







一、Collection、List 新增的方法
Collection中新增的方法
- removeIf
- stream
- parallelStream
- spliterator
List中新增的方法
- replaceAll
- sort
1.1、removeIf
default boolean removeIf(Predicate<? super E> filter)
- 删除容器中所有满足filter指定条件的元素
List<Integer> list = Lists.newArrayList(1, 2, 3, 4, 5, 6, 7, 8, 9);
// 删除列表中大于5的数
list.removeIf(item -> item > 5);
System.out.println(list.toString());
// [1, 2, 3, 4, 5]
1.2、replaceAll
default void replaceAll(UnaryOperator operator)
- 对List中每个元素执行operator指定的操作,并用操作后的结果来替换List中原来的元素
List<Integer> list = Arrays.asList(1, 2, 3, 4);
list.replaceAll(item -> item * 2);
list.forEach(System.out::println); // 2, 4, 6, 8
1.3、sort
default void sort(Comparator<? super E> c)
- 对List集合元素进行排序
List<Integer> list = Arrays.asList(1, 2, 3, 4);
list.sort(Comparator.comparingInt(o -> o)); // 正序
list.sort((o1, o2) -> o2 - o1); // 倒序
list.forEach(System.out::println);
1.4、spliterator
default Spliterator spliterator()
- 可分割的迭代器,不同以往的iterator需要顺序迭代,Spliterator可以分割为若干个小的迭代器进行并行操作,既可以实现多线程操作提高效率,又可以避免普通迭代器的fail-fast机制所带来的异常
List<Integer> list = Arrays.asList(1, 2, 3, 4);
Spliterator<Integer> spliterator = list.spliterator();
spliterator.forEachRemaining(System.out::println);
二、Map 新增的方法
- getOrDefault
- forEach
- putIfAbsent
- compute
- computeIfAbsent
- computeIfPresent
- merge
- remove(key, value)
- replace
- replaceAll
2.1、getOrDefault
default V getOrDefault(Object key, V defaultValue)
- 如果Map中不存在该key,可以提供一个默认值,方法会返回改默认值。如果存在该key,返回键对应的值。
Map<String, Integer> map = new HashMap<String, Integer>() {{
put("one", 1);
put("two", 2);
put("three", 3);
}};
Integer one = map.getOrDefault("one", 11111);
System.out.println("one = " + one); // 1
Integer value = map.getOrDefault("four", 44444);
System.out.println("value = " + value); // 44444
2.2、forEach
default void forEach(BiConsumer<? super K,? super V> action)
- forEach遍历map,对map中的value执行action指定的操作
Map<String, Integer> map = new HashMap<String, Integer>() {{
put("one", 1);
put("two", 2);
put("three", 3);
}};
// 将value都乘2
map.forEach((key, value) -> {
map.put(key, value * 2);
});
map.forEach((k, v) -> System.out.println(k + "---" + v));
//one---2
//two---4
//three---6
}
2.3、putIfAbsent
default V putIfAbsent(K key, V value)
- 判断指定的键(key)是否存在,如果存在就不插入, 不存在则将键/值对插入到 HashMap 中
- 返回值, 如果所指定的 key 已经在 HashMap 中存在,返回和这个 key 值对应的 value, 如果所指定的 key 不在 HashMap 中存在,则返回 null。
- 注意:如果指定 key 之前已经和一个 null 值相关联了 ,则该方法也返回 null。
// 创建一个 HashMap
HashMap<Integer, String> sites = new HashMap<>();
// 往 HashMap 添加一些元素
sites.put(1, "Google");
sites.put(2, "Runoob");
sites.put(3, "Taobao");
System.out.println("sites HashMap: " + sites);
// HashMap 不存在该key
sites.putIfAbsent(4, "Weibo");
// HashMap 中存在 Key
sites.putIfAbsent(2, "Wiki");
System.out.println("Updated Languages: " + sites);
//sites HashMap: {1=Google, 2=Runoob, 3=Taobao}
//Updated sites HashMap: {1=Google, 2=Runoob, 3=Taobao, 4=Weibo}
2.4、compute
default V compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
- 对 HashMap 中指定 key 的值进行重新计算
- 返回值: 如果 key 对应的 value 不存在,则返回该 null,如果存在,则返回通过 remappingFunction 重新计算后的值。
//创建一个 HashMap
HashMap<String, Integer> prices = new HashMap<>();
// 往HashMap中添加映射项
prices.put("Shoes", 200);
prices.put("Bag", 300);
prices.put("Pant", 150);
System.out.println("HashMap: " + prices);
// 重新计算鞋子价格, -50
int newPrice = prices.compute("Shoes", (s, integer) -> integer - 50);
System.out.println("Discounted Price of Shoes: " + newPrice);
// 输出更新后的HashMap
System.out.println("Updated HashMap: " + prices);
// HashMap: {Pant=150, Bag=300, Shoes=200}
// Discounted Price of Shoes: 150
// Updated HashMap: {Pant=150, Bag=300, Shoes=150}
2.5、computeIfAbsent
如果map中key不存在 或 key存在但value=null 的情况, 会重新进行计算
default V computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction)
- 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hashMap 中
- 注意: 如果对于存在的key(如果其value不为null), 直接返回value的值; 如果value为null, 则对存在key也进行重新计算,并设置给该key
// 创建一个 HashMap
HashMap<String, Integer> prices = new HashMap<>();
// 往HashMap中添加映射项
prices.put("Shoes", 200);
prices.put("Bag", 300);
prices.put("Pant", 150);
System.out.println("HashMap: " + prices);
// 计算 Shirt 的值
int shirtPrice = prices.computeIfAbsent("Shirt", s -> 200);
System.out.println("Price of Shirt: " + shirtPrice);
// 输出更新后的HashMap
System.out.println("Updated HashMap: " + prices);
/*
// 上面的key不存在的情况,将不存在的key,以及value存到map
// 如果key以及在map中存在,直接返回key的value,不进行计算了
HashMap: {Pant=150, Bag=300, Shoes=200}
Price of Shirt: 280
Updated HashMap: {Pant=150, Shirt=280, Bag=300, Shoes=200}
*/
2.6、computeIfPresent
只对map中存在的key, 进行计算, 并添加到map
default V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
- 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中
- 返回值: 如果 key 对应的 value 不存在,则返回该 null,如果存在,则返回通过 remappingFunction 重新计算后的值。
// 创建一个 HashMap
HashMap<String, Integer> prices = new HashMap<>();
// 往HashMap中添加映射项
prices.put("Shoes", 200);
prices.put("Bag", 300);
prices.put("Pant", 150);
System.out.println("HashMap: " + prices);
// 对于ABC不存的key,不会计算,也不会添加到HashMap中
// Integer abc = prices.computeIfPresent("ABC", (s, integer) -> integer * 2);
// System.out.println("abc = " + abc); // null
// System.out.println("HashMap: " + prices); // HashMap: {Pant=150, Bag=300, Shoes=200}
Integer shoesNewPrice = prices.computeIfPresent("Shoes", (key, value) -> value * 2);
System.out.println("shoesNewPrice = " + shoesNewPrice); // 400
System.out.println("HashMap: " + prices); //HashMap: {Pant=150, Bag=300, Shoes=400}
2.7、merge
default V merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction)
- 先判断map中指定的 key 是否存在,如果不存在,则添加键值对到 hashMap 中
- 返回值: 如果 key 对应的 value 不存在,则返回该 value 值,如果存在,则返回通过 remappingFunction 重新计算后的值。
参考: https://www.runoob.com/java/java-hashmap-merge.html
2.8、remove(key, value)
default boolean remove(Object key, Object value)
- 只有在当前Map中key映射的值等于value时才删除该映射,否则什么也不做。
Map<String, Integer> map = new HashMap<String, Integer>() {{
put("one", 1);
put("two", 2);
}};
boolean one = map.remove("one", 111);
System.out.println("one = " + one); // false
boolean one1 = map.remove("one", 1);
System.out.println("one1 = " + one1); // true
2.9、replace、replaceAll
- default V replace(K key, V value)
- 当map中存在该key的时候,才替换value
- default boolean replace(K key, V oldValue, V newValue)
- 当map中存在该key且映射的值等于oldValue时, 才替换成newValue
- default void replaceAll(BiFunction<? super K,? super V,? extends V> function)
- 对map中的每个映射执行function指定的操作,并用function的执行结果替换原来的value
Map<String, Integer> map = new HashMap<String, Integer>() {{
put("one", 1);
put("two", 2);
}};
System.out.println(map); // {one=1, two=2}
map.replaceAll((s, integer) -> integer * 2);
System.out.println(map); // {one=2, two=4}
三、Collectors 收集方法
toCollection
toList()
toSet()
toMap
joining
mapping/flatMapping
filtering
counting
minBy/maxBy
summingInt/summingLong/summingDouble
averagingInt/averagingLong/averagingDouble
groupingBy
groupingByConcurrent
partitioningBy
BinaryOperator
summarizingInt
toCollection
此函数返回一个收集器,它将输入元素累积到一个集合中。
List<String> strList = Arrays.asList("a", "b", "c", "b", "a");
// toCollection()
Collection<String> strCollection = strList.parallelStream().collect(Collectors.toCollection(HashSet::new));
System.out.println(strCollection); // [a, b, c]
Set<String> strSet = strList.parallelStream().collect(Collectors.toCollection(HashSet::new));
System.out.println(strSet); // [a, b, c]
List<String> strList1 = strList.parallelStream().sorted(String::compareToIgnoreCase)
.collect(Collectors.toCollection(ArrayList::new));
System.out.println(strList1); // [a, a, b, b, c]
toList、toSet
返回一个收集器,它将输入元素累积到一个新的List/Set中
List<String> strList = Arrays.asList("a", "b", "c", "b", "a");
List<String> uppercaseList = strList.parallelStream().map(String::toUpperCase).collect(Collectors.toList());
System.out.println(uppercaseList); // [A, B, C, B, A]
Set<String> collect = strList.parallelStream().map(String::toUpperCase).collect(Collectors.toSet());
System.out.println("collect = " + collect); // [A, B, C]
toMap
- keyMapper - 用于生成键的映射函数
- valueMapper - 生成值的映射函数
- mergeFunction - 一个合并函数,用于解决提供给映射的与同一键关联的值之间的冲突。合并(对象、对象、双函数)
- mapFactory - 指定返回的Map类型,并将entry插入到该map种
- public static <T,K,U> Collector<T,?,Map<K,U>> toMap(Function<? super T,? extends K> keyMapper, Function<? super T,? extends U> valueMapper) 两个参数的toMap
- public static <T,K,U> Collector<T,?,Map<K,U>> toMap(Function<? super T,? extends K> keyMapper, Function<? super T,? extends U> valueMapper, BinaryOperator<> mergeFunction) 三个参数的
- public static <T,K,U,M extends Map<K,U>> Collector<T,?,M> toMap(Function<? super T,? extends K> keyMapper, Function<? super T,? extends U> valueMapper, BinaryOperator mergeFunction, Supplier<> mapFactory) 四个参数的
List<String> strList = Arrays.asList("a", "b", "c");
Map<String, String> map = strList.stream().collect(Collectors.toMap(Function.identity(), new Function<String, String>() {
@Override
public String apply(String s) {
// 设置value
return s.toUpperCase() + ":gzy";
}
}));
System.out.println("map = " + map); // map = {a=A:gzy, b=B:gzy, c=C:gzy}
}
// -----------------------
List<String> strList2 = Arrays.asList("a", "b", "c", "a", "b", "a");
Map<String, String> map2 = strList2.stream().collect(Collectors.toMap(Function.identity(), String::toUpperCase, new BinaryOperator<String>() {
@Override
public String apply(String s1, String s2) {
return s1 + "_" + s2;
}
}));
// 第三个参数是为了解决,相同key的问题,通过指定规则来合并
System.out.println("map2 = " + map2); // map2 = {a=A_A_A, b=B_B, c=C}
// -----------------------
List<String> strList3 = Arrays.asList("a", "b", "c", "a", "b", "a");
TreeMap<String, String> treeMap = strList3.stream().collect(Collectors.toMap(Function.identity(), String::toUpperCase, new BinaryOperator<String>() {
@Override
public String apply(String s1, String s2) {
return s1 + "_" + s2;
}
}, new Supplier<TreeMap<String, String>>() {
@Override
public TreeMap<String, String> get() {
return new TreeMap<>();
}
}));
System.out.println("treeMap = " + treeMap); // treeMap = {a=A_A_A, b=B_B, c=C}
joining
用于连接字符串
List<String> strList = Arrays.asList("a", "b", "c");
// 等同 String collect = String.join("", strList)
String collect = strList.stream().collect(Collectors.joining());
System.out.println("collect = " + collect); // abc
// String collect1 = String.join("-", strList);
String collect1 = strList.stream().collect(Collectors.joining("-"));
System.out.println("collect1 = " + collect1);
// 在拼接后的字符,之前和之后加上前缀后缀
String collect2 = strList.stream().collect(Collectors.joining("-", "0", "9"));
System.out.println("collect2 = " + collect2);
/*
collect = abc
collect1 = a-b-c
collect2 = 0a-b-c9
*/
mapping/flatMapping
它将Function应用于输入元素,然后将它们累积到给定的Collector
Set<String> setStr = Stream.of("a", "a", "b")
.collect(Collectors.mapping(String::toUpperCase, Collectors.toSet()));
System.out.println(setStr); // [A, B]
Set<String> setStr1 = Stream.of("a", "a", "b")
.collect(Collectors.flatMapping(s -> Stream.of(s.toUpperCase()), Collectors.toSet()));
System.out.println(setStr1); // [A, B]
filtering
设置过滤条件
List<String> strList2 = Lists.newArrayList("1", "2", "10", "100", "20", "999");
Set<String> set = strList2.parallelStream()
.collect(Collectors.filtering(s -> s.length() < 2, Collectors.toSet()));
System.out.println(set); // [1, 2]
counting
计数
Long evenCount = Stream.of(1, 2, 3, 4, 5).filter(x -> x % 2 == 0).collect(Collectors.counting());
System.out.println(evenCount); // 2
minBy/maxBy
最小值/最大值
Optional<Integer> min = Stream.of(1, 2, 3, 4, 5).collect(Collectors.minBy((x, y) -> x - y));
System.out.println(min); // Optional[1]
Optional<Integer> max = Stream.of(1, 2, 3, 4, 5).collect(Collectors.maxBy((x, y) -> x - y));
System.out.println(max); // Optional[5]
summingInt/summingLong/summingDouble
求总和
List<String> strList3 = Arrays.asList("1", "2", "3", "4", "5");
Integer sum = strList3.parallelStream().collect(Collectors.summingInt(Integer::parseInt));
System.out.println(sum); // 15
Long sumL = Stream.of("12", "23").collect(Collectors.summingLong(Long::parseLong));
System.out.println(sumL); // 35
Double sumD = Stream.of("1e2", "2e3").collect(Collectors.summingDouble(Double::parseDouble));
System.out.println(sumD); // 2100.0
averagingInt/averagingLong/averagingDouble
求平均值
List<String> strList4 = Arrays.asList("1", "2", "3", "4", "5");
Double average = strList4.parallelStream().collect(Collectors.averagingInt(Integer::parseInt));
System.out.println(average); // 3.0
Double averageL = Stream.of("12", "23").collect(Collectors.averagingLong(Long::parseLong));
System.out.println(averageL); // 17.5
Double averageD = Stream.of("1e2", "2e3").collect(Collectors.averagingDouble(Double::parseDouble));
System.out.println(averageD); // 1050.0
groupingBy
当我们使用 Stream 流处理数据后,可以根据某个属性来将数据进行分组。
Map<Integer, List<Integer>> mapGroupBy = Stream.of(1, 2, 3, 4, 5, 4, 3).collect(Collectors.groupingBy(x -> x * 10));
System.out.println(mapGroupBy); // {50=[5], 20=[2], 40=[4, 4], 10=[1], 30=[3, 3]}
/**
* Stream流数据--分组操作
* 备注:切记Stream流只能被消费一次,流就失效了
*/
public class CollectDataToArray{
public static void main(String[] args) {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 56),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 53)
);
//1.按照具体年龄分组
Map<Integer, List<Student>> map = studentStream.collect(Collectors.groupingBy((s -> s.getAge())));
map.forEach((key,value)->{
System.out.println(key + "---->"+value);
});
//2.按照分数>=60 分为"及格"一组 <60 分为"不及格"一组
Map<String, List<Student>> map = studentStream.collect(Collectors.groupingBy(s -> {
if (s.getScore() >= 60) {
return "及格";
} else {
return "不及格";
}
}));
map.forEach((key,value)->{
System.out.println(key + "---->"+value.get());
});
//3.按照年龄分组,规约求每组的最大值最小值(规约:reducing)
Map<Integer, Optional<Student>> reducingMap = studentStream.collect(
Collectors.groupingBy(Student::getAge,
Collectors.reducing(
BinaryOperator.maxBy(
Comparator.comparingInt(Student::getScore)
)
)
)
);
reducingMap .forEach((key,value)->{
System.out.println(key + "---->"+value);
});
}
}
52---->[Student{name='赵丽颖', age=52, score=56}, Student{name='柳岩', age=52, score=53}]
56---->[Student{name='杨颖', age=56, score=88}, Student{name='迪丽热巴', age=56, score=99}]
-----------------------------------------------------------------------------------------------
不及格---->[Student{name='赵丽颖', age=52, score=56}, Student{name='柳岩', age=52, score=53}]
及格---->[Student{name='杨颖', age=56, score=88}, Student{name='迪丽热巴', age=56, score=99}]
-----------------------------------------------------------------------------------------------
52---->Student{name='赵丽颖', age=52, score=95}
56---->Student{name='杨颖', age=56, score=88}
多级分组
/**
* Stream流数据--多级分组操作
* 备注:切记Stream流只能被消费一次,流就失效了
*/
public class CollectDataToArray{
public static void main(String[] args) {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33)
);
//多级分组
//1.先根据年龄分组,然后再根据成绩分组
//分析:第一个Collectors.groupingBy() 使用的是(年龄+成绩)两个维度分组,所以使用两个参数 groupingBy()方法
// 第二个Collectors.groupingBy() 就是用成绩分组,使用一个参数 groupingBy() 方法
Map<Integer, Map<Integer, Map<String, List<Student>>>> map = studentStream.collect(Collectors.groupingBy(str -> str.getAge(), Collectors.groupingBy(str -> str.getScore(), Collectors.groupingBy((student) -> {
if (student.getScore() >= 60) {
return "及格";
} else {
return "不及格";
}
}))));
map.forEach((key,value)->{
System.out.println("年龄:" + key);
value.forEach((k2,v2)->{
System.out.println("\t" + v2);
});
});
}
}
年龄:52
{不及格=[Student{name='柳岩', age=52, score=33}]}
{及格=[Student{name='赵丽颖', age=52, score=95}]}
年龄:56
{不及格=[Student{name='迪丽热巴', age=56, score=55}]}
{及格=[Student{name='杨颖', age=56, score=88}]}
groupingByConcurrent
分组,是并发和无序的
Map<Integer, List<Integer>> mapGroupBy = Stream.of(1, 2, 3, 4, 5, 4, 3).collect(Collectors.groupingByConcurrent(x -> x * 10));
System.out.println(mapGroupBy); // {50=[5], 20=[2], 40=[4, 4], 10=[1], 30=[3, 3]}
partitioningBy
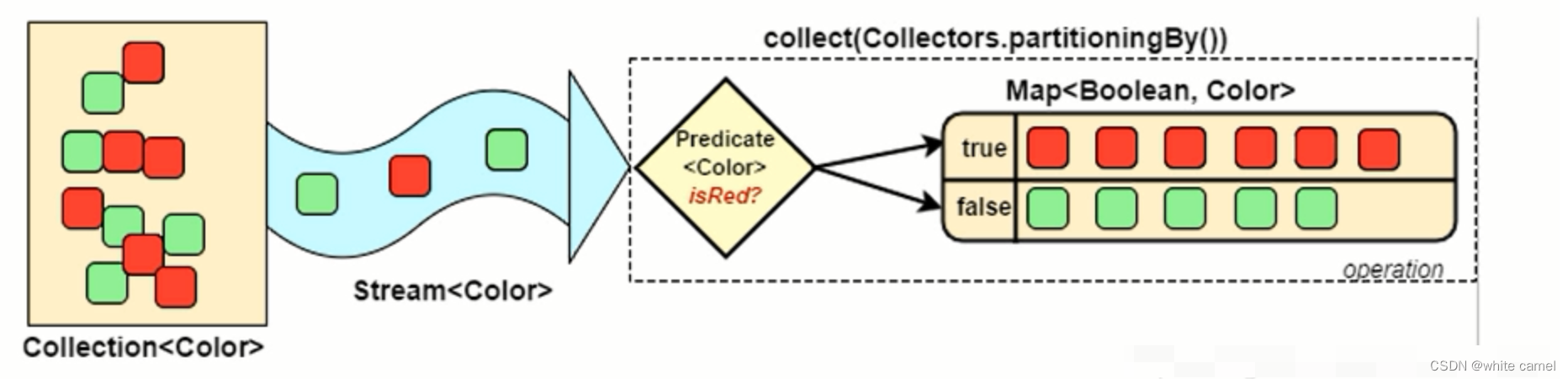
返回一个Collector,它根据Predicate对输入元素进行分区,并将它们组织成Map <Boolean,List >。
分组和分区的区别就在:分组可以有多个组。分区只会有两个区( true 和 false)
Map<Boolean, List<Integer>> mapPartitionBy = Stream.of(1, 2, 3, 4, 5, 4, 3).collect(Collectors.partitioningBy(x -> x % 2 == 0));
System.out.println(mapPartitionBy); // {false=[1, 3, 5, 3], true=[2, 4, 4]}
BinaryOperator
返回一个收集器,它在指定的BinaryOperator下执行其输入元素的减少。这主要用于多级缩减,例如使用groupingBy()和partitioningBy()方法指定下游收集器
Map<Boolean, Optional<Integer>> reducing = Stream.of(1, 2, 3, 4, 5, 4, 3).collect(Collectors.partitioningBy(
x -> x % 2 == 0, Collectors.reducing(BinaryOperator.maxBy(Comparator.comparing(Integer::intValue)))));
System.out.println(reducing); // {false=Optional[5], true=Optional[4]}
summarizingInt
返回统计数据:min, max, average, count, sum
IntSummaryStatistics summarizingInt = Stream.of("12", "23", "35")
.collect(Collectors.summarizingInt(Integer::parseInt));
System.out.println(summarizingInt);
//IntSummaryStatistics{count=3, sum=70, min=12, average=23.333333, max=35}
















 3299
3299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











