









NeRF:一种用于三维场景表达的隐函数。
全称为神经辐射场。关于辐射场,任何结构如果可以用空间位置信息查询到对应的一组 颜色+密度 信息,那么就可以是这里所说的辐射场。NeRF只是使用了神经网络来表示一个辐射场。
NeRF的整体思想是:在forward用体渲染采样神经网络的辐射场,然后将结果和ground truth进行对比,反向优化网络参数,不断迭代使得辐射场接近真实值。
它是深度学习和图形学知识的结合,基于图形学的组件基本上只涉及体渲染,涉及深度学习的组件只是基本的MLP。
之所以用神经网络来表示辐射场,一是比起类似3D Texture这种volume的表示,神经网络没有分辨率的限制,也不会随着表达精度的上升而光速增长体积。另一个原因就是神经网络的参数是可学习的,神经网络中的计算/查询是可微的(只要满足这两个条件,三维表征也可以是其他形式的)。因此NeRF才能通过不断地更新参数来使得表征更加接近真实值,完成高质量的新视角合成任务。
体渲染及其可微性质
体渲染就是模拟光线穿过一系列粒子,发生一些反射、散射、吸收、最后到达人眼的过程。其实不管是硬表面软表面,NeRF都是把各种物体当做不同密度的粒子、烟雾一类的东西去建模的。
体渲染公式其实就是在光线上取一段路径做积分。对计算机来说则是在光线上产生一些step、t,得到一系列采样点的位置r(t) 和观察方向d,然后将这些点作为神经网络的输入,得到对应的密度和颜色。最后再根据距离相机远近计算一个衰减权重T(t),把这些采样点做一个加权和就OK了。
总的来说,体渲染的过程并不复杂,重要的是其积分形式带来的可微性质,使得基于梯度的机器学习算法能够迭代更新可学习参数,从而解决场景优化问题。
Position Encoding
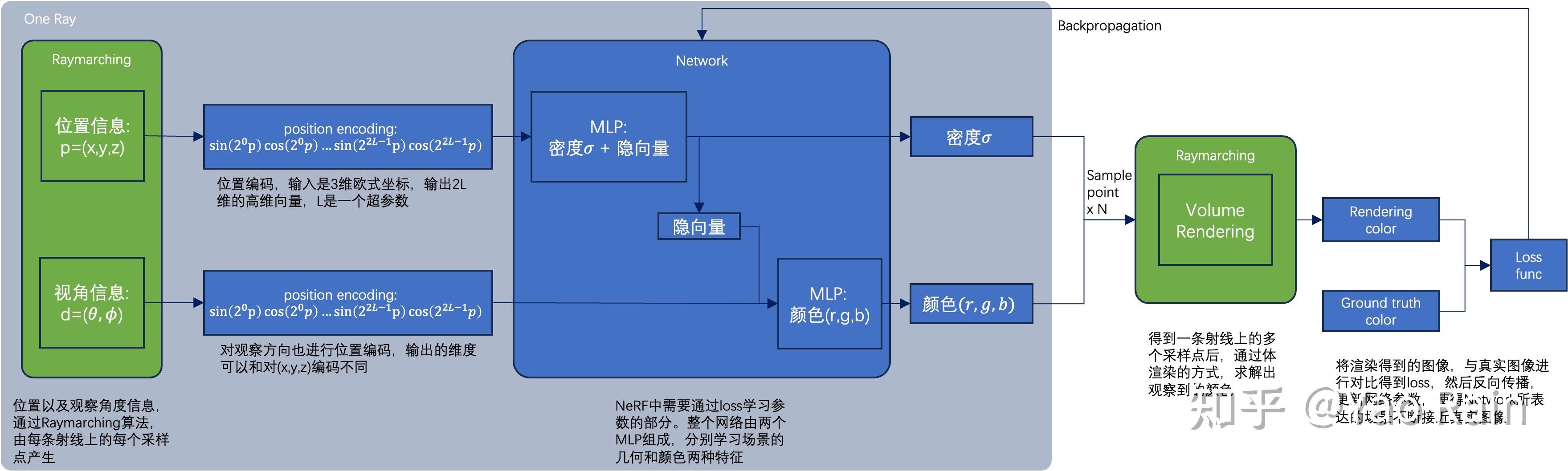
从整个pipeline来说,输入是一个5维向量,(
x
,
y
,
z
x,y,z
x,y,z) 代表采样点位置,(
θ
,
ϕ
\theta,\phi
θ,ϕ) 代表在该点的观察方向。不过NeRF不是端到端的网络,对于它网络的部分,输入维度和L相关,L是位置编码时使用的超参数。
原文中对(
x
,
y
,
z
x,y,z
x,y,z) 编码时用的 L=10,此时密度网络的输入是3210=60 维的向量。当然也不一定用原文中的公式,能把(
x
,
y
,
z
x,y,z
x,y,z)映射到更高维度就可以。
关于使用位置编码的原因是基于过去大家对MLP的观察,因为MLP的参数在学习时会倾向于学习低频信息,所以直接对网络使用5D输入效果会很糊。使用位置编码后原本在低维接近的点,在高维会离得很远。也就是MLP在高维学到的低频信息往往对低维来说不是低频的。
密度网络和外观网络
除了位置编码,NeRF中使用了两个特征网络,5D的输入被拆分成两组,并分别使用不用的L进行位置编码,再送入不同的网络中进行训练。而密度网络中除了密度,还需要输出一个隐向量以供外观网络参考位置信息。
原因在于:
- 在图形学中,三维场景的密度本身就是一个各向同性的属性,并没有视角依赖;
- 外观中的光照效果,不管是普通高光还是各向异性高光,都是依赖于观察方向的。
这样分成两个网络,密度网络可以只考虑密度信息,以便生成更好的几何质量。
分层采样
coarse-to-fine。把整个pipeline生成两个实例,同时优化粗细两个网络。先对粗网络使用较少的采样点粗采样一遍,之后按照粗采样到的位置的密度值,在相应区间生成不同数量的采样点。原则上重点照顾拥有更高密度的位置,密度越高使用越多的采样点进行精细采样。
主要是为了提高采样效率。
小结
NeRF:
- 基于体渲染的可微渲染框架;
- 一种三维表示方式,通过采样点查询颜色和密度信息的过程可微分;
- 基于梯度的优化方法。
下面是当下最流行的instant NGP。
Instant-NGP,用参数化显式表达加速pipeline
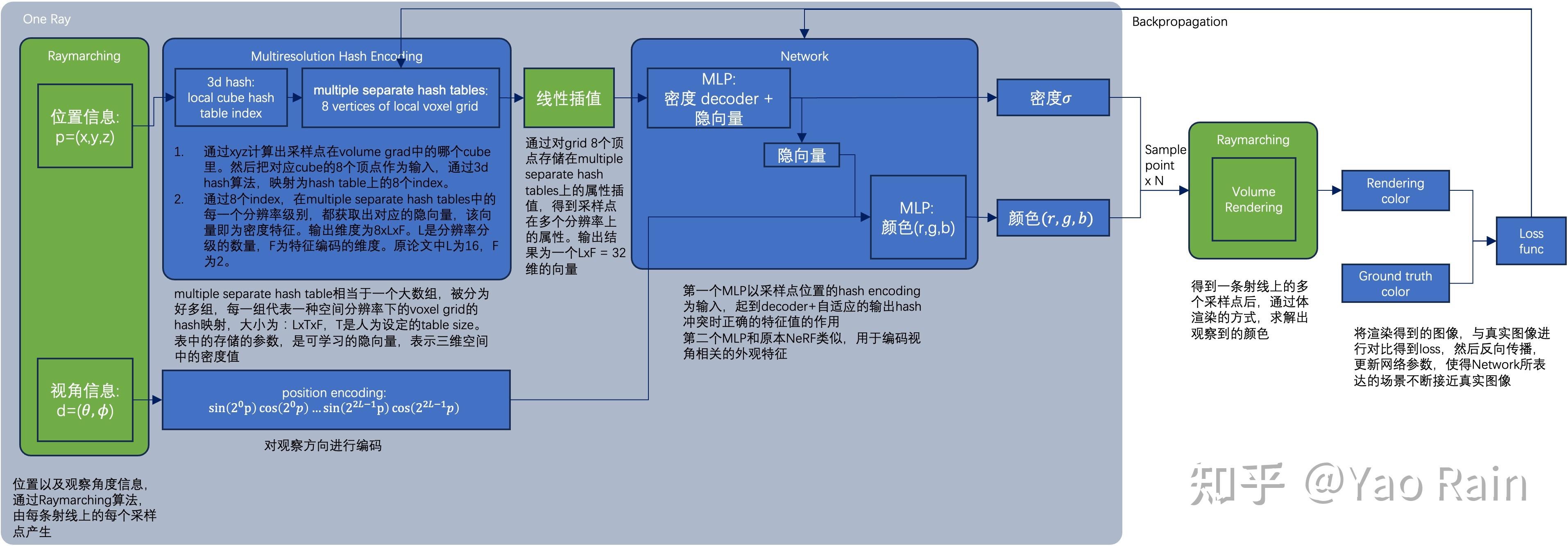
Instant-NGP和NeRF的异同:
- 同样基于体渲染
- 不同于NeRF的MLP,NGP使用稀疏的参数化的voxel grid作为场景表达;
- 基于梯度同时优化场景和MLP。(其中一个MLP用作decoder。)
整体的框架是一样的,最重要的不同是NGP选取了参数化的voxel grid作为场景表达。通过学习让voxel中保存的参数成为场景密度的形状。
MLP最大的问题就是慢,为了能高质量重建场景往往需要一个比较大的网络,每个采样点过一遍网络就会耗费大量时间。而在grid里插值就快得多。但是grid要表达高精度的场景就需要高密度的voxel,会造成极高的内存占用。考虑到场景中有很多地方是空白的,所以NVIDIA提出了一种稀疏的结构来表达场景。
Hashing of voxel grid
简单介绍voxel grid和它的hash table形式。
voxel可以认为是空间中的一个小立方体。voxel grid就可以想象成空间中一系列共用顶点的小正方体。这些小正方体的每个顶点就是一个voxel vertex。这个voxel可以保存任何信息,一般拿来保存一些只和位置有关的信息,比如密度和漫反射颜色。可以用一个三维数组来表示一个voxel grid:[N,N,N],也可以用一个N^3的一维表来表示。
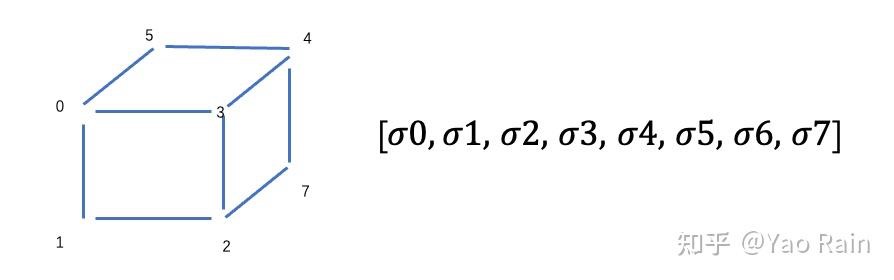
如上图左边就是一个N=2的voxel grid,如果按顺序给每个顶点一个index,然后把其中的密度值放入一个一维表对应的index中,就能得到一个voxel grid的table形式。如果顶点所对应的table中的index是通过hash算法得到的,那么这个一维表就是一个hash grid。具体用到的spatial hash function在此不细讲。
一般情况下,我们需要查询的点不会和grid的顶点重合。所以查询的时候,需要先找到采样的点在哪个小立方体内,然后再对立方体的八个顶点作插值来求解。
Multiresolution hash encoding
如果想要表达一个精细的场景,使用hash grid的时候,哈希表的大小往往是小于顶点数量的,这样就可能造成哈希冲突,表中的密度不知道应该表达哪个顶点的才好。为了避免这种情况,NGP提出了多分辨率哈希编码。
具体来说,把相同空间用不同大小的grid表达,比如从 16×16×16 到 512×512×512 的M个分辨率的grid。然后我们把hash table的大小T设成固定值,比如64×64×64,这样就得到了M个大小为T的hash table,这些表放在一起就是原文中的multiple separate hash tables。当grid超过64时就会冲突,最后的密度就是以不同权重混合每一个分辨率的grid的密度得到的。至于权重则是MLP通过loss学到的。
从输入输出的角度而言,多分辨率哈希编码最后会把一个(x,y,z)的位置信息转变成该位置上的multiple separate hash tables中的密度信息。输出一个L*F维的向量,作为网络的输入。L是总共有多少中不同的分辨率,F是每个顶点保存的密度特征编码的维度。之后MLP为该采样点每个分辨率上的密度分配权重,并做特征decode,得到最终的密度值。
Instant-NGP中的MLP
NGP中同样有两个MLP,一个是类似NeRF的外观网络,另一个则大为不同。
NGP中和密度相关的MLP,功能是把多分辨率哈希编码输出的采样点所对应的多个分辨率上的密度特征编码,按照不同的权重混合,同时做decode得到真正的密度值。
相比与NeRF中60维的MLP输入,NGP中只有32维,同时网络成熟少很多,是一个小型MLP,所以跑起来快很多。
小结
NGP 改进了图形学中已有的结构并应用到体渲染框架中,来加速从二维到三维的重建,并且其中使用的MLP和NeRF的功能完全不同。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











