






1.2 [实验]Hadoop集群安装与配置
1.2.1 实验目的
1、在Linux系统上安装Hadoop及相关应用软件;
2、掌握集群所有节点之间SSH免密登录配置方式;
3、掌握Hadoop集群的搭建配置流程;
4、理解Hadoop集群的原理,并掌握Hadoop集群的配置方法
1.2.2 实验环境
平台:大数据实验实训平台;
操作系统:CentOS 7
JDK安装包:jdk-8u291-linux-*64.tar.gz
Hadoop安装包:hadoop2.7.4.tar.gz
虚拟机:三台
1.2.3 安装准备
需要提前创建三台虚拟机
1.2.4 实验步骤
步骤一 配置及测试虚拟机
- 更改主机名(注意:需要在三台虚拟机都执行以下操作)使用nmtui命令设置主机名

图1.2.1 修改主机名
2、使用电脑方向键选择设置系统主机名然后回车

图1.2.2 选择设置
3、把三台虚拟机的主机名分别修改为hadoop01,hadoop02,hadoop03回车确定

图1.2.3 修改主机名
4、使用命令vi /etc/sysconfig/network,进入该文件后a键开始编辑,删除原有文档,修改为如下所示文档(注意:在其他两台虚拟机中操作时,要对应好之前修改好的主机名,再分别设置为hadoop02和hadoop03)修改完成后esc键退出编辑,冒号wq保存退出
配置参数如下:
NETWORKING=yes
HOSTNAME=hadoop01

图1.2.4 修改network文件
5、配置ip映射,首先用ifconfig命令查看自己三台虚拟机的IP地址分别是什么(注意:如果命令用不了请安装该命令yum install net-tools ifconfig。)
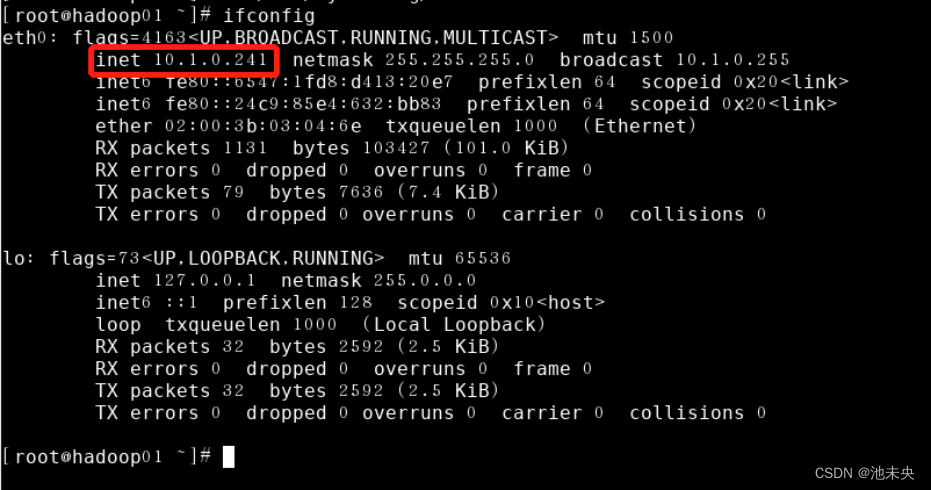
图1.2.5 查看IP地址
6、使用vi /etc/hosts命令进入该文件,在原有文件下增加如图内容,保存退出。其他两台虚拟机重复此操作(注意:你的IP地址要和主机名对应)

图1.2.6 修改hosts文件
7、修改完成后使用reboot命令重启客户端(三台虚拟机都需重启)

图1.2.7 重启客户端
8、映射配置测试,在hadoop01节点中使用ping hadoop02和ping hadoop03命令进行测试,结果如下;

图1.2.8 映射配置测试
9、在hadoop02节点中使用ping hadoop03命令进行测试,结果如下;

图1.2.9 映射配置测试
步骤二 安装配置及测试SSH
1、我们可以用命令rpm -qa | grep ssh来检查是否安装了SSH服务,我们看到有五个包,我们的SSH服务已经安装好了

图1.2.10 检查SSH服务
2、再使用命令ps -e | grep sshd来查看SSH服务是否启动,结果证明虚拟机默认启动了SSH服务

图1.2.11 检查SSH是否启动
3、如果虚拟机没有安装SSH,那我们需要用命令yum install openssh-server来安装SSH

图1.2.12 安装SSH
4、配置SSH的免密登录,因为Hadoop的节点很多,每次在主节点中启动从节点都需要输入密码,所以我们要配置好免密登录。我们从三台虚拟机分别输入以下命令生成公钥和秘钥(注意:三台虚拟机都需要输入该命令生成公钥和秘钥)然后每台虚拟机回车三次即可。
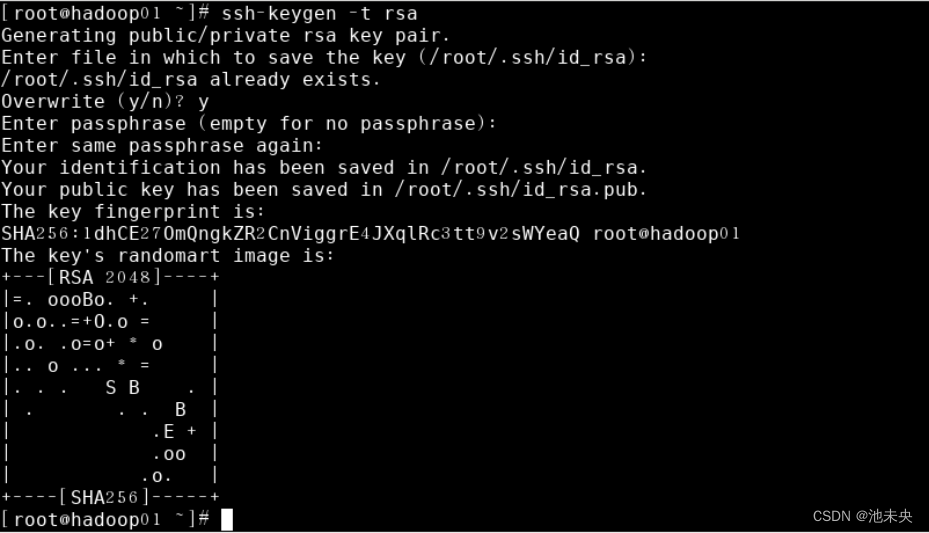
图1.2.13 生成公钥和秘钥
5、Hadoop01的公钥和秘钥生成后,需要把Hadoop01节点的公钥和秘钥分发给hadoop02和hadoop03虚拟机。命令:ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop01,使用该命令将hadoop01虚拟机的公钥秘钥分发给hadoop02和hadoop03虚拟机,其中会输入root账户的密码,如下图。

图1.2.14 公钥和秘钥分发
6、Hadoop02的公钥和秘钥生成后,需要把Hadoop02节点的公钥和秘钥分发给hadoop01和hadoop03虚拟机。命令:ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop02,使用该命令将hadoop02虚拟机的公钥秘钥分发给hadoop01和hadoop03虚拟机,图片同上。
7、Hadoop03的公钥和秘钥生成后,需要把Hadoop03节点的公钥和秘钥分发给hadoop01和hadoop02虚拟机。命令:ssh-copy-id -i /root/.ssh/id_rsa.pub root@hadoop03,使用该命令将hadoop03虚拟机的公钥秘钥分发给hadoop01和hadoop02虚拟机,图片同上。
8、SSH免密登录测试,在hadoop01节点中使用命令 ssh hadoop02,在hadoop02节点中使用命令 ssh hadoop03,在hadoop03节点中使用命令 ssh hadoop01,或直接在hadoop01节点中使用,效果如下。如果从源主机到目的主机的登录过程中,出现需要输入密码的情况,那么需要检查是否已经成功将源主机的公钥文件发送到目的主机中。

图1.2.15 SSH免密登录测试
步骤三 安装配置JDK(hodoop和java的安装包我们平台虚拟机中已经下载好,同学们可以跳过下载步骤,直接解压即可,安装包存放地址为/root/下载)
1、由于Hadoop是由Java语言开发的,Hadoop集群的使用依赖于Java环境,因此安装Hadoop之前,需要先安装并配置好JDK。下载JDK,网址:Java Downloads | Oracle,在我们的虚拟机中就可以直接下载,在虚拟机桌面找到Fireox软件,双击打开直接在网址栏中输入网址即可,如下。(hodoop和java的安装包我们平台虚拟机中已经下载好,同学们可以跳过下载步骤,直接解压即可,安装包存放地址为/root)

图1.2.16 打开Fireox软件
2、我们进入到网站页面看到的是Java SE 16版本的,我们用8版本的,下滑页面找到我们需要的8版本。
图1.2.17 网站页面
3、找到Java SE 8版本后选择右侧的JDK Download,打开后找到如下图JDK的版本,jdk-8u291-linux-*64.tar.gz 大小是138.22MB的,开始下载

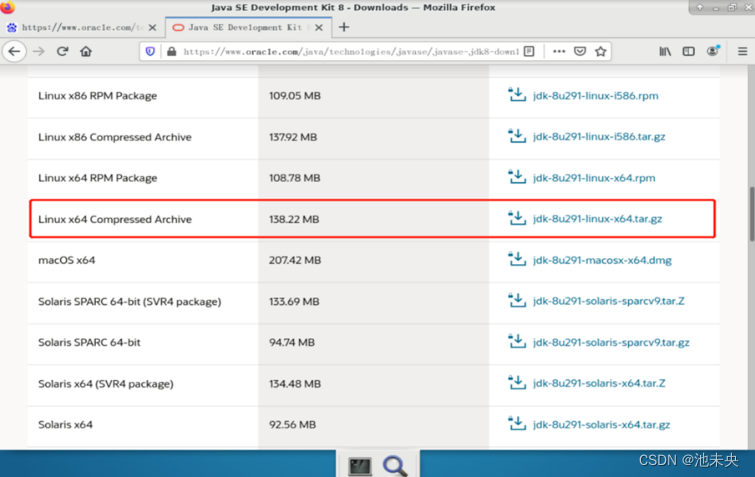
图1.2.18 下载JDK
4、我们下载完JDK后会自动生成一个名为“下载”的文件夹,找到“下载”文件夹(当然你可以把它放到自己的任何文件夹,文件夹最好不要用中文命名),最后从终端进入到放有JDK文件的目录,创建并开始解压安装到/export/servers文件夹。
图1.2.19 下载完成
5、解压命令:tar -zxvf jdk-8u291-linux-*64.tar.gz -C /export/servers如下图。

图1.2.20 解压JDK
6、解压后我们可以到解压目录下查看,蓝色的文件便是我们解压后的文件,如下图

图1.2.21 解压完成
7、由于解压后名字不方便之后使用所以我们直接重命名为jdk,如下图,命令:mv jdk1.8.0_291/ jdk

图1.2.22 重命名
8、安装解压完成后,我们开始配置JDK的环境变量,命令:vi /etc/profile,进入该文件后,找到最后一行,我们把下文的参数添加到该文件最后一行,然后保存退出。配置好后这个文件是不会生效的,需要我们自己使用source /etc/profile命令使他生效。如下图。(注意:以下三行参数一定要把地址写对,如果你的地址是自己修改的,需要把第一行中的地址写为你修改的地址)
配置参数如下:
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

图1.2.23 修改profile文件
9、上述操作完成后,我们想要知道我们的JDK有没有安装成功,所以要验证JDK的安装与配置是否有错,使用java -version命令来验证我们安装的JDK,如下图,我们可以看到JDK的版本以及其他信息后,我们的JDK安装就完成了。

图1.2.24 验证JDK的安装与配置
步骤四 Hdaoop安装解压与配置(下载过程和下载JDK一样,同样在我们的虚拟机中就可以下载)打开后我们可以看到有一个hadoop2.7.4.tar.gz ,254MB的文件,下载就可以)
1、下载hadoop安装包,网址为:Index of /dist/hadoop/common,我们进入网站后下滑页面找到hadoop-2.7.4版本,这个版本相对稳定,然后打开。


图1.2.25 下载hadoop
2、下载成功后依旧在“下载”文件夹中,找到虚拟机桌面的文件系统,找到root目录,找到下载目录打开,如下图。(当然同学也可以放到自己的文件夹)
图1.2.26 下载完成
3、下载成功后,我们开始解压,命令:tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers,解压成功后进入export/servers目录,就可以看到我们解压后的文件,如下图。使用命令mv hadoop-2.7.4 hadoop进行重命名


图1.2.27解压完成
4、和JDK一样,我们安装完成后都需要配置环境变量,使用命令vi /etc/profile进入到该文件后,依旧在最后一行进行配置,参数如下(以下两行参数一定要把地址写对,如果你的地址是自己修改的,需要把第一行中的地址写为你修改的地址)修改完成后保存退出。使用命令source /etc/profile让修改完的配置生效。
配置参数如下:
export HADOOP_HOME=/export/servers/hadoop
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

图1.2.28 配置profile文件
5、Hadoop是否安装配置成功我们还需要进行环境验证,使用命令hadoop version来验证我们的Hadoop环境是否安装成功,如下图,我们可以看到Hadoop的版本号以及其他信息,证明我们的Hadoop安装成功。
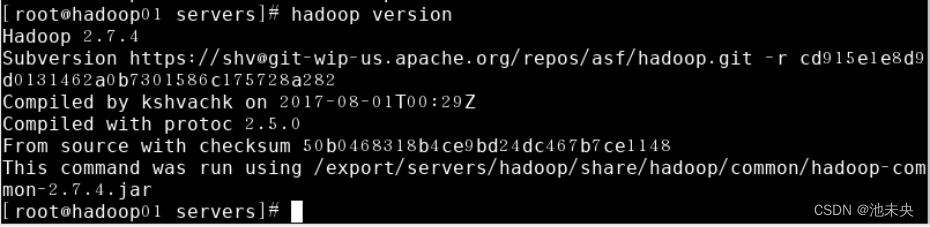
图1.2.29 hadoop环境验证
步骤五 Hadoop集群主节点的配置 (注意:主节点的配置最好在hadoop01虚拟机上完成)
1、使用命令cd /export/servers/hadoop/etc/hadoop进入到hadoop安装目录下,再进入到hadoop文件夹中,此文件夹放置的是hadoop的配置文件,我们需要更改其中几个文件,如下图。

图1.2.30 进入到hadoop安装目录
2、使用vi命令来更改名为hadoop-env.sh的文件,命令为vi hadoop-env.sh,打开文件后找到JAVA_HOME相关配置,把等于号后边的配置改为JDK的安装路径。(注意:地址要写对,是JDK的安装路径,不是hadoop。)然后保存退出,如图
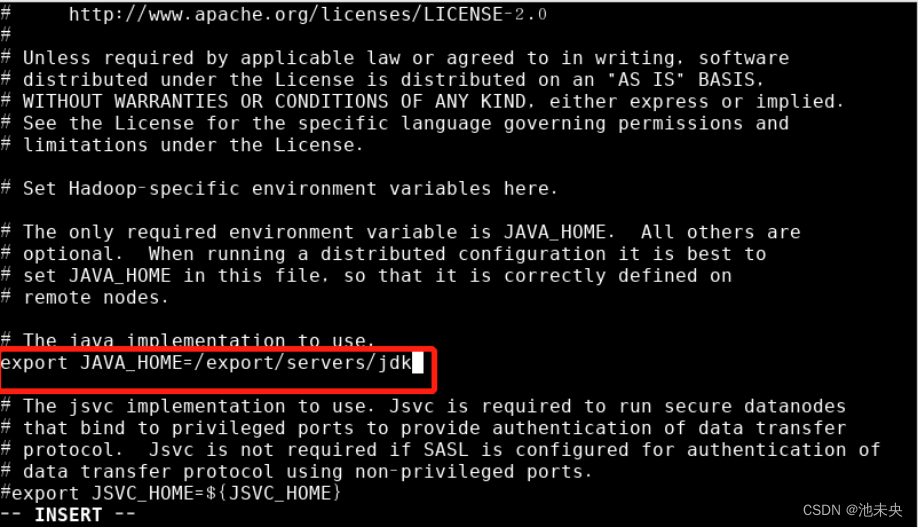
图1.2.31 配置hadoop-env.sh文件
3、修改core-site.xml文件,命令为vi core-site.xml,进入文档后,我们找到最后两行替换为以下配置,然后保存退出。
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop/tmp</value>
</property>

图1.2.32 替换配置文件
4、修改hdfs-site.xml文件,命令为vi hdfs-site.xml。进入文档后,我们找到最后两行替换为以下配置,如下。然后保存退出。
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
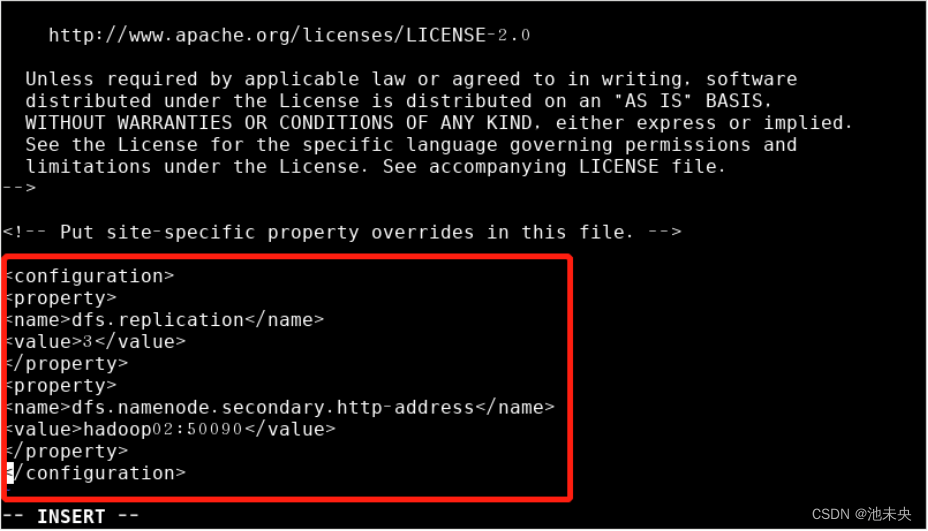
图1.2.33 替换配置文件
5、修改mapred-site.xml文件,因为文件中只有mapred-site.xml.template 文件,所以我们需要修改成 mapred-site.xml文件,命令为cp mapred-site.xml.template mapred-site.xml,如图。

图1.2.34 修改mapred-site.xml文件
然后打开mapred-site.xml文件,命令为vi mapred-site.xml,进入文档后,我们找到最后两行替换为以下配置,如下。然后保存退出。
<!--指定MapReduce运行时框架,这里指定在Yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

图1.2.35 替换配置文件
6、修改yarn-site.xml文件,命令为vi yarn-site.xml。进入文档后,我们找到最后两行替换为以下配置,如下。然后保存退出。
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

图1.2.36 替换配置文件
7、修改slaves文件,命令为vi slaves,进入文档后,我们删除原有文件然后替换为以下内容。保存退出。
配置参数如下:
hadoop01
hadoop02
hadoop03

图1.2.37 修改slaves文件
8、集群主节点配置完成后,还有子节点,子节点的配置只需要我们把主节点的配置分发到子节点上就可以。使用如下命令把主节点配置分发到子节点,如下所示,分发完之后要在hadoop02和hadoop03上执行source /etc/profile命令使它生效
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/servers hadoop02:/export/servers
scp -r /export/servers hadoop03:/export/servers

图1.2.38 分发hadoop01到子节点hadoop02

图1.2.39 分发hadoop01到子节点hadoop03
步骤六 Hadoop集群测试
1、我们集群搭建完成后,要测试集群是否搭建成功,在测试之前,我们还需要完成以下操作,格式化系统文件,初次启动HDFS集群时,必须要对主节点进行格式化处理,格式化文件系统指令如下。(注意:要在主节点进行格式化操作,并且只有我们第一次启动HDFS的时候进行格式化,之后不用再执行此操作)。命令:hdfs namenode -format或 hadoop namenode -format,然后就可以开始启动hadoop集群了,针对Hadoop集群的启动,需要启动内部包含的HDFS集群和YARN集群两个集群框架。启动方式有两种:一种是单节点逐个启动;另一种是使用脚本一键启动。我们来逐一验证。(注意:如遇启动不了可试着关闭防火墙,命令为:systemctl stop firewalld;关闭防火墙。systemctl disable firewalld.service;设置开机禁用防火墙)
2、单节点逐个启动
我们需要先在主节点上启动一个脚本,命令为:hadoop-daemon.sh start namenode(namenode如果启动不了,请重新格式化namenode,命令为:hadoop namenode -format)我们启动完成后怎么查看是否成功呢,使用jps命令来查看,jps命令是用来查看和JAVA相关的进程。

图1.2.40 主节点启动namenode并查看
然后再启动从节点,(注意:从节点hadoop02和hadoop03中只需要启动datanode即可)命令:hadoop-daemon.sh start datanode

图1.2.41 从节点hadoop02启动datanode并查看

图1.2.42 从节点hadoop03启动datanode并查看
3、脚本一键启动和关闭
在主节点hadoop01上执行指令“start-dfs.sh”或“stop-dfs.sh”启动/关闭所有HDFS服务进程;
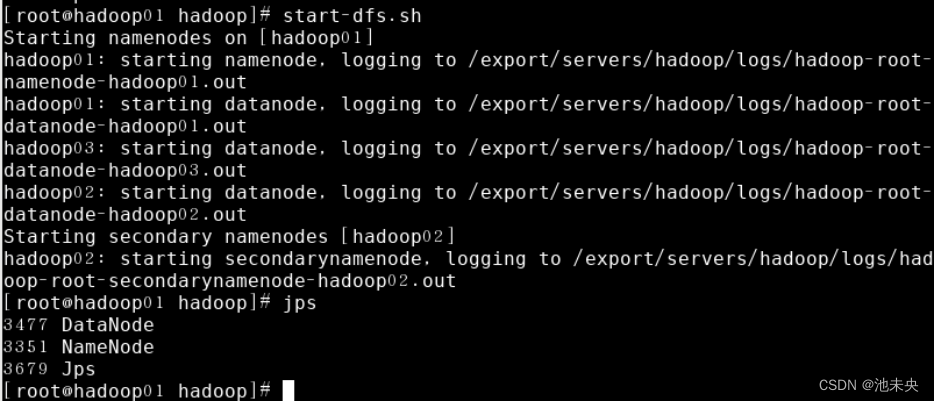
图1.2.43 启动HDFS服务进程

图1.2.44 关闭HDFS服务进程
在主节点hadoop01上执行指令“start-yarn.sh”或“stop-yarn.sh”启动/关闭所有YARN服务进程;

图1.2.45 启动YARN服务进程
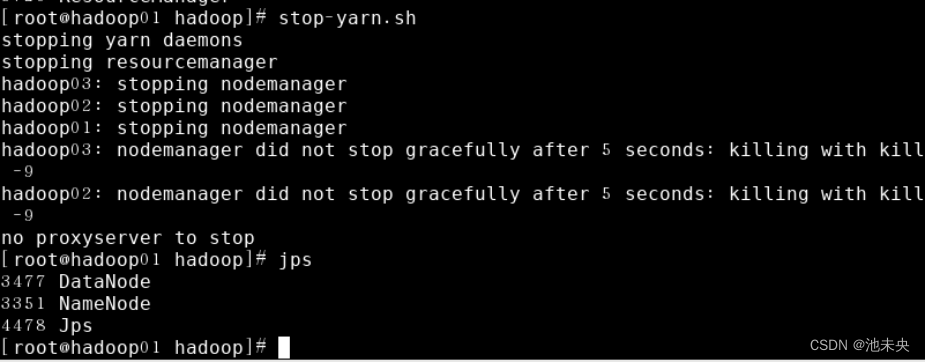
图1.2.46 关闭YARN服务进程
在主节点hadoop01上执行“start-all.sh”或“stop-all.sh”指令,直接启动/关闭整个Hadoop集群服务
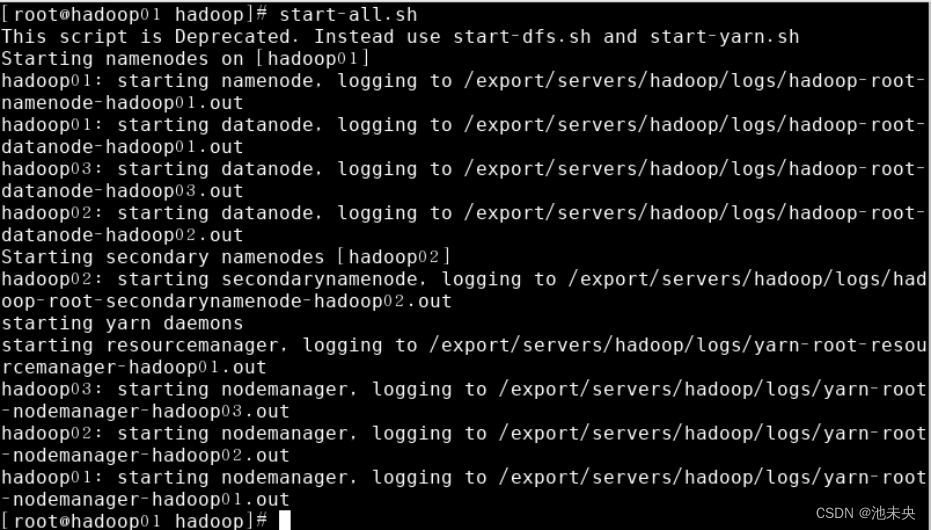
图1.2.47 启动整个Hadoop集群服务

图1.2.48 关闭整个Hadoop集群服务















 2763
2763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









