







目录
摘要理解
像上一篇show,attend and tell论文中,要求预测生成a,of这些不能与图像中的视觉信息相对应的虚词,量词时,仍然要关注一块区域与这些词对应起来。这种情况其实是没有必要的。本文解决的就是这种问题。
在这篇文章中,提出了一种新颖的带有视觉哨兵(visual sentinel)的自适应注意力模型( adaptive attention model)。在每个时间步骤,模型决定是否关注图像(如果关注,关注哪些区域)或视觉哨兵。该模型决定是否关注图像以及关注图像的位置,以便为顺序单词生成提取有意义的信息。
本文在MS COCO数据集和Flickr30k上测试方法,大幅领先先进水平。
源码:源码AdapativeAttention
介绍
注意力机制通常会生成一个空间图(a spatial map),突出显示与每个生成的单词相关的图像区域。
并非描述中所有的生成单词都有相应的视觉信号。例如下图中的on、of、a、top、sign(这里说sign我不太理解,如果不关注图像中的sign怎么确定它是一个标志牌呢),语言相关性使得视觉信号没有那么重要。
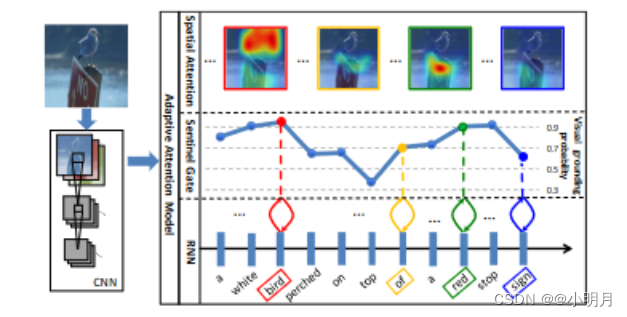
事实上,非视觉单词的梯度可能会误导并削弱视觉信号在指导caption生成过程中的整体有效性。
在本文中,引入了一种自适应注意力编码器解码器框架,它可以自动决定何时依赖视觉信号以及何时仅依赖语言模型。当依赖视觉信号时,模型还决定她应该关注哪个图像区域。本文首先提出了一种用于提取空间图像特征的新颖的空间注意力模型(spatial attention model)。然后,作为本文提出的注意力机制,引入了一种新的长短期记忆(LSTM)扩展,它产生一个额外的“视觉哨兵”向量,而不是单个隐藏状态。
“视觉哨兵”是一个解码器记忆的额外潜在表征,为解码器提供后备选项(fallback option)。本文进一步设计一个新的哨兵门,它决定编码器想要从图像中获取多少新信息,而不是在生成下一个单词的时候依赖视觉哨兵。例如:在上面的图1中,模型在生成单词white,bird,red和stop时学会更多地关注图像,而生成单词top,of,sign时更多地依赖视觉哨兵。
本文贡献如下:
- 引入了一个自适应编码器-解码器框架,它自动决定何时查看图像以及何时依赖语言模型生成下一个单词。
- 首先提出了一种新颖的空间注意力模型,然后在此基础上设计了带有“视觉哨兵”的新型自适应注意力模型。
- 本文的模型在MS-COCO和Flickr30k上显著优于其他先进的方法,
- 本文对自适应注意力模型进行了广泛的分析,包括单词的视觉接地概率(visual grounding probabilitity)和生成注意力图(attention maps)的弱监督定位(weakly supervised localization)。
方法
1.用于图像描述的通用编码器-解码器框架
给定图像和相应的描述,编码器-解码器直接最大化以下的目标:

| P(x,y) | 二元概率分布或联合概率分布,表示两个随机变量x,y同时取某个值的概率。这种表示通常用于描述两个随机变量之间的关联性和相互影响。 |
|---|---|
| P(y|I;θ) | 这种描述通常用于描述在已知一些消息或参数的情况下,y发生的概率。本式子表示在给定条件I和参数θ的情况下,随机变量y的条件概率。 |
| I | Image |
| θ | 模型的参数 |
| y={ y 1 y_1 y1, y 2 y_2 y2,…, y t y_t yt | 相应的描述 |
| θ ∗ θ^* θ∗ | 最优参数 |
| log P(y|I;θ) | 给定图像I和模型参数θ的条件下,生成特定描述y的概率的对数。通过最大化这个对数概率,可以使模型生成与真实字幕最匹配的结果,从而提高图像描述生成的准确性和性能。 |
使用链式法则,联合概率分布的对数似然(likelihood)可以分解为有序条件。注:似然度量了参数取值的可能性,一般使用最大似然。
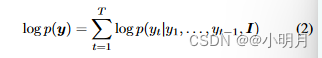
- 为了理解以上式子,先得知道条件概率的链式法则是什么?
 再推下面公式的时候,才发现这个联合概率好像是有另一种表达方式的,下面的一张图片补全了:
再推下面公式的时候,才发现这个联合概率好像是有另一种表达方式的,下面的一张图片补全了:

- 理解链式法则后,就可以根据公式(1)推出公式(2)了。如下图:

至于为什么公式中有个I,这是ChatGPT给出的答案,我原本也不理解。

继续读文章:
为了方便起见,本文放弃了对模型参数的依赖进行参数通用的编码器-解码器框架。
在编码器-解码器框架中,使用循环神经网络RNN,每个条件概率被建模为:
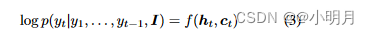
其中 h t h_t ht是RNN在时间t的隐藏状态, c t c_t ct是从图像I中提取的时间t的视觉上下文向量。f是输出 y t y_t yt概率的非线性函数。
本文采取的是LSTM(长短期记忆网络),而不是RNN,LSTM在各种序列建模任务上展示了最先进的性能。LSTM在时间t的隐藏状态 h t h_t ht建模为:
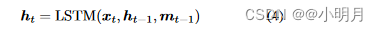
其中, x t x_t xt是输入向量(应该从图像提取出来的特征向量), m t − 1 m_{t-1} mt−1是t-1时的记忆单元向量。
通常,上下文向量 c t c_t ct是神经编码-解码器框架中的重要因素,它为图像描述生成提供视觉证据。这些对上下文向量进行建模的方法分为两类: - 普通编码器-解码器框架:在普通框架中, c t c_t ct仅依赖于编码器,即卷积神经网络(CNN)。输入图像I被输入CNN,CNN提取最后一个全连接层作为全局图像特征。在生成的单词中,上下文向量保持恒定,并且不依赖于解码器的隐藏状态。
- 基于注意力的编码器-解码器框架:在基于注意力的框架中,
c
t
c_t
ct依赖于编码器和解码器。在t时间,基于隐藏状态,编码器将关注图像的特定区域,并使用来自CNN卷积层的空间图像特征来计算
c
t
c_t
ct。一些文献表明,注意力模型可以提高图像字幕的性能。
本文为了计算上下文向量 c t c_t ct,提出了空间注意力模型,然后将模型扩展到自适应注意力模型。
2.空间注意力模型(Spatial attention model)
本文提出了一个用于计算上下文向量
c
t
c_t
ct的空间注意力模型,定义为:

| g | 注意力函数 |
|---|---|
| V=[ v 1 v_1 v1,…, v k v_k vk], v i v_i vi∈ R d R^d Rd | 空间图像特征,每个特征都对应于图像的一部分的d维表示。(其实就是说图像的一部分被表示为d维的特征向量,这些特征向量便于后面去处理) |
| h t h_t ht | RNN在时间t下的隐藏状态 |
给定空间图像特征V∈
R
d
×
k
R_{d×k}
Rd×k(这里为什么维度是d×k呢?因为每一个
v
i
v_i
vi都是d维的,然后又有k个v)和LSTM的隐藏状态
h
t
h_t
ht,作者们通过单层神经网络输入它们,然后使用softmax函数来生成图像的k个区域上的注意力分布。
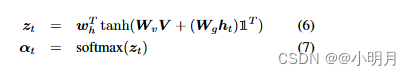
| Ⅰ∈ R k R_k Rk | 所有元素被设置为1的向量 |
|---|---|
| W v W_v Wv, W g W_g Wg∈ R ∗ k × d R*{k×d} R∗k×d, ω h ω_h ωh∈ R k R_k Rk | 要学习的参数 |
| α∈ R ∗ k R*k R∗k | V中特征的注意力权重 |
根据注意力分布,上下文向量
c
t
c_t
ct可以通过以下方式获得:
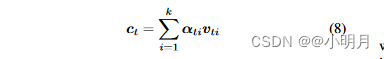
得到了
c
t
c_t
ct和
h
t
h_t
ht,就可以预测下一个单词
y
t
+
1
y_{t+1}
yt+1了。(上面的公式3)。
这个公式(8)有没有很眼熟,这跟show,attend and tell那篇论文里软注意力的上下文向量的计算方式很相似。

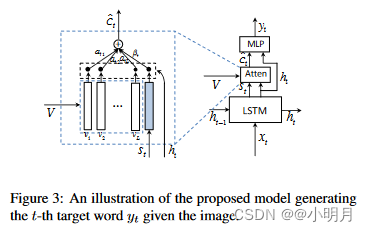
那这篇文章跟show,attend and tell有什么不同呢(直观区别看下图)?
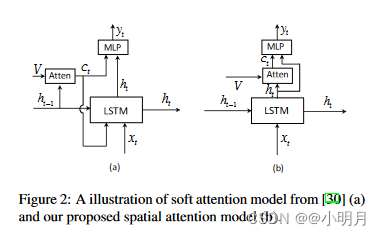
- 首先是我自己的理解:1)从上面的图可以看出来,注意力机制的输入不一样,本篇文章是使用的 h t h_t ht,而另一篇使用的是 h t − 1 h_{t-1} ht−1;2)注意力机制放的位置变了,对LSTM的影响也发生了变化。
- 文章中指出的不同在于:使用当前隐藏状态
h
t
h_t
ht来分析要查看的位置(即生成上下文向量
c
t
c_t
ct),然后结合两个信息源来预测下一个单词。本文作者的动机源于残差网络的优越性能。生成的上下文向量
c
t
c_t
ct可以看作是当前隐藏状态的残差视觉信息,它减少了不确定性或补充了当前隐藏状态用于下一个单词预测的信息量(这里不太明白,对残差网络不熟)。

凭经验发现,空间注意力模型表现更好。

3.自适应注意力模型
虽然基于空间注意力的解码器已被证明对图像描述有效,但是它们无法确定合适依赖视觉信号以及合适依赖语言模型。受其他论文启发,本文引入了一个新概念——“视觉哨兵(visual sentinal)”,本文作者扩展了空间注意力模型,并提出了一种自适应模型,能够确定是否需要关注图像来预测下一个单词。
什么是视觉哨兵?
解码器的存储器存储长期和短期的视觉和语言信息。本文的模型学会从中提取一个新的组件,当模型选择不关注图像时可以依靠该组件。这个新组建称为视觉哨兵。决定关注图像还是关注视觉哨兵的门就是哨兵门。
当解码器RNN是LSTM时,本文考虑保存在其记忆单元中的那些信息。因此,本文扩展LSTM以获得“视觉哨兵”向量(visual sentinal vector)st(这个式子如果看过LSTM的原理的话,会觉得很眼熟,这里推荐大家去看李宏毅老师讲LSTM的那节课,讲的非常好):
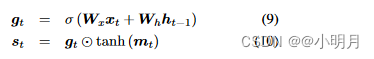
| W t W_t Wt、 W h W_h Wh | 要学习的权重参数 |
|---|---|
| x t x_t xt | 时间t处LSTM的输入 |
| g t g_t gt | 应用于存储单元 m t m_t mt的门 |
| σ | sigmoid激活 |
基于视觉哨兵,提出了一种自适应注意模型来计算上下文向量。
在提出的架构中,新的上下文自适应向量被定义为
c
t
c^t
ct,它被建模为空间关注图像特征(即空间注意力模型的上下文向量)和visual sentinal vector的混合,这会权衡网络从图像中考虑新信息与解码器记忆单元中已知的信息(即视觉哨兵)。其实就是说这个上下文向量使得在改关注图像特征的时候就关注图像特征,在该关注语义信息的时候就关注语义。
混合模型定义如下:

- 上面这个式子中, β t β_t βt∈[0,1]表示时间t时的新哨兵门(sentinal gate),控制模型关注图像视觉信息和visual sentinal(视觉哨兵)的程度。若值=1,表示在生成下一个单词时仅使用visual sentinal,若值=0,则表示在生成下一个单词时仅使用图像的视觉信息。 这个式子和我们概率中的式子很相似,比较容易理解。
- 要计算
β
t
β_t
βt:空间注意力部分k个区域的注意力分布
α
t
α_t
αt也被扩展成了
α
t
^
\hat{α_t}
αt^,做法是在
z
t
z_t
zt后面拼接上一个元素(这个公式里的
W
g
W_g
Wg和之前
z
t
z_t
zt公式里的是一样的,
W
h
W_h
Wh也是):
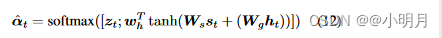
扩展后的 α t ^ \hat{α_t} αt^有k+1个元素,是空间图像特征和视觉哨兵向量上的注意力分布。作者们将该向量的最后一个元素解释为门值。
β t = α t ^ [ k + 1 ] β_t= \hat{α_t}[k+1] βt=αt^[k+1]
原文上面公式有笔误,没带上面的^。
公式(12)可以简化为下图,这个参考博客:若侵权请告知,立马删除

时间t时,词汇表中单词的概率分布:
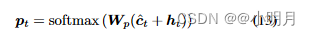
实现细节(Implementation Details)
- Enconder-CNN:使用ResNet最后一个卷积层的空间特征输出来表示图像,维度是2048×7×7。使用A={ α 1 α_1 α1,…, α k α_k αk}, α i α_i αi∈ R 2 048 R^2048 R2048表示k个局部图像特征。那么全局图像特征 α g α^g αg就是局部特征和的平均:

为了建模方便,使用带有rectifier activation function的单层感知器将图像特征向量转换为d维的新向量(用ReLU函数):
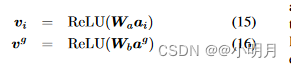
其中,
W
a
W_a
Wa,
W
b
W_b
Wb是权重参数。转换后的空间图像特征形式为V=[
v
1
v_1
v1,…,
v
k
v_k
vk]。
-
Deconder-RNN:作者将词嵌入向量(word embedding vector) ω t ω_t ωt和全局图像特征(global image feature) v g v_g vg拼接起来作为作为LSTM的输入向量: x t x_t xt=[ ω t ω_t ωt; v g v_g vg].
作者使用单层神经网络将哨兵向量 s t s_t st和LSTM的输出向量 h t h_t ht转换为维度为d的新向量。 -
Training details:使用hidden size为512的单层LSTM。使用Adam优化器,语言模型的忽略吧学习率是5e-4,CNN的学习率是1e-5.动量和权重衰减分别是0.8和0.999.在20个epoch之后对CNN进行微调。batch size设置为80,并训练最多50epoch,如果验证 CIDEr 分数在过去 6 个 epoch 中没有提高,则提前停止。模型可以在 30 小时内在单个 Titan X GPU 上进行训练。在对 COCO 和 Flickr30k 数据集的标题进行采样时,使用光束大小 3。
实验结果(results)
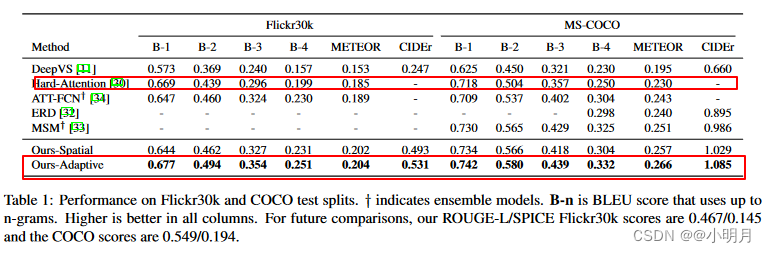
在Flickr30k and COCO test splits上的性能对比。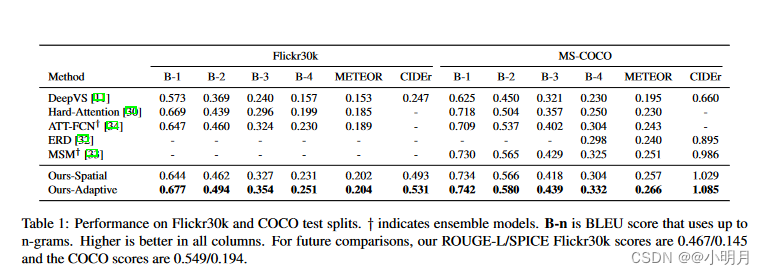
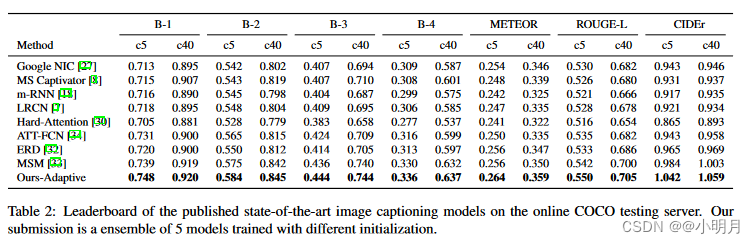
在COCO Server上的对比。
定量分析(quatitative analysis)
使用COCO captioning evaluation tool报告结果。指标如下:BLUE、Meteor、Rouge-L和CIDEr,以及新指标SPICE(这个指标发现与人类判断更好地相关)。总之就是性能更好。就是实验结果的那两张表。
值得注意的是,Google NIC、ERD 和 MSM 使用 Inception-v3作为编码器,与 ResNet-152(我们的模型使用的)相比,它具有相似或更好的分类性能。
定性研究(Qualitative analysis)
一、 可视化生成的字幕中不同单词的空间注意力(spatial attention)的权重α。作者们简单地使用双线性插值(bilinear
interpolation)将注意力权重上采样到图像大小(224×224)。

上图4是COCO 数据集上生成的标题和图像注意力图的可视化。不同的颜色显示了关注区域和下划线单词之间的对应关系。前两列是成功案例,最后一列是失败示例。最好以彩色形式观看。但就算失败,发现模型对于attention的区域是合理的,只是可能对一些物体的材质判断失误。
二、接着可视化sentinal gate(哨兵门)。对于每个单词,使用1-β作为视觉基础概率.对于视觉词,模型给出的概率较大,即更倾向于关注图像特征 c t c_t ct,对于非视觉词,概率比较小。同一个词在不同的上下文中生成时,可能会被分配不同的视觉基础概率。例如,单词“a”通常在句子开头具有较高的视觉基础概率,因为在没有任何语言上下文的情况下,模型需要视觉信息来确定是单数还是复数。
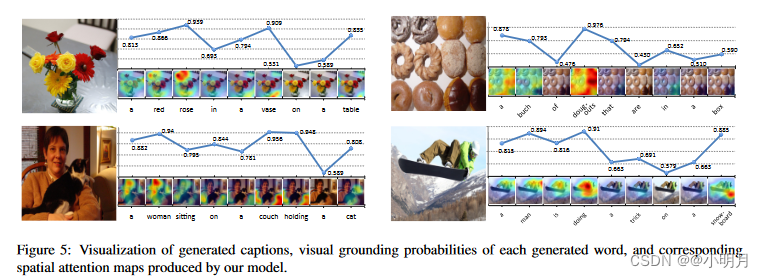
图5主要是sentinal gate概率和注意力的可视化。重点可以关注一下单词a的概率。

表3是相同的单词在COCO和Flickr30k数据集上的Visual grounding probabilities。
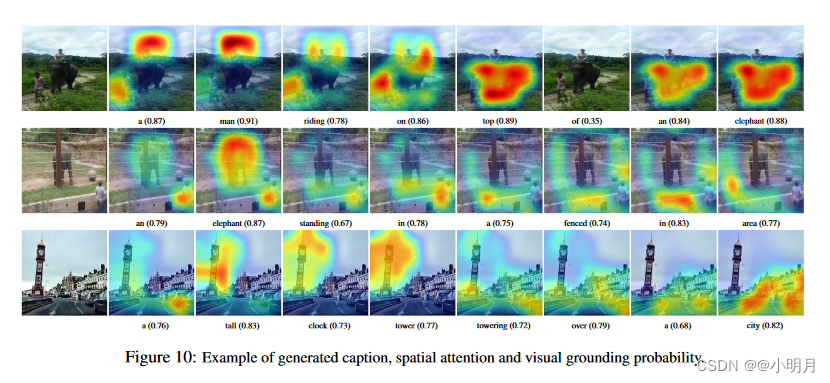
图10是Visual grounding probabilities的可视化示例。
自适应注意力分析
一、参考博客:博客
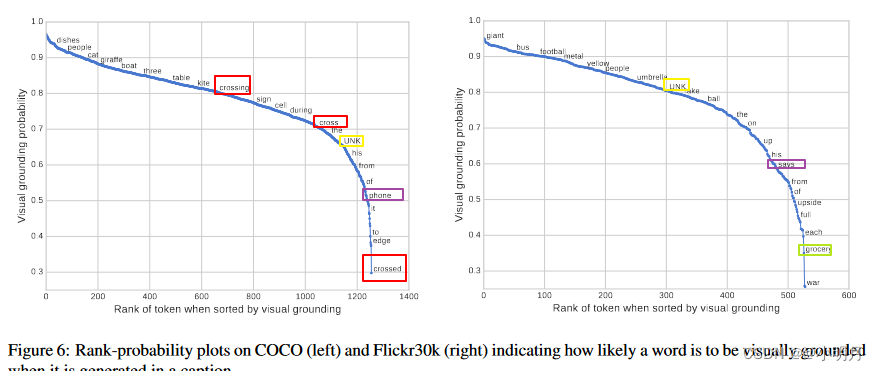
上图6对COCO和Flickr30k中词典的词在生成描述时被认为是视觉词的平均概率进行排序。两个数据集间的相关性为0.483。其中,
- 对于一些实际是视觉词,但是与其他词具有高度相关性的词,模型会把它视作非视觉词,如"phone",与cell的相关性极高,因此本文的模型中它的概率比较低;
- 当生成“UNK”单词时,模型学会较少关注 COCO 上的图像,而是更多关注 Flickr30k 上的图像。
- 相同的单词具有不同的形式也会导致不同的概率,比如,“crossing”、“cross”和“crossed”。模型没有依赖外部语料,完全是自动地发现这些趋势。
二、本文首次使用弱监督定位(weakly supervised location)来评估图像描述的空间注意力。给定单词 w t w_t wt和attention map α t α_t αt,本文首先分割注意力值大于th的区域(图标准化后最大值为1),其中th是使用COCO数据值估计的每类阈值验证分割。采用覆盖分割图中最大连通分量的bounding box,并使用生成的bounding box与真实bounding box的交集IOU(intersection over union)作为定位准确率。
- 具体做法是:首先使用NLTK中的WordNetLemmatizer(词形还原器)对描述中的每个单词进行词形还原。例如将people、women、woman、boy、girl、men、player、baby映射到COCO数据集中的类别person;将plane、jetliner、jet映射到COCO数据集中的类别airplane,taxi映射到类别car,本文还将类别dining table改为table,对于其余类别,报留原始名称。然后图像中attention weight大于阈值的部分会被分割出来,取覆盖分割同中最大连通分量的bounding box,并计算生成的和真实的bounding box的IOU。
spatial attention model和adapative attention model的平均定位准确率分别是0.362和0.373。这表明知道何时关注图像也能让模型更清楚到底要去关注图像的哪一部分。

图11是生成的描述和弱监督定位的可视化。红色框是真实的bounding box,蓝色框是使用spatial attention map的预测位置。
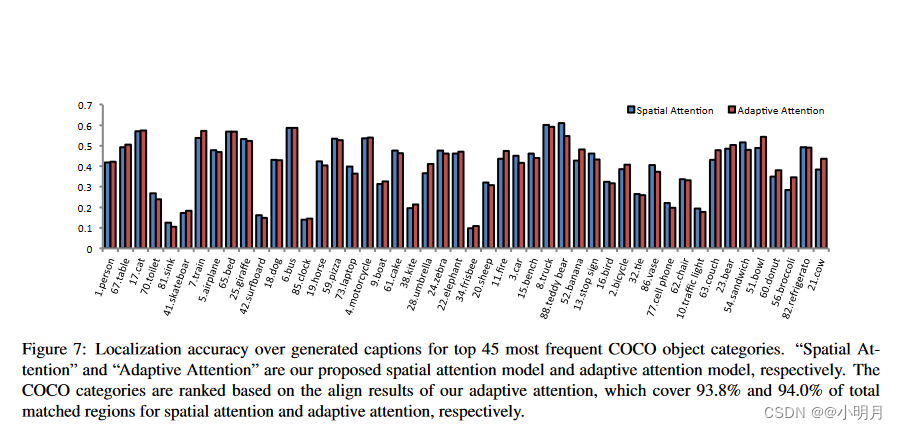
图7显示了COCO数据集中前45个出现最频繁的类别生成图像描述的定位精确度。
这两个模型在"cat"、“bed”、“bus”、“track"等类别上表现良好。但是在较小的物体上,比如"sink(水槽)”、“surfboard(冲浪板)”、“clock”、“firsbee(飞盘)”,两种模型的表现都相对较差。这是因为attention maps是直接从7×7的feature map中直接放大的,而这样维度的特征图会丢失很多空间分辨率和细节信息,使用更大的特征图可以提高性能。

图8可视化了单词of在spatial attention和adapative attetion中的注意力分布。可以看到有视觉哨兵的话,生成of对图像没有一点关注,但是如果没有visual sentinal,非视觉词of的注意力就会高度集中在这些图像的边缘部分,可能会在反向传播时形成噪声影响训练。
结论
本文提出了spatial attention机制,然后在此基础上在LSTM上扩展了视觉哨兵,以此提出adaptive attention model,这使得在生成下一个描述时,对于非视觉词,模型会更多的关注语义,对于视觉词,会更多的关注图像视觉特征。解决了show,attend and tell中生成单词时所有的单词都要模型关注图像的某一区域的问题。并且经过在MS COCO数据集和Flickr30k上测试,性能大幅领先。
但是本文模型,对于一些较小的物体,定位精度较差,因为使用的feature map是7×7的,使用更大的特征图性能应该会更好。














 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









