








一、什么是正则化?
- 在机器学习中正则化(英语:regularization)是指为解决适定性问题或过拟合而加入额外信息的过程。在机器学习和逆问题的优化过程中,正则项往往被加在目标函数当中。
- 过拟合:神经网络模型在训练数据集上的准确率较高,在新的数据进行预测或分类时准确率较低,说明模型的泛化能力差。
二、正则化的作用是什么?
- 由于损失函数只考虑在训练集上的经验风险,这种做法可能会导致过拟合。为了对抗过拟合,我们需要向损失函数中加入描述模型复杂程度的正则项,将经验风险最小化问题转化为结构风险最小化。
- 从使用正则化解决了一个什么问题的角度来看:正则化是为了防止过拟合, 进而增强泛化能力。用白话文转义,泛化误差(即真实情况下模型的误差)= 测试误差(在任意一个测试数据样本上表现出的误差),其实就是使用训练数据训练的模型在测试集上的表现(或说性能 )好不好

上图,红色这条“想象力”过于丰富上下横跳的曲线就是过拟合情形。结合上图和正则化的英文 Regularizaiton-Regular-Regularize,直译应该是:规则化(加个“化”字变动词)。什么是规则?你家人叫你10点前回家吃饭,这就是规则,一个限制。同理,在这里,规则化就是说给需要训练的目标函数加上一些规则(限制),让他们不要自我膨胀。正则化,看起来,挺不好理解的,追其根源,还是“正则”这两字在中文中实在没有一个直观的对应,如果能翻译成规则化,更好理解。但我们一定要明白,搞学术,概念名词的准确是十分重要,对于一个重要唯一确定的概念,为它安上一个不会产生歧义的名词是必须的,正则化的名称没毛病,只是从如何理解的角度,要灵活和类比。
三、正则化的数学表达:
通过向目标函数添加一个参数范数惩罚 项来降低模型的容量,是一类常用的正则化方法。将正则化后的损失函数记作 :
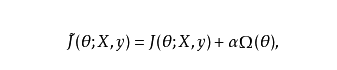
其中 :
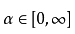
权衡范数惩罚项的相对贡献,越大的αα对应越多的正则化
通常情况下,深度学习中只对网络权重θθ添加约束,对偏置项不加约束。主要原因是偏置项一般需要较少的数据就能精确的拟合,不对其正则化也不会引起太大的方差。另外,正则化偏置参数反而可能会引起显著的欠拟合。
四、实现正则化:
正则化:在损失函数中给每个参数 w 加上权重,引入模型指标,从而抑制模型噪声,减少过拟合现象。
一般情况下:
使用正则化后,损失函数 loss 变为两项之和:
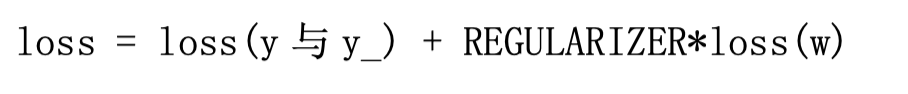
其中,第一项是预测结果与标准答案之间的差距,如之前讲过的交叉熵、均方误差等;第二项是正则化计算结果。
选择正则化的计算方法:
- L1 正则化:
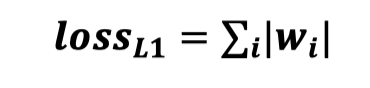
即各个参数的绝对值之和。
Tensorflow函数:
loss(w) = tf.contrib.layers.l1_regularizer(REGULARIZER)(w)
tf.contrib.layers.l1_regularizer(scale, scope=None)
-
参数:
- scale: 正则项的系数.
- scope: 可选的scope name(范围名称)
-
L2 正则化:
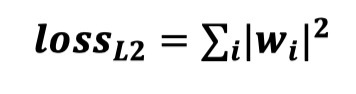
常用的L2参数正则化通过向目标函数添加一个正则项
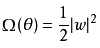
使权重更加接近原点。L2参数正则化方法也叫做权重衰减,有时候也叫做岭回归(ridge regression)
用 Tesnsorflow 函数表示:
loss(w) = tf.contrib.layers.l2_regularizer(REGULARIZER)(w)
tf.contrib.layers.l2_regularizer(scale, scope=None)
- 参数:
- scale: 正则项的系数.
- scope: 可选的scope name(范围名称)
通过上面的分析,L1相对于L2能够产生更加稀疏的模型,即当L1正则在参数w比较小的情况下,能够直接缩减至0.因此可以起到特征选择的作用。
如果从概率角度进行分析,很多范数约束相当于对参数添加先验分布,其中L2范数相当于参数服从高斯先验分布;L1范数相当于拉普拉斯分布。
正则项系数初始值应该设置为多少,好像也没有一个比较好的规范。建议一开始将正则项系数λ设置为0,先确定一个比较好的学习率。然后固定该学习率,给λ一个值(大约1.0),然后根据验证精度,将λ增大或重叠10倍(增减10倍是粗调节,当您确定了λ的合适的数量级后,则λ= 0.01,再进一步地细调节,例如调节为0.02,0.03,0.009之类。)
- 经验:
从0开始,逐渐增大𝜆。在训练集上学习到参数,然后在测试集上验证误差。反复进行这个过程,直到测试集上的误差最小。一般的说,随着𝜆从0开始增大,测试集的误分类率应该是先减小后增大,交叉验证的目的,就是为了找到误分类率最小的那个位置。建议一开始将正则项系数λ设置为0,先确定一个比较好的learning rate。然后固定该learning rate,给𝜆一个值(比如1.0),然后根据validation accuracy,将λ增大或者减小10倍,增减10倍是粗调节,当你确定了𝜆的合适的数量级后,比如𝜆=0.01,再进一步地细调节,比如调节为0.02,0.03,0.009之类。
使用正则化:
- tf.get_variable() 使用这些参数获取现有变量或创建一个新变量。
def get_variable(name,
shape=None,
dtype=None,
initializer=None,
regularizer=None,
...
)
- 参数:
- name就是变量的名称
- shape是变量的维度
- dtype是变量的类型
- initializer是变量初始化的方式
- regularizer:一个(Tensor-> Tensor或None)函数; 将其应用于新创建的变量的结果将添加到集合中可用于正则化。
- 常用的初始化方法

- 1、定义一个变量:
W = tf.Variable(tf.random_normal(3))
- 2、将该变量加入tf.GraphKeys.WEIGHTS集合
tf.add_to_collection(tf.GraphKeys.WEIGHTS, W)
- 3、定义加入了正则化的损失loss:
regularizer = tf.contrib.layers.l2_regularizer(scale) #定义正则化计算方法
reg_term = tf.contrib.layers.apply_regularization(regularizer) #进行正则化(tf.GraphKeys.WEIGHTS集合内)
loss = loss + reg_term) #新的损失值
例子
W_2 = tf.Variable(tf.random_normal([784, 100]))
W_3 = tf.Variable(tf.random_normal([100, 10]))
tf.add_to_collection(tf.GraphKeys.WEIGHTS, W_2) #加入集合
tf.add_to_collection(tf.GraphKeys.WEIGHTS, W_3)
regularizer = tf.contrib.layers.l2_regularizer(scale) #定义方法
reg_term = tf.contrib.layers.apply_regularization(regularizer) #进行正则化
loss = loss + reg_term #加入损失计算
我们还有一种比较直观的方法(适合正则化参数较少的情况):
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w)
loss = cem + tf.add_n(tf.get_collection('losses'))
练习题:
利用 正则化 以及更换 损失函数、优化器 、 激活函数 ,将手写字识别神经网络(可按照自己的想法)优化到百分之九十五以上。
评论出你的答案。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









