash_str = hash_str+'0'
return hash_str
def dHash(img):
# 差值哈希算法
# 缩放8*8
img = cv2.resize(img, (9, 8))
# 转换灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
hash_str = ''
# 每行前一个像素大于后一个像素为1,相反为0,生成哈希
for i in range(8):
for j in range(8):
if gray[i, j] > gray[i, j+1]:
hash_str = hash_str+'1'
else:
hash_str = hash_str+'0'
return hash_str
def pHash(img):
# 感知哈希算法
# 缩放32*32
img = cv2.resize(img, (32, 32)) # , interpolation=cv2.INTER_CUBIC
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 将灰度图转为浮点型,再进行dct变换
dct = cv2.dct(np.float32(gray))
# opencv实现的掩码操作
dct_roi = dct[0:8, 0:8]
hash = []
avreage = np.mean(dct_roi)
for i in range(dct_roi.shape[0]):
for j in range(dct_roi.shape[1]):
if dct_roi[i, j] > avreage:
hash.append(1)
else:
hash.append(0)
return hash
def calculate(image1, image2):
# 灰度直方图算法
# 计算单通道的直方图的相似值
hist1 = cv2.calcHist([image1], [0], None, [256], [0.0, 255.0])
hist2 = cv2.calcHist([image2], [0], None, [256], [0.0, 255.0])
# 计算直方图的重合度
degree = 0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree = degree + \
(1 - abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i]))
else:
degree = degree + 1
degree = degree / len(hist1)
return degree
def classify_hist_with_split(image1, image2, size=(256, 256)):
# RGB每个通道的直方图相似度
# 将图像resize后,分离为RGB三个通道,再计算每个通道的相似值
image1 = cv2.resize(image1, size)
image2 = cv2.resize(image2, size)
sub_image1 = cv2.split(image1)
sub_image2 = cv2.split(image2)
sub_data = 0
for im1, im2 in zip(sub_image1, sub_image2):
sub_data += calculate(im1, im2)
sub_data = sub_data / 3
return sub_data
def cmpHash(hash1, hash2):
# Hash值对比
# 算法中1和0顺序组合起来的即是图片的指纹hash。顺序不固定,但是比较的时候必须是相同的顺序。
# 对比两幅图的指纹,计算汉明距离,即两个64位的hash值有多少是不一样的,不同的位数越小,图片越相似
# 汉明距离:一组二进制数据变成另一组数据所需要的步骤,可以衡量两图的差异,汉明距离越小,则相似度越高。汉明距离为0,即两张图片完全一样
n = 0
# hash长度不同则返回-1代表传参出错
if len(hash1) != len(hash2):
return -1
# 遍历判断
for i in range(len(hash1)):
# 不相等则n计数+1,n最终为相似度
if hash1[i] != hash2[i]:
n = n + 1
return n
def getImageByUrl(url):
# 根据图片url 获取图片对象
html = requests.get(url, verify=False)
image = Image.open(BytesIO(html.content))
return image
def PILImageToCV():
# PIL Image转换成OpenCV格式
path = "/Users/waldenz/Documents/Work/doc/TestImages/t3.png"
img = Image.open(path)
plt.subplot(121)
plt.imshow(img)
print(isinstance(img, np.ndarray))
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
print(isinstance(img, np.ndarray))
plt.subplot(122)
plt.imshow(img)
plt.show()
def CVImageToPIL():
# OpenCV图片转换为PIL image
path = "/Users/waldenz/Documents/Work/doc/TestImages/t3.png"
img = cv2.imread(path)
# cv2.imshow("OpenCV",img)
plt.subplot(121)
plt.imshow(img)
img_b = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(122)
plt.imshow(img_b)
plt.show()
def bytes_to_cvimage(filebytes):
# 图片字节流转换为cv image
image = Image.open(filebytes)
img = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
return img
def runAllImageSimilaryFun(img_a, img_b):
# 均值、差值、感知哈希算法三种算法值越小,则越相似,相同图片值为0
# 三直方图算法和单通道的直方图 0-1之间,值越大,越相似。 相同图片为1
# t1,t2 14;19;10; 0.70;0.75
# t1,t3 39 33 18 0.58 0.49
# s1,s2 7 23 11 0.83 0.86 挺相似的图片
# c1,c2 11 29 17 0.30 0.31
# if para1.startswith("http"):
# # 根据链接下载图片,并转换为opencv格式
# img_a = getImageByUrl(para1)
# img_a = cv2.cvtColor(np.asarray(img_a), cv2.COLOR_RGB2BGR)
# img_b = getImageByUrl(para2)
# img_b = cv2.cvtColor(np.asarray(img_b), cv2.COLOR_RGB2BGR)
# else:
# # 通过imread方法直接读取物理路径
# img_a = cv2.imread(para1)
# img_b = cv2.imread(para2)
hash1 = aHash(img_a)
hash2 = aHash(img_b)
n1 = cmpHash(hash1, hash2)
n1 = 1-float(n1/64)
# print('均值哈希算法相似度aHash:', n1)
hash1 = dHash(img_a)
hash2 = dHash(img_b)
n2 = cmpHash(hash1, hash2)
n2 = 1 - float(n2/64)
# print('差值哈希算法相似度dHash:', n2)
hash1 = pHash(img_a)
hash2 = pHash(img_b)
n3 = cmpHash(hash1, hash2)
n3 = 1-float(n3/64)
# print('感知哈希算法相似度pHash:', n3)
# n4 = classify_hist_with_split(img_a, img_b)
# n4 = round(n4[0], 2)
# print('三直方图算法相似度:', n4)
# n5 = calculate(img_a, img_b)
# n5 = n5[0]
# print("单通道的直方图", n5)
# print("%d %d %d %.2f %.2f " % (n1, n2, n3, round(n4[0], 2), n5[0]))
# print("%.2f %.2f %.2f %.2f %.2f " % (1-float(n1/64), 1 -
# float(n2/64), 1-float(n3/64), round(n4[0], 2), n5[0]))
print(n1,n2,n3)
print(min(n1,n2,n3))
return min(n1,n2,n3)
# plt.subplot(121)
# plt.imshow(Image.fromarray(cv2.cvtColor(img_a, cv2.COLOR_BGR2RGB)))
# plt.subplot(122)
# plt.imshow(Image.fromarray(cv2.cvtColor(img_b, cv2.COLOR_BGR2RGB)))
# plt.show()
def prettyXml(element, indent, newline, level=0):
if element:
if element.text == None or element.text.isspace():
element.text = newline + indent * (level + 1)
else:
element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * (level + 1)
temp = list(element)
for subelement in temp:
if temp.index(subelement) < (len(temp) - 1):
subelement.tail = newline + indent * (level + 1)
else:
subelement.tail = newline + indent * level
prettyXml(subelement, indent, newline, level=level + 1)
def write_xml(box,name,pose, truncated, difficult, root,tree,outpath):
element = Element('object')
one1 = Element('bndbox')
two1 = Element('xmin')
two2 = Element('ymin')
two3 = Element('xmax')
two4 = Element('ymax')
two1.text = box[0]
two2.text = box[1]
two3.text = box[2]
two4.text = box[3]
name_node = Element('name')
name_node.text = name
name_node1 = Element('pose')
name_node1.text = pose
name_node2 = Element('truncated')
name_node2.text = truncated
name_node3 = Element('difficult')
name_node3.text = difficult
element.append(name_node)
element.append(name_node1)
element.append(name_node2)
element.append(name_node3)
one1.append(two1)
one1.append(two2)
one1.append(two3)
one1.append(two4)
element.append(one1)
root.append(element)
prettyXml(root, '\t', '\n')
print('save successful %s'%outpath)
tree.write(outpath, encoding='utf-8', xml_declaration=True)
def write_xml_simple(box,name,root,tree,outpath):
element = Element('object')
one1 = Element('bndbox')
name_node = Element('name')
two1 = Element('xmin')
two2 = Element('ymin')
two3 = Element('xmax')
two4 = Element('ymax')
two1.text = box[0]
two2.text = box[1]
two3.text = box[2]
two4.text = box[3]
name_node.text = name
print('------name--------',name)
element.append(name_node)
one1.append(two1)
one1.append(two2)
one1.append(two3)
one1.append(two4)
element.append(one1)
root.append(element)
print('-------bndbox-------',element)
prettyXml(root, '\t', '\n')
print('save successful %s'%outpath)
tree.write(outpath, encoding='utf-8', xml_declaration=True)
def mixup_with_xml(input_patha,input_pathb,xml_patha, xml_pathb,new_output_jpg, new_output_xml):
for a in os.listdir(input_patha):
name_a = os.path.split(a)[1][3:-4]
img_a = cv2.imread(os.path.join(input_patha,a))
root = ET.parse(os.path.join(xml_patha,a[:-4]+'.xml')).getroot()
num = 0
#for b in random.sample(os.listdir(input_pathb),400):
for b in os.listdir(input_pathb):
name_b = os.path.split(b)[1][3:-4]
# name_b = name_a + 1
img_b = cv2.imread(os.path.join(input_pathb,b))
# sim_jpg = []
# sim_jpg.append(runAllImageSimilaryFun(img_a,img_b))
if int(name_a)==int(name_b) + 1: #and runAllImageSimilaryFun(img_a,img_b) > 0.4:
num = num + 1
#print(runAllImageSimilaryFun(img_a,img_b))
canshu_a = 0.6
canshu_b = 0.6
# canshu_a = round(random.uniform(0.3,0.7),1)
# canshu_b = round(random.uniform(0.3,0.7),1)
# print('------a------',canshu_a,'\n------b------',canshu_b)
# if num < 5:
img_new = cv2.addWeighted(img_a, canshu_a, img_b, canshu_b, 0)
canshu_a = str(canshu_a)[-1]
canshu_b = str(canshu_b)[-1]
cv2.imwrite(os.path.join(new_output_jpg, name_a+'_'+str(canshu_a) +'_mixup3_' + str(canshu_b) + '_'+ name_b +'.jpg'),img_new)
xml_path_b = os.path.join(xml_pathb,b[:-4]+'.xml')
if os.path.exists(xml_path_b):
treeb = ET.parse(xml_path_b)
rootb = treeb.getroot()
for object in root.findall('object'):
box =[object.find('bndbox').find('xmin').text,
object.find('bndbox').find('ymin').text,
object.find('bndbox').find('xmax').text,
object.find('bndbox').find('ymax').text]
name = object.find('name').text
print('----box----name----',box,name)
write_xml_simple(box, name, rootb, treeb, os.path.join(new_output_xml, name_a+'_'+str(canshu_a) +'_mixup3_' + str(canshu_b) + '_'+ name_b +'.xml'))
if __name__ == "__main__":
input_pathb = "./JPEGImages"
input_patha = "./JPEGImages"
xml_pathb = "./Annotations"
xml_patha = "./Annotations"
new_output_jpg = './output_mixup_jpg'
new_output_xml = './output_mixup_xml'
if not os.path.exists(new_output_jpg):
os.mkdir(new_output_jpg)
if not os.path.exists(new_output_xml):
os.mkdir(new_output_xml)
mixup_with_xml(input_patha,input_pathb,xml_patha, xml_pathb,new_output_jpg, new_output_xml)
- mosaic
import random
import cv2
import os
import glob
import numpy as np
from PIL import Image
from lxml import etree
# from ipdb import set_trace
OUTPUT_SIZE = (1024, 1024) # Height, Width
SCALE_RANGE = (0.5, 0.5)
FILTER_TINY_SCALE = 1 / 50
# voc格式的数据集,anno_dir是标注xml文件,img_dir是对应jpg图片
ANNO_DIR = 'JPEGImages'
IMG_DIR = 'Annotations'
# category_name = ['background', 'person']
def main():
img_paths, annos = get_dataset(ANNO_DIR, IMG_DIR)
print(img_paths, annos)
for i in range(1, 30, 1):
idxs = random.sample(range(len(annos)), 4) # 从annos列表长度中随机取4个数
# set_trace()
new_image, new_annos = update_image_and_anno(img_paths, annos,
idxs,
OUTPUT_SIZE, SCALE_RANGE,
filter_scale=FILTER_TINY_SCALE)
# 更新获取新图和对应anno
img_output_folder = "./img_mos/"
if not os.path.exists(img_output_folder):
os.mkdir(img_output_folder)
img_name = 'mosic_20220814_{}.jpg'.format(i)
img_path = img_output_folder + img_name
cv2.imwrite(img_path, new_image)
# annos是
result_list = []
for anno in new_annos:
start_point = (int(anno[1] * OUTPUT_SIZE[1]), int(anno[2] * OUTPUT_SIZE[0])) # 左上角点
end_point = (int(anno[3] * OUTPUT_SIZE[1]), int(anno[4] * OUTPUT_SIZE[0])) # 右下角点
result = [anno[0], 1, int(anno[1] * OUTPUT_SIZE[1]), int(anno[2] * OUTPUT_SIZE[0]), int(anno[3] * OUTPUT_SIZE[1]), int(anno[4] * OUTPUT_SIZE[0])]
result_list.append(result)
cv2.rectangle(new_image, start_point, end_point, (0, 255, 0), 1, cv2.LINE_AA) # 每循环一次在合成图画一个矩形
xml_output_folder = "./xml_mos/"
if not os.path.exists(xml_output_folder):
os.mkdir(xml_output_folder)
if (xml_output_folder is not None) and (os.path.exists(xml_output_folder)):
output_xml(result_list, img_name, new_image.shape, os.path.join(xml_output_folder, img_name.split('.')[0]+".xml"))
cv2.imwrite('wind_output_box.jpg', new_image)
new_image = cv2.cvtColor(new_image, cv2.COLOR_BGR2RGB)
new_image = Image.fromarray(new_image.astype(np.uint8))
i = i + 1
# new_image.show()
# cv2.imwrite('./img/wind_output111.jpg', new_image)
def update_image_and_anno(all_img_list, all_annos, idxs, output_size, scale_range, filter_scale=0.):
output_img = np.zeros([output_size[0], output_size[1], 3], dtype=np.uint8)
scale_x = scale_range[0] + random.random() * (scale_range[1] - scale_range[0])
scale_y = scale_range[0] + random.random() * (scale_range[1] - scale_range[0])
divid_point_x = int(scale_x * output_size[1])
divid_point_y = int(scale_y * output_size[0])
new_anno = []
for i, idx in enumerate(idxs):
# set_trace()
path = all_img_list[idx]
img_annos = all_annos[idx]
img = cv2.imread(path)
if i == 0: # top-left
img = cv2.resize(img, (divid_point_x, divid_point_y))
output_img[:divid_point_y, :divid_point_x, :] = img
for bbox in img_annos:
xmin = bbox[1] * scale_x
ymin = bbox[2] * scale_y
xmax = bbox[3] * scale_x
ymax = bbox[4] * scale_y
new_anno.append([bbox[0], xmin, ymin, xmax, ymax])
elif i == 1: # top-right
img = cv2.resize(img, (output_size[1] - divid_point_x, divid_point_y))
output_img[:divid_point_y, divid_point_x:output_size[1], :] = img
for bbox in img_annos:
xmin = scale_x + bbox[1] * (1 - scale_x)
ymin = bbox[2] * scale_y
xmax = scale_x + bbox[3] * (1 - scale_x)
ymax = bbox[4] * scale_y
new_anno.append([bbox[0], xmin, ymin, xmax, ymax])
elif i == 2: # bottom-left
img = cv2.resize(img, (divid_point_x, output_size[0] - divid_point_y))
output_img[divid_point_y:output_size[0], :divid_point_x, :] = img
for bbox in img_annos:
xmin = bbox[1] * scale_x
ymin = scale_y + bbox[2] * (1 - scale_y)
xmax = bbox[3] * scale_x
ymax = scale_y + bbox[4] * (1 - scale_y)
new_anno.append([bbox[0], xmin, ymin, xmax, ymax])
else: # bottom-right
img = cv2.resize(img, (output_size[1] - divid_point_x, output_size[0] - divid_point_y))
output_img[divid_point_y:output_size[0], divid_point_x:output_size[1], :] = img
for bbox in img_annos:
xmin = scale_x + bbox[1] * (1 - scale_x)
ymin = scale_y + bbox[2] * (1 - scale_y)
xmax = scale_x + bbox[3] * (1 - scale_x)
ymax = scale_y + bbox[4] * (1 - scale_y)
new_anno.append([bbox[0], xmin, ymin, xmax, ymax])
return output_img, new_anno
def get_dataset(anno_dir, img_dir):
# class_id = category_name.index('person')
img_paths = []
annos = []
# for anno_file in glob.glob(os.path.join(anno_dir, '*.txt')):
for anno_file in glob.glob(os.path.join(anno_dir, '*.xml')):
# print(anno_file)
anno_id = anno_file.split('/')[-1].split('.')[0]
#img_name = anno_id + '.jpg'
#anno_id = anno_file.split('\\')[-1].split('x')[0]
# set_trace()
# with open(anno_file, 'r') as f:
# num_of_objs = int(f.readline())
# set_trace()
img_path = os.path.join(img_dir, f'{anno_id}.jpg')
print(img_path)
img = cv2.imread(img_path)
# set_trace()
img_height, img_width, _ = img.shape
del img
boxes = []
bnd_box = parseXmlFiles(anno_file)
#print(bnd_box)
for bnd_id, box in enumerate(bnd_box):
# set_trace()
# result = (box[0], 1, box[1],box[2], box[3], box[4])
categories_id = box[0]
xmin = max(int(box[1]), 0) / img_width
ymin = max(int(box[2]), 0) / img_height
xmax = min(int(box[3]), img_width) / img_width
ymax = min(int(box[4]), img_height) / img_height
boxes.append([categories_id, xmin, ymin, xmax, ymax])
if not boxes:
continue
# result_list.append(result)
img_paths.append(img_path)
annos.append(boxes)
#print(result_list,6666666)
print("annos:所有对原图缩放后的坐标:", annos)
print(img_paths)
return img_paths, annos
def parseXmlFiles(anno_dir):
tree = etree.parse(anno_dir)
root = tree.getroot()
objectes = root.findall('.//object')
bnd_box = []
for object in objectes:
name = object.find("name").text
bndbox = object.find("bndbox")
xmin = float(bndbox.find("xmin").text)
xmax = float(bndbox.find("xmax").text)
ymin = float(bndbox.find("ymin").text)
ymax = float(bndbox.find("ymax").text)
# bnd_box.append([name, xmin, xmax, ymin, ymax])
bnd_box.append([name, xmin, ymin, xmax, ymax])
# print(len(bnd_box),bnd_box)
return bnd_box
def output_xml(result_list, src_img_name,img_shape, xml_path):
"""output result to xml
Args:
result_list (list): [ (code,score,xmin,ymin,xmax,ymax), ]
src_img_name (str): source image name.
img_shape(list): img_shape
xml_path: xml path
Returns:
None
"""
if 0 == len(result_list):
return None
xml_fmt = '''<annotation>
<folder>VOC2007</folder>
<filename>{:}</filename>
<size>
<width>{:d}</width>
<height>{:d}</height>
<depth>{:d}</depth>
</size>
<objectsum>{:d}</objectsum>
{:}</annotation>'''
object_fmt = '''<object>
<Serial>{:d}</Serial>
<name>{:}</name>
<bndbox>
<xmin>{:d}</xmin>
<ymin>{:d}</ymin>
<xmax>{:d}</xmax>
<ymax>{:d}</ymax>
</bndbox>
</object>'''
h,w,c = img_shape
objects_str = ""
for inx, res in enumerate(result_list):
item_str = object_fmt.format(
(inx + 1),
res[0],
int(res[2]),
int(res[3]),
int(res[4]),
int(res[5])
)
objects_str = objects_str + item_str
xml_str = xml_fmt.format(
src_img_name,
w,
h,
c,
len(result_list),
objects_str
)
with open(xml_path, "w") as outfile:
outfile.write(xml_str)
if __name__ == '__main__':
main()
import random
import cv2
import os
import glob
import numpy as np
from PIL import Image
from lxml import etree
import random
import requests
from io import BytesIO
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import xml.etree.ElementTree as ET
from xml.etree.ElementTree import Element
import gflags
import sys
def aHash(img):
# 均值哈希算法
# 缩放为8*8
img = cv2.resize(img, (8, 8))
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# s为像素和初值为0,hash_str为hash值初值为''
s = 0
hash_str = ''
# 遍历累加求像素和
for i in range(8):
for j in range(8):
s = s+gray[i, j]
# 求平均灰度
avg = s/64
# 灰度大于平均值为1相反为0生成图片的hash值
for i in range(8):
for j in range(8):
if gray[i, j] > avg:
hash_str = hash_str+'1'
else:
hash_str = hash_str+'0'
return hash_str
def dHash(img):
# 差值哈希算法
# 缩放8*8
img = cv2.resize(img, (9, 8))
# 转换灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
hash_str = ''
# 每行前一个像素大于后一个像素为1,相反为0,生成哈希
for i in range(8):
for j in range(8):
if gray[i, j] > gray[i, j+1]:
hash_str = hash_str+'1'
else:
hash_str = hash_str+'0'
return hash_str
def pHash(img):
# 感知哈希算法
# 缩放32*32
img = cv2.resize(img, (32, 32)) # , interpolation=cv2.INTER_CUBIC
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 将灰度图转为浮点型,再进行dct变换
dct = cv2.dct(np.float32(gray))
# opencv实现的掩码操作
dct_roi = dct[0:8, 0:8]
hash = []
avreage = np.mean(dct_roi)
for i in range(dct_roi.shape[0]):
for j in range(dct_roi.shape[1]):
if dct_roi[i, j] > avreage:
hash.append(1)
else:
hash.append(0)
return hash
def calculate(image1, image2):
# 灰度直方图算法
# 计算单通道的直方图的相似值
hist1 = cv2.calcHist([image1], [0], None, [256], [0.0, 255.0])
hist2 = cv2.calcHist([image2], [0], None, [256], [0.0, 255.0])
# 计算直方图的重合度
degree = 0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree = degree + \
(1 - abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i]))
else:
degree = degree + 1
degree = degree / len(hist1)
return degree
def classify_hist_with_split(image1, image2, size=(256, 256)):
# RGB每个通道的直方图相似度
# 将图像resize后,分离为RGB三个通道,再计算每个通道的相似值
image1 = cv2.resize(image1, size)
image2 = cv2.resize(image2, size)
sub_image1 = cv2.split(image1)
sub_image2 = cv2.split(image2)
sub_data = 0
for im1, im2 in zip(sub_image1, sub_image2):
sub_data += calculate(im1, im2)
sub_data = sub_data / 3
return sub_data
def cmpHash(hash1, hash2):
# Hash值对比
# 算法中1和0顺序组合起来的即是图片的指纹hash。顺序不固定,但是比较的时候必须是相同的顺序。
# 对比两幅图的指纹,计算汉明距离,即两个64位的hash值有多少是不一样的,不同的位数越小,图片越相似
# 汉明距离:一组二进制数据变成另一组数据所需要的步骤,可以衡量两图的差异,汉明距离越小,则相似度越高。汉明距离为0,即两张图片完全一样
n = 0
# hash长度不同则返回-1代表传参出错
if len(hash1) != len(hash2):
return -1
# 遍历判断
for i in range(len(hash1)):
# 不相等则n计数+1,n最终为相似度
if hash1[i] != hash2[i]:
n = n + 1
return n
def getImageByUrl(url):
# 根据图片url 获取图片对象
html = requests.get(url, verify=False)
image = Image.open(BytesIO(html.content))
return image
def PILImageToCV():
# PIL Image转换成OpenCV格式
path = "/Users/waldenz/Documents/Work/doc/TestImages/t3.png"
img = Image.open(path)
plt.subplot(121)
plt.imshow(img)
print(isinstance(img, np.ndarray))
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
print(isinstance(img, np.ndarray))
plt.subplot(122)
plt.imshow(img)
plt.show()
def CVImageToPIL():
# OpenCV图片转换为PIL image
path = "/Users/waldenz/Documents/Work/doc/TestImages/t3.png"
img = cv2.imread(path)
# cv2.imshow("OpenCV",img)
plt.subplot(121)
plt.imshow(img)
img_b = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(122)
plt.imshow(img_b)
plt.show()
def bytes_to_cvimage(filebytes):
# 图片字节流转换为cv image
image = Image.open(filebytes)
img = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
return img
def runAllImageSimilaryFun(img_a, img_b):
# 均值、差值、感知哈希算法三种算法值越小,则越相似,相同图片值为0
# 三直方图算法和单通道的直方图 0-1之间,值越大,越相似。 相同图片为1
# t1,t2 14;19;10; 0.70;0.75
# t1,t3 39 33 18 0.58 0.49
# s1,s2 7 23 11 0.83 0.86 挺相似的图片
# c1,c2 11 29 17 0.30 0.31
# if para1.startswith("http"):
# # 根据链接下载图片,并转换为opencv格式
# img_a = getImageByUrl(para1)
# img_a = cv2.cvtColor(np.asarray(img_a), cv2.COLOR_RGB2BGR)
# img_b = getImageByUrl(para2)
# img_b = cv2.cvtColor(np.asarray(img_b), cv2.COLOR_RGB2BGR)
# else:
# # 通过imread方法直接读取物理路径
# img_a = cv2.imread(para1)
# img_b = cv2.imread(para2)
hash1 = aHash(img_a)
hash2 = aHash(img_b)
n1 = cmpHash(hash1, hash2)
n1 = 1-float(n1/64)
# print('均值哈希算法相似度aHash:', n1)
hash1 = dHash(img_a)
hash2 = dHash(img_b)
n2 = cmpHash(hash1, hash2)
n2 = 1 - float(n2/64)
# print('差值哈希算法相似度dHash:', n2)
hash1 = pHash(img_a)
hash2 = pHash(img_b)
n3 = cmpHash(hash1, hash2)
n3 = 1-float(n3/64)
# print('感知哈希算法相似度pHash:', n3)
n4 = classify_hist_with_split(img_a, img_b)
n4 = round(n4[0], 2)
# print('三直方图算法相似度:', n4)
n5 = calculate(img_a, img_b)
n5 = n5[0]
# print("单通道的直方图", n5)
# print("%d %d %d %.2f %.2f " % (n1, n2, n3, round(n4[0], 2), n5[0]))
# print("%.2f %.2f %.2f %.2f %.2f " % (1-float(n1/64), 1 -
# float(n2/64), 1-float(n3/64), round(n4[0], 2), n5[0]))
print(n1,n2,n3,n4,n5)
print(min(n1,n2,n3,n4,n5))
return min(n1,n2,n3,n4,n5)
OUTPUT_SIZE = (600, 600) # Height, Width
SCALE_RANGE = (0.5, 0.5)
FILTER_TINY_SCALE = 1 / 50 # if height or width lower than this scale, drop it.
# voc格式的数据集,anno_dir是标注xml文件,img_dir是对应jpg图片
ANNO_DIR = 'Annotations'
IMG_DIR = 'JPEGImages'
# category_name = ['background', 'person']
def main():
img_paths, annos = get_dataset(ANNO_DIR, IMG_DIR)
print(img_paths, annos,66666666666666666666666666666666666666666666)
for i in range(1, 1600, 1):
idxs = random.sample(range(len(annos)), 4) # 从annos列表长度中随机取4个数
# print(idxs,111111111111)
# set_trace()
# idxs = [i for i in annos]
new_image, new_annos = update_image_and_anno(img_paths, annos,
idxs,
OUTPUT_SIZE, SCALE_RANGE,
filter_scale=FILTER_TINY_SCALE)
# 更新获取新图和对应anno
img_output_folder = "./augment_1207/mosic_jpg/"
if not os.path.exists(img_output_folder):
os.mkdir(img_output_folder)
img_name = '{}.jpg'.format(str(idxs[0])+'_'+str(idxs[1])+'_'+str(idxs[2])+'_'+str(idxs[3]))
img_path = img_output_folder + img_name
cv2.imwrite(img_path, new_image)
# annos是
result_list = []
for anno in new_annos:
start_point = (int(anno[1] * OUTPUT_SIZE[1]), int(anno[2] * OUTPUT_SIZE[0])) # 左上角点
end_point = (int(anno[3] * OUTPUT_SIZE[1]), int(anno[4] * OUTPUT_SIZE[0])) # 右下角点
result = [anno[0], 1, int(anno[1] * OUTPUT_SIZE[1]), int(anno[2] * OUTPUT_SIZE[0]), int(anno[3] * OUTPUT_SIZE[1]), int(anno[4] * OUTPUT_SIZE[0])]
result_list.append(result)
cv2.rectangle(new_image, start_point, end_point, (0, 255, 0), 1, cv2.LINE_AA) # 每循环一次在合成图画一个矩形
xml_output_folder = "./augment_1207/mosic_xml/"
if not os.path.exists(xml_output_folder):
os.mkdir(xml_output_folder)
if (xml_output_folder is not None) and (os.path.exists(xml_output_folder)):
output_xml(result_list, img_name, new_image.shape, os.path.join(xml_output_folder, img_name.split('.')[0]+".xml"))
cv2.imwrite('wind_output_box.jpg', new_image)
new_image = cv2.cvtColor(new_image, cv2.COLOR_BGR2RGB)
new_image = Image.fromarray(new_image.astype(np.uint8))
i = i + 1
# new_image.show()
# cv2.imwrite('./img/wind_output111.jpg', new_image)
def update_image_and_anno(all_img_list, all_annos, idxs, output_size, scale_range, filter_scale=0.):
output_img = np.zeros([output_size[0], output_size[1], 3], dtype=np.uint8)
scale_x = scale_range[0] + random.random() * (scale_range[1] - scale_range[0])
scale_y = scale_range[0] + random.random() * (scale_range[1] - scale_range[0])
divid_point_x = int(scale_x * output_size[1])
divid_point_y = int(scale_y * output_size[0])
new_anno = []
for i, idx in enumerate(idxs):
# set_trace()
path = all_img_list[idx]
img_annos = all_annos[idx]
img = cv2.imread(path)
if i == 0: # top-left
img = cv2.resize(img, (divid_point_x, divid_point_y))
output_img[:divid_point_y, :divid_point_x, :] = img
for bbox in img_annos:
xmin = bbox[1] * scale_x
ymin = bbox[2] * scale_y
xmax = bbox[3] * scale_x
ymax = bbox[4] * scale_y
new_anno.append([bbox[0], xmin, ymin, xmax, ymax])
elif i == 1: # top-right
img = cv2.resize(img, (output_size[1] - divid_point_x, divid_point_y))
output_img[:divid_point_y, divid_point_x:output_size[1], :] = img
for bbox in img_annos:
xmin = scale_x + bbox[1] * (1 - scale_x)
ymin = bbox[2] * scale_y
xmax = scale_x + bbox[3] * (1 - scale_x)
ymax = bbox[4] * scale_y
new_anno.append([bbox[0], xmin, ymin, xmax, ymax])
elif i == 2: # bottom-left
img = cv2.resize(img, (divid_point_x, output_size[0] - divid_point_y))
output_img[divid_point_y:output_size[0], :divid_point_x, :] = img
for bbox in img_annos:
xmin = bbox[1] * scale_x
ymin = scale_y + bbox[2] * (1 - scale_y)
xmax = bbox[3] * scale_x
ymax = scale_y + bbox[4] * (1 - scale_y)
new_anno.append([bbox[0], xmin, ymin, xmax, ymax])
else: # bottom-right
img = cv2.resize(img, (output_size[1] - divid_point_x, output_size[0] - divid_point_y))
output_img[divid_point_y:output_size[0], divid_point_x:output_size[1], :] = img
for bbox in img_annos:
xmin = scale_x + bbox[1] * (1 - scale_x)
ymin = scale_y + bbox[2] * (1 - scale_y)
xmax = scale_x + bbox[3] * (1 - scale_x)
ymax = scale_y + bbox[4] * (1 - scale_y)
new_anno.append([bbox[0], xmin, ymin, xmax, ymax])
return output_img, new_anno
def get_dataset(anno_dir, img_dir):
# class_id = category_name.index('person')
img_paths = []
annos = []
# for anno_file in glob.glob(os.path.join(anno_dir, '*.txt')):
for anno_file in glob.glob(os.path.join(anno_dir, '*.xml')):
# print(anno_file)
anno_id = anno_file.split('/')[-1].split('.')[0]
#img_name = anno_id + '.jpg'
#anno_id = anno_file.split('\\')[-1].split('x')[0]
# set_trace()
# with open(anno_file, 'r') as f:
# num_of_objs = int(f.readline())
# set_trace()
img_path = os.path.join(img_dir, f'{anno_id}.jpg')
print(img_path)
img = cv2.imread(img_path)
# set_trace()
img_height, img_width, _ = img.shape
del img
boxes = []
bnd_box = parseXmlFiles(anno_file)
#print(bnd_box)
for bnd_id, box in enumerate(bnd_box):
# set_trace()
# result = (box[0], 1, box[1],box[2], box[3], box[4])
categories_id = box[0]
xmin = max(int(box[1]), 0) / img_width
ymin = max(int(box[2]), 0) / img_height
xmax = min(int(box[3]), img_width) / img_width
ymax = min(int(box[4]), img_height) / img_height
boxes.append([categories_id, xmin, ymin, xmax, ymax])
if not boxes:
continue
# result_list.append(result)
img_paths.append(img_path)
annos.append(boxes)
#print(result_list,6666666)
print("annos:所有对原图缩放后的坐标:", annos)
print(img_paths)
return img_paths, annos
def prettyXml(element, indent, newline, level=0):
if element:
if element.text == None or element.text.isspace():
element.text = newline + indent * (level + 1)
else:
element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * (level + 1)
temp = list(element)
for subelement in temp:
if temp.index(subelement) < (len(temp) - 1):
subelement.tail = newline + indent * (level + 1)
else:
subelement.tail = newline + indent * level
prettyXml(subelement, indent, newline, level=level + 1)
def parseXmlFiles(anno_dir):
tree = etree.parse(anno_dir)
root = tree.getroot()
objectes = root.findall('.//object')
bnd_box = []
for object in objectes:
name = object.find("name").text
bndbox = object.find("bndbox")
xmin = float(bndbox.find("xmin").text)
xmax = float(bndbox.find("xmax").text)
ymin = float(bndbox.find("ymin").text)
ymax = float(bndbox.find("ymax").text)
# bnd_box.append([name, xmin, xmax, ymin, ymax])
bnd_box.append([name, xmin, ymin, xmax, ymax])
# print(len(bnd_box),bnd_box)
return bnd_box
def output_xml(result_list, src_img_name,img_shape, xml_path):
"""output result to xml
Args:
result_list (list): [ (code,score,xmin,ymin,xmax,ymax), ]
src_img_name (str): source image name.
img_shape(list): img_shape
xml_path: xml path
Returns:
None
"""
if 0 == len(result_list):
return None
xml_fmt = '''<annotation>
<folder>VOC2007</folder>
<filename>{:}</filename>
<size>
<width>{:d}</width>
<height>{:d}</height>
<depth>{:d}</depth>
</size>
<objectsum>{:d}</objectsum>
{:}</annotation>'''
object_fmt = '''<object>
<Serial>{:d}</Serial>
<name>{:}</name>
<bndbox>
<xmin>{:d}</xmin>
<ymin>{:d}</ymin>
<xmax>{:d}</xmax>
<ymax>{:d}</ymax>
</bndbox>
</object>'''
h,w,c = img_shape
objects_str = ""
for inx, res in enumerate(result_list):
item_str = object_fmt.format(
(inx + 1),
res[0],
int(res[2]),
int(res[3]),
int(res[4]),
int(res[5])
)
objects_str = objects_str + item_str
xml_str = xml_fmt.format(
src_img_name,
w,
h,
c,
len(result_list),
objects_str
)
with open(xml_path, "w") as outfile:
outfile.write(xml_str)
if __name__ == '__main__':
main()
















 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









