







 本文提出TransVG,一个简洁高效的Transformer视觉接地框架,解决了将语言查询与图像对应区域的问题。现有方法依赖复杂模块,而TransVG采用Transformer进行多模态对应,避免过度适应特定数据集。通过直接坐标回归,TransVG优于传统方法,创造了多个数据集的最新纪录。实验表明,Transformer在多模态融合和推理上的表现优于结构化融合模块。
本文提出TransVG,一个简洁高效的Transformer视觉接地框架,解决了将语言查询与图像对应区域的问题。现有方法依赖复杂模块,而TransVG采用Transformer进行多模态对应,避免过度适应特定数据集。通过直接坐标回归,TransVG优于传统方法,创造了多个数据集的最新纪录。实验表明,Transformer在多模态融合和推理上的表现优于结构化融合模块。
作者

Abstract
在本文中,我们提出了一个简洁而有效的基于转换的视觉基础框架,即TransVG,以解决将语言查询与图像上相应区域的基础任务。最先进的方法,包括两阶段或一阶段的方法,依赖于一个复杂的模块和手动设计的机制来执行查询推理和多模式融合。然而,在融合模块设计中,由于查询分解和图像场景图等机制的参与,使得模型很容易过度适应特定场景的数据集,限制了视觉语言环境之间的充分交互。为了避免这种警告,我们建议通过利用Transformer建立多模态对应关系,并通过经验证明,复杂的融合模块(例如,模块化注意网络、动态图和多模态树)可以被具有更高性能的Transformer-encoder层的简单堆栈所取代。此外,我们将视觉基础重新表述为一个直接坐标回归问题,并避免对一组候选对象(即区域建议或锚定框)进行预测。在五个广泛使用的数据集上进行了广泛的实验,我们的TransVG创造了一系列最先进的记录。我们构建了基于Transformer的可视化接地框架的基准,并使代码在https://github. com/djiajunustc/TransVG。
Introduction
Visual Grounding(也称为指称expression comprehension[31,60]、phrase localization [23,38]和natural language object retrieval [21,25])旨在预测语言表达式所指区域在图像上的位置。这项技术的发展有很大潜力为自然语言表达和物质世界的视觉成分提供智能接口。
解决此任务的现有方法可以大致分为两阶段和一阶段管道,如图1所示。具体而言,两阶段方法[31,34,46,60]首先生成一组稀疏区域建议,然后利用区域表达式匹配找到最佳建议。单阶段方法[9,27,56]在对象检测器的中间层执行视觉语言融合,并在预定义的密集anchors上以最大分数输出框。
 多模态融合与推理在文献[1,35,49,54,65]中得到了广泛的研究,是视觉基础研究的核心问题。一般来说,早期的两阶段和两阶段方法以简单的方式处理多模态融合。具体而言,两阶段相似网络[46]使用MLP测量区域和表达式嵌入之间的相似性,一阶段FAOA[56]通过直接级联将语言向量编码为视觉特征。这些简单的设计是有效的,但会导致次优结果,特别是在长而复杂的语言表达式上。下面的研究提出了不同的体系结构来提高性能。在两阶段方法中,模块化注意网络[59]、各种图[48,52,53]和多模态树[28]被设计用于更好地建模多模态关系。单阶段方法[55]还通过提出多轮融合模块探索了更好的查询建模。
多模态融合与推理在文献[1,35,49,54,65]中得到了广泛的研究,是视觉基础研究的核心问题。一般来说,早期的两阶段和两阶段方法以简单的方式处理多模态融合。具体而言,两阶段相似网络[46]使用MLP测量区域和表达式嵌入之间的相似性,一阶段FAOA[56]通过直接级联将语言向量编码为视觉特征。这些简单的设计是有效的,但会导致次优结果,特别是在长而复杂的语言表达式上。下面的研究提出了不同的体系结构来提高性能。在两阶段方法中,模块化注意网络[59]、各种图[48,52,53]和多模态树[28]被设计用于更好地建模多模态关系。单阶段方法[55]还通过提出多轮融合模块探索了更好的查询建模。
尽管效果很好,但这些复杂的融合模块是基于特定预定义的语言查询或图像场景结构构建的,其灵感来自于人类的先验知识。通常,人工设计的机制参与到融合模块中会使模型过度适应特定场景,例如特定的查询长度和查询关系,并限制可视化语言上下文之间的充分交互。此外,尽管视觉基础的最终目标是定位所引用的对象,但以前的大多数方法都以间接方式将查询对象基础化。它们通常定义语言引导的候选预测、选择和细化的代理问题。通常,候选区域为稀疏区域方案[60,31,46]或密集锚[56],从中选择并优化最佳区域以获得最终接地盒。由于这些方法的预测是由候选对象做出的,因此性能很容易受到生成建议(或预定义锚)的先验知识和为候选对象分配目标的启发式方法的影响。
在本研究中,我们探索了一种避免上述问题的替代方法。形式上,我们引入了一个简洁新颖的基于转换器的框架,即TransVG,以有效地解决Visual grounding的任务。我们的经验表明,结构化的融合模块可以被transformer encoder层的简单堆栈所取代。特别是,Transformer的核心部分(即attention层)已经准备好跨视觉和语言输入建立模态内和模态间的对应关系,尽管我们没有预先定义任何特定的融合机制。此外,我们发现直接回归盒坐标比以前的方法更能间接地对查询对象进行grounding处理。我们的TransVG直接输出4维坐标以使对象接地,而不是基于一组候选框进行预测。
我们提议的TransVG管道如图1(c)所示。我们首先将RGB图像和语言表达式输入到两个兄弟分支中。在这两个分支中分别应用视觉transformer和语言transformer对视觉域和语言域中的全局线索进行建模。然后,将抽象的视觉标记和语言标记进行融合,利用视觉语言transformer进行跨模态关系推理。最后,将参考对象的盒坐标直接回归,进行grounding。我们在五个流行的视觉基础数据集上对我们的框架进行基准测试,包括ReferItGame[23]、Flickr30K实体[38]、RefCOCO[60]、RefCOCO[60]、Refcolog[31],我们的方法设置了一系列最先进的记录。值得注意的是,我们提出的TransVG达到了70.73%, 79. 10%和78.35%在ReferItGame、Flickr30K和RefCOCO数据集的测试集,与实力最强的竞争对手相比,提高了6.13%,5.80%和6.05%。
- In all,我们的贡献有以下三点:
- 我们提出了第一个基于transformer的可视接地框架,该框架拥有更整洁的体系结构,但比流行的单阶段和两阶段框架实现了更好的性能。
- 我们提出了一个优雅的观点,即通过transformer均匀地捕获模态内和模态间的上下文,并将视觉接地描述为一个直接坐标回归问题。
- 我们进行了大量的实验来验证我们的方法的优点,并在几个流行的基准上显示了显著改进的结果。
Related work
2.1Visual Grounding
视觉基础的最新进展可以大致分为两个方向,即:两阶段法[19,20,28,46,48,52,59,63,68]和一阶段法[9,27,42,55,56]。我们将在下面简要回顾它们。
两阶段法
两阶段方法的特点是在第一阶段生成区域建议,然后在第二阶段利用语言表达式选择最佳匹配区域。通常,使用无监督方法[37,46]或预先训练的对象检测器[59,63]生成区域建议。第二阶段应用二元分类[46,64]或最大裕度排序[31,34,47]的训练损失,以最大化正向对象查询对之间的相似性。先锋研究[31,47,60]在两阶段框架下取得了良好的结果。早期工作MattNet[59]引入了模块化设计,通过更好地建模主题、位置和关系相关的语言描述,提高了接地精度。最近的一些研究通过更好地建模对象关系[28,48,52],加强对应学习[29],或利用短语共现[3,7,13],进一步改进了两阶段方法。
一阶段法
单阶段方法摆脱了两阶段模式下的计算密集型对象建议生成和区域特征提取。相反,语言上下文与视觉特征紧密融合,并且进一步利用语言相关特征映射以滑动窗口方式执行边界框预测。开创性的工作FAOA[56]将文本表达式编码为语言向量,并将语言向量融合到YOLOv3检测器[40]中,以固定引用的实例。RCCF[27]将视觉接地问题表述为相关过滤过程[4,17],并选取相关热图的峰值作为目标对象的中心。最近的工作ReSC[55]设计了一个递归子查询构造模块,以解决FAOA[56]对复杂查询的限制。
2.2Transformer
Transformer首次提出在[45],以解决神经机器翻译(NMT)。Transformer层的主要组件是attention模块,它并行扫描输入序列,并使用自适应权重聚合整个序列的信息。与RNN中的循环单元相比[18,32,44],注意机制在处理长序列时表现出更好的性能。这种优势引起了人们对Transformer在NLP任务[11,12,39,66]和语音识别[33,50]中应用的研究兴趣。
Transformer In Vision tasks
受Transformer在神经机器翻译中的巨大成功的启发,提出了一系列适用于视觉任务的Transformer[5、6、8、14、22、51、62、67 ]。深入的工作DETR[5]将目标检测作为一个集预测问题。它引入了一小组可学习的对象查询,利用注意机制解释全局上下文和对象关系,并并行输出最终的预测集。ViT[14]表明,纯Transformer可以在图像分类任务上实现优异的性能。最近,在[6]中引入了预训练图像处理转换器(IPT),以解决低级视觉问题,例如: denoising, super-resolution and deraining。
Transformer in Vision-Language Tasks
在BERT[12]强大的预训练模型的推动下,一些研究人员开始研究视觉语言预训练(VLP)[10,26,30,43,57],以联合表示图像和文本。通常,这些模型将对象建议和文本作为输入,并设计多个transformer-encoder层用于联合表示学习。引入了大量的预训练任务,包括图像文本匹配(ITM)、词区域对齐(WRA)、蒙蔽语言建模(MLM)、蒙蔽区域建模(MRM)等,尽管基本单元(即transformer编码器层)相似,VLP的目标是学习具有大规模数据的通用视觉语言表示,以促进下游任务。相比之下,我们专注于开发一种新的基于transformer的可视接地框架,并学习使用少量可视接地数据执行同构多模态推理。

3 Transformers for Visual grounding
这项工作中,我们提出了Visual grounding Transformer(TransVG),这是一种基于transformer编码器堆栈和直接盒坐标预测的Visual grounding任务的新框架。如图2所示,给定一个图像和一个语言表达式作为输入,我们首先将它们分成两个兄弟分支,即。视觉分支和语言分支,生成视觉和语言特征嵌入。然后,我们将多模态特征嵌入到一起,并附加一个可学习标记(称为[REG]标记)来构造视觉语言融合模块的输入。视觉语言Transformer利用自我注意机制对语内和语间语境进行建模,将不同语态的输入标记均匀地嵌入到一个共同的语义空间中。最后,利用[REG]token的输出状态直接预测预测头中参考对象的4维坐标。
在下面的小节中,我们首先回顾了Transformer的初步设计,然后详细阐述了用于视觉接地的Transformer设计。
3.1Preliminary准备
在详细介绍TransVG的体系结构之前,我们简要回顾了[45]中提出的用于机器翻译的传统Transformer。Transformer的核心部件是注意力机制。给定查询嵌入fq、密钥嵌入fk和值嵌入fv,单个头部注意层的输出计算如下:
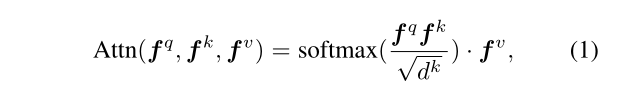 式中 d k d^{k} dk为 f k f^{k} fk的channel dimension。与经典的神经序列转导模型类似,传统的Transformer具有编码器-解码器结构。然而,在我们的方法中,我们只使用transformer编码器层。
式中 d k d^{k} dk为 f k f^{k} fk的channel dimension。与经典的神经序列转导模型类似,传统的Transformer具有编码器-解码器结构。然而,在我们的方法中,我们只使用transformer编码器层。
具体地说,每个Transformer编码器层有两个子层,即,一个多头自我注意层和一个简单的前馈网络(FFN)。多头注意是单头注意的一种变体(如函数1),selfattention表示查询、键和值来自同一个嵌入集。FFN是由完全连接层和ReLU激活层组成的MLP。
在Transformer Encoder层中,每个子层被放入residual structure残余结构中,其中在残余连接之后执行层归一化[2]。让我们将输入表示为xn,Transformer Encoder层中的过程为:
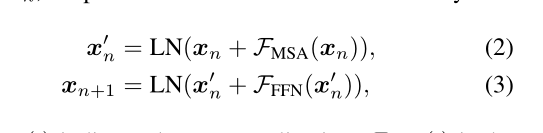 LN(·)表示层规范化,FMSA(·)表示多头自注意层,FFFN(·)表示前馈网络。
LN(·)表示层规范化,FMSA(·)表示多头自注意层,FFFN(·)表示前馈网络。
3.2TransVG Architecture
如图2所示,TransVG中有四个主要组件:(1)视觉分支,(2)语言分支,(3)视觉语言融合模块,(4)预测头。
Visual Branch
可视分支从卷积主干网络开始,然后是可视转换器。我们利用常用的ResNet[16]作为骨干网络。视觉Transformer由6个Transformer encoder层组成。每个Transformer encoder层包括一个多头自关注层和一个FFN。在多头注意层中有8个头,在FFN中有2个FC层,后面是ReLU激活层。这两个FC层的输出通道尺寸分别为2048和256。
给定一个图像 z 0 ∈ R 3 × H 0 × W 0 z_{0}∈R^{3×H0×W0} z0∈R3×H
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3177
3177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









