







文章目录
提示:如果你没有看【ElasticSearch】ElasticSearch 快速入门(精讲),请先去学习一下。
elasticsearch的官方使用文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-getting-started.html
一、创建一个springboot项目
创建的时候,需要注意的是将elasticsearch相关的依赖勾上,如下
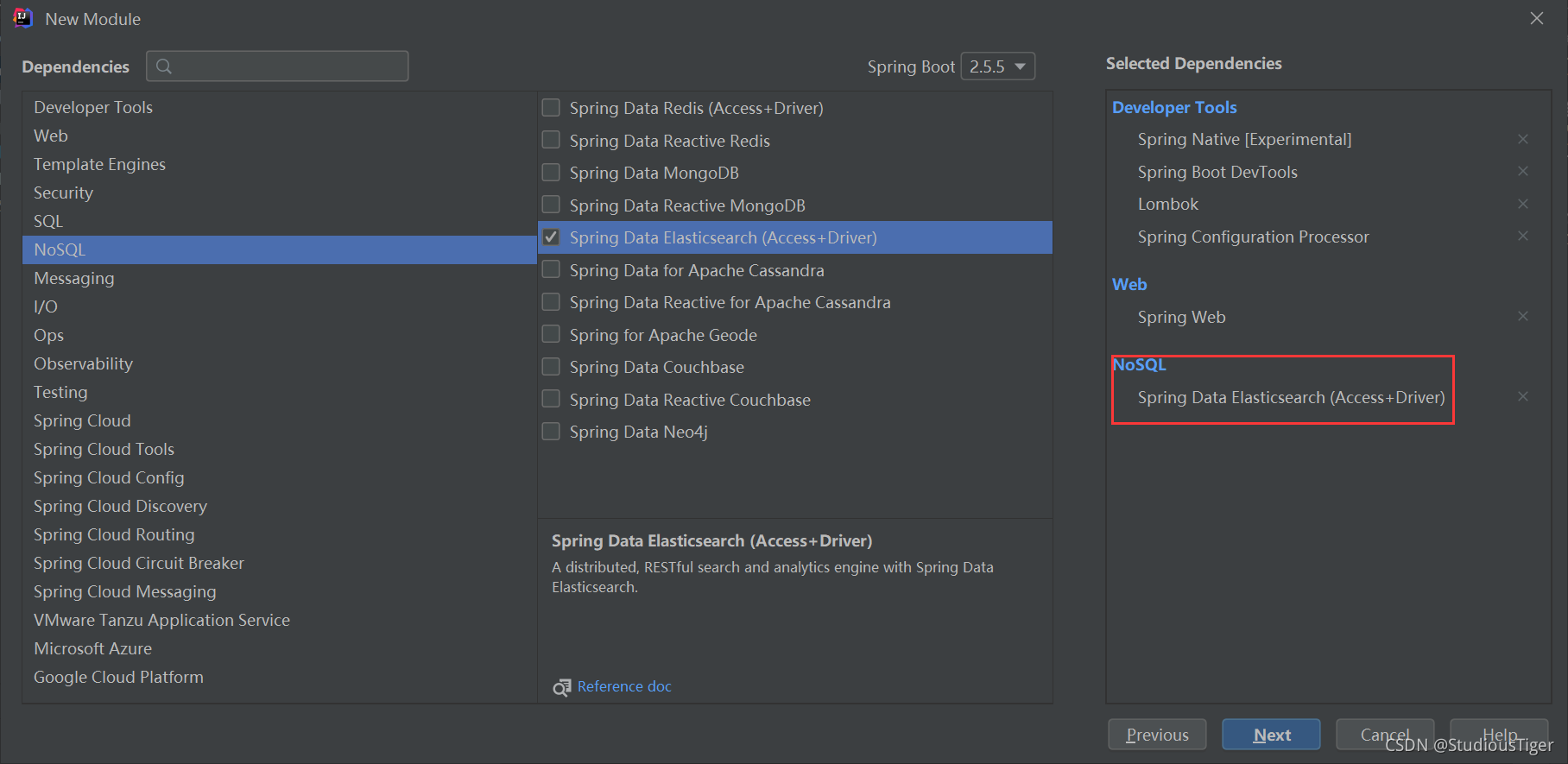
当我创建完成之后,需要保持elasticsearch的依赖于本地的elasticsearch的版本一致,我们可以看到springboot默认的版本信息是7.12.1
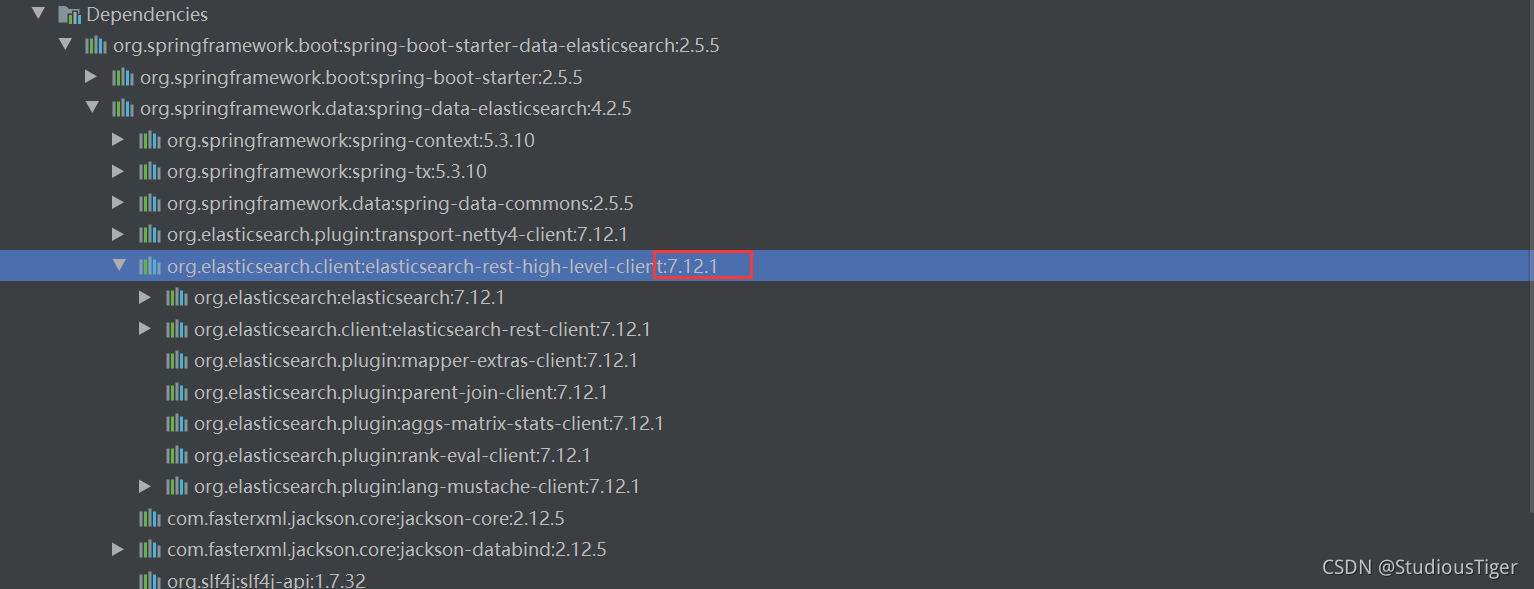
我本地的elasticsearch的版本是7.6.1,所以我们不需要手动修改elasticsearch的版本信息(如果你的springboot中的elasticsearch版本高于你的本地的elasticsearch版本,那么你可以不用修改版本)

<elasticsearch.version>7.6.1</elasticsearch.version>
根据elasticsearch的官网的初始化指南,我们下一步需要配置RestHighLevelClient,如下:
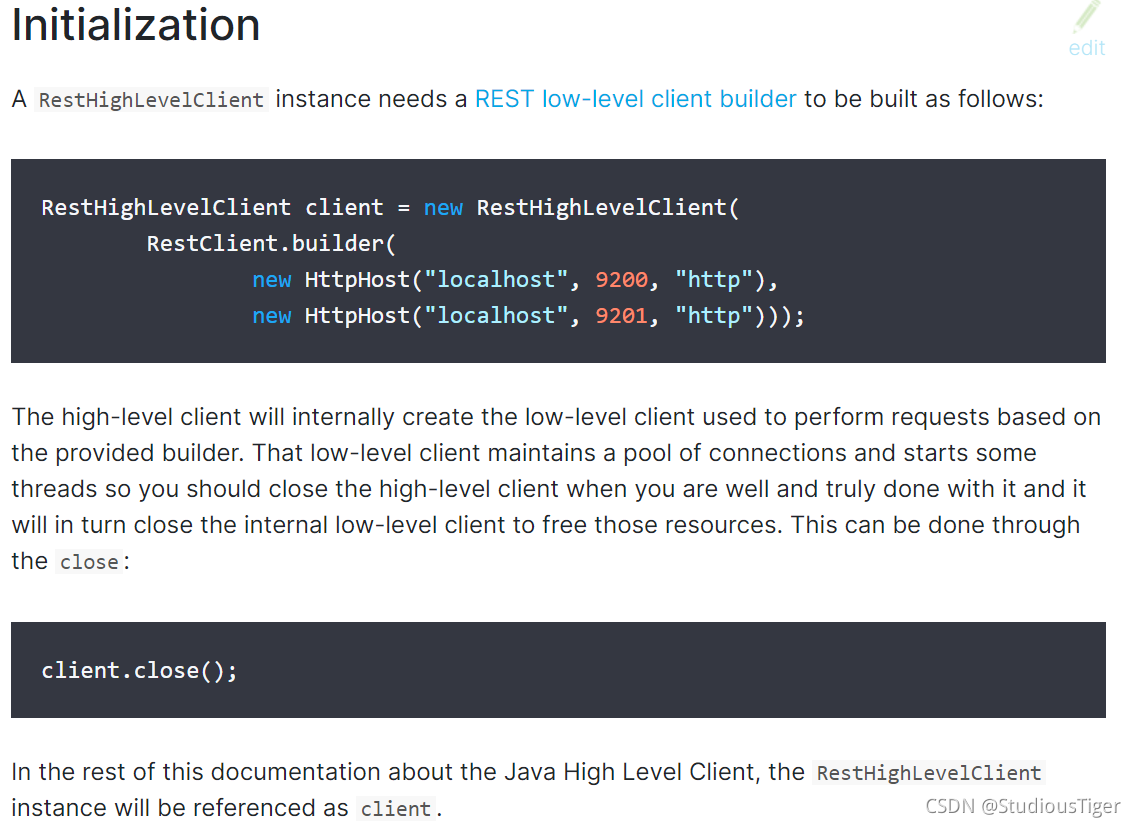
在springboot中,我们只需要将RestHighLevelClient注入到springboot容器中即可
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")
));
return client;
}
}
二、关于索引的API操作
我们需要开启elasticsearch

开启elasticsearch-head-master

1、创建索引
CreateIndexRequest(“tiger_index”):创建一个索引(tiger_index)请求
client.indices().create(req, RequestOptions.DEFAULT):客户端执行创建索引(tiger_index)的请求
RequestOptions.DEFAULT:我们使用默认的请求操作即可
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//测试创建索引
@Test
void contextLoads01() throws IOException {
//创建索引请求
CreateIndexRequest req = new CreateIndexRequest("tiger_index");
//客户端执行请求
CreateIndexResponse createIndexResponse = client.indices().create(req, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
client.close();
}
我们可以发现,tiger_index索引确实被创建了

2、获取索引
GetIndexRequest(“tiger_index”):创建一个获得索引(tiger_index)的请求
client.indices().exists(tiger_index, RequestOptions.DEFAULT):判断索引(tiger_index)是否存在
RequestOptions.DEFAULT:我们使用默认的请求操作即可
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//测试获取索引
@Test
void contextLoads02() throws IOException {
GetIndexRequest tiger_index = new GetIndexRequest("tiger_index");
boolean exists = client.indices().exists(tiger_index, RequestOptions.DEFAULT);
client.close();
System.out.println(exists);
}

3、删除索引
DeleteIndexRequest(“tiger_index”):创建一个删除索引(tiger_index)的请求
client.indices().delete(tiger_index, RequestOptions.DEFAULT) :执行删除索引(tiger_index)的请求
RequestOptions.DEFAULT:我们使用默认的请求操作即可
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//测试删除索引
@Test
void contextLoads03() throws IOException {
DeleteIndexRequest tiger_index = new DeleteIndexRequest("tiger_index");
AcknowledgedResponse delete = client.indices().delete(tiger_index, RequestOptions.DEFAULT);
client.close();
System.out.println(delete.isAcknowledged());
}

可以发现tiger_index确实没有了
三、关于文档的API操作
1、添加文档记录
通过java来操作elasticsearch的插入时,我们只需要将实体类转换成json进行操作即可。
创建一个实体类
@Component
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private int age;
private String gender;
}
编写插入代码
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//插入操作
@Test
void contextLoads04() throws IOException {
// 创建实体类
User user = new User("胡学好01", 18, "男");
// 获取索引请求
IndexRequest req = new IndexRequest("tiger_index");
req.id("1"); //id
req.timeout(TimeValue.timeValueSeconds(1)); // 超时
// 将user转成json,并传入请求
req.source(JSON.toJSONString(user), XContentType.JSON);
// 客户端实行index操作
IndexResponse index = client.index(req, RequestOptions.DEFAULT);
client.close();
System.out.println(index.toString());
System.out.println(index.status());
}


2、获取文档记录
先判断要获取的文档是否存在
GetRequest(“tiger_index”, “1”):创建一个获取文档的get请求
fetchSourceContext(new FetchSourceContext(false):不获取上下文
storedFields(“none”):不获取字段
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//判断文档是否存在
@Test
void contextLoads05() throws IOException {
// 创建一个请求
GetRequest getRequest = new GetRequest("tiger_index", "1");
// 不获取上下文,提高判断的效率
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
// 判断是否存在
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
client.close();
System.out.println(exists);
}

获取文档信息
client.get(getRequest, RequestOptions.DEFAULT):客户端执行get操作获取elasticsearch的文档
documentFields.getSourceAsString():将获取的文档转化成字符串
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//获取文档信息
@Test
void contextLoads06() throws IOException {
// 创建一个请求
GetRequest getRequest = new GetRequest("tiger_index", "1");
// 获取文档
GetResponse documentFields = client.get(getRequest, RequestOptions.DEFAULT);
client.close();
// 将文档转化成字符串(你也可以进行其他操作)
String sourceAsString = documentFields.getSourceAsString();
System.out.println(sourceAsString);
}

3、更新文档记录
UpdateRequest(“tiger_index”, “1”):获取一个更细请求
updateRequest.doc(JSON.toJSONString(user), XContentType.JSON):和我之前使用Kibana更新操作是一样,需要一个doc
client.update(updateRequest, RequestOptions.DEFAULT):客户端执行更新操作
updateResponse.status():查看更新操作的状态
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//更新文档信息
@Test
void contextLoads07() throws IOException {
// 获取一个更新请求操作
UpdateRequest updateRequest = new UpdateRequest("tiger_index", "1");
updateRequest.timeout("1s"); // 设置超时
User user = new User("胡学好01", 22, "男");
// 装入更新后的数据
updateRequest.doc(JSON.toJSONString(user), XContentType.JSON);
// 客户端执行更新操作
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
// 查看状态
client.close();
System.out.println(updateResponse.status());
}


4、删除文档记录
DeleteRequest(“tiger_index”, “1”):获取一个删除请求
client.delete(request, RequestOptions.DEFAULT):客户端执行删除操作
delete.status():查看删除状态
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//删除文档信息
@Test
void contextLoads08() throws IOException {
// 获取一个删除请求操作
DeleteRequest request = new DeleteRequest("tiger_index", "1");
request.timeout("1s"); //设置超时
// 客户端执行删除操作
DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT);
client.close();
System.out.println(delete.status());
}


5、批处理文档操作
在实际的开发中,我们往往不会进行一条一条的操作,尤其是对于添加文档记录操作,elasticsearch给我提供了一个批量处理文档的实体类(BulkRequest),我们可以使用client对操作进行批量的处理。
new BulkRequest():获取一个批处理请求
bulkRequest.add(…):向批处理请求中添加操作(可以是添加、查找、更新和删除)
client.bulk(bulkRequest, RequestOptions.DEFAULT):客户端执行批处理操作
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
// 批量操作文档信息
@Test
void contextLoads09() throws IOException {
// 获取一个批处理请求
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s"); // 设置超时
ArrayList<User> users = new ArrayList();
users.add(new User("胡学好01", 22, "男"));
users.add(new User("胡学好02", 23, "女"));
users.add(new User("胡学好03", 24, "男"));
users.add(new User("胡学好04", 25, "女"));
users.add(new User("胡学好05", 26, "男"));
users.add(new User("胡学好06", 27, "女"));
for (int i = 0; i < users.size(); i++) {
// 向批处理请求中设置插入操作(当然你也可以进行其他操作)
bulkRequest.add(
new IndexRequest("tiger_index") // 设置操作的索引
.id(""+(i+1)) // 设置id(不设置则为随机的ID)
.source(JSON.toJSONString(users.get(i)),XContentType.JSON) // 设置待插入的资源
);
// 客户端执行批处理操作
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
client.close();
System.out.println(bulk.status()); //查看状态
}
}

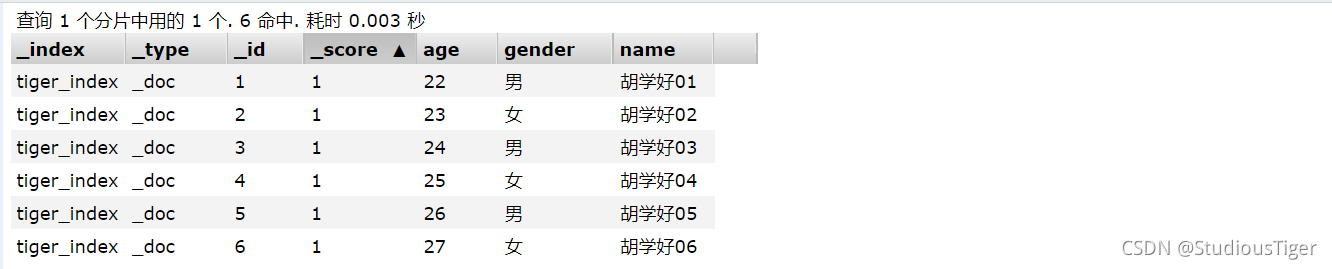
6、查询操作(☆☆)
① 简单的查询
查询需要的对象结构关系:
client.search(searchRequest, RequestOptions.DEFAULT)
new SearchRequest()
searchRequest.source(searchSourceBuilder)
new SearchSourceBuilder()
searchSourceBuilder.query(XXXXQueryBuilder)
searchSourceBuilder.timeout
QueryBuilders.XXXXQuery()
解释:
client.search(searchRequest, RequestOptions.DEFAULT):客户端执行查询操作
new SearchRequest():创建一个查询请求
searchRequest.source(searchSourceBuilder):想查询请求中添加查询资源
new SearchSourceBuilder():创建一个查询资源构造器,用于设置特定的查询操作
searchSourceBuilder.query(XXXXQueryBuilder):设置特定的查询操作
QueryBuilders.XXXXQuery()<:构建特定的查询操作
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
// 查询操作文档信息
@Test
void contextLoads10() throws IOException {
// 1 获取一个查询请求
SearchRequest searchRequest = new SearchRequest();
// 3 构建一个SearchSourceBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 5 构建一个MatchQueryBuilder(你也可以构建其他的,如:MatchPhrasePrefixQueryBuilder,MatchAllQueryBuilder)
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "胡学好");
// 4 发现 query中需要 QueryBuilder
searchSourceBuilder.query(matchQueryBuilder);
// 设置超时,发现必须要传入TimeValue
searchSourceBuilder.timeout(new TimeValue(10, TimeUnit.SECONDS));
// 2 点开发现source中需要一个SearchSourceBuilder
searchRequest.source(searchSourceBuilder);
// 6 客户端执行搜索
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
client.close();
// 获取 getHits
System.out.println(JSON.toJSONString(search.getHits()));
System.out.println("=======================================");
// 遍历 getHits
for (SearchHit hit : search.getHits()) {
System.out.println(hit.getSourceAsString());
}
}

② 高亮查询(☆☆)
我们在进行京东搜索的时候,我们我们会发现有一些高亮显示,如下:

这种效果我们的elasticsearch中也是可以进行实现的,期无非就是HTML代码,例如:对于胡学好,我们可以进行<em style='color:red'>胡</em><em style='color:red'>学</em><em style='color:red'>好</em>
下面我们进行实现高亮搜索,高亮搜索实在简单搜索的基础上实现的。
第一步:配置高亮字段
//设置高亮显示
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<em style='color:red'>");
highlightBuilder.postTags("</em>");
highlightBuilder.field("name");
highlightBuilder.requireFieldMatch(false); //每一个记录总只设置一个高亮
searchSourceBuilder.highlighter(highlightBuilder);
第二步:获取高亮字段,并在其重写如hit的map中
// 遍历 getHits
for (SearchHit hit : search.getHits()) {
// 获取高亮
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField name = highlightFields.get("name"); //获取高亮中的name属性
// 获取hit并将其转换成map
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
// 如果高亮的name存在
if(name!=null){
// 获取高亮的碎片(之所以是碎片,是因为elasticsearch会设置高亮的字段中的将每一个字设置前后缀)
Text[] fragments = name.fragments();
String new_name = "";
// 将高亮的碎片拼接成一个完整的字符串
for (Text fragment : fragments) {
new_name += fragment;
}
// 将原本的sourceAsMap中的name进行替换
sourceAsMap.put("name",new_name);
}
System.out.println(sourceAsMap);
}
完整代码
// 查询操作文档信息
@Test
void contextLoads10() throws IOException {
// 1 获取一个查询请求
SearchRequest searchRequest = new SearchRequest();
// 3 构建一个SearchSourceBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 5 构建一个MatchQueryBuilder(你也可以构建其他的,如:MatchPhrasePrefixQueryBuilder,MatchAllQueryBuilder)
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "胡学好");
// 4 发现 query中需要 QueryBuilder
searchSourceBuilder.query(matchQueryBuilder);
// 设置超时,发现必须要传入TimeValue
searchSourceBuilder.timeout(new TimeValue(10, TimeUnit.SECONDS));
//@=========================================================================
//设置高亮显示
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<em style='color:red'>");
highlightBuilder.postTags("</em>");
highlightBuilder.field("name");
highlightBuilder.requireFieldMatch(false); //每一个记录总只设置一个高亮
searchSourceBuilder.highlighter(highlightBuilder);
//@=========================================================================
// 2 点开发现source中需要一个SearchSourceBuilder
searchRequest.source(searchSourceBuilder);
// 6 客户端执行搜索
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
client.close();
// 遍历 getHits
for (SearchHit hit : search.getHits()) {
//&=========================================================================
// 获取高亮
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField name = highlightFields.get("name"); //获取高亮中的name属性
//&=========================================================================
// 获取hit并将其转换成map
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
//%=========================================================================
// 如果高亮的name存在
if(name!=null){
// 获取高亮的碎片(之所以是碎片,是因为elasticsearch会设置高亮的字段中的将每一个字设置前后缀)
Text[] fragments = name.fragments();
String new_name = "";
// 将高亮的碎片拼接成一个完整的字符串
for (Text fragment : fragments) {
new_name += fragment;
}
// 将原本的sourceAsMap中的name进行替换
sourceAsMap.put("name",new_name);
}
//%=========================================================================
System.out.println(sourceAsMap);
}
}

✈ ❀ 希望平凡の我,可以给你不凡の体验 ☂ ✿ ,白嫖有罪 ☠ ,记得关注哦 ❥(^_-)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









