







作者

Abstract
Referring expression comprehension expects to accurately locate an object described by a language expression, which requires precise language-aware visual object representations. However, existing methods usually use rectangular object representations, such as object proposal regions and grid regions. They ignore some fine-grained object information like shapes and poses, which are often described in language expressions and important to localize objects. Additionally, rectangular object regions usually contain background contents and irrelevant foreground features, which also decrease the localization performance. To address these problems, we propose a language-aware deformable convolution model (LDC) to learn language-aware fine-grained object representations. Rather than extracting rectangular object representations, LDC adaptively samples a set of key points based on the image and language to represent objects. This type of object representations can capture more fine-grained object information (e.g., shapes and poses) and suppress noises in accordance with language and thus, boosts the object localization performance. Based on the language-aware fine-grained object representation, we next design a bidirectional interaction model (BIM) that leverages a modified co-attention mechanism to build cross-modal bidirectional interactions to further improve the language and object representations. Furthermore, we propose a hierarchical fine-grained representation network (HFRN) to learn language-aware fine-grained object representations and cross-modal bidirectional interactions at local word level and global sentence level, respectively. Our proposed method outperforms the state-of-the-art methods on the RefCOCO, RefCOCO+ and Ref- COCOg datasets.
参照表达式理解期望精确定位由语言表达式描述的对象,这需要精确的语言感知视觉对象表示。然而,现有的方法通常使用矩形对象表示,例如对象提议区域和网格区域。他们忽略了一些细粒度的对象信息,如形状和姿态,这些信息通常在语言表达式中描述,对本地化对象很重要。此外,矩形对象区域通常包含背景内容和不相关的前景特征,这也降低了定位性能。为了解决这些问题,我们提出了一个语言感知的可变形卷积模型(LDC)来学习语言感知的细粒度对象表示。LDC不是提取矩形对象表示,而是基于图像和语言自适应地采样一组关键点来表示对象。这种类型的对象表示可以捕捉更细粒度的对象信息(例如,形状和姿态)并根据语言抑制噪声,从而提高对象定位性能。基于语言感知的细粒度对象表示,我们接下来设计双向交互模型(BIM ),该模型利用修改的共同注意机制来构建跨模态双向交互,以进一步改进语言和对象表示。此外,我们提出了一个分层细粒度表示网络(HFRN ),分别在局部单词级和全局句子级学习语言感知的细粒度对象表示和跨模态双向交互。我们提出的方法在RefCOCO、RefCOCO+和RefCOCOg数据集上的性能优于当前最先进的方法。
Introduction

参照表达理解旨在参照自然语言表达定位图像中的特定对象,这是面向人机通信的人工智能领域的基本任务之一[8,13,14,23,26,36–38,40,44,52]。为了实现这一目标,指代表达理解不仅需要理解图像和自然语言,而且还需要将它们对齐和关联以根植于正确的区域,这使得它具有挑战性。
为了对语言和视觉之间的关系进行建模,现有的方法[2,16,22,25,27,28,35,41–43,45,47–50]通常将语言特征和常规图像区域特征相结合,例如对象提议区域[2,22,25,27,28,41–43,47–50]和网格区域[16,35,45],分别如图1 (a)和(b)所示。然而,这些方法忽略了一些与自然语言相关的细粒度对象信息,如对象形状和姿态,这些信息通常在语言表达式中描述,并且在参考表达式理解来定位和区分目标对象时很重要。此外,矩形提议区域通常包含噪声信息,例如背景内容或不相关的前景特征。例如,在图1 (a)中,基于提议区域的方法没有通过紧密的边界框来定位“斑块”对象。原因之一是该方法中的对象表示不包含细粒度的对象形状信息,并且引入了一些噪声,如“牌匾”的底部和正方形板。在图1 (b)中,如果没有细粒度的对象表示,基于网格区域的方法无法找到目标对象。
为了解决上述问题,我们提出了一种语言感知的可变形卷积模型(LDC)来学习语言感知的细粒度对象表示。与以前提取矩形对象表示的方法不同,LDC自适应地生成基于图像和语言表示对象的一组关键点。它可以捕捉与语言相关的更细粒度的对象信息(例如,形状和姿态)。例如,在图1 ©中,这些关键点被放置在“斑块”的边界上,以捕捉形状信息“圆”。此外,可以通过聚集这些周围特征来增强对象特征的语义区分,这将有助于视觉和语言之间的后续跨通道交互。
基于语言感知的细粒度对象表示,我们接下来设计双向交互模型(BIM)来构建双向视觉-语言交互,以进一步改进语言和对象表示。BIM使用修改的共同注意机制,并由语言加权视觉分支和视觉加权语言分支组成。语言加权视觉分支使用语言特征作为线索来加权每个位置的视觉特征。相反,视觉加权视觉分支使用视觉特征将语言投射到视觉空间。
我们的LDC和BIM基于表达式提取视觉对象表示,表达式中包含层次语义信息,比如单词级和句子级信息。整个句子描述的是全局语义,而有很多细节是用文字描述的。因此,我们提出了一个层次化的细粒度表示网络(HFRN)来学习细粒度的对象表示,并在不同的语义层建立双向的跨通道交互,以实现精确的对象定位。我们在三个基准数据集上验证了所提方法的有效性,包括RefCOCO [15]、RefCOCO+ [15]和RefCOCOg [27]数据集。实验结果证明了该方法的有效性。
总之,我们的方法的主要贡献如下:
- 我们提出了一个语言感知的可变形模型(LDC)和一个双向交互模型(BIM),以学习语言感知的细粒度对象表示,并构建双向跨通道交互来进一步增强对象和语言表示。
- 我们提出了一种分层细粒度表示网络(HFRN),它在局部单词级和全局句子级利用LDC和BIM来预测更准确的理解结果。
- 大量实验表明,我们的方法在RefCOCO、RefCOCO+和RefCOCOg数据集上明显优于最先进的方法。
Related work
近年来,参照表达理解的任务吸引了越来越多的关注,其期望基于输入的表达在图像中定位相应的对象。以前的指代表达理解方法[2,6,11,16,22,25,27,28,35,41–43,45,47–51]主要可以分为两类,包括基于提议区域的方法[2,6,11,22,25,27,28,41–43,47–51]和基于网格区域的方法[16,35,45]。
大多数基于建议区域的方法[2,22,41–43,47,50]都基于“监听器”策略,该策略首先将语言特征与建议区域的视觉特征相结合,然后从这些建议中选择最匹配输入表达式的目标区域。建议区域通常由预训练的对象检测器提取(例如,更快的R-CNN [34],掩模R-CNN [9]和其他[4,17,30–32])。为了将视觉区域与更强大的表达对齐,方法[22,47]提出将表达分解为三个部分(主题、定位和关系),并利用跨通道注意力来关注相关区域。为了自适应地基于复杂的指代表达,在[43]中的动态图形注意网络基于多模态上下文关系图执行多步视觉推理,以逐步识别复合对象。在一些作品中[25,27,28,48],“说话者”策略首先从每个对象的视觉特征预测表情,然后将预测的表情与输入表情进行匹配,以找出期望的对象。基于上述“听者”和“说者”的工作,于等人[49]提出了一个说话者-听者-强化者的联合模型,以更好地沟通语言和视觉之间的关系。虽然这些方法可以保证相当大的性能,但它们通常依赖于由预训练的对象检测器生成的提议区域。如果该区域不在建议区域中,将无法定位目标对象。此外,矩形建议区域是粗略的对象表示,其可能包含背景内容或不相关的前景特征,并因此干扰对象定位精度。
基于网格区域的方法[16,35,45]通常将语言特征与网格区域特征相融合,然后利用一阶段对象检测器(例如YOLOv3 [33])来直接定位对应于输入表达式的对象。这些方法不依赖于预先提取的建议区域,并且是端到端训练的。Yang等人[45]将文本查询的嵌入和空间特征集成到YOLOv3对象检测器中[33]。廖等人[16]介绍了一种跨通道相关滤波方法,将语言特征映射到CenterNet对象检测器[7]。然而,这些方法使用矩形网格区域来表示对象,这忽略了一些细粒度的对象信息(例如,对象形状和姿态),并且可能导致输入表达式的不准确的对象定位。与它们不同的是,我们的方法基于图像和语言自适应地学习一组关键点来表示对象,而不是矩形对象区域,这不仅可以捕捉更细粒度的对象信息,而且可以根据语言抑制噪声。
3 PROPOSED METHOD
在本节中,我们首先介绍所提出的语言感知可变形卷积模型(LDC)和双向迭代模型(BIM ),以学习语言感知的细粒度对象表示。然后,我们详细介绍了提出的层次细粒度表示网络(HFRN ),它应用这两个模型来定位引用表达式描述的对象。
3.1Language-Aware Deformable Convolution Model (LDC)
在指称表达理解中,精确的语言感知对象表征有助于将图像与语言对齐,提高定位性能。为了学习语言感知的细粒度对象表示,一方面,我们提出了一种语言感知的可变形卷积模型(LDC ),它基于图像和语言自适应地采样一组关键点来建模对象形状、姿态和重要的语义信息。另一方面,我们利用监督学习策略来优化LDC,以更好地预测这些关键点。我们提取伪本地化,并将其与真实边界框进行比较,无需额外的手动注释。
提出的LDC如图2所示。考虑视觉表示 V ∈ R c v × h × w V∈\R^{c_v×h×w} V∈Rcv×h×w和语言表示 q ∈ R c q q∈\R^{c_q} q∈Rcq,其中 c v 、 h 和 w c_v、h和w cv、h和w分别表示视觉特征图 V V V的通道维度、高度和宽度; c q c_q cq 表示语言特征 q q q 的通道维度。这里, V = { v p } p = 1 h w V = \{v_p\}^{hw}_{p=1} V={
vp}p=1hw, v p ∈ R c v v_p∈ \R^{c_v} vp∈Rcv 表示 V V V 中第 p p p 个位置的特征向量。我们的目标是自适应地学习语言感知的关键点。受可变形卷积 [5] 的启发,我们首先为每个地图位置 p p p 定义一个初始点集 G G G。初始 G = { ( − 1 , − 1 ) , . . . , ( 0 , 0 ) , . . . , ( 1 , 1 ) } G = \{(−1,−1), ..., (0, 0), ..., (1, 1)\} G={
(−1,−1),...,(0,0),...,(1,1)} 是一个 3 × 3 的点集,其中每组坐标代表相对点到 p p p 的位置。然后,我们可以通过偏移 G G G中点的坐标来近似得到想要的关键点物体的边界。为此,我们使用全连接层生成一组语言过滤器 f q f^q fq 并将视觉表示 V V V 与这些语言过滤器进行卷积以获得语言感知偏移量 Δ p q Δp^q Δpq:
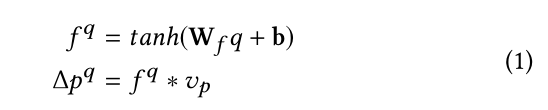
其中tanh是激活函数, W f W_f Wf和 b b b是全连接层的权重和偏差。 f q ∈ R 2 n c v f^q∈ \R^{2nc_v} fq∈R2ncv 是语言过滤器的集合,其中 n = 3 × 3 = 9 n = 3 × 3 = 9 n=3×3=9 表示每个视觉表示 v p v_p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









