







1、概述
摘要:本案例主要围绕发生的一个热点"玲娜贝儿事件热搜"的评论,使用情感分析模型及数据挖掘技术进行可视化的数据分析。 案例使用jupyter进行开发,python3.6.x版本,利用python的pandas、matplotlib、numpy、wordcloud、sklearn等库实现。
提示:本文是基于我之前情感预测模型《SVM和朴素贝叶斯情感分析模型》实现的,所以在此之前需要各位小伙伴先去学习一下情感分析模型的实现哦~我们在这篇案例中就不在重复对模型详细讲解了,当然如果你在机器已经不是小白,可以跳过上篇文档直接学习下面案例哦~
关键词:python;情感分析;svm;朴素贝叶斯;机器学习;数据分析;
2、理论
机器学习朴素贝叶斯使用概率统计的知识对样本数据集进行分类,有着坚实的数据理论基础,且不容易发生过拟合现象适合大数据量的训练。在实际和svm对比使用中也发现朴素贝叶斯在训练10万条数据的训练速度非常快,且朴素贝叶斯的泛化能力大大强于SVM,这里泛化能力我想仔细说明一下,简单来说是朴素贝叶斯不光在同类型评论的训练集效果不错,在不同类别评论的数据的预测效果也非常准确。
对于SVM的理解,我们就不进行算法的深度剖析,我只进行通俗的解释,SVM算法如果在二维空间中,他就是去找一个线最优的去分割开二维中的点实现分类,在三维空间中,它就是找一个超平面去分割空间的点。(我尊重科学的严谨性,如有不准确请积极批评补充哦~)
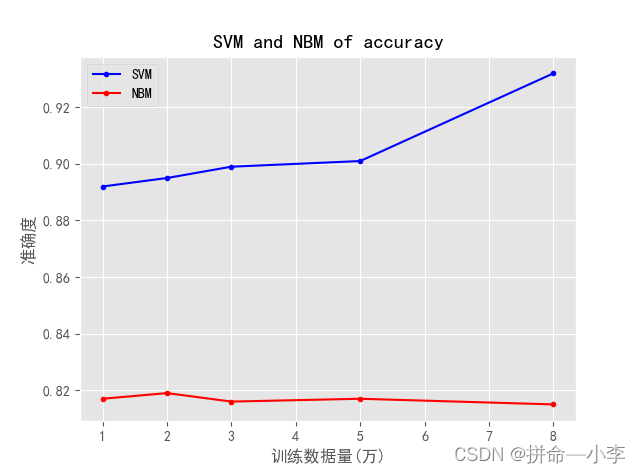
该图示利用两者算法分别对评论的数据进行训练随着训练数据量的增多,模型准确度的折线图。
3、实现
- 数据处理
下图是我们爬取玲娜贝儿热点评论数据:博主、该事件的文章内容、发布时间、转发数、点赞数、评论人、评论内容、评论时间、评论点赞数、是否认证等数据。
我们通过原始爬取数据发现有很多数据需要处理,例如时间以及评论内容等,我们需要将英文格式时间处理为右侧的时间格式。
| Sun Dec 05 22:56:48 +0800 2021 ====> 2021-12-05 22:00:00 |
import pandas as pd
import datetime
"""
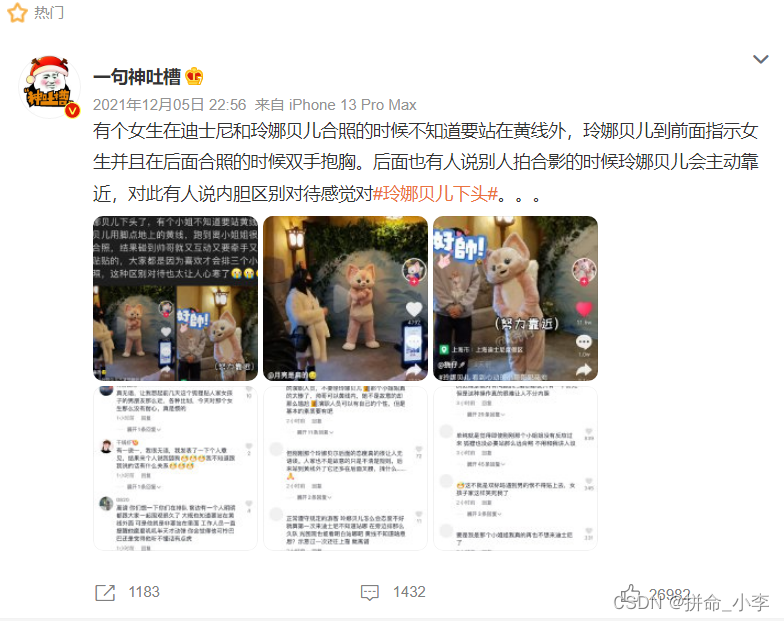
一句神吐槽
有个女生在迪士尼和玲娜贝儿合照的时候不知道要站在黄线外,
玲娜贝儿到前面指示女生并且在后面合照的时候双手抱胸。
后面也有人说别人拍合影的时候玲娜贝儿会主动靠近,对此有人说内胆区别对待感觉对#玲娜贝儿下头#。。。
"""
# 处理英文时间
def date_process(time):
time = time.replace('+0800 ','')
time_format = datetime.datetime.strptime(time,'%a %b %d %H:%M:%S %Y')
return datetime.datetime.strftime(time_format, '%Y-%m-%d %H:00:00')
def review_process(text):
return text.replace("回复","")
weibo = pd.read_excel("./weibo_吐槽.xlsx")
# 只选取第六列-第九列的数据
weibo = weibo.iloc[:,6:10]
# 清除空行数据
weibo = weibo.dropna()
weibo['评论时间'] = weibo['评论时间'].apply(date_process)
weibo['评论内容'] = weibo['评论内容'].apply(review_process)
weibo最终经过处理之后的数据转化为pandas的dataframe展示数据如下,对我们分析来说其实有意义的几个维度特征是:评论人、评论内容、时间、点赞数。

- 词云图可视化
我们读取文件评论内容使用python的词云图库wordcloud进行事件评论内容的一个词云图展示,其实就是把所有的评论字符串拼接丢到方法里就好了,很简单!
pip install wordcloud # 安装对应的词云图库
#生成词云
import wordcloud
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 将数组转化为字符串
word_show = ' '.join(weibo['评论内容'])
# msyh.ttc字体文件
w = wordcloud.WordCloud(font_path="msyh.ttc", width=1000, height= 700,background_color="white", max_words=100)
# 传入功能主治的字符串生成词云图
w.generate(word_show)
w.to_file("hot_word.jpg")
plt.figure(figsize=(8,8.5))
plt.imshow(w, interpolation='bilinear')
plt.axis('off')
plt.title('评论内容词云图', fontsize=30)
plt.show()
- 点赞Top5统计
使用sort_values(by='评论点赞数',ascending=False)方法实现top的统计,by是通过那个属性列进行sort,ascending是否是生序。
review_top = weibo.sort_values(by='评论点赞数',ascending=False)[0:5]
review_top = review_top.loc[:,['评论人','评论点赞数']]
review_top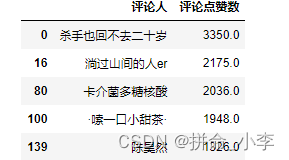
我们使用python的matplotlib可视化库对其进行展示top可视化展现
plt.barh([1,2,3,4,5], list(review_top['评论点赞数']) ,tick_label = list(review_top['评论人']),color='#0BF92E')
plt.xlabel('点赞数')
plt.ylabel('评论人')
plt.title('点赞数TOP5')
plt.tight_layout()
plt.show()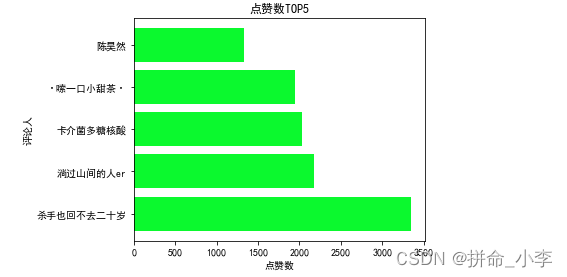
- 情感分析统计
我们使用之前训练好的svm和朴素贝叶斯模型(任选其一),对评论内容进行情感分析预测,模型就是直接使用我们之前文章已经训练好的直接进行预测。然后我们队预测结果进行一个饼图的可视化展示。
import re
import jieba_fast as jieba
from sklearn.externals import joblib
# 获取停用词列表
def get_custom_stopwords(stop_words_file):
with open(stop_words_file,encoding='utf-8') as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
# 去除停用词方法
def remove_stropwords(mytext,cachedStopWords):
return " ".join([word for word in mytext.split() if word not in cachedStopWords])
# 处理否定词不的句子
def Jieba_Intensify(text):
word = re.search(r"不[\u4e00-\u9fa5 ]",text)
if word!=None:
text = re.sub(r"(不 )|(不[\u4e00-\u9fa5]{1} )",word[0].strip(),text)
return text
# 判断句子消极还是积极
def IsPoOrNeg(text):
# 加载训练好的模型
# model = joblib.load('tfidf_nb_sentiment.model')
model = joblib.load('tfidf_svm1_sentiment.model')
# 获取停用词列表
cachedStopWords = get_custom_stopwords(".\\stopwords.txt")
# 去除停用词
text = remove_stropwords(text,cachedStopWords)
# jieba分词
seg_list = jieba.cut(text, cut_all=False)
text = " ".join(seg_list)
# 否定不处理
text = Jieba_Intensify(text)
y_pre =model.predict([text])
proba = model.predict_proba([text])[0]
if y_pre[0]==1:
# print(text,":此话极大可能是积极情绪(概率:)"+str(proba[1]))
return "积极"
else:
# print(text,":此话极大可能是消极情绪(概率:)"+str(proba[0]))
return "消极"
weibo['标签'] = None
weibo['标签'] = weibo['评论内容'].apply(IsPoOrNeg)
weibo['标签'].value_counts()
lable = list(dict(weibo['标签'].value_counts()).keys())
value = list(weibo['标签'].value_counts())
explode=[0.01,0.01]
plt.figure(figsize=(6, 6))
plt.pie(value,explode=explode,labels=lable,autopct='%1.1f%%')#绘制饼图
plt.title('时间积极消极态度')
plt.show()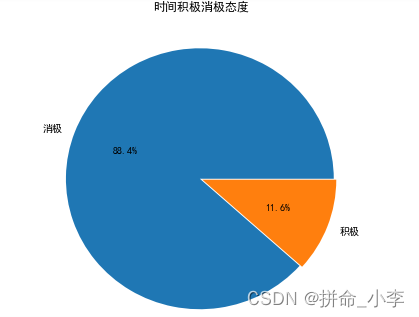
- 时间爆发点可视化
# 过滤掉数量小于3的数据
date_seris = date_seris[date_seris > 3]
print(date_seris)
date_dict = dict(date_seris)
date_keys = list(date_dict.keys())
date_value = list(date_dict.values())
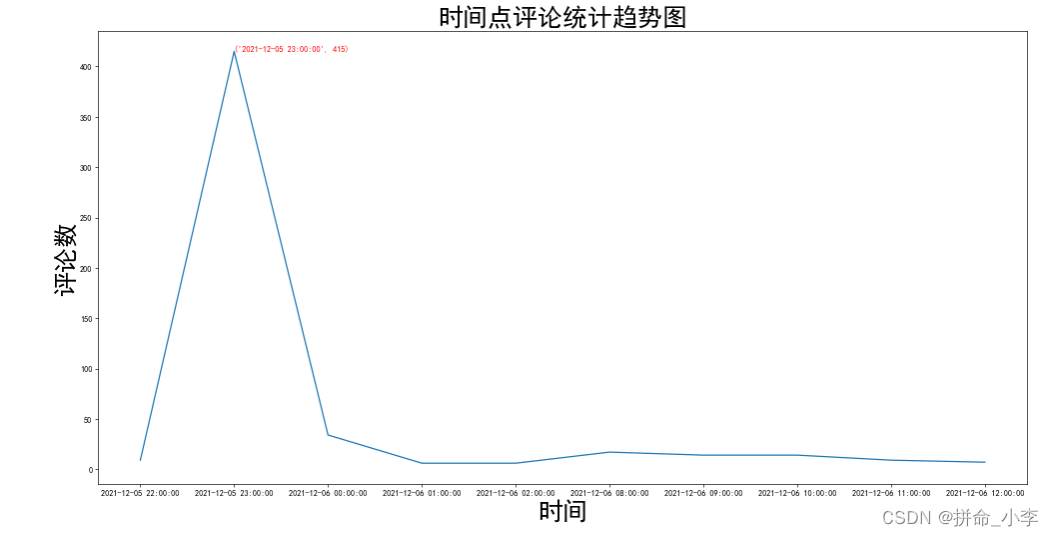
plt.figure(figsize=(20,10),dpi=60)
plt.plot(date_keys,date_value)
plt.xlabel('时间',fontsize=30)
plt.ylabel('评论数',fontsize=30)
value_max = max(date_value)
key_max = date_keys[date_value.index(value_max)]
plt.text(key_max,value_max,(key_max,value_max),color='r')
plt.title('时间点评论统计趋势图',fontsize=30)
plt.show()可以看到热点在2021-12-05 23:00:00的时间点评论是最多的,可见该事件点是事件的爆发点,之后时间段趋于平稳。
来个三连吧!



















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











