







Hadoop组件
Mapreduce
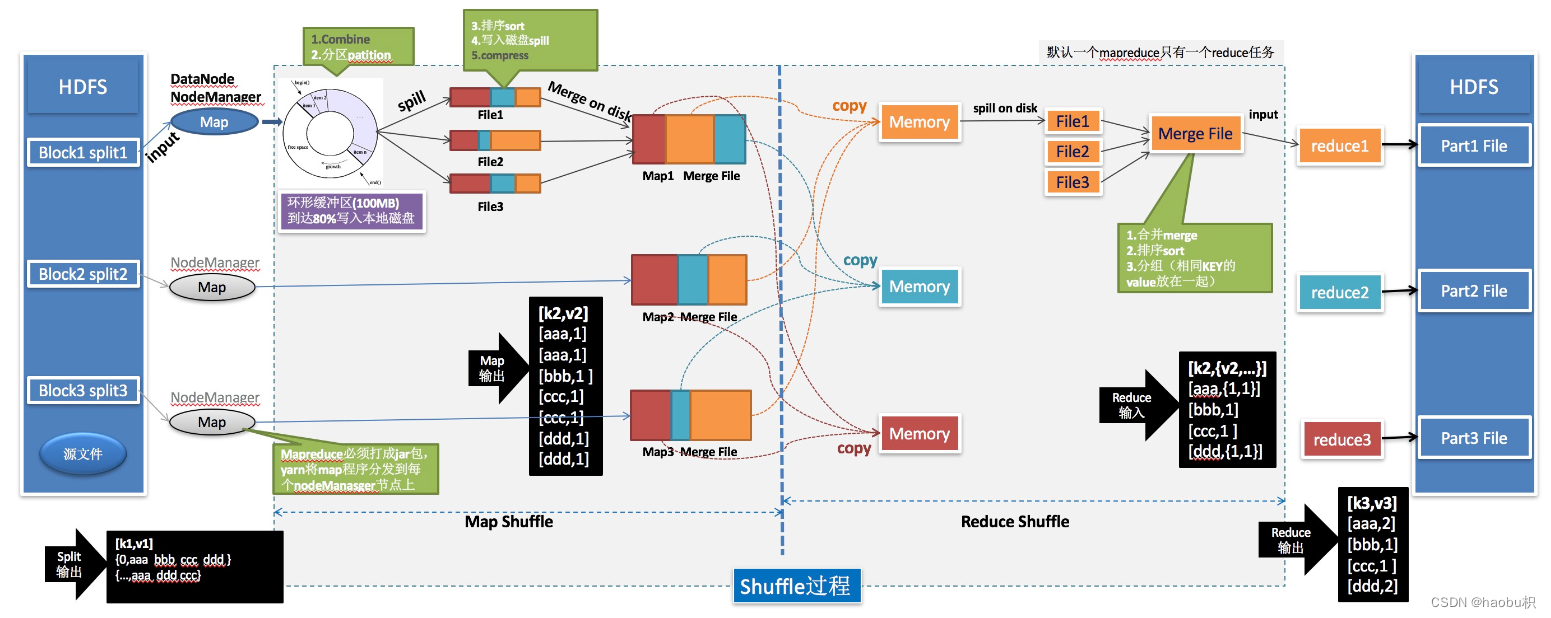
mapreduce详细流程
- 准确待处理文件
- submit对原始文件进行切片分析
- 提交(job切片,jar包,xml文件),对集群进行提交
- 计算maptask数量:客户端向yarn提交后,yarn开启一个mrappmaster任务,会根据切片个数,开启对应数量的maptask
- maptask启动:通过inputformat来读取文件
- 逻辑运算:数据读取完成后,将数据交给mapper完成业务逻辑代码,通过outputcollector向环形缓冲器写入<k,v>数据
- 分区排序溢写:当数据写入到环形缓冲区时,利用快速排序算法对缓冲区内的数据进行排序,先按照分区编号进行排序,再按照key进行排序,经过排序之后,数据以分区为单位聚集在一起
- merge阶段:当所有数据处理完后,map task对所有临时文件进行一次合并,确保最终生成一个数据文件。maptask以分区为单位进行合并,归并排序所有溢写文件。
- copy阶段:reducetask从各个maptask上拷贝一片数据,
- sort阶段:为了将key相同的数据聚集起来,因为map task已经实现了局部排序,然后reducetask就只对数据进行一次归并排序
- reduce阶段:reduce函数将计算结果写到hdfs上
mapreduce过程中的三次排序
在MapReduce的shuffle过程中通常会执行三次排序,分别是:
- Map输出阶段(溢写阶段):根据分区以及key进行快速排序
- Map的合并溢写文件:将同一个分区的多个溢写文件进行归并排序,合成大的溢写文件
- Reduce输入阶段:将同一分区,来自不同Map task的数据文件进行归并排序
- 最后阶段:使用了堆排作最后的合并过程。
map和reduce的数量
- map数量
map的数量通常是由hadoop集群的DFS块大小确定的,也就是输入文件的总块数,正常的map数量的并行规模大致是每一个Node是10~100个,对于CPU消耗较小的作业可以设置Map数量为300个左右,但是由于hadoop的每一个任务在初始化时需要一定的时间,因此比较合理的情况是每个map执行的时间至少超过1分钟。具体的数据分片是这样的,InputFormat在默认情况下会根据hadoop集群的DFS块大小进行分片,每一个分片会由一个map任务来进行处理,当然用户还是可以通过参数mapred.min.split.size参数在作业提交客户端进行自定义设置。还有一个重要参数就是mapred.map.tasks,这个参数设置的map数量仅仅是一个提示,只有当InputFormat
决定了map任务的个数比mapred.map.tasks值小时才起作用。同样,Map任务的个数也能通过使用JobConf
的conf.setNumMapTasks(intnum)方法来手动地设置。这个方法能够用来增加map任务的个数,但是不能设定任务的个数小于Hadoop系统通过分割输入数据得到的值。当然为了提高集群的并发效率,可以设置一个默认的map数量,当用户的map数量较小或者比本身自动分割的值还小时可以使用一个相对交大的默认值,从而提高整体hadoop集群的效率。 - reduc数量
reduce在运行时往往需要从相关map端复制数据到reduce节点来处理,因此相比于map任务。reduce节点资源是相对比较缺少的,同时相对运行较慢,正确的reduce任务的个数应该是0.95或者1.75*(节点数×mapred.tasktracker.tasks.maximum参数值)。如果任务数是节点个数的0.95倍,那么所有的reduce任务能够在map任务的输出传输结束后同时开始运行。如果任务数是节点个数的1.75倍,那么高速的节点会在完成他们第一批reduce任务计算之后开始计算第二批reduce任务,这样的情况更有利于负载均衡。同时需要注意增加reduce的数量虽然会增加系统的资源开销,但是可以改善负载匀衡,降低任务失败带来的负面影响。同样,Reduce任务也能够与map任务一样,通过设定JobConf 的conf.setNumReduceTasks(int num)方法来增加任务个数。
map join vs reduce join
- map join:在提交作业的时候先将小表放在该作业的DistributedCache中比如放在Hashmap等容器中,然后join的时候取出,然后扫描大表,看大表中每条记录的join key/value值是否能在在内存中找到相同的join key的记录,如果有则直接输出结果。
- reduce join:在map阶段,map函数同时读取两个文件,然后为了区分两个文件来源的key/value分别打上标签。然后在reduce阶段,reduce函数获取key相同来自两个文件的value list,然后对两个文件的数据进行join。(笛卡尔乘积)
HBASE工作流程
写入流程
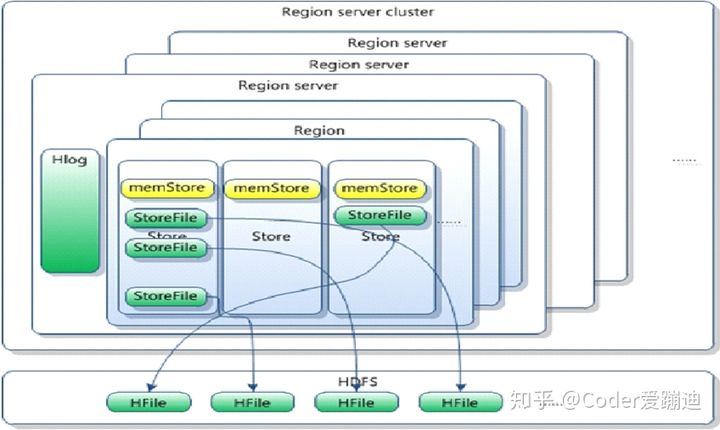
1、Client访问zookeeper,获取元数据存储所在的regionserver
2、拿到对应的表存储的regionserver,通过刚刚获取的地址访问对应的regionserver,
3、去表所在的regionserver进行数据的添加
4、查找对应的region,在region中寻找列族,把数据分别写到Hlog和memstore各一份
5、当memstore写入的值变多,触发溢写操作(flush),进行文件的溢写,成为一个StoreFile
6、当溢写的文件过多时,会触发文件的合并(Compact)操作。合并有两种方式(major,minor)多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除
minor compaction:小范围合并,默认是3-10个文件进行合并,不会删除其他版本的数据。
major compaction:将当前目录下的所有文件全部合并,一般手动触发,会删除其他版本的数据(不同时间戳的)
7、当region中的数据逐渐变大之后,达到某一个阈值,会进行裂变(一个region等分为两个region,并分配到不同的regionserver),原本的Region会下线,新Split出来的两个Region会被HMaster分配到相应HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。
读过程
1.Client访问zookeeper,获取元数据存储所在的regionserver
2.通过刚刚获取的地址访问对应的regionserver,拿到对应的表存储的regionserver
3.去表所在的regionserver进行数据的读取
4.查找对应的region,在region中寻找列族,先找到memstore,找不到去blockcache中寻找,再找不到就进行storefile的遍历
5.找到数据之后会先缓存到blockcache中,再将结果返回.blockcache逐渐满了之后,会采用LRU的淘汰策略。
补充
在HBase中,BlockCache是一种读缓存。HBase会将一次文件查找的Block块缓存到Cache中,以便后续同一请求或者邻近数据查找请求直接从内存中获取,避免昂贵的IO操作。如果需要缓存的数据超过堆大小的情况下,推荐使用Block Cache下的off-heap。Off-heap是指堆外内存,不由GC管理,但可以通过full GC回收,通过-XX:MaxDirectMemorySize设置大小。
当scan获取数据时,可以通过setCacheBlocks方法来设置是否使用block cache,对于频繁访问的行才建议使用block cache。
对于MapReduce的Scan作为输入任务,应该设置为setCacheBlocks(false)以避免在MapReduce期间使用BlockCache。这是因为BlockCache是HBase的读缓存,保存着最近被访问的数据块。在MapReduce期间,由于大量的数据读取,BlockCache会被填满,导致缓存失效,从而导致性能下降。
.HStore存储是HBase存储的核心,其中由两部分组成,一部分是Memstore,一部分是StoreFile。
.HLog的的功能: 宕机数据恢复
在分布式系统环境中,我们是无法避免系统出错或者宕机的,一旦HRegionServer意外退出,MemStore中的内存数据就会丢失,而引入HLog就是为了防止这种情况。
工作机制:每个HRegionServer中都会有一个HLog对象,HLog是一个实现Write Ahead Log的类,每次用户操作写入Memstore的同时,也会写一份数据到HLog文件中,HLog文件定期会滚动出新,并删除旧的文件(已持久化到Storefile中的数据),当HRegionServer意外终止后,HMaster会通过Zookeeper感知,HMaster首先处理遗留的HLog文件,将不同region的log数据拆分,分别放在相应region目录下,然后再将失效的region(带有刚刚拆分的log)重新分配,领取到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到Memstore中,然后flush到StoreFile,完成数据恢复。
.Region就是StoreFiles,StoreFiles里由HFile构成,HFile里由hbase的data块构成,一个data块里面又有很多的keyvalue对,每个keyvalue里存了我们需要的值。
HDFS工作流程
- namenode(管理节点):namenode管理文件系统的命名空间。它维护着文件系统树及整棵树内的所有文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。namenode也记录着每个文件中各个块所在的数据节点信息,但是它并不会永久保存块的位置信息,因为这些信息会在系统启动时根据数据节点信息重建。
- datanode:datanode是文件系统的工作节点。它们根据需要存储并检检索数据块(受客户端或namenode调度),并且定期向namenode发送它们所存储的块的列表。
读取流程
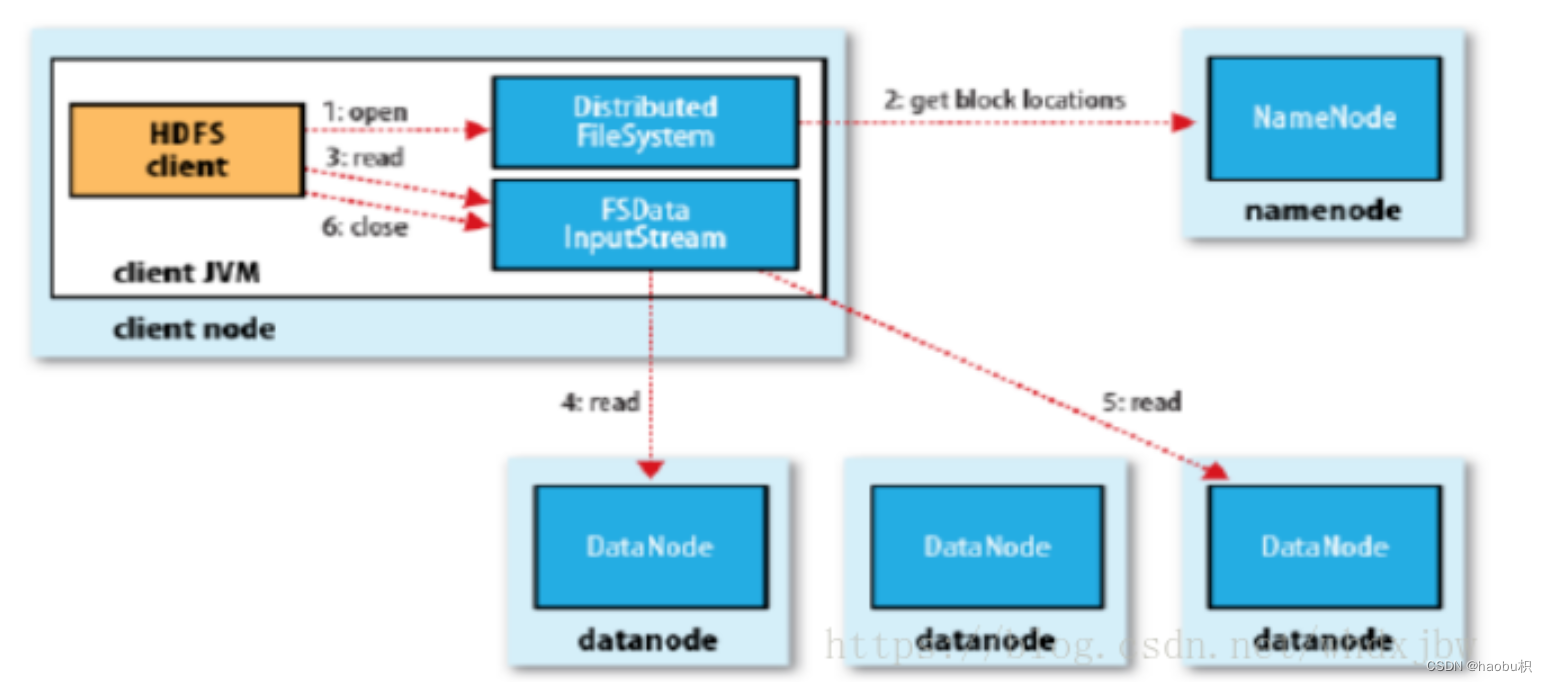
- 客户端调用 FileSystem 对象的open()方法,其实获取的是一个分布式文件系统(DistributedFileSystem)实例;
- 将所要读取文件的请求发送给 NameNode,然后 NameNode 返回文件数据块所在的 DataNode 列表(是按照 Client 距离 DataNode 网络拓扑的远近进行排序的),同时也会返回一个文件系统数据输入流(FSDataInputStream)对象;
- 客户端调用 read() 方法,会找出最近的 DataNode 并连接;
- 数据从 DataNode 源源不断地流向客户端。
写入流程
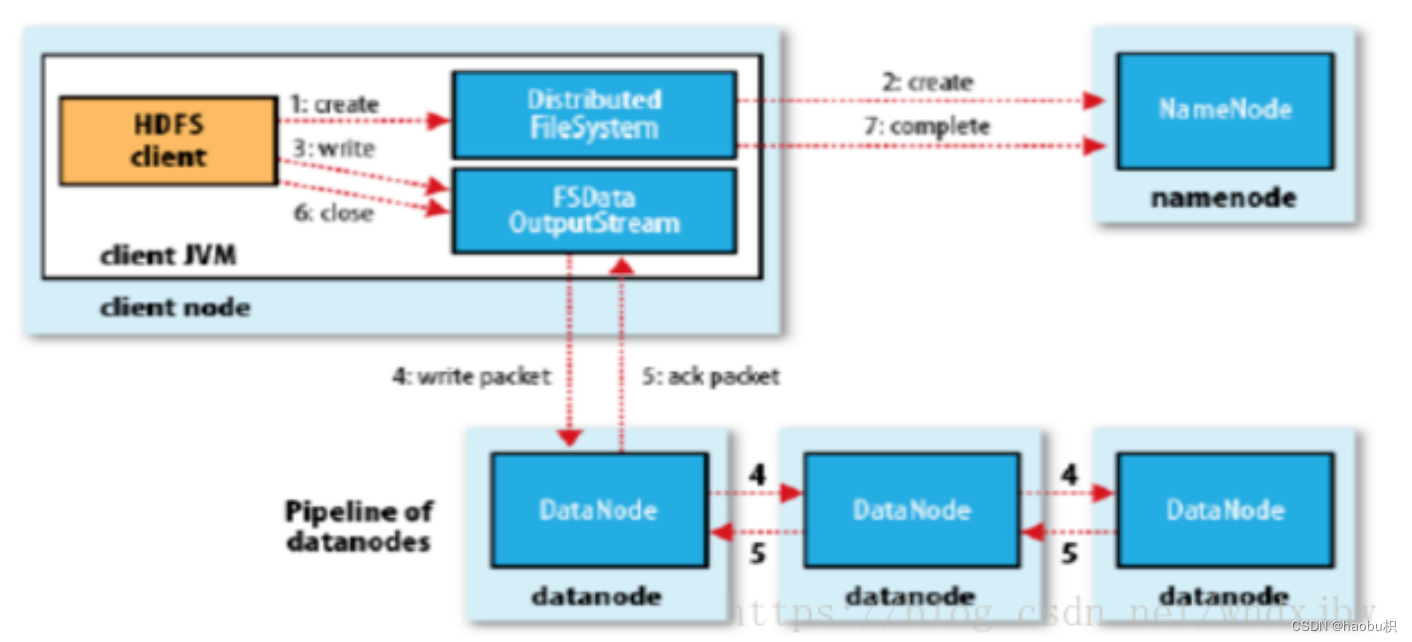
- 客户端通过调用分布式文件系统(DistributedFileSystem)的create()方法创建新文件;
- DistributedFileSystem 将文件写入请求发送给 NameNode,此时 NameNode 会做各种校验,比如文件是否存在,客户端有无权限去创建等;
- 如果校验不通过则会抛出I/O异常。如果校验通过,NameNode 会将该操作写入到编辑日志中,并返回一个可写入的 DataNode 列表,同时,也会返回文件系统数据输出流(FSDataOutputStream)的对象;
- 客户端在收到可写入列表之后,会调用 write() 方法将文件切分为固定大小的数据包,并排成数据队列;
- 数据队列中的数据包会写入到第一个 DataNode,然后第一个 DataNode 会将数据包发送给第二个 DataNode,依此类推。
- DataNode 收到数据后会返回确认信息,等收到所有 DataNode 的确认信息之后,写入操作完成。
hdfs小文件危害和解决办法
小文件来源和危害:
源数据本身有很多小文件;动态分区会产生大量小文件;reduce个数越多,小文件越多;按分区插入数据的时候会产生大量的小文件。
从Hive的角度看,小文件会开很多map,一个map开一个JVM去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重影响性能。HDFS存储大多小文件,会导致namenode元数据特别大,占用太多内存,制约了集群的扩展。
解决方法:
合并小文件: 使用Hadoop的MapReduce或Hive自带的输入格式(TextFile、 SequenceFile等)来合并小文件,将它们合并成一个或几个更大的文件。
压缩文件: 使用Hadoop的压缩算法(如gzip、snappy、Izo等)来压缩小文件,减小文件大小,提高I/O效率。
调整输入格式: 使用Hive的输入格式 (如ORC、Parquet等) 代替TextFile、 SequenceFile等格式,可以提高查询性能,同时可以减少小文件的数量。
使用分区:将数据根据一些共同属性(如日期、地区等)进行分区,可以将小文件转换成更大的块,提高性能。
合理设置参数: 调整MapReduce任务的参数 (如mapreduceinputfileinputformat.splitminsize等)可以让任务更适合处理小文件,提高效率。
使用动态资源分配: 可以通过设置Spark参数 (如spark.dynamicAllocation.enabled) 来使用动态资源分配,从而优化Spark集群资源的使用。
Yarn工作流程
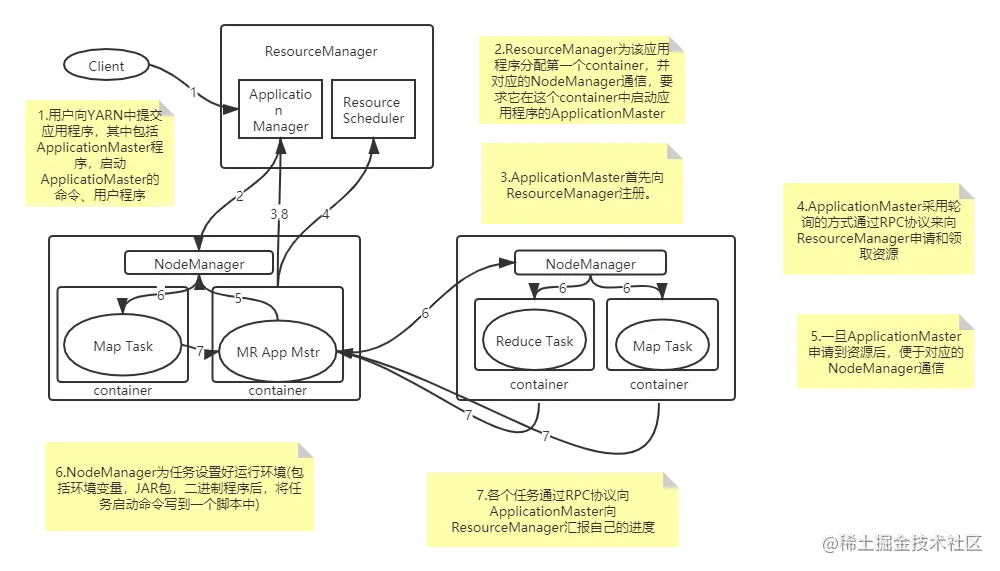
1.用户向YARN中提交应用程序,其中包括ApplicationMaster程序,启动ApplicatioMaster的命令、用户程序
2.ResourceManager为该应用程序分配第一个container,并与对应的NodeManager通信,要求它在这个container中启动应用程序的ApplicationMaster
3.ApplicationMaster首先向ResourceManager注册。
4.ApplicationMaster采用轮询的方式通过RPC协议来向ResourceManager申请和领取资源
5.一旦ApplicationMaster申请到资源后,便于对应的NodeManager通信
6.NodeManager为任务设置好运行环境(包括环境变量,JAR包,二进制程序后,将任务启动命令写到一个脚本中)
7.各个任务通过RPC协议向ApplicationMaster向ResourceManager汇报自己的进度
ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理的分配和管理。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Application Manager,ASM)
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等) 将系统的资源分配给各个正在进行的应用程序。需要注意的是,该调度器是一个纯调度器,它不再从事任何与具体应用程序相关的工作。这些都交给ApplicationMaster完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”表示。
ApplicationMaster(AM)
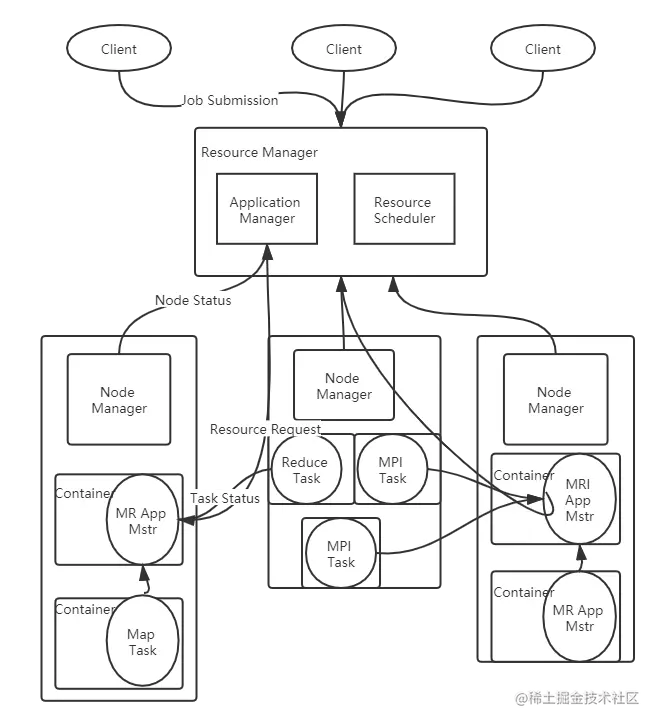
用户提交的每个应用程序均包含一个AM,主要功能:
- RM调度器协商以获取资源(用container表示)
- 将得到的任务进一步分配给内部的任务
- 与NM通信以启动、停止任务
- 监控所有任务的状态,并在任务失败的时候重新为任务申请资源并重启任务
当前YARN自带了两个AM实现,一个用于演示AM编写方法的实例程序,它可以申请一定数目的Container以并行运行一个Shell命令或者Shell脚本。另一个是运行MapReduce应用程序的AM— MRAppMaster
NodeManager
Nm是每个节点上的资源和任务管理器,一方面,他会定时的向RM汇报本节点上的资源使用情况和各个Container的运行状态。另一方面,它接受并处理来自AM的Container启动、停止请求。
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。当AM向RM申请资源时。RM为AM返回的资源是用Container表示的。YARN会表示为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。需要注意的是,Container不同于MRv1中的solt,它是一个动态资源划分单位,是根据应用程序动态生成的,YARN只支持CPU和内存两种资源,使用Cgroup进行隔离
Spark工作流程
Application:应用程序
- 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源
- 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上
- SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task
- Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor
- Task在Executor上运行,运行完毕释放所有资源
SPARK SQL和HIVE SQL对比
| Spark SQL | Hive | |
|---|---|---|
| 查询语言 | Spark SQL和HQL | HQL |
| 执行引擎 | Spark | 默认Mapreduce,可以自定义为Spark |
| 数据存储 | 本身不提供数据存储,可指定到不同存储系统,如HDFS,hive,Hbase,Mysql | HDFS |
| 元数据存储 | 可选元数据存储 | 必须指定元数据存储 |
| API | DataFrame/DateSet DSL 和SQL | HQL |
| Schema | schema自动关联 | 使用DDL显示表明schema |
| 对比方面\计算引擎 | spark | mapreduce | 备注 |
|---|---|---|---|
| 计算方式 | 内存计算 | IO读写 | 迭代计算过程中,MR需要不断IO,而Spark引入了RDD和DAG,使计算过程基于内存完成,提升了处理性能 |
| 任务调度 | task为线程级别 | task为进程级别 | Spark可以通过复用线程池中的线程减少启动,关闭task所需要的消耗。 |
| 执行策略 | Spark在shuffle时只有部分场景需要排序,支持基于hash的分布式聚合,更加省时 | Mapreduce在shuffle前需要花费大量时间进行排序 |
Spark,hive on spark,spark on hive三者比较
Hive引擎包括:默认MR、tez、spark
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
【spark on hive 】
hive只作为存储角色,spark 负责sql解析优化,底层运行的还是sparkRDD
具体可以理解为spark通过sparkSQL使用hive语句操作hive表,底层运行的还是sparkRDD,
步骤如下:
1.通过sparkSQL,加载Hive的配置文件,获取Hive的元数据信息
2.获取到Hive的元数据信息之后可以拿到Hive表的数据
3.通过sparkSQL来操作Hive表中的数据
【hive on spark】
hive既作为存储又负责sql的解析优化,spark负责执行
这里Hive的执行引擎变成了spark,不再是MR。
这个实现较为麻烦,必须重新编译spark并导入相关jar包
目前大部分使用spark on hive
优化举例
谓词下推
select a.*,b.* from
tb1 a join tb2 b
on a.id = b.id
where a.c1 > 20 and b.c2< 100
优化为
select a.*,b.* from
(select * from tb1 where c1>20) a
join
(select * from tb2 where c2<100) b
on a.id = b.id
减少后期执行过程中的join的shuffle数据量;
列裁剪
select a.name,b.salary from
(select * from tb1 where c1>20) a
join
(select * from tb2 where c2<100) b
on a.id = b.id
优化为
select a.name,b.salary from
(select id,name from tb1 where c1>20) a
join
(select id,salary from tb2 where c2<100) b
on a.id = b.id
执行前将不需要的列裁剪掉,减少数据量获取;
常量累加
select 1+1 as cnt from tb
select 2 as cnt from tb
如何使用sqoop
Sqoop是一个用于将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:MySQL、Oracle、Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。下面是将数据从MySQL导入到HDFS的步骤:
在HDFS中创建目录,用于导入后存放数据。
使用sqoop import命令将MySQL中的表导入到HDFS中。
sqoop import \
--connect jdbc:mysql://<mysql_host>/<database_name> \
--username <username> \
--password <password> \
--table <table_name> \
--delete-target-dir \
--target-dir <hdfs_directory_path> \
--m 1
其中,<mysql_host>是MySQL主机名或IP地址,<database_name>是要导入的数据库名,和是MySQL登录用户名和密码,<table_name>是要导入的表名,<hdfs_directory_path>是要存储数据的HDFS目录路径,–m 1表示使用一个Mapper任务执行导入操作。
要使用web调用MySQL中的数据进行前端展示,您需要使用一些技术和工具。以下是一些步骤:
- 使用Java Web框架(如Spring Boot)创建Web应用程序。
- 在Web应用程序中使用JDBC连接到MySQL数据库。
- 编写SQL查询以从MySQL数据库中检索数据。
- 将检索到的数据存储在Java对象中。
- 使用Java对象将数据传递到前端(HTML、CSS和JavaScript)。
- 在前端使用JavaScript和AJAX技术将数据呈现给用户。
Zookeeper 如何保证分布式系统数据一致性
ZAB协议的消息广播,崩溃恢复和数据同步
消息广播
一个事务请求(Write)进来之后,Leader 节点会将写请求包装成 Proposal 事务,并添加一个全局唯一的 64 位递增事务 ID,也就是 Zxid(消息的先后顺序就是通过比较 Zxid);
Leader 节点向集群中其他节点广播 Proposal 事务,Leader 节点和 Follower 节点是解耦的,通信都会经过一个 FIFO 的消息队列,Leader 会为每一个 Follower 节点分配一个单独的 FIFO 队列,然后把 Proposal 发送到队列中;
Follower 节点收到对应的 Proposal 之后会把它持久到磁盘上,当完全写入之后,发一个 ACK 给 Leader;
当 Leader 节点收到超过半数 Follower 节点的 ACK 之后(Quorum 机制),会提交本地机器上的事务,同时开始广播 commit, Follower 节点收到 commit 之后,完成各自的事务提交。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9voQBzvj-1681778635762)(数仓面经.assets/v2-22d9ae5ce56af93dcbf4466e21b51381_1440w.webp)]
- 当 Leader(Server1) 发起一个事务 Proposal1 后就宕机了,导致 Follower 都没有 Proposal1。
- 当 Leader 发起 Proposal2 后收到了半数以上的 Follower 的 ACK,但是还没来得及向 Follower 节点发送 Commit 消息就宕机了。
奔溃恢复
集群服务刚启动时进入崩溃恢复阶段选取 Leader 节点。
Leader 节点突然宕机或者由于网络原因导致 Leader 节点与过半的 Follower 失去了联系,集群也会进入崩溃恢复模式。
选举 Leader 节点
- 各个节点变为 Looking 状态
- Leader 宕机后,余下的 Follower 节点都会将自己的状态变更为 Looking(注意 Observer 不参与选举),然后开始进入 Leader 选举过程。
- 各个 Server 节点都会发出一个投票,参与选举
- 在第一次投票中,所有的 Server 都会投自己,然后各自将投票发送给集群中所有机器。
- 集群接收来自各个服务器的投票,开始处理投票和选举
- 处理投票的过程就是对比 Zxid 的过程,假定 Server3 的 Zxid 最大,Server1 判断 Server3 可以成为 Leader,那么 Server1 就投票给 Server3,判断的依据如下:首先选举 epoch 最大的,如果 epoch 相等,则选 zxid 最大的,若 epoch 和 zxid 都相等,则选择 server id 最大的。 在选举过程中,如果有节点获得超过半数的投票数,则会成为 Leader 节点,反之则重新投票选举。
- epoch 是 ZooKeeper 中的一个概念,用于标识 ZooKeeper 的版本。每次集群中的 Leader 发生变化时,都会增加 epoch 的值。epoch 的值是一个 32 位的整数,它会被写入到事务日志中,以便在崩溃恢复时使用。当一个 Follower 节点从 Leader 节点同步数据时,如果发现自己的 epoch 比 Leader 节点的 epoch 小,则会拒绝同步数据。
- 选举成功,各节点的状态为 Leading 和 Following。
- Zab 中的节点有三种状态,folloing(当前节点是 Follower 节点),leading(当前节点是 Leader 节点),looking/election(当前节点处于选举状态);伴随着的 Zab 协议消息广播和崩溃恢复两阶段之间的转换,节点状态也随之转换。
消息同步
崩溃恢复完成选举以后,接下来的工作就是数据同步,在选举过程中,通过投票已经确认 Leader 节点是最大 Zxid 的节点,同步阶段就是利用 Leader 前一阶段获得的最新 Proposal 历史同步集群中所有的副本
















 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









