







 本文描述了一套基于Python开发的微博舆情分析系统,旨在提高工作效率和用户便利性。系统包括热搜数据管理、类搜索引擎和热点词统计等功能,实现了信息管理的自动化和规范化,简化了用户操作。通过管理员模块,可以查看和管理数据。系统经过测试,性能良好,后续将根据用户反馈持续优化升级。
本文描述了一套基于Python开发的微博舆情分析系统,旨在提高工作效率和用户便利性。系统包括热搜数据管理、类搜索引擎和热点词统计等功能,实现了信息管理的自动化和规范化,简化了用户操作。通过管理员模块,可以查看和管理数据。系统经过测试,性能良好,后续将根据用户反馈持续优化升级。
背景分析
随着互联网大趋势的到来,社会的方方面面,各行各业都在考虑利用互联网作为媒介将自己的信息更及时有效地推广出去,而其中最好的方式就是建立网络管理系统,并对其进行信息管理。由于现在网络的发达,微博舆情分析系统的资讯信息通过网络进行信息管理掀起了热潮,所以针对微博舆情分析系统的用户需求开发出一套微博舆情分析系统。
整个开发过程首先对软件系统进行需求分析,得出系统的主要功能。接着对系统进行总体设计和详细设计。总体设计主要包括系统功能设计、系统总体结构设计、系统数据结构设计和系统安全设计等;详细设计主要包括系统数据库访问的实现,主要功能模块的具体实现,模块实现关键代码等。最后对系统进行功能测试,并对测试结果进行分析总结,得出系统中存在的不足及需要改进的地方,为以后的系统维护提供了方便,同时也为今后开发类似系统提供了借鉴和帮助。
本系统开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与微博舆情分析系统的实际需求相结合,确定了Python开发微博舆情分析系统的使用。
需求分析
微博舆情分析系统主要是为了提高工作人员的工作效率和更方便快捷的满足用户,更好存储所有数据信息及快速方便的检索功能,对系统的各个模块是通过许多今天的发达系统做出合理的分析来确定用户的可操作性,遵循开发的系统优化的原则,经过全面的调查和研究。系统所要实现的功能分析,对于现在网络方便的管理,系统要实现用户可以直接在平台上进行查看所有数据信息,根据需求可以进行在线添加,删除或修改微博舆情分析系统信息,微博舆情分析系统的开发不仅仅是能满足用户的需求,还能提高管理员的工作效率,减少原有不必要的工作量。
开发目标
微博舆情分析系统的主要开发目标如下:
(1)实现管理系统信息关系的系统化、规范化和自动化;
(2)减少维护人员的工作量以及实现用户对信息的控制和管理;
(3)方便查询信息及管理信息等;
(4)通过网络操作,改善处理问题的效率,提高操作人员利用率;
(5)考虑到用户多样性特点,要求界面简单,操作简便。
系统结构与实现
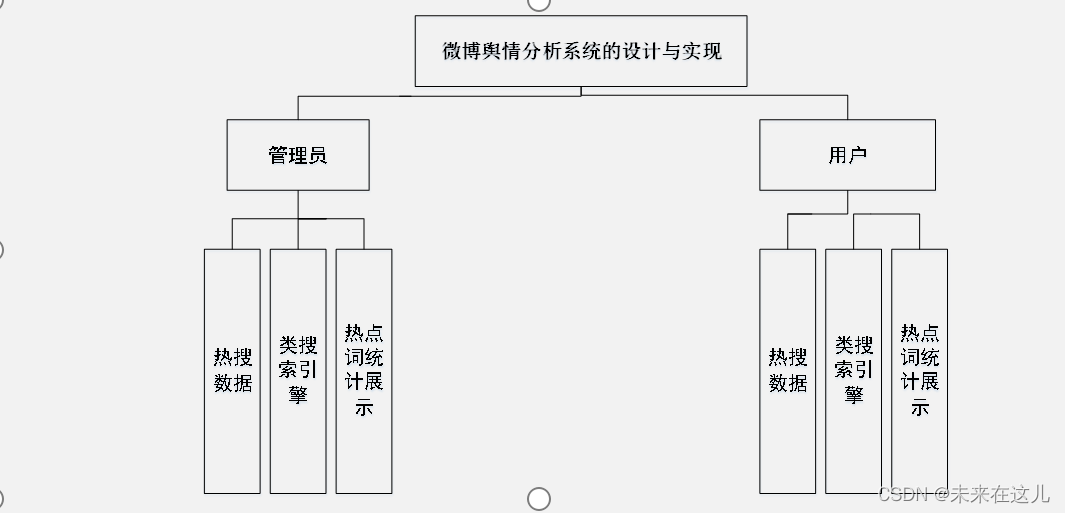
管理员功能模块
管理员登录进入微博舆情分析系统可以查看热搜数据、类搜索引擎、热点词统计展示等内容
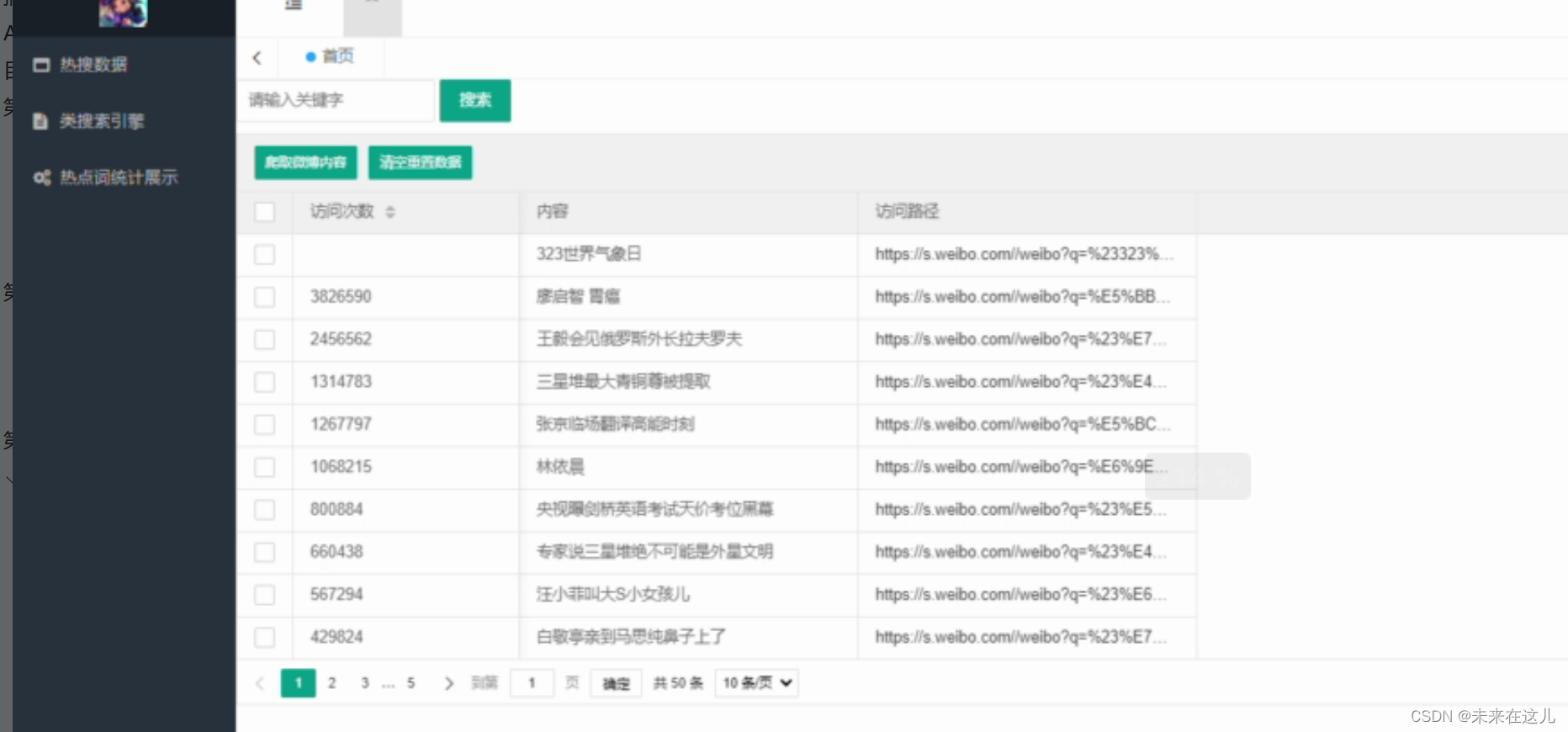
热搜数据,在热搜数据页面可以通过输入关键字可以搜索相关热搜,并根据需要清空重置数据
热搜,通过点击爬取微博内容,系统自动爬取微博内容,点击访问路径后会出现热搜微博。
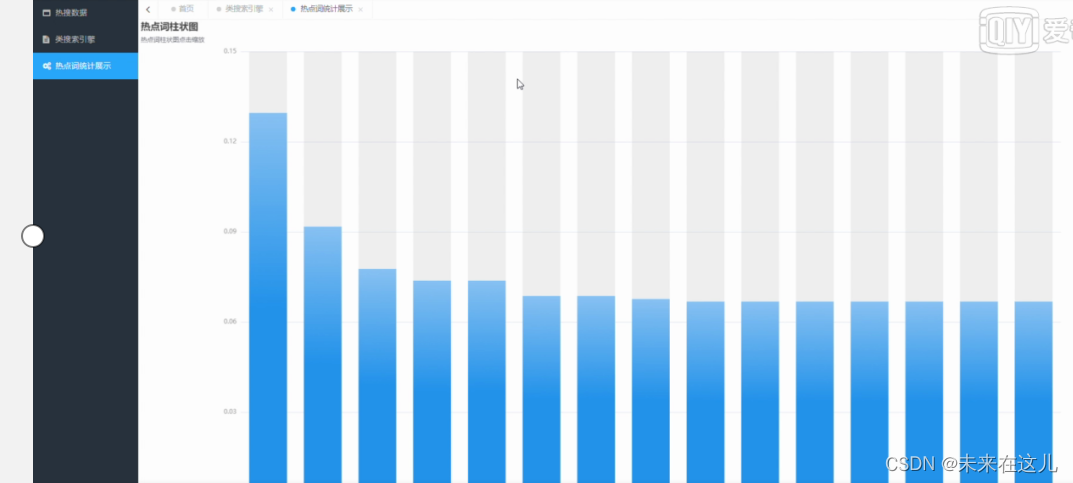
热点词统计,在热点词统计页面可以查看热点词语的柱状图
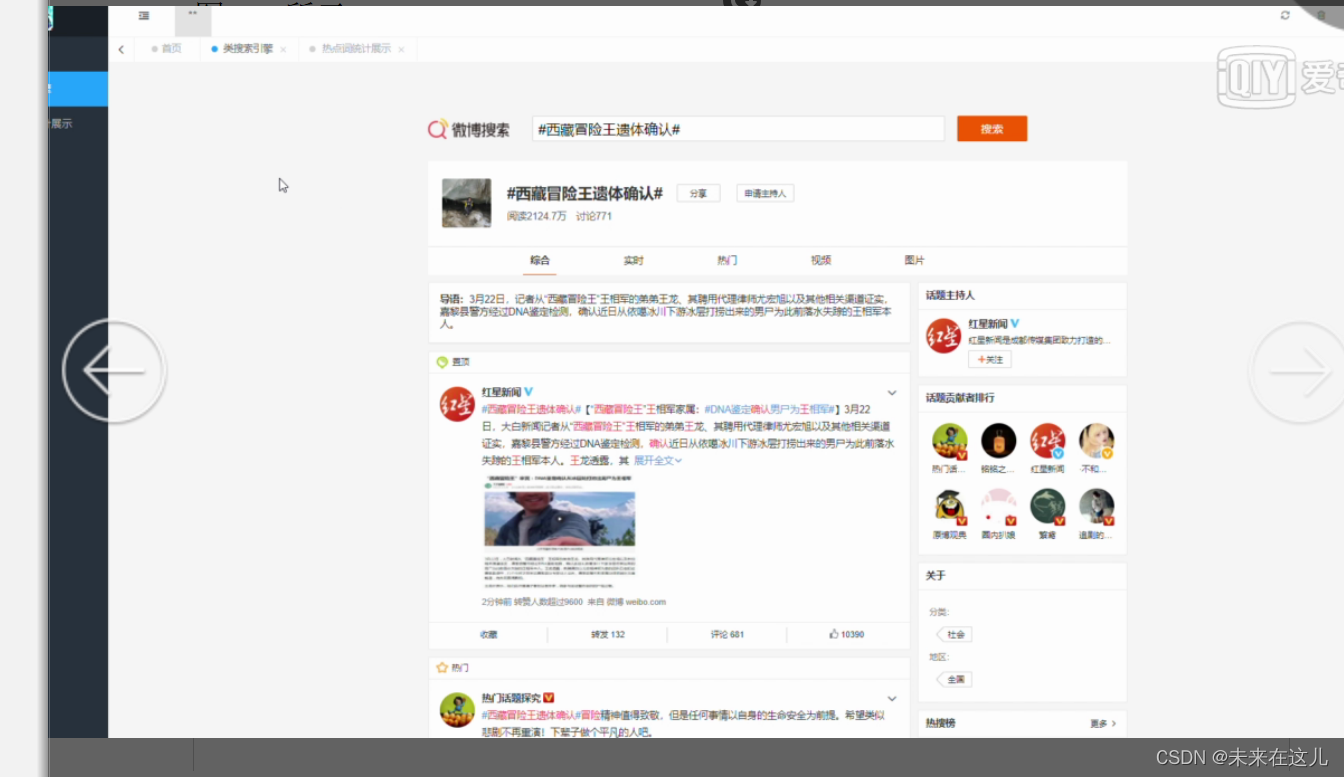
类搜索引擎,在类搜索引擎页面通过输入关键字进行搜索,会出现和关键字有关的微博内容、访问次数、访问路径等内容。热点微博,通过类搜索引擎后,点击访问路径,会出现相关热点微博
样例代码
from flask import Flask
from flask import request,render_template
app = Flask(__name__)
from spider.spiderObtain import xlSpider
from analyze.analyze import analyze
from api.htmlAPI import htmlAPI
from hotword.hotword import hotwords
app.register_blueprint(xlSpider,url_prefix='/xlSpider')
app.register_blueprint(analyze,url_prefix='/analyze')
app.register_blueprint(hotwords,url_prefix='/hotwords')
app.register_blueprint(htmlAPI,url_prefix='/api')
app.config['JSON_AS_ASCII'] = False
@app.route('/')
def indexHtml():
return render_template("index.html")
if __name__ == '__main__':
app.run()
总结
经过对一系列测试结果的有效分析,本平台开发系统符合用户的要求和需求。所有的基本功能相对齐全,操作起来简单方便,测试系统性能良好,作为大众化系统使用是比较值得推广宣传的。后续我们的微博舆情分析系统收到了大量用户反馈,通过不断优化和升级,系统的稳定性和准确性得到了进一步提高。在分析中,我们发现用户对某些热点事件的情绪波动较大,需要更加敏锐地捕捉用户情感变化,以便更好地为用户提供服务。同时,我们也发现了一些有趣的数据趋势,例如某些话题的热度在特定时间段内会有明显的增长或下降。我们将继续努力改进系统,为用户提供更加精准、实用的分析报告,同时也会不断关注用户反馈,不断完善我们的服务。感谢大家对我们的支持和信任,我们将继续为您提供最优质的微博舆情分析服务。
资源地址:https://download.csdn.net/download/weishuai90/87656893



















 3915
3915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











