







2. 基于邻域的算法
基于邻域的算法分为两大类,一是基于用户的协同过滤算法,二是基于物品的协同过滤算法。
2.1 基于用户的协同过滤算法
2.1.1 基础算法
- 基于用户的协同过滤算法
当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A。
主要包括两个步骤:
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
其中,步骤(1)的关键就是计算两个用户的兴趣相似度。
这里,协同过滤算法主要利用行为的相似度计算兴趣的相似度。
兴趣相似度
给定用户 u u u和用户 v v v,令 N ( u ) N(u) N(u)表示用户 u u u曾经有过正反馈的物品集合,令 N ( v ) N(v) N(v)为用户 v v v曾经有过正反馈的物品集合。那么, 计算 u u u和 v v v的兴趣相似度,
可以通过的 J a c c a r d Jaccard Jaccard公式:
W u v = ∣ N ( u ) ∩ N ( v ) ∣ ∣ N ( u ) ∪ N ( v ) ∣ W_{uv}=\frac {|N(u) \cap N(v)|}{|N(u) \cup N(v)|} Wuv=∣N(u)∪N(v)∣∣N(u)∩N(v)∣
或者通过余弦相似度:
W u v = ∣ N ( u ) ∩ N ( v ) ∣ ∣ N ( u ) ∣ ∣ N ( v ) ∣ W_{uv}=\frac {|N(u) \cap N(v)|}{\sqrt{|N(u)| |N(v)|}} Wuv=∣N(u)∣∣N(v)∣∣N(u)∩N(v)∣
以下图中的用户行为记录为例,UserCF计算用户兴趣相似度,展示如下:
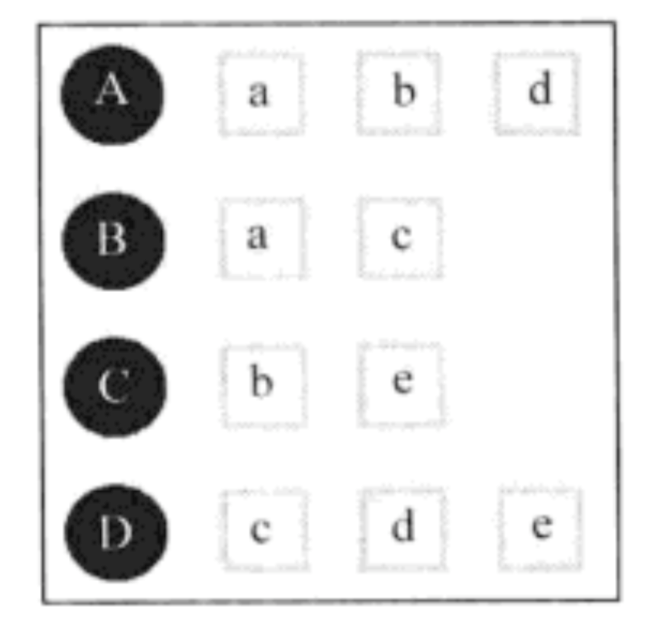
在该例中,用户A对物品 a , b , d {a,b,d} a,b,d有过行为,用户B对物品 a , c {a,c} a,c有过行为,利用余弦相似度公式计算用户A和用户B的兴趣相似度为:
W a b = { a , b , d } ∩ { a , c } ∣ { a , b , d } ∣ ∣ { a , c } ∣ = 1 6 W_{ab}=\frac {\{a,b,d\} \cap \{a,c\}}{\sqrt {|\{a,b,d\}| |\{a,c\}|}}=\frac {1}{\sqrt{6}} Wab=∣{a,b,d}∣∣{a,c}∣{a,b,d}∩{a,c}=61
若对两两用户都利用余弦相似度计算相似度,其时间复杂度是
O
(
∣
U
∣
∗
∣
U
∣
)
O(|U|*|U|)
O(∣U∣∗∣U∣),这在用户数很大时非常耗时。
事实上,很多用户相互之间并没有对同样的物品产生过行为,即,很多时候
∣
N
(
u
)
∩
N
(
v
)
∣
=
0
|N(u) \cap N(v)|=0
∣N(u)∩N(v)∣=0。
因此,可以先计算出
∣
N
(
u
)
∩
N
(
v
)
∣
≠
0
|N(u) \cap N(v)| \neq 0
∣N(u)∩N(v)∣=0的用户对
(
u
,
v
)
(u, v)
(u,v),然后再对这种情况除以分母
∣
N
(
u
)
∣
∣
N
(
v
)
∣
\sqrt{|N(u)| |N(v)|}
∣N(u)∣∣N(v)∣。
UserCF算法
- 思想
可以建立物品到用户的倒查表,对于每个物品都保存对该物品产生过行为的用户列表。
令稀疏矩阵
C
[
u
]
[
v
]
=
∣
N
(
u
)
∩
N
(
v
)
∣
C[u][v]=|N(u) \cap N(v)|
C[u][v]=∣N(u)∩N(v)∣,假设用户
u
u
u和用户
v
v
v同时属于倒查表中
K
K
K个物品对
应的用户列表,有
C
[
u
]
[
v
]
=
K
C[u][v]=K
C[u][v]=K。
从而,可以扫描倒查表中每个物品对应的用户列表,将用户列表中的两两用户对应的 C [ u ] [ v ] C[u][v] C[u][v]加1,最终就可以得到所有用户之间不为0的 C [ u ] [ v ] C[u][v] C[u][v]。
- 步骤及示例
(1) 建立物品-用户的倒排表(即,对于每个物品都保存对该物品产生过行为的用户列表,如下图所示)。
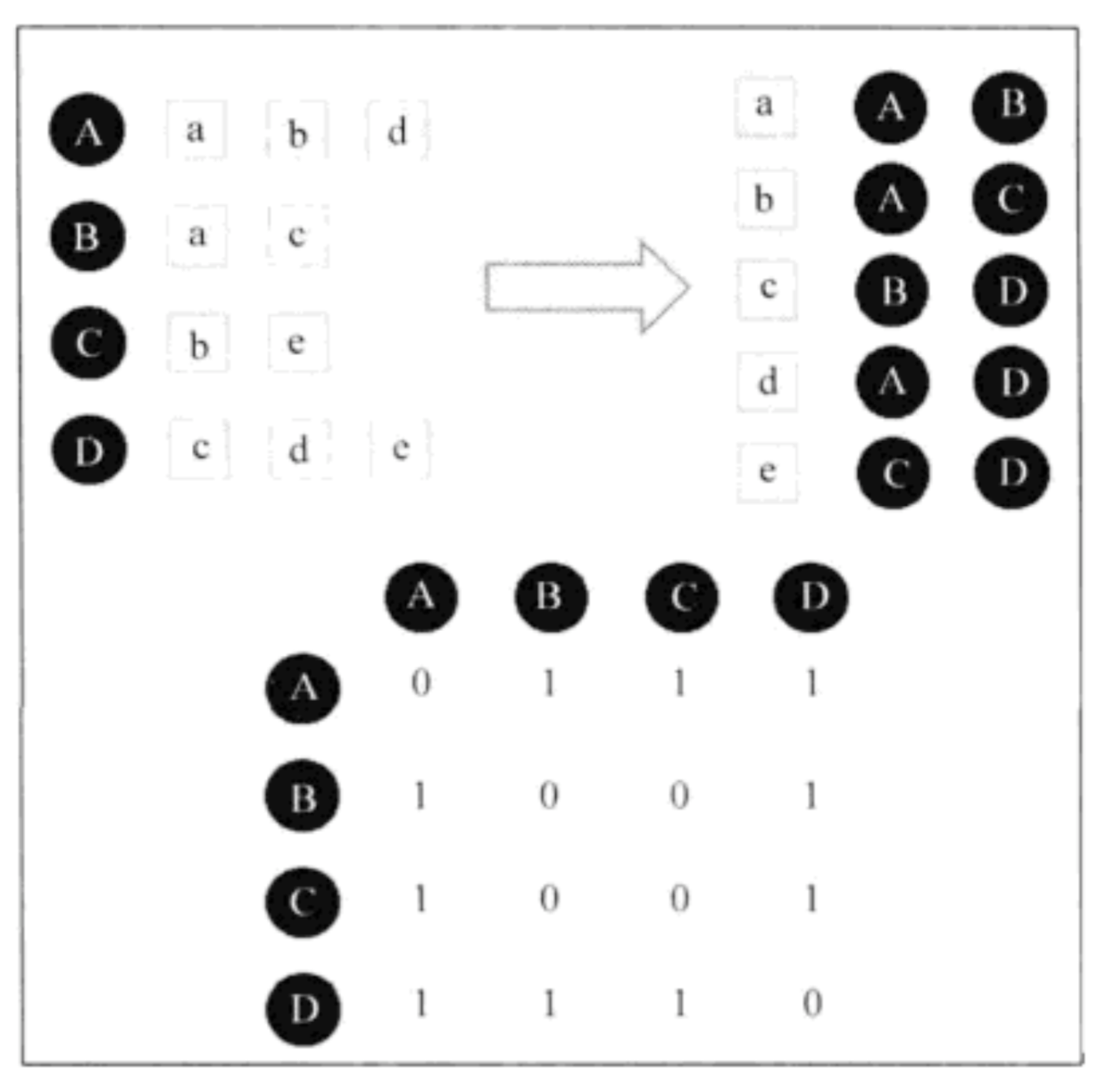
(2) 建立一个4×4的用户相似度矩阵
W
W
W。
对于物品
a
a
a,将
W
[
A
]
[
B
]
W[A][B]
W[A][B]和
W
[
B
]
[
A
]
W[B][A]
W[B][A]加1,以此类推。
扫描完所有物品后,可以得到最终的
W
W
W矩阵。此时,
W
W
W是余弦相似度中的分子部分。
(3) 将 W W W除以分母进而得到最终的用户兴趣相似度。
(4) 计算用户 u u u对物品 i i i的感兴趣程度,公式如下:
p ( u , i ) = ∑ v ∈ S ( u , K ) ∩ N ( i ) w u v r v i p(u,i)=\sum_{v \in S(u,K) \cap N(i)}w_{uv}r_{vi} p(u,i)=v∈S(u,K)∩N(i)∑wuvrvi
其中, S ( u , K ) S(u,K) S(u,K)包含和用户 u u u兴趣最接近的 K K K个用户, N ( i ) N(i) N(i)是对物品 i i i有过行为的用户集合, w u v w_{uv} wuv是用户 u u u和用户 v v v的兴趣相似度, r v i r_{vi} rvi代表用户 v v v对物品 i i i的兴趣。因为使用的是单一行为的隐反馈数据,所以所有的 r v i r_{vi} rvi=1。
(5) 给用户推荐和他兴趣最相似的 K K K个用户喜欢的物品。
结合上文中的示例,选取 K K K=3,用户A对物品 c c c、 e e e没有过行为,因此可以把这两个物品推荐给用户A。
根据UserCF算法, 用户A对物品c的兴趣是:
p ( A , c ) = W A B + W A D = 0.7416 p(A, c) =W_{AB}+W_{AD}=0. 7416 p(A,c)=WAB+WAD=0.7416
- 参数
参数 K K K是UserCF的一个重要参数,它的调整对推荐算法的各种指标都会产生一定的影响。
(1) 精确率和召回率
推荐系统的精度指标(精确率和召回率)并不和参数
K
K
K成线性关系。
选择合适的K对于获得高的推荐系统精度比较重要。
推荐结果的精度对K也不是特别敏感,只要选在一定的区域内,就可以获得不错的精度。
(2) 流行度
K
K
K越大则UserCF推荐结果越热门。
(3) 覆盖率
K
K
K越大则UserCF推荐结果的覆盖率越低。
2.1.2 用户相似度计算的改进
余弦相似度公式,是计算用户兴趣相似度最简单的公式。本节将讨论如何改进该公式,来提高UserCF的推荐性能。
思想:两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。
根据用户行为计算用户的兴趣相似度,改进公式如下:
W u v = ∑ i ∈ N ( u ) ∩ N ( v ) 1 l o g 1 + ∣ N ( i ) ∣ ∣ N ( u ) ∣ ∣ N ( v ) ∣ W_{uv}=\frac {\sum_{i \in \,N(u) \cap N(v)} \frac {1}{log1+|N(i)|}}{\sqrt{|N(u)| |N(v)|}} Wuv=∣N(u)∣∣N(v)∣∑i∈N(u)∩N(v)log1+∣N(i)∣1
由此可见,该公式通过 1 l o g 1 + ∣ N ( i ) ∣ \frac {1}{log1+|N(i)|} log1+∣N(i)∣1惩罚了用户 u u u和用户 v v v共同兴趣列表中热门物品对他们相似度的影响。
实验结果表名,在计算用户兴趣相似度时考虑物品的流行度,对提升推荐结果的质量确实有帮助。
参考
《推荐系统实践》—— 2.4.1 基于用户的协同过滤算法















 2031
2031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









