







 本文详细介绍了时空LSTM(ST-LSTM)模型在位置预测任务中的数据预处理过程和特征嵌入。数据以字典形式存储在h5文件中,经过Dataset类处理,构建用户历史轨迹。每个样本包含历史位置、时间差和空间距离,通过嵌入层转换为向量。temporal_slots和spatial_slots用于创建时间间隔和空间距离的嵌入空间。模型通过STLSTMClassifier处理batch_l、batch_t、batch_d,将时间、空间信息与地点特征融合,进行序列学习。
本文详细介绍了时空LSTM(ST-LSTM)模型在位置预测任务中的数据预处理过程和特征嵌入。数据以字典形式存储在h5文件中,经过Dataset类处理,构建用户历史轨迹。每个样本包含历史位置、时间差和空间距离,通过嵌入层转换为向量。temporal_slots和spatial_slots用于创建时间间隔和空间距离的嵌入空间。模型通过STLSTMClassifier处理batch_l、batch_t、batch_d,将时间、空间信息与地点特征融合,进行序列学习。
STLSTM
论文:HST-LSTM: A Hierarchical Spatial-Temporal Long-Short Term Memory Network for Location Prediction
数据猜想
- 所有的数据以字典的形式储存在h5文件中。
hdf_filedir = os.path.join('data', 'data-split', f'{dataset_name}.h5') train_df = pd.read_hdf(hdf_filedir, key='train') val_df = pd.read_hdf(hdf_filedir, key='test' if test else 'val') - 数据集(以训练集为例,验证集一样)进入Dataset类中进行处理。处理的内容是:
dataset = Dataset(train_df, val_df, history_count=history_count, poi_count=meta_data['poi'])
需要注意的是:history_count=3(dataset = get_dataset(dataset_name=args["dataset"], history_count=3, test=True);),它的意义在于,过滤记录数目不足4条的用户。pairs = [] for user_id, group in tqdm(data.groupby('user_id'), total=data['user_id'].drop_duplicates().shape[0], desc='Construct sequences'): if group.shape[0] > self.history_count: # 满足要求记录数目的用户,对其所有记录进行整体处理。 # 假如有四条记录,则下面循环执行1次。 for i in range(group.shape[0] - self.history_count): his_rows = group.iloc[i:i+self.history_count] history_location = his_rows['poi_id_'].tolist() history_t = his_rows['delta_t'].tolist() history_d = his_rows['delta_d'].tolist() label_location = group.iloc[i+self.history_count]['poi_id_'] pairs.append((history_location, history_t, history_d, label_location)) # 外循环结束后,pairs中将不再有user_id的分化。 # pair的数目 、 四个特征(poi_id、delta_t、delta_d、标签) 、 同user_id的记录数目(3) 、 return pairs
关于四个特征,要再说明一下。
首先初始数据集大致的格式如下所示。
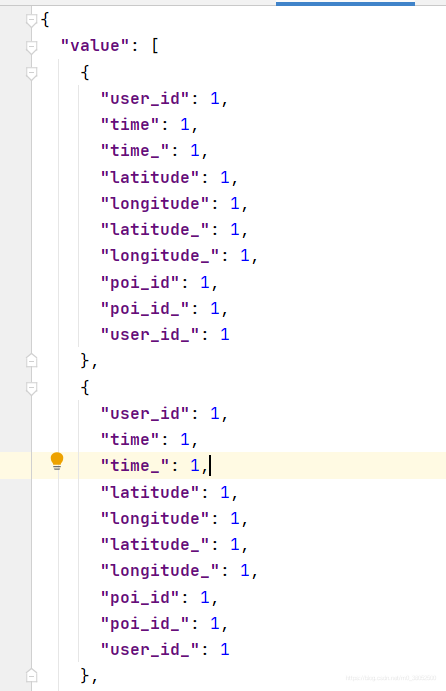
def construct_sequence(self, data):
data_ = pd.DataFrame(data, copy=True)
data_.index -= 1
data_.columns = [f'{c}_' for c in data.columns]
data = pd.concat([data, data_], axis=1).iloc[1:-1]
data['delta_t'] = (data['time_'] - data['time']).apply(lambda time: time.seconds)
data['delta_d'] = ((data['latitude'] - data['latitude_']).pow(2) +
(data['longitude'] - data['longitude_']).pow(2)).pow(0.5)
data['user_id_'] = data['user_id_'].astype(int)
data['poi_id_'] = data['poi_id_'].astype(int)
data['user_id'] = data['user_id'].astype(int)
data['poi_id'] = data['poi_id'].astype(int)
之后,经过处理得到。

红色的部分加上绿色部分表示每个pair的数据,因为既含有列表也含有标量,所以pairs并不是标准的结构化变量。
所以说,每个pair包含四个部分,而前三个部分是三个不同的特征,最后一个是标签,而经过train_iter,shuffle打乱的是pairs。
def train_iter(self, batch_size):
return next_batch(shuffle(self.train_pair), batch_size)
嵌入向量
for train_batch in dataset.train_iter(batch_size):
batch_l, batch_t, batch_d, batch_label = zip(*train_batch)
_ = batch_train(model, embed_matrix[np.array(batch_l)], batch_t, batch_d, batch_label)
这里的每次训练的输入参数,发现仅限于关于地点的特征是嵌入向量。
参考下面的代码可以知道batch_l, batch_t, batch_d, batch_label对应的是:history_location、history_t、history_d、label_location。
for user_id, group in tqdm(data.groupby('user_id'),
total=data['user_id'].drop_duplicates().shape[0],
desc='Construct sequences'):
if group.shape[0] > self.history_count:
for i in range(group.shape[0] - self.history_count):
his_rows = group.iloc[i:i+self.history_count]
history_location = his_rows['poi_id_'].tolist()
history_t = his_rows['delta_t'].tolist()
history_d = his_rows['delta_d'].tolist()
label_location = group.iloc[i+self.history_count]['poi_id_']
pairs.append((history_location, history_t, history_d, label_location))
return pairs
而前三个参数将会送入到model中训练。
model(batch_l, batch_t, batch_d)。
Slots:temporal_slots、spatial_slots
temporal_slots = construct_slots(dataset.min_t, dataset.max_t,
num_temporal_slots, temporal_slot_type)
spatial_slots = construct_slots(dataset.min_d, dataset.max_d,
num_spatial_slots, spatial_slot_type)
这里的temporal_slots、spatial_slots,细细分析construct_slots函数的参数,发现后两个其实没啥(其中第三个参数是作为超参数被指定的),但前两者其实是用于构造num_slots个元素的列表。(参考以下代码)
def construct_slots(min_value, max_value, num_slots, type):
if type == 'exp':
n = (max_value - min_value) / (math.exp(num_slots - 1) - 1)
return [n * (math.exp(x) - 1) + min_value for x in range(num_slots)]
elif type == 'linear':
n = (max_value - min_value) / (num_slots - 1)
return [n * x + min_value for x in range(num_slots)]
self.min_t, self.max_t, self.min_d, self.max_d = 1e8, 0., 1e8, 0.
self.min_t = min(self.min_t, data['delta_t'].min())
self.max_t = max(self.max_t, data['delta_t'].max())
self.min_d = min(self.min_d, data['delta_d'].min())
self.max_d = max(self.max_d, data['delta_d'].max())
而这两个slots的作用是用来生成时间和经纬度相关空间距离的嵌入空间。
self.embed_s = nn.Embedding(len(temporal_slots), input_size)
self.embed_s.weight.data.normal_(0, 0.1)
self.embed_q = nn.Embedding(len(spatial_slots), input_size)
self.embed_q.weight.data.normal_(0, 0.1)
现在基本可以确定:原始的数据集提供了嵌入空间的边界,而后指定的超参数num_slots,是做了以下操作。
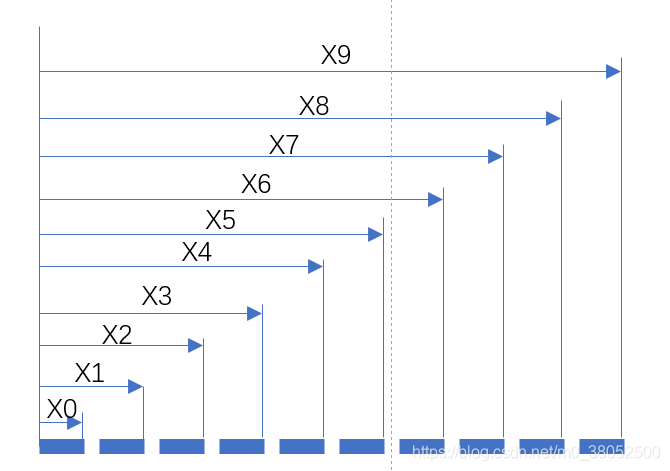
注意不是均等分!,每一个元素X代表是一个时间间隙。
STLSTMClassifier:batch_l, batch_t, batch_d
def forward(self, batch_l, batch_t, batch_d):
batch_l = torch.from_numpy(np.array(batch_l)).type(torch.FloatTensor).to(self.device)
t_ld, t_hd, t_l, t_h = self.place_parameters(*cal_slot_distance_batch(batch_t, self.temporal_slots))
d_ld, d_hd, d_l, d_h = self.place_parameters(*cal_slot_distance_batch(batch_d, self.spatial_slots))
batch_s = self.cal_inter(t_ld, t_hd, t_l, t_h, self.embed_s)
batch_q = self.cal_inter(d_ld, d_hd, d_l, d_h, self.embed_q)
hidden_out, cell_out = self.st_lstm(batch_l, batch_s, batch_q)
linear_out = self.linear(hidden_out[:,-1,:])
return linear_out
################ =================================== ##############
def cal_slot_distance_batch(batch_value, slots):
# Lower bound distance, higher bound distance, lower bound, higher bound.
ld, hd, l, h = [], [], [], []
for batch in batch_value:
ld_row, hd_row, l_row, h_row = [], [], [], []
for step in batch: # 一个 列表数据 包含 三个 时间点的记录信息。 即 3个step。
ld_one, hd_one, l_one, h_one = cal_slot_distance(step, slots)
ld_row.append(ld_one)
hd_row.append(hd_one)
l_row.append(l_one)
h_row.append(h_one)
ld.append(ld_row)
hd.append(hd_row)
l.append(l_row)
h.append(h_row)
return np.array(ld), np.array(hd), np.array(l), np.array(h)
############# =================================== ################
def cal_slot_distance(value, slots):
higher_bound = bisect(slots, value) # 二分查找 获取到的是索引位置。
lower_bound = higher_bound - 1 # 下界索引只与上界索引相差一
if higher_bound == len(slots): # 即该value是slots列表中的最后一个。
return 1., 0., lower_bound, lower_bound
else:
lower_value = slots[lower_bound]
higher_value = slots[higher_bound]
total_distance = higher_value - lower_value
return (value - lower_value) / total_distance, (higher_value - value) / total_distance, lower_bound, higher_bound # 相当于对上界和下届的值做了归一化
详情见上面代码的注释。
t_ld, t_hd, t_l, t_h = self.place_parameters(*cal_slot_distance_batch(batch_t, self.temporal_slots))
d_ld, d_hd, d_l, d_h = self.place_parameters(*cal_slot_distance_batch(batch_d, self.spatial_slots))
# Lower bound distance, higher bound distance, lower bound, higher bound.
batch_s = self.cal_inter(t_ld, t_hd, t_l, t_h, self.embed_s)
batch_q = self.cal_inter(d_ld, d_hd, d_l, d_h, self.embed_q)
def cal_inter(self, ld, hd, l, h, embed):
l_embed = embed(l)
h_embed = embed(h)
return torch.stack([hd], -1) * l_embed + torch.stack([ld], -1) * h_embed
其中的,torch.stack的解释如下:
而这里的hd、ld、l、d应该是一个(batch_size,step_num(为3))的矩阵对象。经过嵌入空间的编码分别得到一个(batch_size,step_num,编码维度)。矩阵的乘法是对应位置相乘,但是这里明显的,hd、ld、l、d的维度不够三维。因此,这里使用为其添加列表的外框,经过stack得到(batch_size,step_num,1),这样就可以实现第三维度的广播计算。如下面的图所示。
import torch
a = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = torch.tensor([[11, 22, 33], [44, 55, 66], [77, 88, 99]])
c = torch.stack([a, b], 0)
print(a)
print(b)
print(c)
# 输出信息:
tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
tensor([[11, 22, 33],
[44, 55, 66],
[77, 88, 99]])
tensor([[[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9]],
[[11, 22, 33],
[44, 55, 66],
[77, 88, 99]]])

如此,经过cal_inter函数将时序(后来节点的时间减去前者的时间)和空序(空间三维距离)上的各类信息做了融合和编码。从而实现了batch_t, batch_d向batch_s,batch_q的转变。而batch_l则基本保持不变。
Model:batch_l, batch_s, batch_q
根据上一步的分析可以知晓:batch_l, batch_s, batch_q三者的shape分别为:(batch_size,3,embed_matrix的编码空间维度)、(batch_size,3,Embedding编码维度)、(batch_size,3,Embedding编码维度)
注意batch_l也是经过了编码处理的,是在train开始之前。
_ = batch_train(model, embed_matrix[np.array(batch_l)], batch_t, batch_d, batch_label)
def forward(self, input_l, input_s, input_q, hc=None):
output_hidden, output_cell = [], []
self.check_forward_input(input_l, input_s, input_q)
for step in range(input_l.size(1)):
hc = self.cell(input_l[:, step, :], input_s[:, step, :], input_q[:, step, :], hc)
output_hidden.append(hc[0])
output_cell.append(hc[1])
return torch.stack(output_hidden, 1), torch.stack(output_cell, 1)
# STLSTM
self.cell = STLSTMCell(input_size, hidden_size, bias) # input_size 为编码空间的维度。
hc = self.cell(input_l[:, step, :], input_s[:, step, :], input_q[:, step, :], hc)
# STLSTMCell 主要是定了很多参数。
st_lstm_cell(input_l=input_l, input_s=input_s, input_q=input_q,
hidden=hc[0], cell=hc[1],
w_ih=self.w_ih, w_hh=self.w_hh, w_s=self.w_s, w_q=self.w_q,
b_ih=self.b_ih, b_hh=self.b_hh)
# st_lstm_cell 最为核心的地方!
next_hidden, next_cell # 即 hc 包含的是含有该两个元素的列表。
到此就结束了,需要进一步指出的是,step维度值为3,对应三个特征,在本例中表示前中后三个位置节点。
batch_l:表示id的编码特征信息,维度和下面两者的特征维度一致。
batch_s:表示time的编码特征信息,
batch_q:表示由经纬度计算得到的空间距离的编码特征信息。
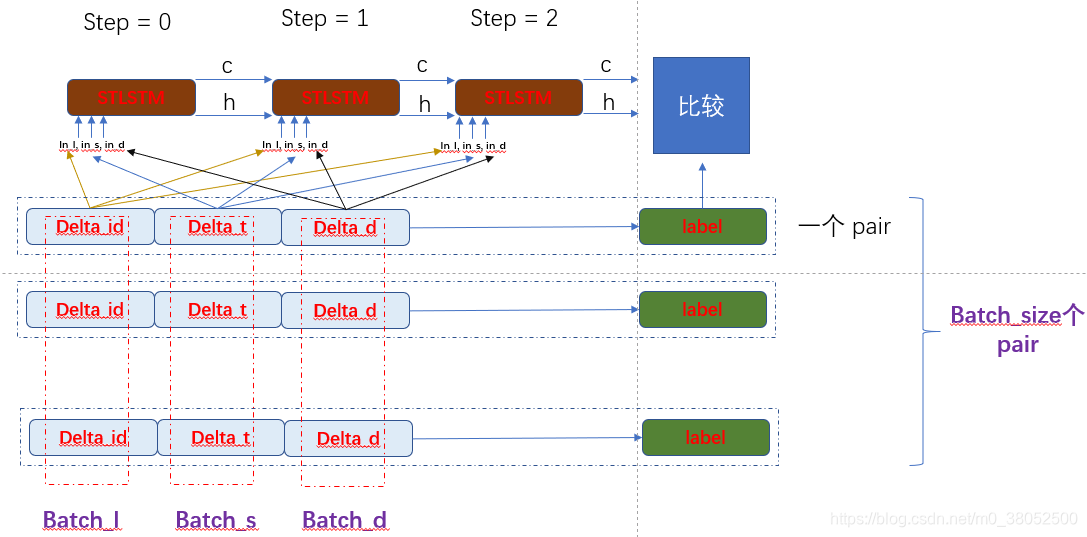
最后以一张图结束模型和数据之间的大致关系:

















 2780
2780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









