









hashmap源码解析
jdk7 :hashmap
简单给介绍下,java1.7版本的hashMap。
它的底层是由数组和链表组成的,里面就存的Entry对象,把key和value都放入到Entry里面,数组和链表都是放在堆里面的,引用的是地址

添加数据
先讲讲hashmap是数组怎么添加数据的。
它是通过key值通过hashcode来算出的一个值(相当于一个随机数)
然后把值按照容量大小取余,就得到数组下标。
那它的链表又怎么填加呢,这就要涉及到算法。
1.头插法 ,2.尾插法
等会讲了得时候,想一下到底是采用得哪一种
我们来看一下put方法

我们来看 hash(key)方法是怎么回事

hashseed是hash种子,hash种子是用来算hashcode才会用到的,让hash算法更复杂,让hash值更加散列一点,h^的异或运算就是4次扰动也是这样。可以当容量超过多少的时候,就可以设置hash种子,让hash算法的散列性更高一点。
扩容的时候也使用了hash种子
rerurn sun.misc.Hashing.stringHsh32((String) k);最终就是设置hash种子的

在编译运行前,就可以设置hash种子

这里它并没有用传统的方式用%去取余,而是采用为运算,假如下标数字9的hsahcode是57,默认容量是16,我们看一下是怎么算出下标的,这里在put方法中使用indexFor方法

这里是把:容量16-1再做与计算
57 0011 1001
16 0000 1111
0000 1001 这里算出下标就是9
我们就把数据插入到数组的下标9这里

假如另外一个key算出的hashcode是0010 1001
0010 1001
16 0000 1111
0000 1001 这里同样算出9
这时候就出现了链表.
那我们是采用头插法还是尾插法呢
先给看看尾插法是怎样的
这个是封装类
package dcp.it;
public class Node {
private Object value;//内容
public Node next;//节点
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
public Node(Object value, Node next) {
this.value = value;
this.next = next;
}
@Override
public String toString() {
return "Node{" + "value=" + value + ", next=" + next + '}';
}
}
在看一下尾插法的测试类
@Test
public void test1() {
Node header1 = new Node(1, null);
//这是尾部插入
header1.next = new Node(2, null);
//获取header1的next
Node header2 = header1.getNext();
header2.next= new Node(3, null);
System.out.println(header1);
// Node{value=1, next=Node{value=2, next=Node{value=3, next=null}}}
for (Node i = header1.next; i !=null; i=i.next) {
if (i.next == null) {
// System.out.println(i.getValue());
if (i.getValue() == (Object) 5) {
break;
}
i.next=new Node(5, null);
}
}
System.out.println(header1);
//Node{value=1, next=Node{value=2, next=Node{value=3, next=Node{value=5, next=null}}}}
}
在来看看头插法
@Test
public void test2() {
Node header = new Node(1, null);
//这是头部插入
header= new Node(2, header);
header= new Node(3, header);
header= new Node(5, header);
System.out.println(header);
//Node{content=3, next=Node{content=1, next=Node{content=2, next=null}}}
}
大家能看出来头插法和尾插法的差别吗?
尾插法:在栈里面添加了新的Node对象,在堆里面new了一个node
头插法:就只在堆里面new一个node,就不需要去遍历获取到next的属性为null才往里面添加数据。
所以要实现快速插入,java1.7中就采用了头插法的方式,而在Java1.8以后都是采用的尾插法。
头插法就出现下面的情况

那它是怎么把header2移动到数组的下标去呢

这时候看见程序中这行代码
header= new Node(2, header);
就是把旧header存入到new的Node的next属性中,然后重新赋值给header就来到了数组的下标9中了
我们回到put方法中看一下,for循环里面是怎么回事?

就是算出的下标来,遍历链表,当遇见了相同的key的时候,在把新的value覆盖旧的value,然后返回旧的value,所以当你们在put相同key的时候其实是有返回值的
接下来,在看看modCount++是怎么回事?
其实modCount++就是代表修改次数,在hashmap的remove也采用了
这里我们采用了一个案例来简单看一下,迭代器Iterator对象来遍历hashmap


我们看一下iterator()方法去干什么了

去返回了一个newKeyIterator方法
我们在看一下

去new KeyIterator对象
再来瞅瞅

咦,这个类继承了HashIterator
一般new对象都会先执行父类的构造函数,我们再去看看

这个不就是我们要的modCount吗
相对于我们知道expectedModCount了对吧,接下来就会有用了
当你put方法使用2次,modCount++ 就等于2了
赋值expectedModCount也就等于2

到这里我们看一下whlie里面的内容
hashNext里面就是判断

这里面就是判断next是否为空
不为空我们就进行下面的
我们看一下迭代器next方法

这里就调用了KeyIterator对象的next方法
再去调用父类的nextEntry方法

这里就判断modCount和expectedModCount是否相等就抛异常
从一开始modCount和expectedModCount都等于2,是不会抛异常的
所以进行下一步
我们看一看其实第一次遍历,其实key是等于2的

我们在看一下hashmap的remove方法
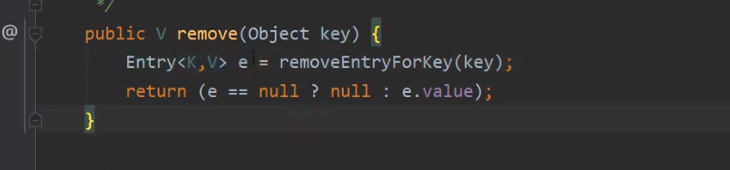
在进入removeEntryForKey
截图不完整,在看下一张
这时候我们的modCount就发生改变了,而expectedModCount却没有发生变化
当我们在回到第二次遍历的时候

这里就重复上面的步骤来到了
就来判断modCount和expectedModCount是否相等就抛异常
modCount=3 和expectedModCount=2 就会抛出异常

那我们怎么解决这个问题呢
这时候就可以报hashmap对象改成iterator对象就可以了

我们看看iterator对象的remove方法

看见了吗,这里的expectedModCount有重新赋值,这个方法执行完,expectedModCount就会变成2
当我们在回到遍历第二次的时候,就不会出现刚刚的异常了
其实在赋值上面还是调用的hashmap的removeEntryForKey方法
那么这个modcount到底是干嘛的呢?
其实就一个快速失败的容错机制
就是在多线程的时候,一个在遍历,一个线程在执行put或remove的时候,出现并发问题。
扩容
那我们就回到put方法这里来看看下一步

看见addEntry就可以大概知道是扩容了吧,那我们就简单说说,上面if()里面的内容
先看看默认容量16怎么来的

这个简单的位运算就不细讲了
if就是空数组的时候执行这个方法inflateTable(threshold);
这个threshold代表阈值,是通过 (容量*加载因子)获得的扩容阈值
加载因子是0.75,至于为什么是0.75呢?
就在你默认容量16*0.75=12的时候,超过12就实现2倍扩容
当你小于0.75,就开始扩容的话,相当于小于12开始扩容,就会造成容量空间资源浪费,当你大于0.75就会导致扩容效率慢,所以结果java公司的计算0.75是最合适的值。
那我们就进入inflateTable方法看一下

那我们看看roundUpToPowerOf2方法看一下

阈值大于最大容量值吗,那我们就去到highestOneBit方法中
那我们就把阈值17带到方法中算算


我们回到上一步,看见highestOneBit里面的参数是(number-1)<<1,就先执行左移位运算
这样相当于把容量扩大了一倍,算出他的2的幂次方数的容量
就如同这样,这就是17算出来的容量

那么我们为什么要移动16位呢,明明8位就得到同样的数据???
其实我们想一想int类型又多少位,4字节32位,是不是刚好就是移动的位数了,就是防止越界
那我们在回到inflateTable方法

看一下initialHashSeedAsNeed方法

这里就是之前所说,在运行前配置hash种子,判断是否有hash种子,没有配置默认为0
if的内容终于结束了,我们再来看看addEntry的方法

来来来,别放弃,我们继续

if里面就是当size大于阈值的时候就实现2倍扩容i
为什么要扩容呢?
就是为了把链表变短,加快查询速度,当我们添加数据的时候,链表越长,查询就越慢
那他是怎么变短的呢,
一开始不是说了吗,它的数组下标的通过容量取余算出来的,当你容量变大了,它的下标是不是变了呢,
0011 1001
0010 1001
一开始容量为16的时候算出下标都是9
0011 1001
16 0000 1111
index 0000 1001
------------------
0010 1001
16 0000 1111
index 0000 1001
我们看看容量为32下标是多少
0011 1001
32 0001 1111
index 0001 1001 25
------------------
0010 1001
32 0001 1111
index 0000 1001 9
看出差别了吧
那我们去看看它的resize方法咯

这里transfer方法就把旧的hashmap重新放到了扩容后的hashmap中咯
hashmap多线程安全问题
来来继续看看

看见了吗,遍历table数组,在把链表重新放入新的table中了。
你以为就这样结束了吗???
还没完了,再来画个图讲讲多线程怎么出现不安全的情况,嘿嘿,惊不惊喜,意不意外?
当2个线程都在执行的时候,线程2卡在了这个地方

这时候线程1旧正常执行下面的内容

e指向table的数组中的一个entry
e.next赋值给了next
我们看看这步


再来


看到这里是不是很奇妙??
是不是想到之前的头插法了???
对的没错,就是头插法
在看看下一步


这里的whlie才完了一圈

我们按一下快进
再来两圈

这样我们的线程1旧完成了,线程2终于获得了权限,当我们的线程2的e2和next2又指向哪呢
这其实是2个线程都生成的数组,当第一个线程执行完了,线程2开始执行
这也是一开始线程2卡住的地方

e2和next2其实还是指向之前的位置
线程2 是执行完这行代码卡住的

那我们开始下一步代码


再来下一步


继续
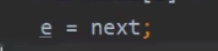

这时候,完成一圈while了
再来看看第二圈


再来


看见上面了,是不是看见过???
没错,就是上一张图,这时候旧出现了问题了
来来,继续走代码


再来
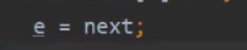

这一圈完了,我们下一圈见


再看


哎,是不是这时候旧出现循环链表了
再来下一步


再来



这时候e2就为null跳出循环了,这时候,循环链表就在hashmap中了
出现这种情况,就在get和put就会出现了死循环
这就是多线程扩容的情况下hashmap出现循环链表的情况。
咋们终于结束了hashmap1.7的内容了
有啥不清楚的,讲错了的地方,大佬来指点一下下。















 2547
2547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









