






目录
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
目标:获取微博社会栏目热点数据
一、用Requests获取网页源码
1.1 过程分析
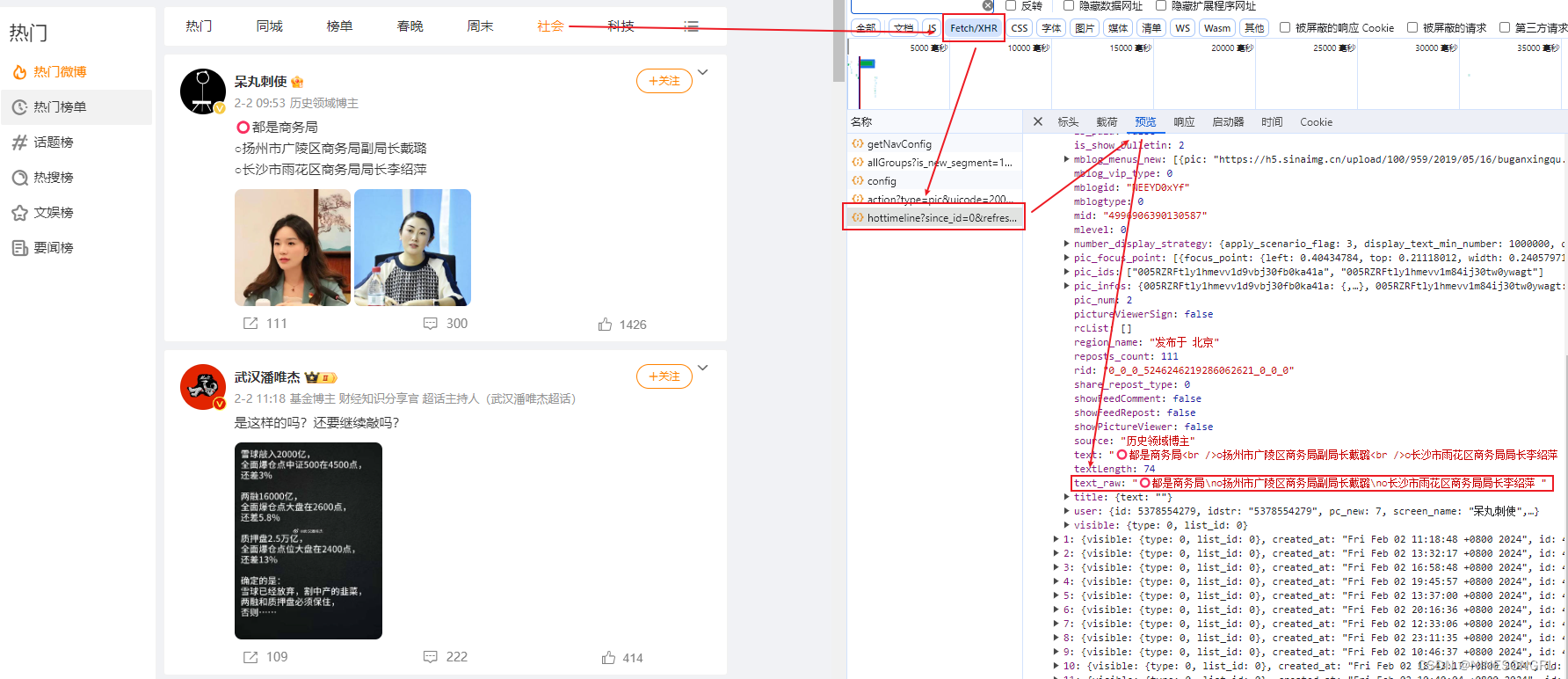
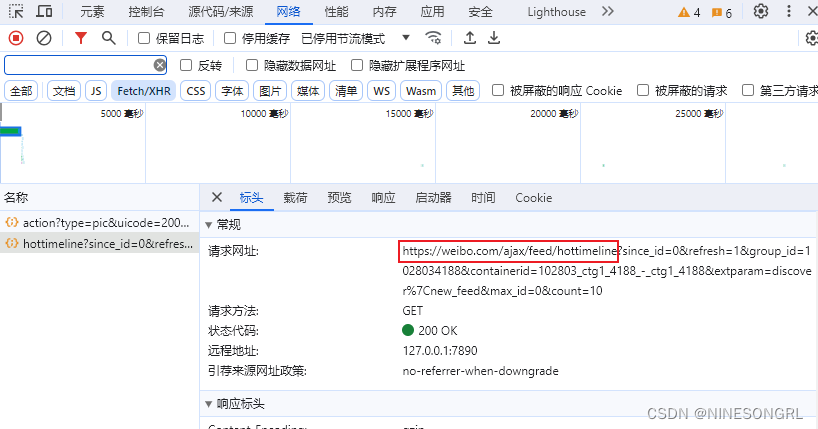
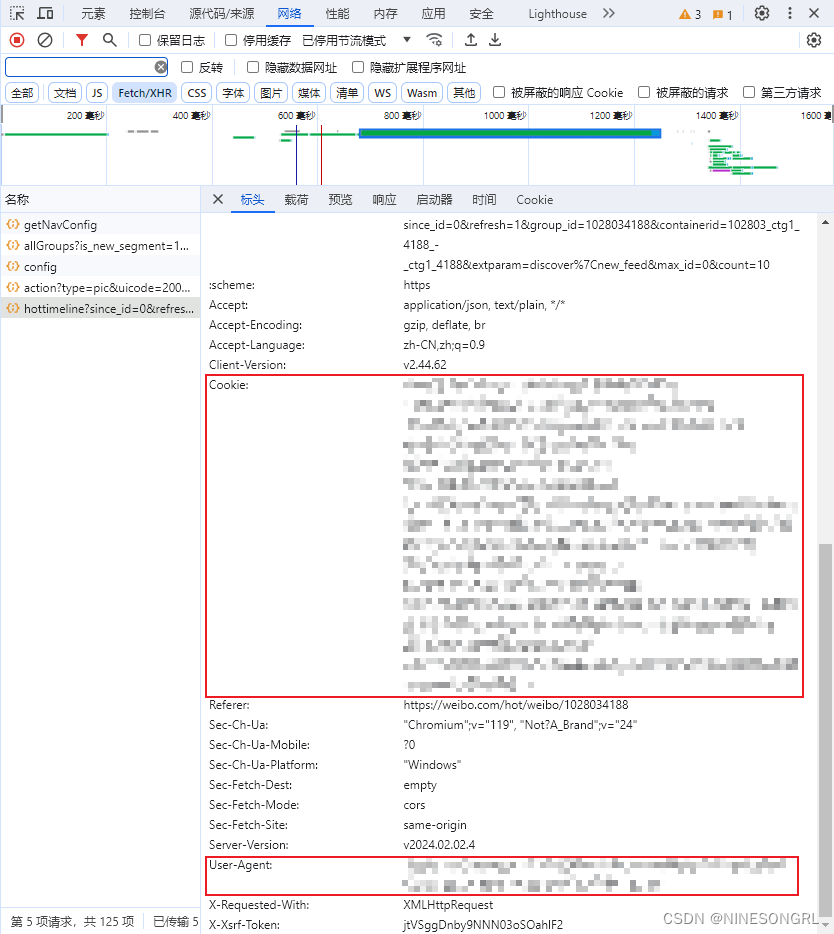
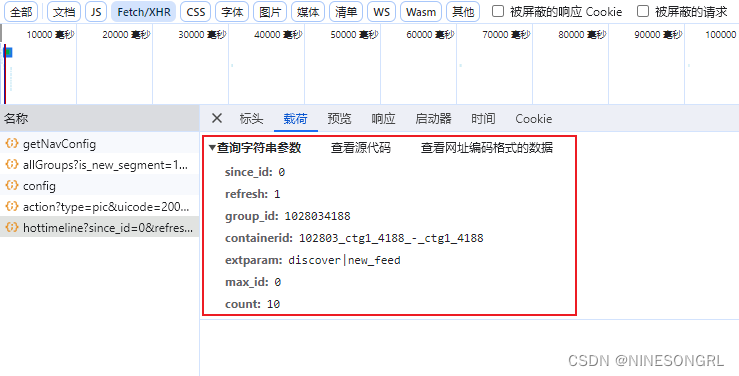
首先定位到要爬取的网站链接,通过F12打开控制台,找到请求包列表查看预览,定位到所需数据所在的具体请求包,找到待爬取网页的url(标头)、参数列表(载荷)、用户Cookie和Agent(标头)。
- url:网页地址,地址中?号后的部分为参数,可以通过调整参数(删改测试)明确网页固定参数和可变参数,固定参数可以直接写入url,非固定参数需要通过params参数来控制。
- 参数列表:表示当前网页的参数设置
- 用户Cookie和Agent:浏览器标识,用于request请求中模拟浏览器活动
比如现在要爬取微博热点数据:
1.2 代码演示
获取到这些信息后,就可以开始写request请求获取网页的数据源码,如下:
import requests
import csv
import numpy as np
import os
import time
from datetime import datetime
articalUrl = 'https://weibo.com/ajax/feed/hottimeline'
headers={
'Cookie' : '...',
'User-Agent': '...'
}
# 此为社会热点页面参数
params = {
'group_id':'1028034188',
'containerid':'102803_ctg1_4188_-_ctg1_4188',
'max_id':0,
'count':20,
'extparam':'discover|new_feed'
}
# response得到get后的数据源码
response = requests.get(articalUrl,headers = headers,params = params)二、网页解析与数据存储
2.1 网页解析
可以观察到,我们所需的各类数据,都在statuses模块的分组内,以此不断切分出所需数据并导入目标文件即可:

2.2 代码演示
def get_data(url,params):
headers={
'Cookie' : '...',
'User-Agent': '...'
}
response = requests.get(url,headers = headers,params = params)
if response.status_code == 200: # “200”标识代表GET请求成功
return response.json()['statuses'] # 此处直接提取出statuses中的内容
else:
print('出错了')
return None
# 切分数据
def parse_json(response):
for artice in response:
id = artice['id']
LikeNum = artice['attitudes_count']
commentsLen = artice['comments_count']
reposts_count = artice['reposts_count']
try:
region=artice['region_name'].replace('发布于 ','')
except:
region = '无'
content = artice['text_raw']
contentLen = artice['textLength']
created_at = datetime.strptime(artice['created_at'],'%a %b %d %H:%M:%S %z %Y').strftime('%Y-%m-%d %H:%M:%S')
try:
detailUrl = 'https://weibo.com/'+ str(artice['id']) + '/' + str(artice['mblogid'])
except:
detailUrl = '无'
authorName = artice['user']['screen_name']
authorAvatar = artice['user']['avatar_large']
authorDetail = 'https://weibo.com/u/' + str(artice['user']['id'])
writerRow([
# id,
# LikeNum,
# commentsLen,
# reposts_count,
# region,
# content,
# contentLen,
# created_at,
# type,
# detailUrl,
# authorAvatar,
# authorDetail
content # 此处只爬取内容,可以修改
])三、完整代码
file_path = './articaleData'
def init():
if not os.path.exists(file_path):
with open(file_path,'w',encoding='utf-8',newline='') as csvFile:
writer = csv.writer(csvFile)
writer.writerow([
'id',
'likeNum',
'commentsLen',
'reposts_count',
'region',
'content',
'contentLen',
'created_at',
'detailurl',
'authorAvatar',
'authorName',
'authorDetail',
])
def writerRow(row):
with open(file_path,'a',encoding='utf-8',newline='') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(row)
def get_data(url,params):
headers={
'Cookie' : '...',
'User-Agent': '...'
}
response = requests.get(url,headers = headers,params = params)
if response.status_code == 200:
return response.json()['statuses']
else:
print('出错了')
return None
def parse_json(response):
for artice in response:
id = artice['id']
LikeNum = artice['attitudes_count']
commentsLen = artice['comments_count']
reposts_count = artice['reposts_count']
try:
region=artice['region_name'].replace('发布于 ','')
except:
region = '无'
content = artice['text_raw']
contentLen = artice['textLength']
created_at = datetime.strptime(artice['created_at'],'%a %b %d %H:%M:%S %z %Y').strftime('%Y-%m-%d %H:%M:%S')
try:
detailUrl = 'https://weibo.com/'+ str(artice['id']) + '/' + str(artice['mblogid'])
except:
detailUrl = '无'
authorName = artice['user']['screen_name']
authorAvatar = artice['user']['avatar_large']
authorDetail = 'https://weibo.com/u/' + str(artice['user']['id'])
writerRow([
# id,
# LikeNum,
# commentsLen,
# reposts_count,
# region,
# content,
# contentLen,
# created_at,
# detailUrl,
# authorAvatar,
# authorDetail
content
])
def start(pageNum = 10):
articalUrl = 'https://weibo.com/ajax/feed/hottimeline'
init()
for page in range(0,pageNum):
print('正在爬取的类型: %s 中的第%s页文章数据'%('社会',page +1))
parmas = {
'group_id':'1028034188',
'containerid':'102803_ctg1_4188_-_ctg1_4188',
'max_id':page,
'count':20,
'extparam':'discover|new_feed'
}
response = get_data(articalUrl,parmas)
parse_json(response)
print('爬取完毕!')
if __name__ == "__main__":
start()















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









