







 本文详述了实例分割的单阶段方法,探讨了局部掩码和全局掩码的表示方式,包括显式编码的轮廓、结构化4D张量和紧凑型掩码编码。此外,还对比了基于局部和全局掩码的方法,如YOLACT、PolarMask、TensorMask等,以及SOLO系列的按位置分割目标的技术。这些方法在效率和准确性上有所提升,为实例分割提供了新的思路。
本文详述了实例分割的单阶段方法,探讨了局部掩码和全局掩码的表示方式,包括显式编码的轮廓、结构化4D张量和紧凑型掩码编码。此外,还对比了基于局部和全局掩码的方法,如YOLACT、PolarMask、TensorMask等,以及SOLO系列的按位置分割目标的技术。这些方法在效率和准确性上有所提升,为实例分割提供了新的思路。
本文比较全面地介绍了实例分割在单阶段方法上的进展,根据基于局部掩码、基于全局掩码和按照位置分割这三个类别,分析了相关19篇论文的研究情况,并介绍了它们的优缺点。
实例分割是一项具有挑战性的计算机视觉任务,需要预测对象实例及其每像素分割掩码。这使其成为语义分割和目标检测的混合体。
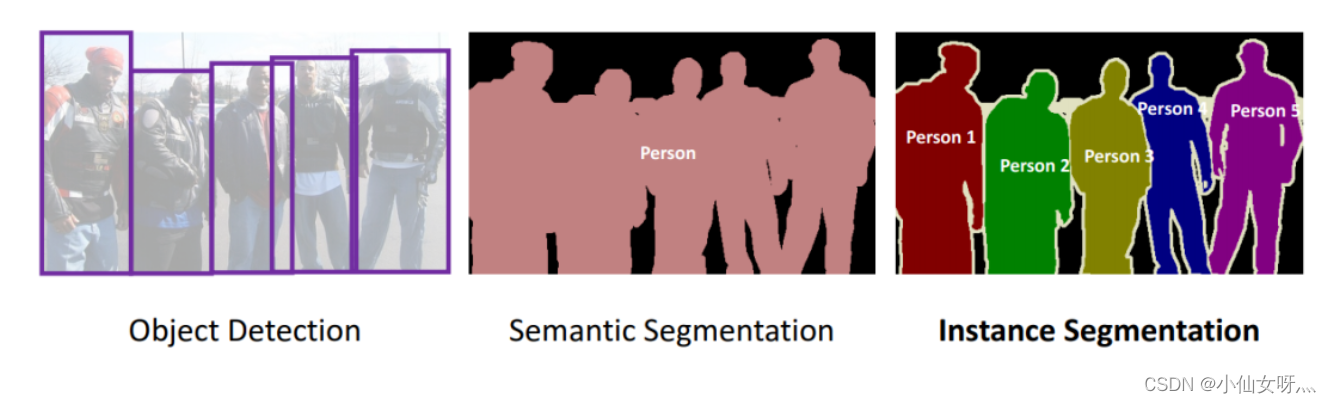
自 Mask R-CNN 以来,实例分割的SOTA方法主要是 Mask RCNN 及其变体(PANet、Mask Score RCNN 等)。它采用先检测再分割的方法,先进行目标检测,提取每个目标实例周围的边界框,然后在每个边界框内部进行二值分割,分离前景(目标)和背景。
除了检测然后分割(或逐检测分割)的自顶向下方法之外,还有其他一些实例分割方法。一个例子是通过将实例分割作为自底向上的像素分配问题来关注像素,就像在 SpatialEmbedding (ICCV 2019) 中所做的那样。但是这些方法通常比检测然后分割的 SOTA 具有更差的性能,我们不会在这篇文章中详细介绍。
然而,Mask RCNN 速度非常慢,许多实时应用场合无法使用。此外,Mask RCNN 预测的掩码具有固定的分辨率,因此对于具有复杂形状的大目标来说不够精细。由于anchor-free目标检测方法(例如 CenterNet 和 FCOS)的进步,已经出现了一波关于单阶段实例分割的研究。其中许多方法比 Mask RCNN 更快、更准确,如下图所示。
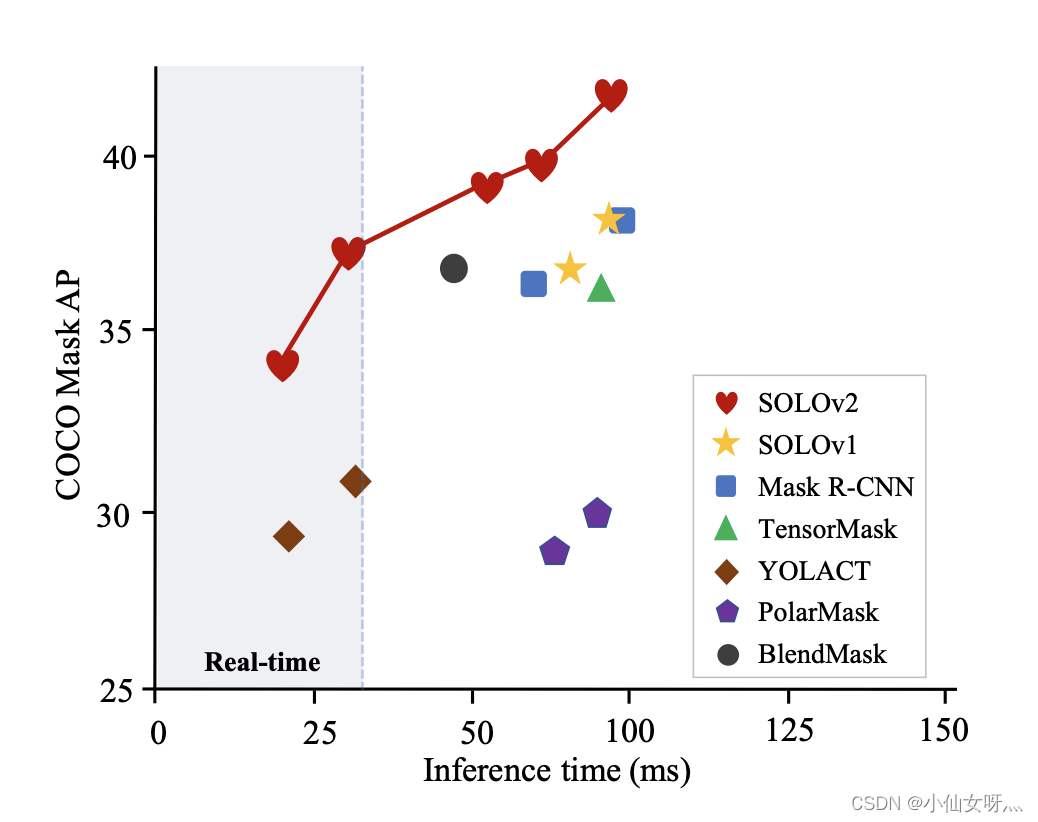
最近在 Tesla V100 GPU 上测试的单阶段方法的推理时间
本文将回顾单阶段实例分割的最新进展,重点是掩码表示——实例分割的一个关键方面。
局部掩码和全局掩码
在实例分割中要问的一个核心问题是实例掩码的表示或参数化——1)是使用局部掩码还是全局掩码,2)如何表示/参数化掩码。
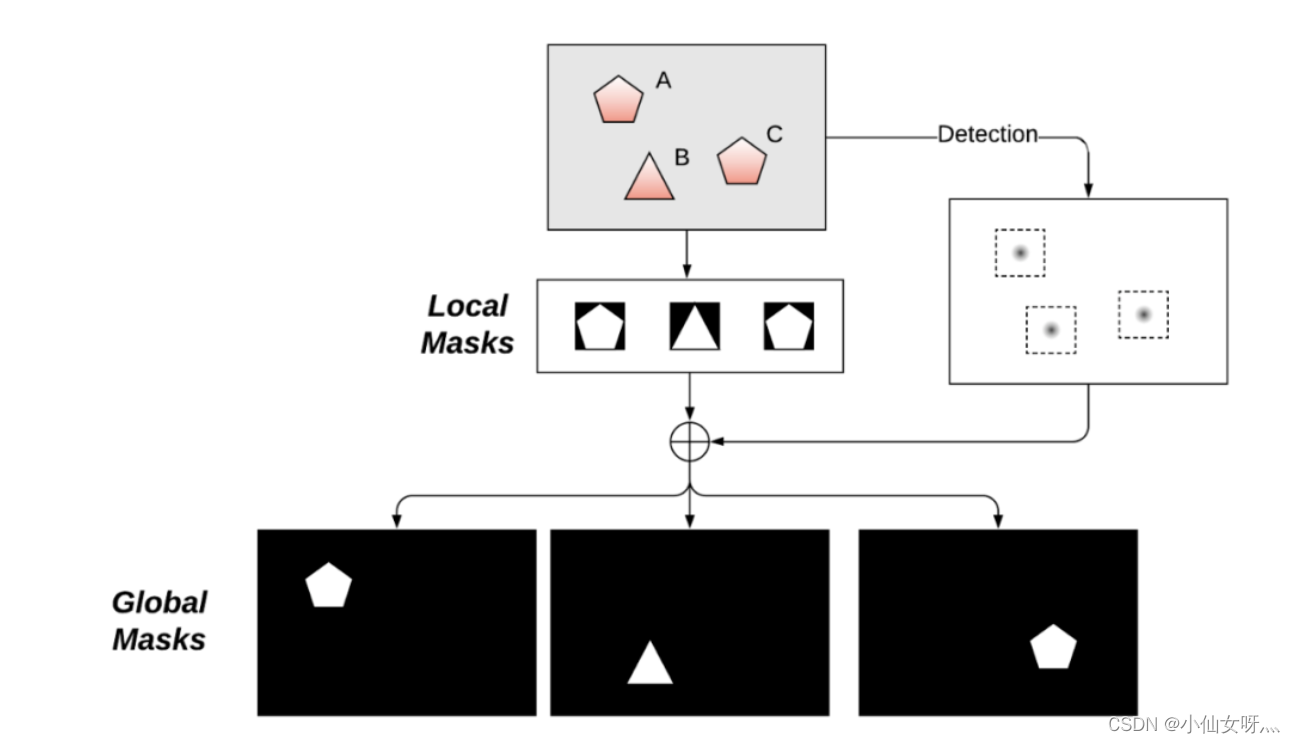
主要有两种表示实例掩码的方法:局部掩码和全局掩码。
全局掩码是我们最终想要的,它与输入图像具有相同的空间范围,尽管分辨率可能更小,例如原始图像的 1/4 或 1/8。它具有对大或小目标具有相同分辨率(因此具有固定长度特征)的天然优势。这不会牺牲更大目标的分辨率,固定分辨率有助于执行批处理以进行优化。
局部掩码通常更紧凑,因为它没有作为全局掩码的过多边界。它必须与要恢复到全局掩码的掩码位置一起使用,并且局部掩码大小将取决于目标大小。但是要执行有效的批处理,实例掩码需要固定长度的参数化。最简单的解决方案是将实例掩码调整为固定图像分辨率,如 Mask RCNN 所采用的那样。正如我们在下面看到的,还有更有效的方法来参数化局部掩码。
根据是使用局部掩码还是全局掩码,单阶段实例分割在很大程度上可以分为基于局部掩码( local-mask-based )和基于全局掩码( global-mask-based )的方法。
基于局部掩码的方法
基于局部掩码的方法直接在每个局部区域上输出实例掩码。
显式编码的轮廓
Bounding box 在某种意义上是一个粗糙的掩码,它用最小的边界矩形来逼近掩码的轮廓。ExtremeNet(Bottom-up Object Detection by Grouping Extreme and Center Points,CVPR 2019)通过使用四个极值点(因此是一个具有8个自由度的边界框而不是传统的4个DoF)进行检测,并且这种更丰富的参数化可以自然地扩展通过在其对应边缘上的两个方向上的极值点延伸到整个边缘长度的 1/4 的一段,到八边形掩模。

从那时起,有一系列工作试图将实例掩码的轮廓编码/参数化为固定长度的系数,给定不同的分解基础。这些方法回归每个实例的中心(不一定是 bbox 中心)和相对于该中心的轮廓。
ESE-Seg&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









