







网络深度是影响深度卷积神经网络性能的一大因素,但是研究者发现当网络不断加深时,训练的结果并不好。这不是因为过拟合,因为过拟合的话应该是训练集上结果好,测试集不好,但深度网络出现的现象是训练集上的效果就不好。而且这种现象还会随着深度加深而变差。这并不符合逻辑,因为深层网络在训练时,可以是在浅层网络的函数上加上一个恒等变换。而深层网络显然没有把这种恒等变换学习到。因此,提出了Resnet。
网络结构是有好多个block组成,每个block的构成如下图,加入了一个shortcut connections 从函数上来看就是加入了一个恒等变换。
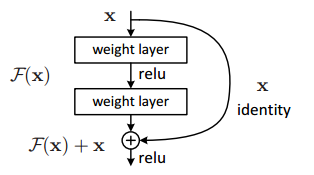
从正向传播上来看,引入恒等变换可以使网络参数调整作用更大。这个地方引用下知乎上一个特别好的回答(http://www.jianshu.com/p/e58437f39f65)
“F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F’(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F’的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器”
这位朋友的回答我觉得很形象。
那么什么是更敏感,我觉得从反向传播上来看就是“梯度消失现象得以解决”。梯度是用来更新权值参数以使网络拟合的更好的,用误差项来求得,而误差项表征的其实就是对网络损失值的敏感程度(我是这么理解的)。所以说,加入了一个short connections 从反向传播上,给误差项来了一个直接向前面层的传播并相加,缓解了梯度的减小问题。从而解决了梯度消失。
在统计和最优参数选取时,统计误差以及残差是两个紧密相关,但同时又极易混淆的概念.两者都是对"样本值偏离均值"的测量. 样本误差是指样本对母本(无法观察到的)均值及真实值的均值的偏离. 残差则是指样本和观察值(样本总体)或回归值(拟合)的差额. 拟合值是统计模型的拟合结果,是依据拟合模型得出的,应该是的值; 误差和残差的差异distinction在回归中尤其重要, 精细的残差即通常所说的学生化残差…(后一句不理解)
简单理解为:
误差:即观测值与真实值的偏离;
残差:观测值与拟合值的偏离.
误差与残差,这两个概念在某程度上具有很大的相似性,都是衡量不确定性的指标,可是两者又存在区别。 误差与测量有关,误差大小可以衡量测量的准确性,误差越大则表示测量越不准确。
误差分为两类:系统误差与随机误差。其中,系统误差与测量方案有关,通过改进测量方案可以避免系统误差。随机误差与观测者,测量工具,被观测物体的性质有关,只能尽量减小,却不能避免。
残差――与预测有关,残差大小可以衡量预测的准确性。残差越大表示预测越不准确。残差与数据本身的分布特性,回归方程的选择有关。
误差: 所有不同样本集的均值的均值,与真实总体均值的偏离.由于真实总体均值通常无法获取或观测到,因此通常是假设总体为某一分布类型,则有N个估算的均值; 表征的是观测/测量的精确度;
误差大,由异常值引起.表明数据可能有严重的测量错误;或者所选模型不合适,;
残差: 某样本的均值与所有样本集均值的均值, 的偏离; 表征取样的合理性,即该样本是否具代表意义;
残差大,表明样本不具代表性,也有可能由特征值引起.
反正要看一个模型是否合适,看误差;要看所取样本是否合适,看残差;
作者:jyli2_11
来源:CSDN
原文:https://blog.csdn.net/jyli2_11/article/details/76098361














 4095
4095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









