







1、hadoop和hadoop生态系统
hadoop的思想来源是Google,Google曾经面对一个问题,大量的网页怎么存储,怎么快速搜索的问题,于是三篇论文诞生了GFS、Map-Reduce、BigTable,这三篇论文的开源实现版本分别就是hadoop的hdfs、mapreduce和hbase,分别对应大数据存储、大数据分析计算、列式非关系型数据库。
hadoop本身就是一个软件,一个用java写好的软件,只要你电脑上装好了jdk,就能运行。 hadoop1.0软件本身有两个模块,hdfs和mapreduce,hadoop2.0添加了一个yarn。hdfs做存储、mapreduce做计算,yarn做计算资源管理。
hadoop生态系统则是指围绕 hadoop建立起的一整套开源软件, 包括了做高可用的zookeeper、 非关系型数据库hbase、机器学习 框架mahout、数据仓库hive、 日志收集工具flume、 流式计算框架storm等。

2、HDFS
试想一下,每天数以亿计的访问量,产生的大量的数据,我们可以分开存储,每一台机器存储一天、或者一个小时的数据,当我们需要这些数据的时候,根据存储的规则去对应的机器找。但是这样带来的问题是销量的降低,我们还要分开在每个机器进行计算,然后再汇总计算。要是有一台机器有无限大的磁盘存储、无限大的内存,那我们可以将所有的数据都放到这台超级计算机上,计算的时候,也可以只在这一台机器进行计算,不用管数据的分布情况。但是这样的机器是很难制造出来的,成本也特别高。而hadoop就解决了这个问题。hadoop将很多廉价的服务器,连接在一起,通过事先写好的规则,进行存储服务。这样就算数据量再大,只需要hadoop管理即可,我自己并不关心这是一台机器还是很多机器。这和人才培养也是一样的,我们不可能投入很大的精力去培养一个超级英雄,而是制定规则将很多人团结起来,成本低效率高。
hdfs就是一个分布式存储系统,提供了高可靠性、高扩展性和高吞吐率的数据存储服务。
Namenode:元数据节点,是系统唯一的管理者。负责元数据的管理;与client交互进行提供元数据查询;分配数据存储节点等。
Datanode:数据存储节点,负责数据块的存储与冗余备份;执行数据块的读写操作等。
3、什么是MapReduce?
- Map:映射过程,把一组数据按照某种Map函数映射成新的数据。
- Reduce:归约过程,把若干组映射结果进行汇总并输出。

让我们来看一个实际应用的栗子,如何高效地统计出全国所有姓氏的人数?
我们可以利用MapReduce的思想,针对每个省的人口做并行映射,统计出若干个局部结果,再把这些局部结果进行整理和汇总:

这张图是什么意思呢?我们来分别解释一下步骤:
- Map: 以各个省为单位,多个线程并行读取不同省的人口数据,每一条记录生成一个Key-Value键值对。图中仅仅是简化了的数据。
- Shuffle Shuffle这个概念在前文并未提及,它的中文意思是“洗牌”。Shuffle的过程是对数据映射的排序、分组、拷贝。
- Reduce 执行之前分组的结果,并进行汇总和输出。需要注意的是,这里描述的Shuffle只是抽象的概念,在实际执行过程中Shuffle被分成了两部分,一部分在Map任务中完成,一部分在Reduce任务中完成。
4、Yarn
- ResourceManager 每个集群一个实例,用于管理整个集群的资源使用;
- NodeManager 负责接收ResourceManager的资源分配请求 负责监控并报告Container使用信息给ResourceManager 和ResourceManager配合,NodeManager负责整个Hadoop集群中的资源分配工作。

5、 配置环境变量
创建工作目录:mkdir –p /usr/hadoop
解压hadoop:tar -zxvf /opt/soft/hadoop-2.7.3.tar.gz -C /usr/hadoop/

修改/etc/profile文件
#HADOOP
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin

生效配置文件:source /etc/profile
6、配置Hadoop各组件
hadoop的各个组件的都是使用XML进行配置,这些文件存放在hadoop的etc/hadoop目录下。
| Common组件 | core-site.xml |
| HDFS组件 | hdfs-site.xml |
| MapReduce组件 | mapred-site.xml |
| YARN组件 | yarn-site.xml |
6.1hadoop-env.sh
修改java环境变量: export JAVA_HOME=/usr/java/jdk1.8.0_171

6.2 core-site.xml
注意在<configuration></configuration>中加入代码

<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
6.3 yarn -site.xml
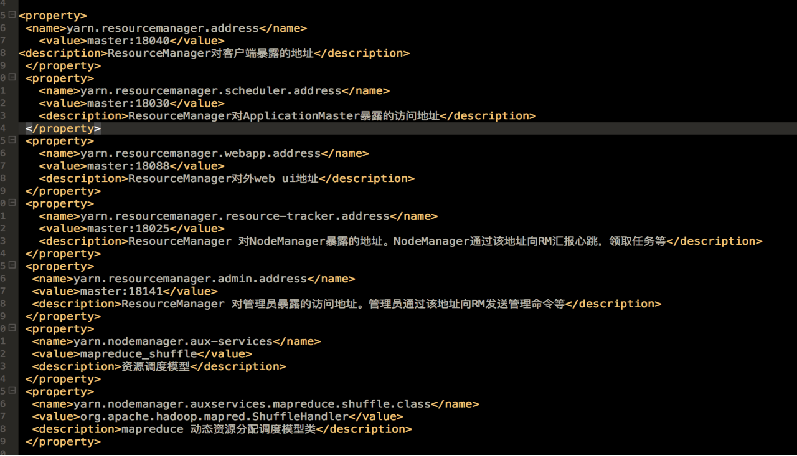
6.4 hdfs-site.xml

6.5 mapred-site.xml
hadoop是没有这个文件的,需要将mapred-site.xml.template复制为mapred-site.xml。
cp mapred-site.xml.template mapred-site.xml
<property>
<!-指定Mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6.6 设置节点文件
编写slave文件,添加子节点slave1和slave2

编写master文件,添加主节点master

分发hadoop
scp -r /usr/hadoop root@slave1:/usr/
scp -r /usr/hadoop root@slave2:/usr/
7. HDFS格式化
格式化namenode:hadoop namenode -format

当出现“Exiting with status 0”的时候,表明格式化成功。

8. 开启集群
仅在master主机上开启操作命令。它会带起从节点的启动。
开启集群:sbin/start-all.sh
查看进程:jps

子节点上进行查看:
 集群开启之后可以访问其集群的Web UI,直接使用浏览器访问master的50070 端口,查看集群的运行状态。 (注意,如果发现集群已启动,但是访问不了,可能是防火墙没有关闭) 浏览器访问:masterIP:50070
集群开启之后可以访问其集群的Web UI,直接使用浏览器访问master的50070 端口,查看集群的运行状态。 (注意,如果发现集群已启动,但是访问不了,可能是防火墙没有关闭) 浏览器访问:masterIP:50070

8.1 hadoop脚本命令练习
查看dfs根目录文件:hadoop fs –ls /
在hdfs上创建文件data :hadoop fs –mkdir /data
再次进行查看:hadoop fs –ls /
 8.2 Web查看hdfs
8.2 Web查看hdfs
使用浏览器对集群进行查看。依次进入“Utilities”->“Browse the file system”
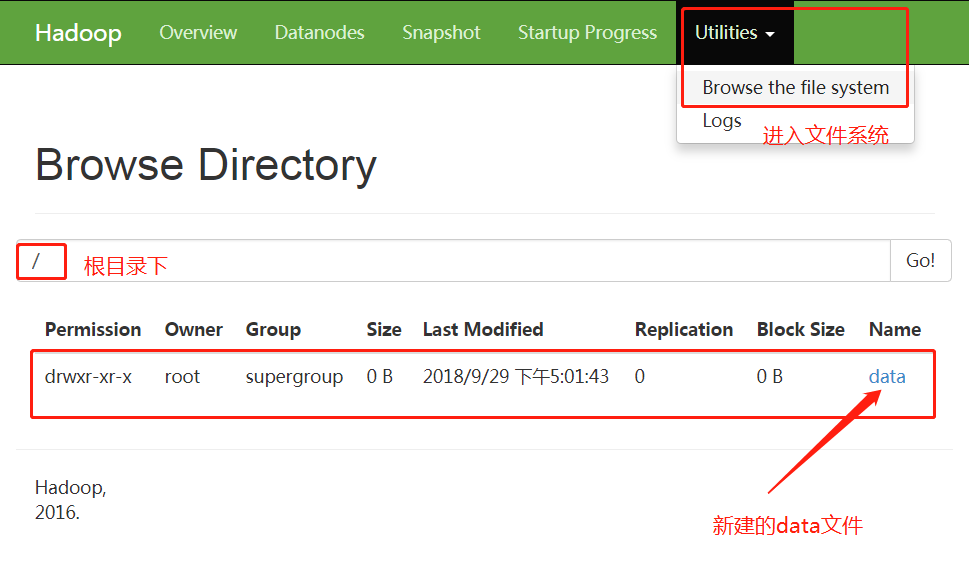 8.3 Hdfs-shell
8.3 Hdfs-shell
hadoop fs -mkdir -p /home/hadoop/
hadoop fs -put /usr/hadoop/hadoop-2.7.3/bin/ /home/hadoop/
hadoop fs -ls /
hadoop fs -get /home/hadoop/bin/rcc /root
cd /root/
ls
cat rcc

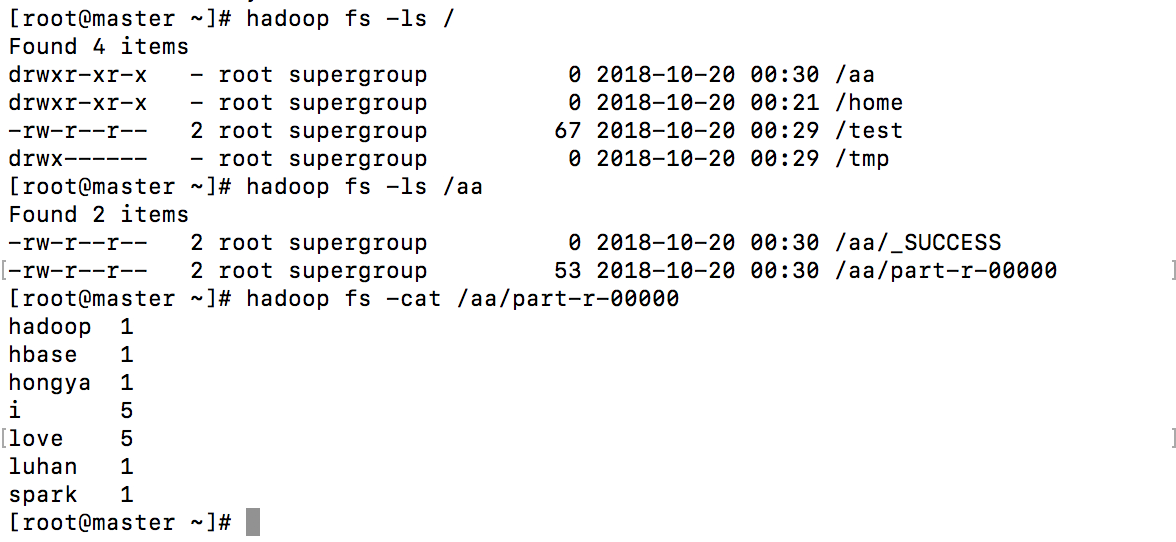
hadoop fs -put /root/test /
hadoop jar /usr/hadoop/hadoop-2.7.3/share/
hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test /aa

hadoop fs -cat /aa/part-r-00000
















 1887
1887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











