







 本文探讨了在关系抽取任务中应用对抗训练,通过在CNN和RNN模型上引入对抗噪声,增强了模型在多实例多标签场景下的表现。实验在NYT和UW数据集上取得了良好效果,表明对抗训练能有效提高模型的鲁棒性,特别是在RNN模型中更为显著。
本文探讨了在关系抽取任务中应用对抗训练,通过在CNN和RNN模型上引入对抗噪声,增强了模型在多实例多标签场景下的表现。实验在NYT和UW数据集上取得了良好效果,表明对抗训练能有效提高模型的鲁棒性,特别是在RNN模型中更为显著。
Adversarial Training for Relation Extraction
Abstract
对抗训练是一种在训练过程中加入噪声的正则分类算法。这篇论文在多实例多标签的关系抽取任务中加入对抗噪声来提升模型表现。通过在CNN和RNN两种主流框架上进行对抗训练,在两种不同的数据集上都去得了不错的效果。
Methodology
在多实例多标签的关系抽取任务中,X={x1,x2,. . .,xn} 代表这些句子都包含一个相同的实体对。而我们任务就是给该实体对找到一个合适的关系类型:P(r| x1, . . . , xn)。
Sentence Encoder
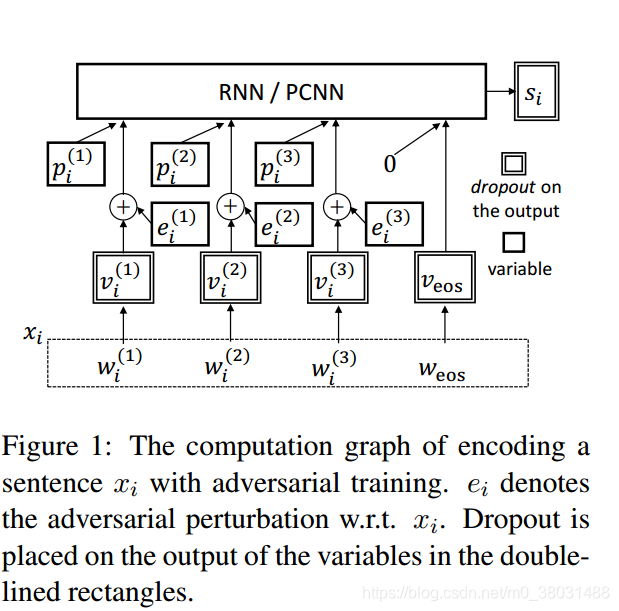
对与每个句子xi,我们都希望通过非线性转换来使其变成一个向量化的特征表示si (si =f(xi; θ))。对于如何构造模型来使其满足这一要求,我们采用关系抽取任务中常用的PCNN()和RNN来代替目标函数。
Selective Attention
对于注意力机制,论文中采用Lin (http://iiis.tsinghua.edu.cn/~weblt/papers/relation-classification.pdf)提出的注意力机制。![]()
一个实体对所要表达的关系取取决于所有包含该实体对的句子。这里αr代表注意力权重。论文中下边的公式来计算注意力权重:
![]()
这里qr的embedding是根据关系r来计算的。
Loss Function
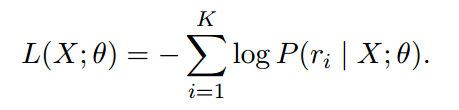
这里由于是多标签问题,K代表X表达的k种关系。
Dropout:
论文中对word embedding 使用dropout,对position embedding不使用dropout。
Adversarial Training
对抗训练是一种正则化分类算法,旨在通过对训练数据增加小而持久的扰动来提高模型的鲁棒性。增加扰动之后的损失函数就变成了如下形式了:
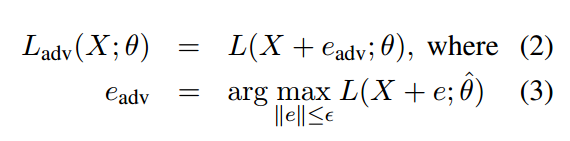
这里Eadv就相当于对word embedding增加的小扰动。由于公式(3)在神经网络中难以计算,顾用一下公式代替:
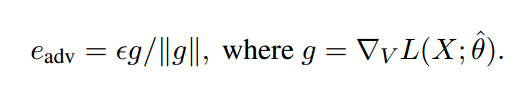
这里V代表X中所有词的向量化表示,||g||代表X中的所有单词的梯度变化。
Experiments
For The NYT dataset
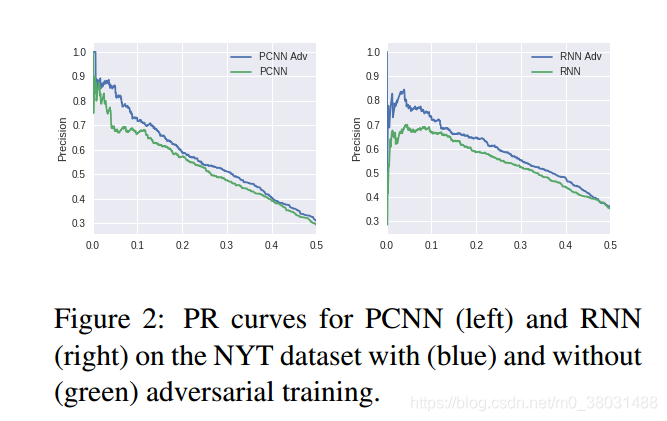
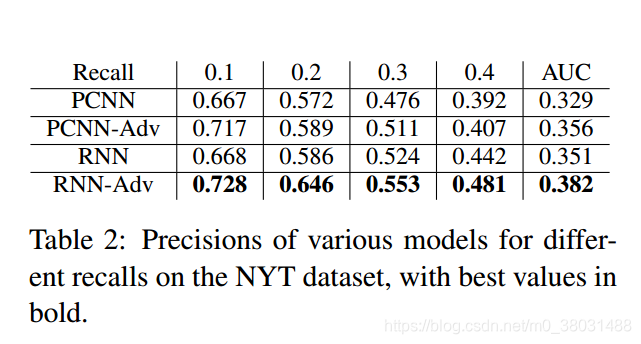
For The UW dataset
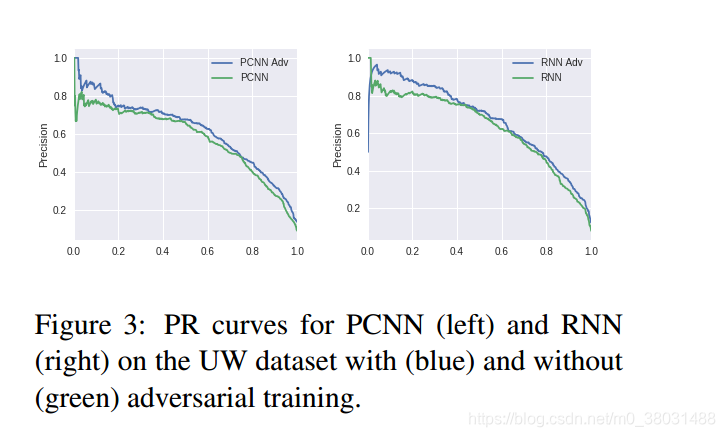
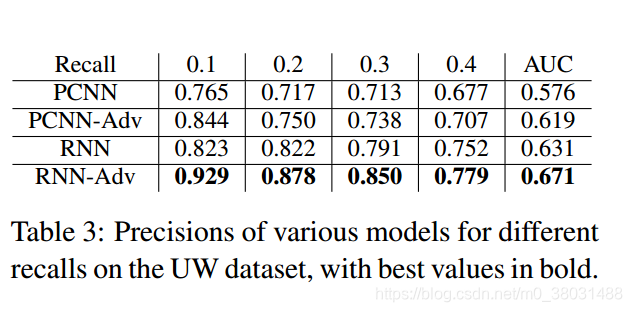
Discussion
对于CNN和RNN来说,CNN对于扰动较为敏感,RNN对于扰动较为稳定,这也说明了RNN在此任务中的鲁棒性更好,这也是为什么RNN的实验效果更好的原因。再有,对于对抗网络的训练,我们旨在对其施加小而持久的扰动,这样才能提高网络的鲁棒性。扰动过高会使得信息的语义发生改变,从而降低模型的表现。

















 2598
2598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









