







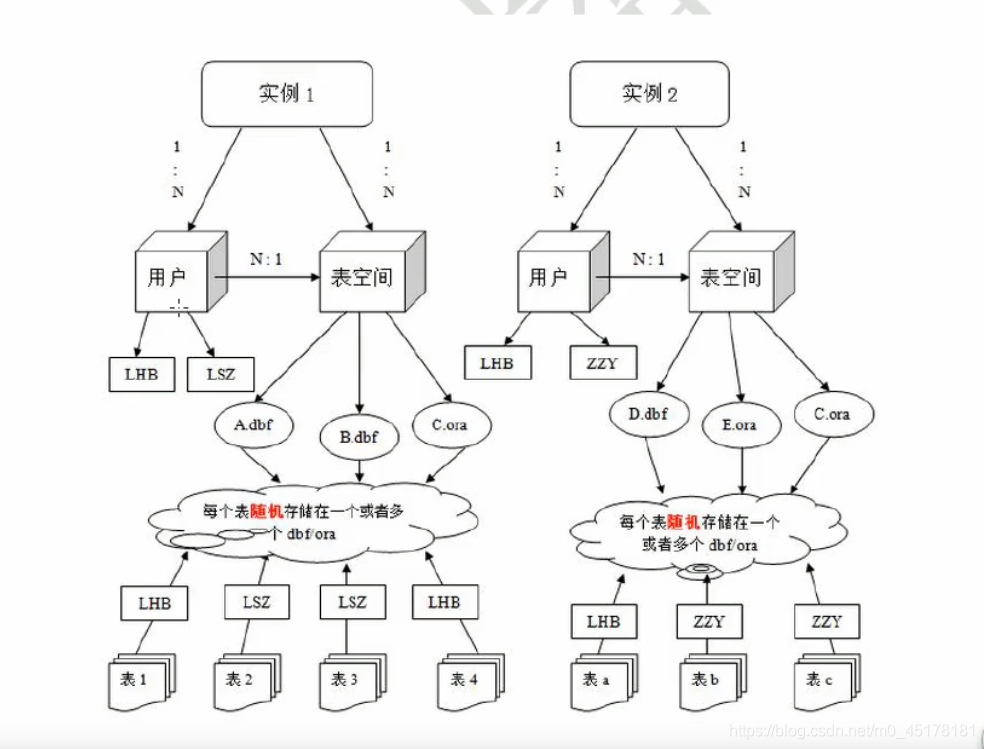
Oracle数据库
oracle体系结构
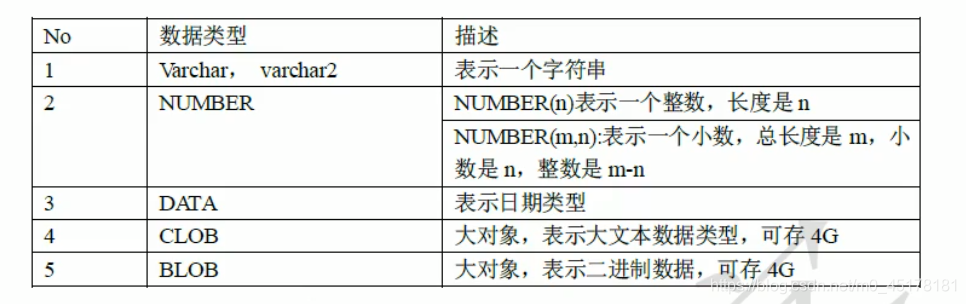
oracle数据类型
oracle导出dmp文件
导出远程oracle数据库(ip为192.168.1.186,端口号为1521,sid为orcl)中,用户tom(密码为tom)的数据,
并将数据存至d:/daochu.dmp中(tom为dba角色,后面本地用户也要赋予相应的角色)
exp tom/tom@192.168.1.186:1521/orcl file=d:/daochu.dmp
oracle还原dmp文件
1.首先创建新的表空间
create tablespace TOOLBOX
logging
datafile ‘C:\oraclexe\app\oracle\oradata\XE\TOOLBOX.dbf’
size 50m
autoextend on
next 32m maxsize unlimited
extent management local;
2.创建用户,赋予权限
create user TOOLBOX identified by 123456;
alter user TOOLBOX default tablespace TOOLBOX;
grant CREATE ANY DIRECTORY,create session,create table,create view,unlimited tablespace to TOOLBOX;
完整创建用户:
CREATE TABLESPACE NNC_INDEX01 -- 表空间
LOGGING
DATAFILE 'D:\javaJDK\IDEA_JAVA\oracle\Oracle\Oracle\ORCL\NNC_INDEX01.DBF' -- 改路径
SIZE 32M
AUTOEXTEND ON
NEXT 32M MAXSIZE 4096M
EXTENT MANAGEMENT LOCAL;
CREATE USER NNC_INDEX01 IDENTIFIED BY NNC_INDEX01; -- 给权限
alter user NNC_INDEX01 default tablespace NNC_INDEX01; -- 给权限
ALTER USER NNC_INDEX01 QUOTA UNLIMITED ON NNC_INDEX01;
GRANT CREATE SESSION TO NNC_INDEX01;
GRANT CREATE CLUSTER TO NNC_INDEX01;
GRANT CREATE DATABASE LINK TO NNC_INDEX01;
GRANT CREATE ANY INDEX TO NNC_INDEX01;
GRANT CREATE ANY TABLE TO NNC_INDEX01;
GRANT CREATE ANY VIEW TO NNC_INDEX01;
GRANT SELECT ANY TABLE to NNC_INDEX01;
GRANT DELETE ANY TABLE to NNC_INDEX01;
GRANT UPDATE ANY TABLE to NNC_INDEX01;
GRANT INSERT ANY TABLE to NNC_INDEX01;
GRANT ALTER SYSTEM TO NNC_INDEX01;
GRANT DEBUG ANY PROCEDURE TO NNC_INDEX01;
ALTER TABLESPACE NNC_INDEX01 ADD DATAFILE 'D:\javaJDK\IDEA_JAVA\oracle\Oracle\Oracle\ORCL\NNC_INDEX01' SIZE 2000M;
ALTER TABLESPACE NNC_DATA01 ADD DATAFILE 'E:\YonYou\FuYouData\fyhrp_20210105\NNC_DATA_ADD1008' SIZE 2000M autoextend ON NEXT 100m maxsize unlimited;
3.登录ToolBox用户
sqlplus 用户名/密码
4.创建DIRECTORY是dmp文件存放的目录
把dmp存放在oracle数据库的orcl目录下的一个新建dpdump文件下
然后创建sql语句:
CREATE OR REPLACE DIRECTORY
DMPDIR AS 'D:\javaJDK\IDEA_JAVA\oracle\Oracle\Oracle\ORCL\dpdump';
5.编写导入impdp语句
impdp toolbox/123456 (用户/密码) DIRECTORY=DMPDIR DUMPFILE=hz_toolbox_20160613.dmp(dmp路径) full=y
impdp system/du012340 DIRECTORY=DMPDIR DUMPFILE=2020-10-24_HRP.DMP full=y
6.如果表空间不够,增加表空间
ALTER TABLESPACE NNC_DATA01 ADD DATAFILE 'D:\javaJDK\IDEA_JAVA\oracle\Oracle\Oracle\ORCL\NNC_DATA_ADD01' SIZE 2000M;
oracle覆盖原有的dmp文件
导入dpm文件到oracle
system
//创建表空间
//1、创建新用户lyy及密码lyy
create user jjzx0107 identified by jjzx0107;
//其中,创建新用户登录cmd->sqlplus->登陆system/123456
//2、赋予权限
grant connect,resource,dba to jjzx0107;
//dba:拥有全部特权,是系统最高权限,只有DBA才可以创建数据库结构。
//resource:拥有Resource权限的用户只可以创建实体,不可以创建数据库结构。
//connect:拥有Connect权限的用户只可以登录Oracle,不可以创建实体,不可以创建数据库结构。
//3.导入dmp文件,覆盖原有的用户:REMAP_SCHEMA=hrp:jjzx0107
impdp jjzx0107/jjzx0107 dumpfile=2020-12-29_HRP.dmp ignore=n logfile=2020-12-29_HRP_expdp.log DIRECTORY=DMPDIR REMAP_SCHEMA=hrp:jjzx0107
//
impdp fyhrp20210125/fyhrp20210125 dumpfile=fyhrp_20210124.dmp ignore=n logfile=fyhrp_20210124_HRP_expdp.log DIRECTORY=DMPDIR REMAP_SCHEMA=NNC_INDEX1000:fyhrp20210125 table_exists_action=replace
//在cmd中导入dpm文件
imp lyy/lyy file='G:\5系列\5系列home\20171030.dmp' full=y ignore=y;
imp lituo1/lituo1 file='F:\lituo\daochu.dmp' full=y ignore=y;
//方法二、plsql导入的
tools->import tables->选择importfile
----------------
drop user 用户名 cascade;
imp lyy/lyy file='G:\32位\back\JXBZSNC20180201.dmp' full=y ignore=y;
CREATE OR REPLACE DIRECTORY DMPDIR AS 'G:\32位\back\';
impdp cqzyy0822/cqzyy0822 DIRECTORY=DMPDIR DUMPFILE=JXBZSNC20180201.dmp full=y
create table sm_pub_filesystem (x int);
impdp jjzx0107/jjzx0107 dumpfile=2020-12-29_HRP.dmp ignore=n logfile=2020-12-29_HRP_expdp.log DIRECTORY=DMPDIR REMAP_SCHEMA=hrp:jjzx0107
EAS数据库还原通用操作指导
--EAS数据库还原通用操作指导
--以下操作是建立在ORACLE程序已经安装好,ORACLE数据库已经创建好的条件上,注意版本匹配和选择UTF-8数据集
--以下的命令符:#或$ 表示在小机系统上执行,同样的命令在Windows下,直接进入cmd执行
--注意本文所有语句执行时一定不要选择自动换行
----------------------------------------------------------------------------------------
--一、数据文件备份
--1.1首先确认数据库中已经创建了物理路径的目录名称
#su - oracle
$sqlplus /nolog
SQL>conn /as sysdba
SQL> select * from dba_directories;
--如果检查发现没有目录名称,则执行新建目录命令
--WINDOWS环境下
CREATE DIRECTORY EASBAK as 'D:\orabak';
--小机环境下
CREATE DIRECTORY EASBAK as '/app/easbak';
--创建并替换当前目录
create or replace directory EASBAK as '/opt/easbak';
--针对目录给用户授权
grant read,write on directory EASBAK to NEWDB850BC;
--确认对应目录是否有足够的磁盘空间,查看oracle帐户是否有读写权限 查看linux文件夹的权限:ls -ld 文件夹名称(所在目录)
chown -R oracle.oinstall /opt/easbak
chmod 775 /opt/easbak
chown -R oracle.oinstall /oradata2/easbak/cqjy20181109.dmp
--1.2数据备份命令-按EAS数据中心用户备份数据(注意,此命令不是在SQLPLUS中执行,是在$或cmd窗口下执行)
expdp system/kingdee schemas=zyeas01 directory=EASBAK dumpfile=zyeas01-20170831.dmp logfile=zyeas01-20170831.log
--涉及数据库大的变动时,建议一定要对数据库做一个全库备份:
expdp system/kingdee DIRECTORY=EASBAK DUMPFILE=full.dmp FULL=Y
--排除个别表进行备份
expdp system/kingdee schemas=YHTJ001 DIRECTORY=EASBAK DUMPFILE=yh20181214.dmp logfile=yh20181214.log EXCLUDE=TABLE:\"IN \(\'T_LOG_APP\',\'T_BAS_ATTACHMENT\'\)\"
grant select on T_LOG_APP to test99;
grant select on T_BAS_ATTACHMENT to test99;
---------------------------------------------------------------------------------------------
--二、数据文件还原
--1、安装oracle软件,注意和正式库版本一致或更高,安装过程中注意ORACLE程序和数据库字符集一定都要选UTF-8
--1.1事先确认清楚备份的用户及其表空间名称---必须的
--2、安装完成后使用dbca新建测试数据库testorcl
--3、进入sqlplus
#su - oracle
$sqlplus /nolog
SQL>conn /as sysdba
SQL>
或打开cmd进入sqlplus
--4、执行新建表空间命令创建数据表空间和临时表空间,特别注意,和正式用的EAS数据库中用到的表空间名称要一致
--查找正式库里EAS账套对应的4个表空间,注意表空间名称中间有schemas
select TABLESPACE_NAME,status from dba_tablespaces;
--4.1创建数据表空间
create tablespace EAS_D_zyeas01_STANDARD datafile 'F:\oradata\EAS_D_zyeas01_STANDARD.dbf' size 10000M autoextend ON next 500M maxsize 32000M;
--给表空间增加数据文件
ALTER TABLESPACE EAS_D_zyeas01_STANDARD ADD DATAFILE 'F:\oradata\EAS_D_zyeas01_STANDARD01.dbf' SIZE 2000M AUTOEXTEND ON NEXT 500M MAXSIZE 30000M;
--4.2创建临时表空间:
create temporary tablespace EAS_T_zyeas01_STANDARD tempfile 'F:\oradata\EAS_T_zyeas01_STANDARD.dbf' size 1000M autoextend ON next 500M maxsize 10000M;
--4.3创建索引和临时数据表空间
create tablespace EAS_D_zyeas01_TEMP2 datafile 'F:\oradata\EAS_D_zyeas01_TEMP2.dbf' size 1000M autoextend ON next 500M maxsize 32000M;
create tablespace EAS_D_zyeas01_index datafile 'F:\oradata\EAS_D_zyeas01_index.dbf' size 2000M autoextend ON next 500M maxsize 32000M;
--5、执行新建用户命令,并指定对应的表空间:
CREATE USER zyeas01 IDENTIFIED BY VALUES 'password' DEFAULT TABLESPACE "EAS_D_zyeas01_STANDARD" TEMPORARY TABLESPACE "EAS_T_zyeas01_STANDARD";
--修改用户密码命令:alter user zyeas01 identified by password;
--删除表空间命令(同时删除数据文件):DROP TABLESPACE EAS_D_test_index INCLUDING CONTENTS AND DATAFILES;
--修改表空间名称命令:alter tablespace EAS_D_zyeas01_STANDARD rename to EAS_D_zyeas02_STANDARD;
--4.3给表空间增加数据文件
ALTER TABLESPACE EAS_D_zyeas01_STANDARD ADD DATAFILE 'F:\oradata\EAS_D_zyeas01_STANDARD01.dbf' SIZE 2000M AUTOEXTEND ON NEXT 500M MAXSIZE 30000M;
ALTER TABLESPACE EAS_D_TEST99_STANDARD ADD DATAFILE '/oracle/oradata/EAS_D_zyeas01_STANDARD01.dbf' SIZE 2000M AUTOEXTEND ON NEXT 500M MAXSIZE 30000M;
--查询并删除用户和表空间
select username,default_tablespace,temporary_tablespace from dba_users;
select TABLESPACE_NAME,status,contents from dba_tablespaces;
select * from dba_data_files
drop user senci0831 cascade;
DROP TABLESPACE EAS_D_SENCI0831_STANDARD INCLUDING CONTENTS AND DATAFILES;
--5、执行新建用户命令,并指定对应的表空间:
CREATE USER zyeas01 IDENTIFIED BY VALUES 'password' DEFAULT TABLESPACE "EAS_D_zyeas01_STANDARD" TEMPORARY TABLESPACE "EAS_T_zyeas01_STANDARD";
--zyeas01 就是新用户名 password是用户密码,一定要表单引号,不能用双引号,表空间名称用双引号
--注意新建用户时,用户名不要用"",否则会出现新建用户成功,但使用时提示无此用户的情况
--用户解锁命令 alter user scott account unlock;
--修改用户密码命令:alter user zyeas01 identified by password;
--alter user test default tablespace test temporary tablespace testtemp profile default;
--回收用户dba的角色:
revoke dba from user
--dba角色赋予用户:
grant dba to user
--6、执行数据库还原
--windows环境下:打开另外一个cmd
--小机环境下:再打开一个连接到服务器,在#命令行下还原测试数据库
--当备份帐套的表空间和测试环境表空间一致时
impdp system/2358016636 schemas=NEWDB850BC DIRECTORY =EASBAK DUMPFILE=NEWDB850BC.DMP logfile=NEWDB850BCaaaaa.log TABLE_EXISTS_ACTION=replace
---2、EAS7.5使用了index的表空间,还原方法
--低版本oracle使用imp
--imp system/kingdee fromuser=zyeas01 touser=zyeas02 file='F:\easbak\zyeas01-20170831.dmp' log='20141215.log'
--注意impdp和expdp,imp和exp是配对使用的
imp system/kingdee fromuser=cqjy2018 touser=cqjy04 file='/oradata2/easbak/cqjy20181109.dmp' log='aaa.log' ignore=y
---特殊情况
---1、当在同一数据库备份还原时,备份帐套的表空间和测试环境表空间不能一致
---执行以下还原命令,实现用户和表空间的替换,把备份的zyeas01还原到zyeas02上
impdp system/kingdee schemas=zyeas01 dumpfile=zyeas01.dmp logfile=zyeas01.log directory=EASBAK remap_schema=zyeas01:zyeas02 remap_tablespace=EAS_D_zyeas01_STANDARD:EAS_D_zyeas02_STANDARD remap_tablespace=EAS_T_zyeas01_TEMP:EAS_T_zyeas02_TEMP TABLE_EXISTS_ACTION=replace
---2、EAS7.5使用了index的表空间,还原方法:
---2.1通过EAS管理控制台新建一个空的数据中心,然后再还原
impdp system/kingdee schemas=eas85 dumpfile=TAIKE-20200420.dmp logfile=eas85.log directory=EASBAK remap_schema=eas85:eastest remap_tablespace=EAS_D_eas85_STANDARD:EAS_D_eastest_STANDARD remap_tablespace=EAS_T_eas85_STANDARD:EAS_T_eastest_STANDARD remap_tablespace=EAS_D_EAS85_index:EAS_D_eastest_index remap_tablespace=EAS_D_EAS85_TEMP2:EAS_D_EAStest_TEMP2
---2.2使用本文介绍的通用还原操作,并且在成功还原后注册EAS数据中心,并在数据库管理中马上清理表t_sys_tablespacesinfo
---truncate table t_sys_tablespaceinfo
---清理表t_sys_tablespaceinfo的作用是放弃使用索引表空间
---3、使用正式数据库的备份还原其中一张表
--方法一:
--第一步:备份并删除要还原的表t_bd_accountview
drop table t_bd_accountview purge
--第二步:还原表
impdp zyeas01/kingdee directory=easbak dumpfile=zyeas01.dmp logfile=zyeas01.log tables=zyeas01.t_bd_accountview
注意一定要使用zyeas01这样的EAS用户名,不能使用system,注意zyeas01要有easbak目录的读写权限
--grant read,write on directory easbak to zyeas01;
--方法二:
expdp zyeas01/kingdee TABLES=t_wfr_actinst dumpfile=t_wfr_actinst.dmp directory =EASBAK
impdp zyeas01/111 DIRECTORY=EASBAK DUMPFILE=t_wfr_actinst.dmp TABLES=t_wfr_actinst TABLE_EXISTS_ACTION=replace;
--注意复制执行脚本语句时一定不要选择本文档为自动换行
---4、如果还原过程中出现乱码,则还原前先设置客户端语言
Set NLS_LANG =american_america.utf8
export NLS_LANG =american_america.utf8
--三、数据文件还原总结
--确认准备工作做好
expdp system/kingdee schemas=zyeas01 directory=EASBAK dumpfile=zyeas01-20170831.dmp logfile=zyeas01-20170831.log
impdp system/kingdee schemas=zyeas01 DIRECTORY=EASBAK dumpfile=zyeas01-20170831.dmp logfile=zyeas01-20170831.log
oracle常用命令
--创建表空间
create tablespace itheima
datafile 'c:\itheima.dbf'
size 100m
autoextend on
next 10m;
--删除表空间
drop tablespace itheima;
--将磁盘上的数据文件一同删除(不知道啥原因,本人执行后磁盘上的数据文件还在,这时可以手动删除掉)
drop tablespace testdb including contents and datafiles;
--创建用户
create user itheima
identified by itheima --密码
default tablespace itheima; --出生的表空间
--给用户授权
--oracle数据库中常用角色
connect--连接角色,基本角色
resource--开发者角色
dba--超级管理员角色
--给itheima用户授予dba角色
grant dba to itheima;
---切换到itheima用户下
---创建一个person表
create table person(
pid number(20),
pname varchar2(10)
);
创建表空间
select * from dba_data_files;
CREATE TABLESPACE zyeb -- 表空间
LOGGING
DATAFILE 'D:\javaJDK\IDEA_JAVA\oracle\Oracle\Oracle\ORCL\zyeb .DBF' -- 改路径
SIZE 32M
AUTOEXTEND ON
NEXT 32M MAXSIZE 4096M
EXTENT MANAGEMENT LOCAL;
CREATE USER zyeb IDENTIFIED BY zyeb; -- 给权限
alter user zyeb default tablespace zyeb; -- 给权限
ALTER USER zyeb QUOTA UNLIMITED ON zyeb;
GRANT CREATE SESSION TO zyeb;
GRANT CREATE CLUSTER TO zyeb;
GRANT CREATE DATABASE LINK TO zyeb;
GRANT CREATE ANY INDEX TO zyeb;
GRANT CREATE ANY TABLE TO zyeb;
GRANT CREATE ANY VIEW TO zyeb;
GRANT SELECT ANY TABLE to zyeb;
GRANT DELETE ANY TABLE to zyeb;
GRANT UPDATE ANY TABLE to zyeb;
GRANT INSERT ANY TABLE to zyeb;
GRANT ALTER SYSTEM TO zyeb;
GRANT DEBUG ANY PROCEDURE TO zyeb;
修改表结构
---添加一列
alter table person add (gender number(1));
---修改列类型
alter table person modify gender char(1);
---修改列名称
alter table person rename column gender to sex;
---删除一列
alter table person drop column sex;
---查询表中记录
select * from person;
----添加一条记录
insert into person (pid, pname) values (1, '小明');
commit;
----修改一条记录
update person set pname = '小马' where pid = 1;
commit;
----三个删除
--删除表中全部记录
delete from person;
--删除表结构
drop table person;
--先删除表,再次创建表。效果等同于删除表中全部记录。
--在数据量大的情况下,尤其在表中带有索引的情况下,该操作效率高。
--索引可以提供查询效率,但是会影响增删改效率。
truncate table person;
----序列不真的属于任何一张表,但是可以逻辑和表做绑定。
----序列:默认从1开始,依次递增,主要用来给主键赋值使用。
----dual:虚表,只是为了补全语法,没有任何意义。
create sequence s_person;
select s_person.nextval from dual;--增长序列
select s_person.currval from dual;--锁定序列
----添加一条记录
insert into person (pid, pname) values (s_person.nextval, '小明');
commit;
select * from person;
----scott用户,密码tiger。
--解锁scott用户
alter user scott account unlock;
--解锁scott用户的密码【此句也可以用来重置密码】
alter user scott identified by tiger;
--切换到scott用户下
函数
--单行函数:作用于一行,返回一个值。
---字符函数
select upper('yes') from dual;--YES小写变大写
select lower('YES') from dual;--yes大写变小写
----数值函数
select round(56.16, -2) from dual;---四舍五入,后面的参数表示保留的位数
select trunc(56.16, -1) from dual;---直接截取,不在看后面位数的数字是否大于5.
select mod(10, 3) from dual;---求余数
----日期函数
----查询出emp表中所有员工入职距离现在几天。
select sysdate-e.hiredate from emp e;
----算出明天此刻
select sysdate+1 from dual;
----查询出emp表中所有员工入职距离现在几月。
select months_between(sysdate,e.hiredate) from emp e;
----查询出emp表中所有员工入职距离现在几年。
select months_between(sysdate,e.hiredate)/12 from emp e;
----查询出emp表中所有员工入职距离现在几周。
select round((sysdate-e.hiredate)/7) from emp e;
----转换函数fm去掉月份的0,hh是按24小时计算
---日期转字符串
select to_char(sysdate, 'fm yyyy-mm-dd hh24:mi:ss') from dual;
---字符串转日期
select to_date('2018-6-7 16:39:50', 'fm yyyy-mm-dd hh24:mi:ss') from dual;
----通用函数
---算出emp表中所有员工的年薪
----奖金里面有null值,如果null值和任意数字做算术运算,结果都是null。
select e.sal*12+nvl(e.comm, 0) from emp e;
---条件表达式
---条件表达式的通用写法,mysql和oracle通用
---给emp表中员工起中文名
select e.ename,
case e.ename
when 'SMITH' then '曹贼'
when 'ALLEN' then '大耳贼'
when 'WARD' then '诸葛小儿'
--else '无名'
end
from emp e;
---判断emp表中员工工资,如果高于3000显示高收入,如果高于1500低于3000显示中等收入,
-----其余显示低收入
select e.sal,
case
when e.sal>3000 then '高收入'
when e.sal>1500 then '中等收入'
else '低收入'
end
from emp e;
----oracle中除了起别名,都用单引号。
----oracle专用条件表达式
select e.ename,
decode(e.ename,
'SMITH', '曹贼',
'ALLEN', '大耳贼',
'WARD', '诸葛小儿',
'无名') "中文名"
from emp e;
--多行函数【聚合函数】:作用于多行,返回一个值。
select count(1) from emp;---查询总数量
select sum(sal) from emp;---工资总和
select max(sal) from emp;---最大工资
select min(sal) from emp;---最低工资
select avg(sal) from emp;---平均工资
查询
---分组查询
---查询出每个部门的平均工资
---分组查询中,出现在group by后面的原始列,才能出现在select后面
---没有出现在group by后面的列,想在select后面,必须加上聚合函数。
---聚合函数有一个特性,可以把多行记录变成一个值。
select e.deptno, avg(e.sal)--, e.ename
from emp e
group by e.deptno;
---查询出平均工资高于2000的部门信息
select e.deptno, avg(e.sal) asal
from emp e
group by e.deptno
having avg(e.sal)>2000;
---所有条件都不能使用别名来判断。
--比如下面的条件语句也不能使用别名当条件
select ename, sal s from emp where sal>1500;
---查询出每个部门工资高于800的员工的平均工资
select e.deptno, avg(e.sal) asal
from emp e
where e.sal>800
group by e.deptno;
----where是过滤分组前的数据,having是过滤分组后的数据。
---表现形式:where必须在group by之前,having是在group by之后。
---查询出每个部门工资高于800的员工的平均工资
---然后再查询出平均工资高于2000的部门
select e.deptno, avg(e.sal) asal
from emp e
where e.sal>800
group by e.deptno
having avg(e.sal)>2000;
---多表查询中的一些概念
---笛卡尔积
select *
from emp e, dept d;
---等值连接
select *
from emp e, dept d
where e.deptno=d.deptno;
---内连接
select *
from emp e inner join dept d
on e.deptno = d.deptno;
---查询出所有部门,以及部门下的员工信息。【外连接】
select *
from emp e right join dept d
on e.deptno=d.deptno;
---查询所有员工信息,以及员工所属部门
select *
from emp e left join dept d
on e.deptno=d.deptno;
---oracle中专用外连接
select *
from emp e, dept d
where e.deptno(+) = d.deptno;
select * from emp;
---查询出员工姓名,员工领导姓名
---自连接:自连接其实就是站在不同的角度把一张表看成多张表。
select e1.ename, e2.ename
from emp e1, emp e2
where e1.mgr = e2.empno;
------查询出员工姓名,员工部门名称,员工领导姓名,员工领导部门名称
select e1.ename, d1.dname, e2.ename, d2.dname
from emp e1, emp e2, dept d1, dept d2
where e1.mgr = e2.empno
and e1.deptno=d1.deptno
and e2.deptno=d2.deptno;
---子查询
---子查询返回一个值
---查询出工资和SCOTT一样的员工信息
select * from emp where sal = -- 这里=是有问题的,在子查询为空,就出错了,就可以用in
(select sal from emp where ename = 'SCOTT')
---子查询返回一个集合
---查询出工资和10号部门任意员工一样的员工信息
select * from emp where sal in
(select sal from emp where deptno = 10);
---子查询返回一张表
---查询出每个部门最低工资,和最低工资员工姓名,和该员工所在部门名称
---1,先查询出每个部门最低工资
select deptno, min(sal) msal
from emp
group by deptno;
---2,三表联查,得到最终结果。
select t.deptno, t.msal, e.ename, d.dname
from (select deptno, min(sal) msal
from emp
group by deptno) t, emp e, dept d
where t.deptno = e.deptno
and t.msal = e.sal
and e.deptno = d.deptno;
----oracle中的分页
---rownum行号:当我们做select操作的时候,
--每查询出一行记录,就会在该行上加上一个行号,
--行号从1开始,依次递增,不能跳着走。
----排序操作会影响rownum的顺序
select rownum, e.* from emp e order by e.sal desc
----如果涉及到排序,但是还要使用rownum的话,我们可以再次嵌套查询。
select rownum, t.* from(
select rownum, e.* from emp e order by e.sal desc) t;
----emp表工资倒叙排列后,每页五条记录,查询第二页。
----rownum行号不能写上大于一个正数。
select * from(
select rownum rn, tt.* from(
select * from emp order by sal desc
) tt where rownum<11
) where rn>5
视图
---视图
---视图的概念:视图就是提供一个查询的窗口,所有数据来自于原表。
---查询语句创建表
create table emp as select * from scott.emp;
select * from emp;
---创建视图【必须有dba权限】
create view v_emp as select ename, job from emp;
---查询视图
select * from v_emp;
---修改视图[不推荐]
update v_emp set job='CLERK' where ename='ALLEN';
commit;
---创建只读视图
create view v_emp1 as select ename, job from emp with read only;
---视图的作用?
---第一:视图可以屏蔽掉一些敏感字段。
---第二:保证总部和分部数据及时统一。
索引
---索引
--索引的概念:索引就是在表的列上构建一个二叉树
----达到大幅度提高查询效率的目的,但是索引会影响增删改的效率。
---单列索引
---创建单列索引
create index idx_ename on emp(ename);
---单列索引触发规则,条件必须是索引列中的原始值。
---单行函数,模糊查询,都会影响索引的触发。
select * from emp where ename='SCOTT'
---复合索引
---创建复合索引
create index idx_enamejob on emp(ename, job);
---复合索引中第一列为优先检索列
---如果要触发复合索引,必须包含有优先检索列中的原始值。
select * from emp where ename='SCOTT' and job='xx';---触发复合索引
select * from emp where ename='SCOTT' or job='xx';---不触发索引
select * from emp where ename='SCOTT';---触发单列索引。
pl/sql编程语言
---pl/sql编程语言
---pl/sql编程语言是对sql语言的扩展,使得sql语言具有过程化编程的特性。
---pl/sql编程语言比一般的过程化编程语言,更加灵活高效。
---pl/sql编程语言主要用来编写存储过程和存储函数等。
---声明方法
---赋值操作可以使用:=也可以使用into查询语句赋值
declare
i number(2) := 10;
s varchar2(10) := '小明';
ena emp.ename%type;---引用型变量
emprow emp%rowtype;---记录型变量
begin
dbms_output.put_line(i);
dbms_output.put_line(s);
select ename into ena from emp where empno = 7788;
dbms_output.put_line(ena);
select * into emprow from emp where empno = 7788;
dbms_output.put_line(emprow.ename || '的工作为:' || emprow.job);
end;
---pl/sql中的if判断
---输入小于18的数字,输出未成年
---输入大于18小于40的数字,输出中年人
---输入大于40的数字,输出老年人
declare
i number(3) := ⅈ
begin
if i<18 then
dbms_output.put_line('未成年');
elsif i<40 then
dbms_output.put_line('中年人');
else
dbms_output.put_line('老年人');
end if;
end;
---pl/sql中的loop循环
---用三种方式输出1到10是个数字
---while循环
declare
i number(2) := 1;
begin
while i<11 loop
dbms_output.put_line(i);
i := i+1;
end loop;
end;
---exit循环
declare
i number(2) := 1;
begin
loop
exit when i>10;
dbms_output.put_line(i);
i := i+1;
end loop;
end;
---for循环
declare
begin
for i in 1..10 loop
dbms_output.put_line(i);
end loop;
end;
---游标:可以存放多个对象,多行记录。
---输出emp表中所有员工的姓名
declare
cursor c1 is select * from emp;
emprow emp%rowtype;--接受变量
begin
open c1;
loop
fetch c1 into emprow;
exit when c1%notfound; --拿不到数据自动退出
dbms_output.put_line(emprow.ename);
end loop;
close c1;
end;
-----给指定部门员工涨工资
declare
cursor c2(eno emp.deptno%type)
is select empno from emp where deptno = eno;
en emp.empno%type;
begin
open c2(10);-- 加入变量
loop
fetch c2 into en; --植入值
exit when c2%notfound;
update emp set sal=sal+100 where empno=en;
commit;
end loop;
close c2;
end;
----查询10号部门员工信息
select * from emp where deptno = 10;
存储过程和存储函数
---存储过程
--存储过程:存储过程就是提前已经编译好的一段pl/sql语言,放置在数据库端
--------可以直接被调用。这一段pl/sql一般都是固定步骤的业务。
----给指定员工涨100块钱
create or replace procedure p1(eno emp.empno%type)
is
begin
update emp set sal=sal+100 where empno = eno;
commit;
end;
select * from emp where empno = 7788;
----测试p1
declare
begin
p1(7788);
end;
----通过存储函数实现计算指定员工的年薪
----存储过程和存储函数的参数都不能带长度
----存储函数的返回值类型不能带长度
create or replace function f_yearsal(eno emp.empno%type) return number
is
s number(10);
begin
select sal*12+nvl(comm, 0) into s from emp where empno = eno;
return s;
end;
----测试f_yearsal
----存储函数在调用的时候,返回值需要接收。
declare
s number(10);
begin
s := f_yearsal(7788);
dbms_output.put_line(s);
end;
---out类型参数如何使用
---使用存储过程来算年薪
create or replace procedure p_yearsal(eno emp.empno%type, yearsal out number)
is
s number(10);
c emp.comm%type;
begin
select sal*12, nvl(comm, 0) into s, c from emp where empno = eno;
yearsal := s+c;
end;
---测试p_yearsal
declare
yearsal number(10);
begin
p_yearsal(7788, yearsal);
dbms_output.put_line(yearsal);
end;
----in和out类型参数的区别是什么?
---凡是涉及到into查询语句赋值或者:=赋值操作的参数,都必须使用out来修饰。
---存储过程和存储函数的区别
---语法区别:关键字不一样,
------------存储函数比存储过程多了两个return。
---本质区别:存储函数有返回值,而存储过程没有返回值。
----------如果存储过程想实现有返回值的业务,我们就必须使用out类型的参数。
----------即便是存储过程使用了out类型的参数,起本质也不是真的有了返回值,
----------而是在存储过程内部给out类型参数赋值,在执行完毕后,我们直接拿到输出类型参数的值。
----我们可以使用存储函数有返回值的特性,来自定义函数。
----而存储过程不能用来自定义函数。
----案例需求:查询出员工姓名,员工所在部门名称。
----案例准备工作:把scott用户下的dept表复制到当前用户下。
create table dept as select * from scott.dept;
----使用传统方式来实现案例需求
select e.ename, d.dname
from emp e, dept d
where e.deptno=d.deptno;
----使用存储函数来实现提供一个部门编号,输出一个部门名称。
create or replace function fdna(dno dept.deptno%type) return dept.dname%type
is
dna dept.dname%type;
begin
select dname into dna from dept where deptno = dno;
return dna;
end;
---使用fdna存储函数来实现案例需求:查询出员工姓名,员工所在部门名称。
select e.ename, fdna(e.deptno)
from emp e;
触发器
---触发器,就是制定一个规则,在我们做增删改操作的时候,
----只要满足该规则,自动触发,无需调用。
----语句级触发器:不包含有for each row的触发器。
----行级触发器:包含有for each row的就是行级触发器。
-----------加for each row是为了使用:old或者:new对象或者一行记录。
---语句级触发器
----插入一条记录,输出一个新员工入职
create or replace trigger t1
after
insert
on person
declare
begin
dbms_output.put_line('一个新员工入职');
end;
---触发t1
insert into person values (1, '小红');
commit;
select * from person;
---行级别触发器
---不能给员工降薪
---raise_application_error(-20001~-20999之间, '错误提示信息');
create or replace trigger t2
before
update
on emp
for each row
declare
begin
if :old.sal>:new.sal then
raise_application_error(-20001, '不能给员工降薪');
end if;
end;
----触发t2
select * from emp where empno = 7788;
update emp set sal=sal-1 where empno = 7788;
commit;
----触发器实现主键自增。【行级触发器】
---分析:在用户做插入操作的之前,拿到即将插入的数据,
------给该数据中的主键列赋值。
create or replace trigger auid
before
insert
on person
for each row
declare
begin
select s_person.nextval into :new.pid from dual;
end;
--查询person表数据
select * from person;
---使用auid实现主键自增
insert into person (pname) values ('a');
commit;
insert into person values (1, 'b');
commit;
----oracle10g ojdbc14.jar
----oracle11g ojdbc6.jar
游标的定义
--显示cursor的处理
declare
---声明cursor,创建和命名一个sql工作区
cursor cursor_name is
select real_name from account_hcz;
v_realname varchar2(20);
begin
open cursor_name;---打开cursor,执行sql语句产生的结果集
fetch cursor_name intov_realname;--提取cursor,提取结果集中的记录
dbms_output.put_line(v_realname);
closecursor_name;--关闭cursor
end;
存储过程中游标定义使用
as //定义(游标一个可以遍历的结果集)
CURSOR cur_1 IS
SELECT area_code,CMCODE,SUM(rmb_amt)/10000 rmb_amt_sn,
SUM(usd_amt)/10000 usd_amt_sn
FROM BGD_AREA_CM_M_BASE_T
WHERE ym >= vs_ym_sn_beg
AND ym <= vs_ym_sn_end
GROUP BY area_code,CMCODE;
begin //执行(常用For语句遍历游标)
FOR rec IN cur_1 LOOP
UPDATE xxxxxxxxxxx_T
SET rmb_amt_sn= rec.rmb_amt_sn,usd_amt_sn = rec.usd_amt_sn
WHERE area_code = rec.area_code
AND CMCODE = rec.CMCODE
AND ym = is_ym;
END LOOP;
额外学习
-- 1、根据删除的时间查询出被删除的数据
select * from szdj_work_plan AS OF TIMESTAMP TO_TIMESTAMP('2018-1-19 16:51:37', 'yyyy-mm-dd hh24:mi:ss') where subject='测试一下删除0119'
-- 1、表中唯一的最大的值
select hibernate_sequence.nextval from dual
3、备份数据库
完全备份
exp demo/demo@orcl buffer=1024 file=d:\back.dmp full=y
demo:用户名、密码
buffer: 缓存大小
file: 具体的备份文件地址
full: 是否导出全部文件
ignore: 忽略错误,如果表已经存在,则也是覆盖
将数据库中system用户与sys用户的表导出
exp demo/demo@orcl file=d:\backup\1.dmp owner=(system,sys)
导出指定的表
exp demo/demo@orcl file=d:\backup2.dmp tables=(teachers,students)
按过滤条件,导出
exp demo/demo@orcl file=d:\back.dmp tables=(table1) query=\" where filed1 like 'fg%'\"
导出时可以进行压缩;命令后面 加上 compress=y ;如果需要日志,后面: log=d:\log.txt
备份远程服务器的数据库
exp 用户名/密码@远程的IP:端口/实例 file=存放的位置:\文件名称.dmp full=y
4、数据库还原
打开cmd直接执行如下命令,不用再登陆sqlplus。
完整还原
imp demo/demo@orcl file=d:\back.dmp full=y ignore=y log=D:\implog.txt
指定log很重要,便于分析错误进行补救。
导入指定表
imp demo/demo@orcl file=d:\backup2.dmp tables=(teachers,students)
还原到远程服务器
imp 用户名/密码@远程的IP:端口/实例 file=存放的位置:\文件名称.dmp full=y
二、Oracle表操作
1、创建表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)
根据已有的表创建新表:
A:select * into table_new from table_old (使用旧表创建新表)
B:create table tab_new as select col1,col2… from tab_old definition only<仅适用于Oracle>
2、删除表
drop table tabname
3、重命名表
说明:alter table 表名 rename to 新表名
eg:alter table tablename rename to newtablename
4、增加字段
说明:alter table 表名 add (字段名 字段类型 默认值 是否为空);
例:alter table tablename add (ID int);
eg:alter table tablename add (ID varchar2(30) default '空' not null);
5、修改字段
说明:alter table 表名 modify (字段名 字段类型 默认值 是否为空);
eg:alter table tablename modify (ID number(4));
6、重名字段
说明:alter table 表名 rename column 列名 to 新列名 (其中:column是关键字)
eg:alter table tablename rename column ID to newID;
7、删除字段
说明:alter table 表名 drop column 字段名;
eg:alter table tablename drop column ID;
8、添加主键
alter table tabname add primary key(col)
9、删除主键
alter table tabname drop primary key(col)
10、创建索引
create [unique] index idxname on tabname(col….)
11、删除索引
drop index idxname
注:索引是不可更改的,想更改必须删除重新建。
12、创建视图
create view viewname as select statement
13、删除视图
drop view viewname
三、Oracle操作数据
1、数据查询
select <列名> from <表名> [where <查询条件表达试>] [order by <排序的列名>[asc或desc]]
2、插入数据
insert into 表名 values(所有列的值);
insert into test values(1,'zhangsan',20);
insert into 表名(列) values(对应的值);
insert into test(id,name) values(2,'lisi');
3、更新数据
update 表 set 列=新的值 [where 条件] -->更新满足条件的记录
update test set name='zhangsan2' where name='zhangsan'
update 表 set 列=新的值 -->更新所有的数据
update test set age =20;
4、删除数据
delete from 表名 where 条件 -->删除满足条件的记录
delete from test where id = 1;
delete from test -->删除所有
commit; -->提交数据
rollback; -->回滚数据
delete方式可以恢复删除的数据,但是提交了,就没办法了 delete删除的时候,会记录日志 -->删除会很慢很慢
truncate table 表名
删除所有数据,不会影响表结构,不会记录日志,数据不能恢复 -->删除很快
drop table 表名
删除所有数据,包括表结构一并删除,不会记录日志,数据不能恢复-->删除很快
5、数据复制
表数据复制
insert into table1 (select * from table2);
复制表结构
create table table1 select * from table2 where 1>1;
复制表结构和数据
create table table1 select * from table2;
复制指定字段
create table table1 as select id, name from table2 where 1>1;
四、数据库复制命令
/
Oracle如何插入日期数据
Oracle数据库插入日期型数据
往Oracle数据库中插入日期型数据(to_date的用法)
INSERT INTO FLOOR VALUES ( to_date ( '2007-12-20 18:31:34' , 'YYYY-MM-DD HH24:MI:SS' ) ) ;
查询显示:2007-12-20 18:31:34.0
-------------------
INSERT INTO FLOOR VALUES ( to_date ( '2007-12-14 14:10' , 'YYYY-MM-DD HH24:MI' ) );
查询显示:2007-12-14 14:10:00.0
-------------------
INSERT INTO FLOOR VALUES ( to_date ( '2007-12-14 14' , 'YYYY-MM-DD HH24' ) );
查询显示:2007-12-14 14:00:00.0
-------------------
INSERT INTO FLOOR VALUES ( to_date ( '2007-11-15' , 'YYYY-MM-DD' ) );
查询显示:2007-11-15 00:00:00.0
-------------------
INSERT INTO FLOOR VALUES ( to_date ( '2007-09' , 'YYYY-MM' ) );
查询显示:2007-09-01 00:00:00.0
-------------------
INSERT INTO FLOOR VALUES ( to_date ( '2007' , 'YYYY' ) );
查询显示:2007-05-01 00:00:00.0
-------------------
一、基础
1、说明:创建数据库
CREATE DATABASE database-name
2、说明:删除数据库
drop database dbname
3、说明:备份sql server
--- 创建 备份数据的 device
USE master(管理员)
EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat'
--- 开始 备份
BACKUP DATABASE pubs TO testBack
4、说明:创建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)
根据已有的表创建新表:
A:create table tab_new like tab_old (使用旧表创建新表)
//此语句经过测试 如不加only关键字在mysql数据库中可以使用,使用请谨慎
B:create table tab_new as select col1,col2… from tab_old definition only
5、说明:删除新表
drop table tabname
6、说明:增加一个列
Alter table tabname add column col type
注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
7、说明:添加主键: Alter table tabname add primary key(col)
//删除语句待定,经本人测试mysql数据库中此方法并不能删除主键约束
说明:删除主键: Alter table tabname drop primary key(col)
8、说明:创建索引:create [unique] index idxname on tabname(col….)
删除索引:drop index idxname
注:索引是不可更改的,想更改必须删除重新建。
9、说明:创建视图:create view viewname as select statement
删除视图:drop view viewname
10、说明:几个简单的基本的sql语句
选择:select * from table1 where 范围
插入:insert into table1(field1,field2) values(value1,value2)
删除:delete from table1 where 范围
更新:update table1 set field1=value1 where 范围
//模糊查询
查找:select * from table1(表明) where field1 like ’%value1%’ ---like的语法很精妙,查资料!
//排序的两种升序和降序,根据所选定的字段值来进行升序和降序排列,在mysql数据库中实现语句为
select 8from table order by filed1 ....(字段名) desc/asc;(升序或者是降序)
排序:select * from table1 order by field1,field2 [desc](排序查询)
//mysql数据库查询总数方法可以是select count(*) from table(表名字);
总数:select count as totalcount from table1
求和:select sum(field1) as sumvalue from table1
平均:select avg(field1) as avgvalue from table1
最大:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
11、说明:几个高级查询运算词
A: UNION 运算符
UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。
B: EXCEPT 运算符
EXCEPT运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当 ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行。
C: INTERSECT 运算符
INTERSECT运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行。
注:使用运算词的几个查询结果行必须是一致的。
12、说明:使用外连接
A、left (outer) join:
左外连接(左连接):结果集几包括连接表的匹配行,也包括左连接表的所有行。
mysql中示例:
select *from table1 left join table2 where table1.*=table2.*(此处为查询条件,*表示字段,如id)
左外连接即以左边的表为主表
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
B:right (outer) join:
右外连接(右连接):结果集既包括连接表的匹配连接行,也包括右连接表的所有行。
select *from table1 right join table2 where table1.*=table2.*(此处为查询条件,*表示字段,如id)
右外连接即以左边的表为主表
C:full/cross (outer) join:
select *from table1 (inner此字段可加可不加) join table2 where table1.*=table2.*(此处为查询条件,*表示字段,如id)
全外连接:不仅包括符号连接表的匹配行,还包括两个连接表中的所有记录。
12、分组:Group by:
一张表,一旦分组 完成后,查询后只能得到组相关的信息。
组相关的信息:(统计信息) count,sum,max,min,avg 分组的标准)
在SQLServer中分组时:不能以text,ntext,image类型的字段作为分组依据
在selecte统计函数中的字段,不能和普通的字段放在一起;
13、对数据库进行操作:
分离数据库: sp_detach_db;附加数据库:sp_attach_db 后接表明,附加需要完整的路径名
14.如何修改数据库的名称:
sp_renamedb 'old_name', 'new_name'
二、提升
1、说明:复制表(只复制结构,源表名:a 新表名:b) (Access可用)
法一:select * into b from a where 1<>1(仅用于SQlServer)
法二:select top 0 * into b from a
2、说明:拷贝表(拷贝数据,源表名:a 目标表名:b) (Access可用)
insert into b(a, b, c) select d,e,f from b;
3、说明:跨数据库之间表的拷贝(具体数据使用绝对路径) (Access可用)
insert into b(a, b, c) select d,e,f from b in ‘具体数据库’ where 条件
例子:..from b in '"&Server.MapPath(".")&"\data.mdb" &"' where..
4、说明:子查询(表名1:a 表名2:b)
select a,b,c from a where a IN (select d from b ) 或者: select a,b,c from a where a IN (1,2,3)
5、说明:显示文章、提交人和最后回复时间
select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
6、说明:外连接查询(表名1:a 表名2:b)
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
7、说明:在线视图查询(表名1:a )
select * from (SELECT a,b,c FROM a) T where t.a > 1;
8、说明:between的用法,between限制查询数据范围时包括了边界值,not between不包括
select * from table1 where time between time1 and time2
select a,b,c, from table1 where a not between 数值1 and 数值2
9、说明:in 的使用方法
select * from table1 where a [not] in (‘值1’,’值2’,’值4’,’值6’)
10、说明:两张关联表,删除主表中已经在副表中没有的信息
delete from table1 where not exists ( select * from table2 where table1.field1=table2.field1 )
11、说明:四表联查问题:
select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....
12、说明:日程安排提前五分钟提醒
SQL: select * from 日程安排 where datediff('minute',f开始时间,getdate())>5
13、说明:一条sql 语句搞定数据库分页
select top 10 b.* from (select top 20 主键字段,排序字段 from 表名 order by 排序字段 desc) a,表名 b where b.主键字段 = a.主键字段 order by a.排序字段
具体实现:
关于数据库分页:
declare @start int,@end int
@sql nvarchar(600)
set @sql=’select top’+str(@end-@start+1)+’+from T where rid not in(select top’+str(@str-1)+’Rid from T where Rid>-1)’
exec sp_executesql @sql
注意:在top后不能直接跟一个变量,所以在实际应用中只有这样的进行特殊的处理。Rid为一个标识列,如果top后还有具体的字段,这样做是非常有好处的。因为这样可以避免 top的字段如果是逻辑索引的,查询的结果后实际表中的不一致(逻辑索引中的数据有可能和数据表中的不一致,而查询时如果处在索引则首先查询索引)
14、说明:前10条记录
select top 10 * form table1 where 范围
15、说明:选择在每一组b值相同的数据中对应的a最大的记录的所有信息(类似这样的用法可以用于论坛每月排行榜,每月热销产品分析,按科目成绩排名,等等.)
select a,b,c from tablename ta where a=(select max(a) from tablename tb where tb.b=ta.b)
16、说明:包括所有在 TableA中但不在 TableB和TableC中的行并消除所有重复行而派生出一个结果表
(select a from tableA ) except (select a from tableB) except (select a from tableC)
17、说明:随机取出10条数据
select top 10 * from tablename order by newid()
18、说明:随机选择记录
select newid()
19、说明:删除重复记录
1),delete from tablename where id not in (select max(id) from tablename group by col1,col2,...)
2),select distinct * into temp from tablename
delete from tablename
insert into tablename select * from temp
评价: 这种操作牵连大量的数据的移动,这种做法不适合大容量但数据操作
3),例如:在一个外部表中导入数据,由于某些原因第一次只导入了一部分,但很难判断具体位置,这样只有在下一次全部导入,这样也就产生好多重复的字段,怎样删除重复字段
alter table tablename
--添加一个自增列
add column_b int identity(1,1)
delete from tablename where column_b not in(
select max(column_b) from tablename group by column1,column2,...)
alter table tablename drop column column_b
20、说明:列出数据库里所有的表名
select name from sysobjects where type='U' // U代表用户
21、说明:列出表里的所有的列名
select name from syscolumns where id=object_id('TableName')
22、说明:列示type、vender、pcs字段,以type字段排列,case可以方便地实现多重选择,类似select 中的case。
select type,sum(case vender when 'A' then pcs else 0 end),sum(case vender when 'C' then pcs else 0 end),sum(case vender when 'B' then pcs else 0 end) FROM tablename group by type
显示结果:
type vender pcs
电脑 A 1
电脑 A 1
光盘 B 2
光盘 A 2
手机 B 3
手机 C 3
23、说明:初始化表table1
TRUNCATE TABLE table1
24、说明:选择从10到15的记录
select top 5 * from (select top 15 * from table order by id asc) table_别名 order by id desc
三、技巧
1、1=1,1=2的使用,在SQL语句组合时用的较多
“where 1=1” 是表示选择全部 “where 1=2”全部不选,
如:
if @strWhere !=''
begin
set @strSQL = 'select count(*) as Total from [' + @tblName + '] where ' + @strWhere
end
else
begin
set @strSQL = 'select count(*) as Total from [' + @tblName + ']'
end
我们可以直接写成
错误!未找到目录项。
set @strSQL = 'select count(*) as Total from [' + @tblName + '] where 1=1 安定 '+ @strWhere 2、收缩数据库
--重建索引
DBCC REINDEX
DBCC INDEXDEFRAG
--收缩数据和日志
DBCC SHRINKDB
DBCC SHRINKFILE
3、压缩数据库
dbcc shrinkdatabase(dbname)
4、转移数据库给新用户以已存在用户权限
exec sp_change_users_login 'update_one','newname','oldname'
go
5、检查备份集
RESTORE VERIFYONLY from disk='E:\dvbbs.bak'
6、修复数据库
ALTER DATABASE [dvbbs] SET SINGLE_USER
GO
DBCC CHECKDB('dvbbs',repair_allow_data_loss) WITH TABLOCK
GO
ALTER DATABASE [dvbbs] SET MULTI_USER
GO
7、日志清除
SET NOCOUNT ON
DECLARE @LogicalFileName sysname,
@MaxMinutes INT,
@NewSize INT
USE tablename -- 要操作的数据库名
SELECT @LogicalFileName = 'tablename_log', -- 日志文件名
@MaxMinutes = 10, -- Limit on time allowed to wrap log.
@NewSize = 1 -- 你想设定的日志文件的大小(M)
Setup / initialize
DECLARE @OriginalSize int
SELECT @OriginalSize = size
FROM sysfiles
WHERE name = @LogicalFileName
SELECT 'Original Size of ' + db_name() + ' LOG is ' +
CONVERT(VARCHAR(30),@OriginalSize) + ' 8K pages or ' +
CONVERT(VARCHAR(30),(@OriginalSize*8/1024)) + 'MB'
FROM sysfiles
WHERE name = @LogicalFileName
CREATE TABLE DummyTrans
(DummyColumn char (8000) not null)
DECLARE @Counter INT,
@StartTime DATETIME,
@TruncLog VARCHAR(255)
SELECT @StartTime = GETDATE(),
@TruncLog = 'BACKUP LOG ' + db_name() + ' WITH TRUNCATE_ONLY'
DBCC SHRINKFILE (@LogicalFileName, @NewSize)
EXEC (@TruncLog)
-- Wrap the log if necessary.
WHILE @MaxMinutes > DATEDIFF (mi, @StartTime, GETDATE()) -- time has not expired
AND @OriginalSize = (SELECT size FROM sysfiles WHERE name = @LogicalFileName)
AND (@OriginalSize * 8 /1024) > @NewSize
BEGIN -- Outer loop.
SELECT @Counter = 0
WHILE ((@Counter < @OriginalSize / 16) AND (@Counter < 50000))
BEGIN -- update
INSERT DummyTrans VALUES ('Fill Log') DELETE DummyTrans
SELECT @Counter = @Counter + 1
END
EXEC (@TruncLog)
END
SELECT 'Final Size of ' + db_name() + ' LOG is ' +
CONVERT(VARCHAR(30),size) + ' 8K pages or ' +
CONVERT(VARCHAR(30),(size*8/1024)) + 'MB'
FROM sysfiles
WHERE name = @LogicalFileName
DROP TABLE DummyTrans
SET NOCOUNT OFF
8、说明:更改某个表
exec sp_changeobjectowner 'tablename','dbo'
9、存储更改全部表
CREATE PROCEDURE dbo.User_ChangeObjectOwnerBatch
@OldOwner as NVARCHAR(128),
@NewOwner as NVARCHAR(128)
AS
DECLARE @Name as NVARCHAR(128)
DECLARE @Owner as NVARCHAR(128)
DECLARE @OwnerName as NVARCHAR(128)
DECLARE curObject CURSOR FOR
select 'Name' = name,
'Owner' = user_name(uid)
from sysobjects
where user_name(uid)=@OldOwner
order by name
OPEN curObject
FETCH NEXT FROM curObject INTO @Name, @Owner
WHILE(@@FETCH_STATUS=0)
BEGIN
if @Owner=@OldOwner
begin
set @OwnerName = @OldOwner + '.' + rtrim(@Name)
exec sp_changeobjectowner @OwnerName, @NewOwner
end
-- select @name,@NewOwner,@OldOwner
FETCH NEXT FROM curObject INTO @Name, @Owner
END
close curObject
deallocate curObject
GO
10、SQL SERVER中直接循环写入数据
declare @i int
set @i=1
while @i<30
begin
insert into test (userid) values(@i)
set @i=@i+1
end
案例:
有如下表,要求就裱中所有沒有及格的成績,在每次增長0.1的基礎上,使他們剛好及格:
Name score
Zhangshan 80
Lishi 59
Wangwu 50
Songquan 69
while((select min(score) from tb_table)<60)
begin
update tb_table set score =score*1.01
where score<60
if (select min(score) from tb_table)>60
break
else
continue
end
数据开发-经典
1.按姓氏笔画排序:
Select * From TableName Order By CustomerName Collate Chinese_PRC_Stroke_ci_as //从少到多
2.数据库加密:
select encrypt('原始密码')
select pwdencrypt('原始密码')
select pwdcompare('原始密码','加密后密码') = 1--相同;否则不相同 encrypt('原始密码')
select pwdencrypt('原始密码')
select pwdcompare('原始密码','加密后密码') = 1--相同;否则不相同
3.取回表中字段:
declare @list varchar(1000),
@sql nvarchar(1000)
select @list=@list+','+b.name from sysobjects a,syscolumns b where a.id=b.id and a.name='表A'
set @sql='select '+right(@list,len(@list)-1)+' from 表A'
exec (@sql)
4.查看硬盘分区:
EXEC master..xp_fixeddrives
5.比较A,B表是否相等:
if (select checksum_agg(binary_checksum(*)) from A)
=
(select checksum_agg(binary_checksum(*)) from B)
print '相等'
else
print '不相等'
6.杀掉所有的事件探察器进程:
DECLARE hcforeach CURSOR GLOBAL FOR SELECT 'kill '+RTRIM(spid) FROM master.dbo.sysprocesses
WHERE program_name IN('SQL profiler',N'SQL 事件探查器')
EXEC sp_msforeach_worker '?'
7.记录搜索:
开头到N条记录
Select Top N * From 表
-------------------------------
N到M条记录(要有主索引ID)
Select Top M-N * From 表 Where ID in (Select Top M ID From 表) Order by ID Desc
----------------------------------
N到结尾记录
Select Top N * From 表 Order by ID Desc
案例
例如1:一张表有一万多条记录,表的第一个字段 RecID 是自增长字段, 写一个SQL语句, 找出表的第31到第40个记录。
select top 10 recid from A where recid not in(select top 30 recid from A)
分析:如果这样写会产生某些问题,如果recid在表中存在逻辑索引。
select top 10 recid from A where……是从索引中查找,而后面的select top 30 recid from A则在数据表中查找,这样由于索引中的顺序有可能和数据表中的不一致,这样就导致查询到的不是本来的欲得到的数据。
解决方案
1,用order by select top 30 recid from A order by ricid 如果该字段不是自增长,就会出现问题
2,在那个子查询中也加条件:select top 30 recid from A where recid>-1
例2:查询表中的最后以条记录,并不知道这个表共有多少数据,以及表结构。
set @s = 'select top 1 * from T where pid not in (select top ' + str(@count-1) + ' pid from T)'
print @s exec sp_executesql @s
9:获取当前数据库中的所有用户表
select Name from sysobjects where xtype='u' and status>=0
10:获取某一个表的所有字段
select name from syscolumns where id=object_id('表名')
select name from syscolumns where id in (select id from sysobjects where type = 'u' and name = '表名')
两种方式的效果相同
11:查看与某一个表相关的视图、存储过程、函数
select a.* from sysobjects a, syscomments b where a.id = b.id and b.text like '%表名%'
12:查看当前数据库中所有存储过程
select name as 存储过程名称 from sysobjects where xtype='P'
13:查询用户创建的所有数据库
select * from master..sysdatabases D where sid not in(select sid from master..syslogins where name='sa')
或者
select dbid, name AS DB_NAME from master..sysdatabases where sid <> 0x01
14:查询某一个表的字段和数据类型
select column_name,data_type from information_schema.columns
where table_name = '表名'
15:不同服务器数据库之间的数据操作
--创建链接服务器
exec sp_addlinkedserver 'ITSV ', ' ', 'SQLOLEDB ', '远程服务器名或ip地址 '
exec sp_addlinkedsrvlogin 'ITSV ', 'false ',null, '用户名 ', '密码 '
--查询示例
select * from ITSV.数据库名.dbo.表名
--导入示例
select * into 表 from ITSV.数据库名.dbo.表名
--以后不再使用时删除链接服务器
exec sp_dropserver 'ITSV ', 'droplogins '
--连接远程/局域网数据(openrowset/openquery/opendatasource)
--1、openrowset
--查询示例
select * from openrowset( 'SQLOLEDB ', 'sql服务器名 '; '用户名 '; '密码 ',数据库名.dbo.表名)
--生成本地表
select * into 表 from openrowset( 'SQLOLEDB ', 'sql服务器名 '; '用户名 '; '密码 ',数据库名.dbo.表名)
--把本地表导入远程表
insert openrowset( 'SQLOLEDB ', 'sql服务器名 '; '用户名 '; '密码 ',数据库名.dbo.表名)
select *from 本地表
--更新本地表
update b
set b.列A=a.列A
from openrowset( 'SQLOLEDB ', 'sql服务器名 '; '用户名 '; '密码 ',数据库名.dbo.表名)as a inner join 本地表 b
on a.column1=b.column1
--openquery用法需要创建一个连接
--首先创建一个连接创建链接服务器
exec sp_addlinkedserver 'ITSV ', ' ', 'SQLOLEDB ', '远程服务器名或ip地址 '
--查询
select *
FROM openquery(ITSV, 'SELECT * FROM 数据库.dbo.表名 ')
--把本地表导入远程表
insert openquery(ITSV, 'SELECT * FROM 数据库.dbo.表名 ')
select * from 本地表
--更新本地表
update b
set b.列B=a.列B
FROM openquery(ITSV, 'SELECT * FROM 数据库.dbo.表名 ') as a
inner join 本地表 b on a.列A=b.列A
--3、opendatasource/openrowset
SELECT *
FROM opendatasource( 'SQLOLEDB ', 'Data Source=ip/ServerName;User ID=登陆名;Password=密码 ' ).test.dbo.roy_ta
--把本地表导入远程表
insert opendatasource( 'SQLOLEDB ', 'Data Source=ip/ServerName;User ID=登陆名;Password=密码 ').数据库.dbo.表名
select * from 本地表
SQL Server基本函数
SQL Server基本函数
1.字符串函数 长度与分析用
1,datalength(Char_expr) 返回字符串包含字符数,但不包含后面的空格
2,substring(expression,start,length) 取子串,字符串的下标是从“1”,start为起始位置,length为字符串长度,实际应用中以len(expression)取得其长度
3,right(char_expr,int_expr) 返回字符串右边第int_expr个字符,还用left于之相反
4,isnull( check_expression , replacement_value )如果check_expression為空,則返回replacement_value的值,不為空,就返回check_expression字符操作类
5,Sp_addtype自定義數據類型
例如:EXEC sp_addtype birthday, datetime, 'NULL'
6,set nocount {on|off}
使返回的结果中不包含有关受 Transact-SQL 语句影响的行数的信息。如果存储过程中包含的一些语句并不返回许多实际的数据,则该设置由于大量减少了网络流量,因此可显著提高性能。SET NOCOUNT 设置是在执行或运行时设置,而不是在分析时设置。SET NOCOUNT 为 ON 时,不返回计数(表示受 Transact-SQL 语句影响的行数)。
SET NOCOUNT
为 OFF 时,返回计数
常识
在SQL查询中:from后最多可以跟多少张表或视图:256在SQL语句中出现 Order by,查询时,先排序,后取在SQL中,一个字段的最大容量是8000,而对于nvarchar(4000),由于nvarchar是Unicode码。
SQLServer2000
同步复制技术实现步骤
一、 预备工作
1.发布服务器,订阅服务器都创建一个同名的windows用户,并设置相同的密码,做为发布快照文件夹的有效访问用户--管理工具--计算机管理--用户和组--右键用户--新建用户--建立一个隶属于administrator组的登陆windows的用户(SynUser)2.在发布服务器上,新建一个共享目录,做为发布的快照文件的存放目录,操作:
我的电脑--D:\ 新建一个目录,名为: PUB
--右键这个新建的目录--属性--共享--选择"共享该文件夹"--通过"权限"按纽来设置具体的用户权限,保证第一步中创建的用户(SynUser) 具有对该文件夹的所有权限
--确定3.设置SQL代理(SQLSERVERAGENT)服务的启动用户(发布/订阅服务器均做此设置)
开始--程序--管理工具--服务
--右键SQLSERVERAGENT--属性--登陆--选择"此账户"--输入或者选择第一步中创建的windows登录用户名(SynUser)--"密码"中输入该用户的密码4.设置SQL Server身份验证模式,解决连接时的权限问题(发布/订阅服务器均做此设置)
企业管理器
--右键SQL实例--属性--安全性--身份验证--选择"SQL Server 和 Windows"--确定5.在发布服务器和订阅服务器上互相注册
企业管理器
--右键SQL Server组--新建SQL Server注册...--下一步--可用的服务器中,输入你要注册的远程服务器名 --添加--下一步--连接使用,选择第二个"SQL Server身份验证"--下一步--输入用户名和密码(SynUser)--下一步--选择SQL Server组,也可以创建一个新组--下一步--完成6.对于只能用IP,不能用计算机名的,为其注册服务器别名(此步在实施中没用到) (在连接端配置,比如,在订阅服务器上配置的话,服务器名称中输入的是发布服务器的IP)
开始--程序--Microsoft SQL Server--客户端网络实用工具
--别名--添加--网络库选择"tcp/ip"--服务器别名输入SQL服务器名--连接参数--服务器名称中输入SQL服务器ip地址--如果你修改了SQL的端口,取消选择"动态决定端口",并输入对应的端口号
二、 正式配置
1、配置发布服务器
打开企业管理器,在发布服务器(B、C、D)上执行以下步骤:
(1) 从[工具]下拉菜单的[复制]子菜单中选择[配置发布、订阅服务器和分发]出现配置发布和分发向导(2) [下一步] 选择分发服务器 可以选择把发布服务器自己作为分发服务器或者其他sql的服务器(选择自己)(3) [下一步] 设置快照文件夹
采用默认\\servername\Pub
(4) [下一步] 自定义配置
可以选择:是,让我设置分发数据库属性启用发布服务器或设置发布设置
否,使用下列默认设置(推荐)
(5) [下一步] 设置分发数据库名称和位置 采用默认值(6) [下一步] 启用发布服务器 选择作为发布的服务器(7) [下一步] 选择需要发布的数据库和发布类型(8) [下一步] 选择注册订阅服务器(9) [下一步] 完成配置2、创建出版物
发布服务器B、C、D上
(1)从[工具]菜单的[复制]子菜单中选择[创建和管理发布]命令(2)选择要创建出版物的数据库,然后单击[创建发布](3)在[创建发布向导]的提示对话框中单击[下一步]系统就会弹出一个对话框。对话框上的内容是复制的三个类型。我们现在选第一个也就是默认的快照发布(其他两个大家可以去看看帮助)(4)单击[下一步]系统要求指定可以订阅该发布的数据库服务器类型,SQLSERVER允许在不同的数据库如 orACLE或ACCESS之间进行数据复制。
但是在这里我们选择运行"SQL SERVER 2000"的数据库服务器
(5)单击[下一步]系统就弹出一个定义文章的对话框也就是选择要出版的表
注意: 如果前面选择了事务发布 则再这一步中只能选择带有主键的表
(6)选择发布名称和描述(7)自定义发布属性 向导提供的选择:
是 我将自定义数据筛选,启用匿名订阅和或其他自定义属性
否 根据指定方式创建发布 (建议采用自定义的方式)
(8)[下一步] 选择筛选发布的方式(9)[下一步] 可以选择是否允许匿名订阅1)如果选择署名订阅,则需要在发布服务器上添加订阅服务器
方法: [工具]->[复制]->[配置发布、订阅服务器和分发的属性]->[订阅服务器] 中添加
否则在订阅服务器上请求订阅时会出现的提示:改发布不允许匿名订阅
如果仍然需要匿名订阅则用以下解决办法
[企业管理器]->[复制]->[发布内容]->[属性]->[订阅选项] 选择允许匿名请求订阅2)如果选择匿名订阅,则配置订阅服务器时不会出现以上提示(10)[下一步] 设置快照 代理程序调度(11)[下一步] 完成配置
当完成出版物的创建后创建出版物的数据库也就变成了一个共享数据库
有数据
srv1.库名..author有字段:id,name,phone, srv2.库名..author有字段:id,name,telphone,adress
要求:
srv1.库名..author增加记录则srv1.库名..author记录增加srv1.库名..author的phone字段更新,则srv1.库名..author对应字段telphone更新
--*/
--大致的处理步骤--1.在 srv1 上创建连接服务器,以便在 srv1 中操作 srv2,实现同步exec sp_addlinkedserver 'srv2','','SQLOLEDB','srv2的sql实例名或ip' exec sp_addlinkedsrvlogin 'srv2','false',null,'用户名','密码'
go
--2.在 srv1 和 srv2 这两台电脑中,启动 msdtc(分布式事务处理服务),并且设置为自动启动
。我的电脑--控制面板--管理工具--服务--右键 Distributed Transaction Coordinator--属性--启动--并将启动类型设置为自动启动
go
--然后创建一个作业定时调用上面的同步处理存储过程就行了
企业管理器
--管理--SQL Server代理--右键作业--新建作业--"常规"项中输入作业名称--"步骤"项--新建--"步骤名"中输入步骤名--"类型"中选择"Transact-SQL 脚本(TSQL)" --"数据库"选择执行命令的数据库--"命令"中输入要执行的语句: exec p_process --确定--"调度"项--新建调度--"名称"中输入调度名称--"调度类型"中选择你的作业执行安排--如果选择"反复出现" --点"更改"来设置你的时间安排
然后将SQL Agent服务启动,并设置为自动启动,否则你的作业不会被执行
设置方法:
我的电脑--控制面板--管理工具--服务--右键 SQLSERVERAGENT--属性--启动类型--选择"自动启动"--确定.
--3.实现同步处理的方法2,定时同步
--在srv1中创建如下的同步处理存储过程
create proc p_process
as
--更新修改过的数据
update b set name=i.name,telphone=i.telphone
from srv2.库名.dbo.author b,author i
where b.id=i.id and
(b.name <> i.name or b.telphone <> i.telphone)
--插入新增的数据insert srv2.库名.dbo.author(id,name,telphone)
select id,name,telphone from author i
where not exists(
select * from srv2.库名.dbo.author where id=i.id)
--删除已经删除的数据(如果需要的话)
delete b
from srv2.库名.dbo.author b
where not exists(
select * from author where id=b.id)
go
oracle恢复删除的数据
分为两种方法:scn和时间戳两种方法恢复。
一、通过scn恢复删除且已提交的数据
1、获得当前数据库的scn号
select current_scn from v$database; (切换到sys用户或system用户查询)
查询到的scn号为:1499223
2、查询当前scn号之前的scn
select * from 表名 as of scn 1499220; (确定删除的数据是否存在,如果存在,则恢复数据;如果不是,则继续缩小scn号)
3、恢复删除且已提交的数据
flashback table 表名 to scn 1499220;
二、通过时间恢复删除且已提交的数据
1、查询当前系统时间
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;
2、查询删除数据的时间点的数据
select * from 表名 as of timestamp to_timestamp('2013-05-29 15:29:00','yyyy-mm-dd hh24:mi:ss'); (如果不是,则继续缩小范围)
3、恢复删除且已提交的数据
flashback table 表名 to timestamp to_timestamp('2013-05-29 15:29:00','yyyy-mm-dd hh24:mi:ss');
注意:如果在执行上面的语句,出现错误。可以尝试执行 alter table 表名 enable row movement; //允许更改时间戳
三、
1、查找表中多余的重复记录(多个字段)
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
2、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
一些数据库常用的导入导出命令吧:
该命令在“开始菜单>>运行>>CMD”中执行
一、数据导出(exp.exe)
1、将数据库orcl完全导出,用户名system,密码accp,导出到d:\daochu.dmp文件中
exp system/accp@orcl file=d:\daochu.dmp full=y
2、将数据库orcl中scott用户的对象导出
exp scott/accp@orcl file=d:\daochu.dmp owner=(scott搜索)
3、将数据库orcl中的scott用户的表emp、dept导出
exp scott/accp@orcl file= d:\daochu.dmp tables=(emp,dept)
4、将数据库orcl中的表空间testSpace导出
exp system/accp@orcl file=d:\daochu.dmp tablespaces=(testSpace)
二、数据导入(imp.exe)
1、将d:\daochu.dmp 中的数据导入 orcl数据库中。
imp system/accp@orcl file=d:\daochu.dmp full=y
2、如果导入时,数据表已经存在,将报错,对该表不会进行导入;加上ignore=y即可,表示忽略现有表,在现有表上追加记录。
imp scott/accp@orcl file=d:\daochu.dmp full=y ignore=y
3、将d:\daochu.dmp中的表emp导入
imp scott/accp@orcl file=d:\daochu.dmp tables=(emp)
4、导出的用户名和现在要导入的不一样:fromuser导出时的用户名,touser现在要导入的用户名
imp system/system@tyq file=e:\abc.dmp ignore=y fromuser=sa touser=system
完全卸载Oracle
用Oracle自带的卸载程序不能从根本上卸载Oracle,从而为下次的安装留下隐患,那么怎么才能完全卸载Oracle呢?
那就是直接注册表清除,步骤如下:
开始->设置->控制面板->管理工具->服务 停止所有Oracle服务
开始->程序->Oracle - OraDb11g_home1->Oracle安装产品-> Universal Installer卸装所有Oracle产品,但Universal Installer本身不能被删除
这里写图片描述
关闭所有关于Oracle的服务
关闭所有关于Oracle的服务
运行regedit,选择HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE,按del键删除这个入口
**运行regedit,删除以下这三个位置中的所有Oracle入口。
1.HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services\下所有Oracle删除
2.HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services\下所有Oracle删除
3.HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\下所有Oracle删除
** 运行regedit,
4.HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Eventlog\Application\下所有Oracle删除,
删除所有Oracle入口**
开始->设置->控制面板->系统->高级->环境变量 删除环境变量CLASSPATH和PATH中有关Oracle的设定
从桌面上、STARTUP(启动)组、程序菜单中,删除所有有关Oracle的组和图标
删除c:\Program Files\Oracle目录
重新启动计算机,重起后才能完全删除Oracle所在目录
删除与Oracle有关的文件,选择Oracle所在的缺省目录C:\Oracle,删除这个入 口目录及所有子目录,并从Windows目录(一般为C:\WINDOWS)下删除oralce文件等等
修改密码




java.sql.SQLException: ORA-28040:
没有匹配的验证协议(12c或者12c rac)
1.plsql可以连接,java程序不能连接,报如下错误:
2. 一直以来用的都是服务器上的Oracle数据库,今天改成连接本地Oracle 12c数据库是出问题了。hibernate连接Oracle12c时出现
java.sql.SQLException: ORA-28040: 没有匹配的验证协议。
通过查找资料找到了好的解决方案。不需要像网友所说的到官网上下载新的驱动来解决问题。
解决方案:
在Oracle的安装路径下找到sqlnet.ora文件。(我的安装路径F:\app\root\root\product\12.1.0\dbhome_1\NETWORK\ADMIN)
在文件的最后添加SQLNET.ALLOWED_LOGON_VERSION=8就完美解决了;
ORA-28000: the account is locked-的解决办法
解决:
(1)conn system/du012340 as sysdba; //以DBA的身份登录
(2)alter user system account unlock;// 然后解锁
Oracle ORA-01033: ORACLE initialization or shutdown in progress 错误解决办法
问题
好久没用数据库,最近需要导数据发现数据库已经无法连接,输入用户名密码也不起作用;之前也遇到过一次,直接重新安装。但Oracle的安装过程实在有点麻烦,所以寻找其他解决方法。
IMP-00058: 遇到 ORACLE 错误 1033
ORA-01033: ORACLE initialization or shutdown in progress用户名: system
口令:
IMP-00058: 遇到 ORACLE 错误 1033
ORA-01033: ORACLE initialization or shutdown in progress用户名: system
口令:
听同学说Oracle需要定期更改密码,觉得可能是这个原因,就去查找密码重置方法,密码不能用的话重置比较麻烦。
注意到找到的文章说一般是间隔180天才需要修改密码,而我距离上次重装应该没有半年,所以猜测不是这个原因。所以直接按照Oracle的错误编号来查找(Oracle这点做得很好,这个样错误容易查找),就找到了这篇 文章 ,之后的就是按照这个教程解决,文章作者没遇到但列出的问题我这里也遇到了,顺利解决。下面记录一下解决步骤:
解决步骤
第一步、sqlplus /NOLOG
第二步、SQL>connect sys/change_on_install as sysdba
提示:已成功
第三步、SQL>shutdown normal
提示:
数据库已经关闭
已经卸载数据库
ORACLE 例程已经关闭
第四步、SQL>startup mount
提示:
Total System Global Area 5110898688 bytes
Fixed Size 2806480 bytes
Variable Size 1107299632 bytes
Database Buffers 3992977408 bytes
Redo Buffers 7815168 bytes
数据库装载完毕。
第五步、SQL>alter database open(这一步出错)
提示:
ORA-01157: 无法标识/锁定数据文件11 - 请参阅DBWR 跟踪文件
ORA-01110: 数据文件11: ''''I:\tablesapce\APP0104_DEFAULT.dbf''
看到这个APP0104_DEFAULT.dbf 想起来了,是之前往数据库里导入DMP文件时创建的,当时是在移动硬盘上的,后来硬盘被拿走了,所以Oracle找不到这些表空间了。按照提示的数据文件编号11,对表空间进行drop操作。
第六步、SQL>alter database datafile 11 offline drop
第七步、重复第五第六步,直到所有无法连接的的表空间都已经drop为止(当时创建太多,一直drop到40才结束)
第八步、输入shutdown normal, startup mount, alter database open
最后、 无需重启,使用原来的用户名密码即可登录成功;使用SQL Developer也可以连接。
至此,问题解决。
ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务
ORA-12541 TNS 无监听程序
找到E:\app\chuangxing1116\product\11.2.0\dbhome_1\NETWORK\ADMIN文件夹下的listener.ora文件进行修改
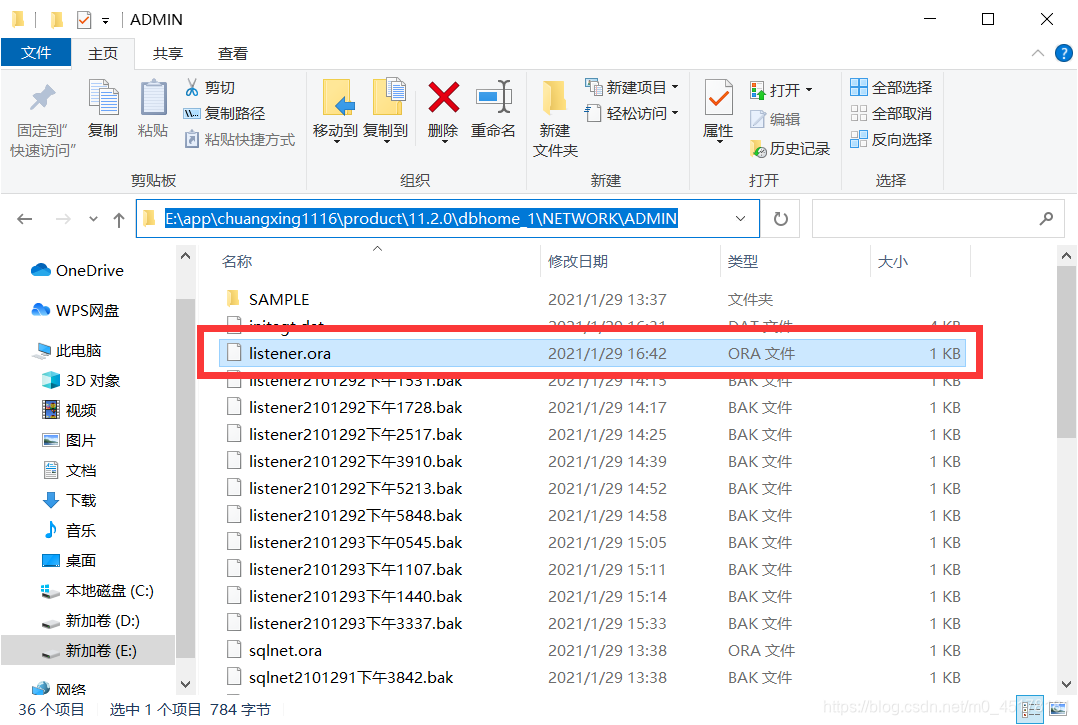
1.加入orcl内容
(SID_DESC =
(GLOBAL_DBNAME = orcl)
(ORACLE_HOME = E:\app\chuangxing1116\product\11.2.0\dbhome_1)
(SID_NAME = orcl)
)
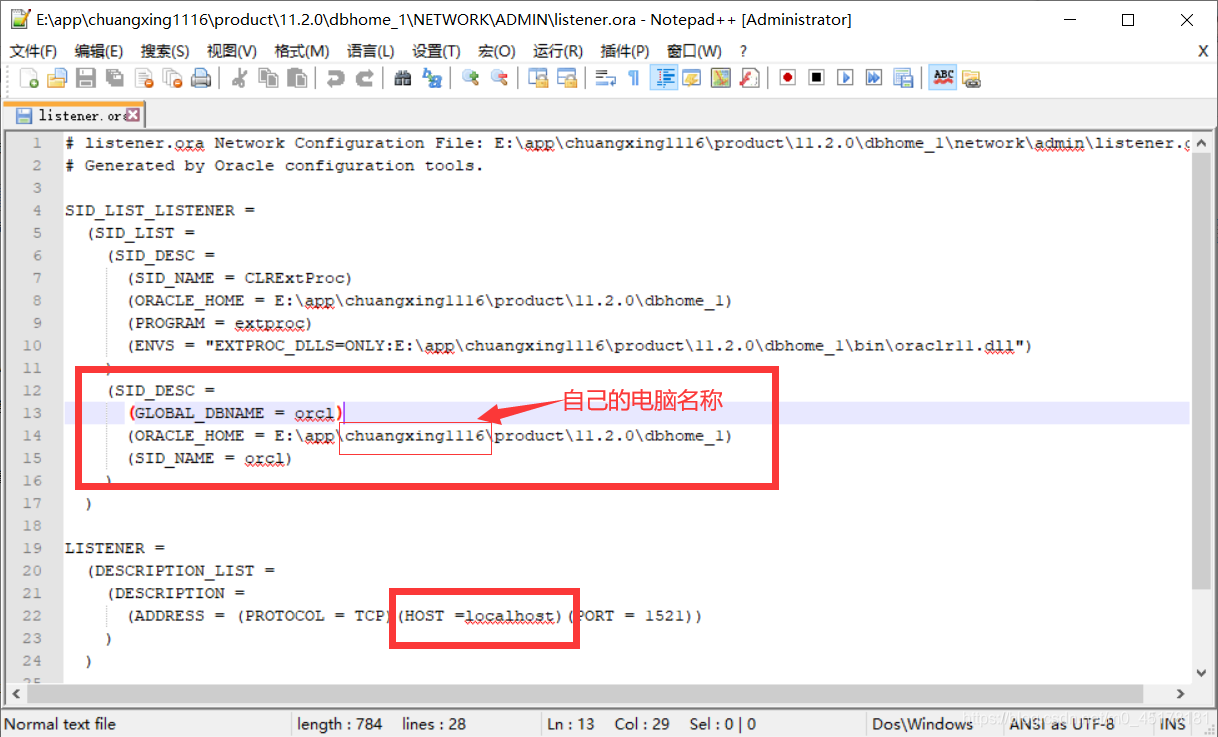
2.修改host的ip值为localhost
3.打开同路径下的tnsnames.ora
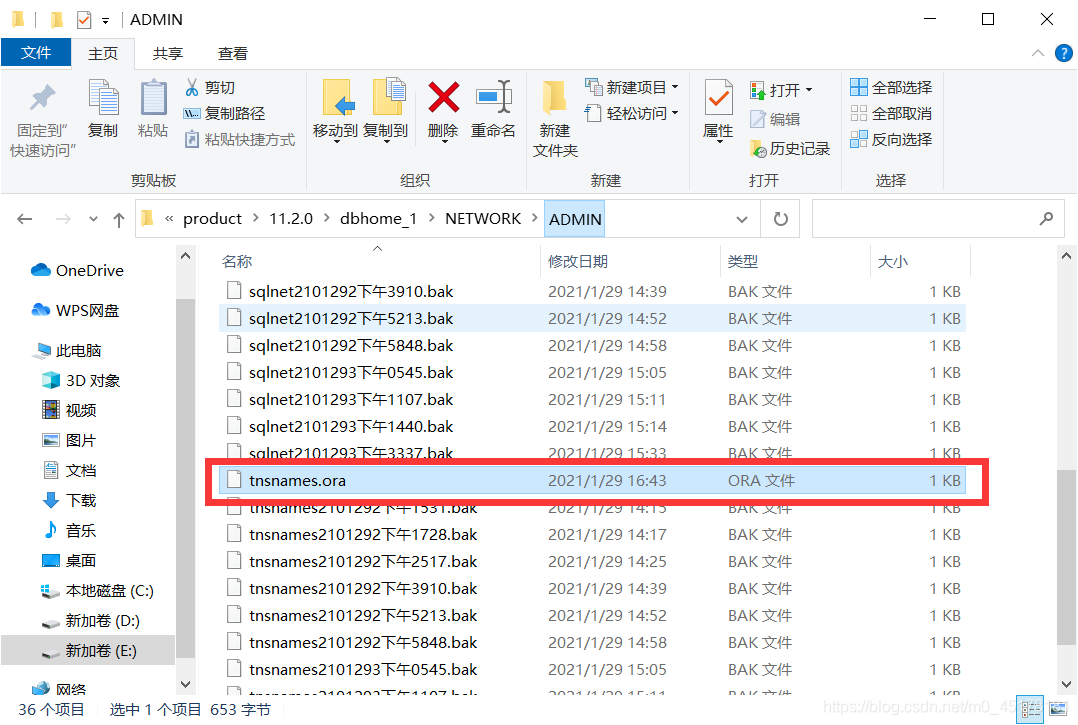
4.修改tnsnames.ora的host全部改为localhost
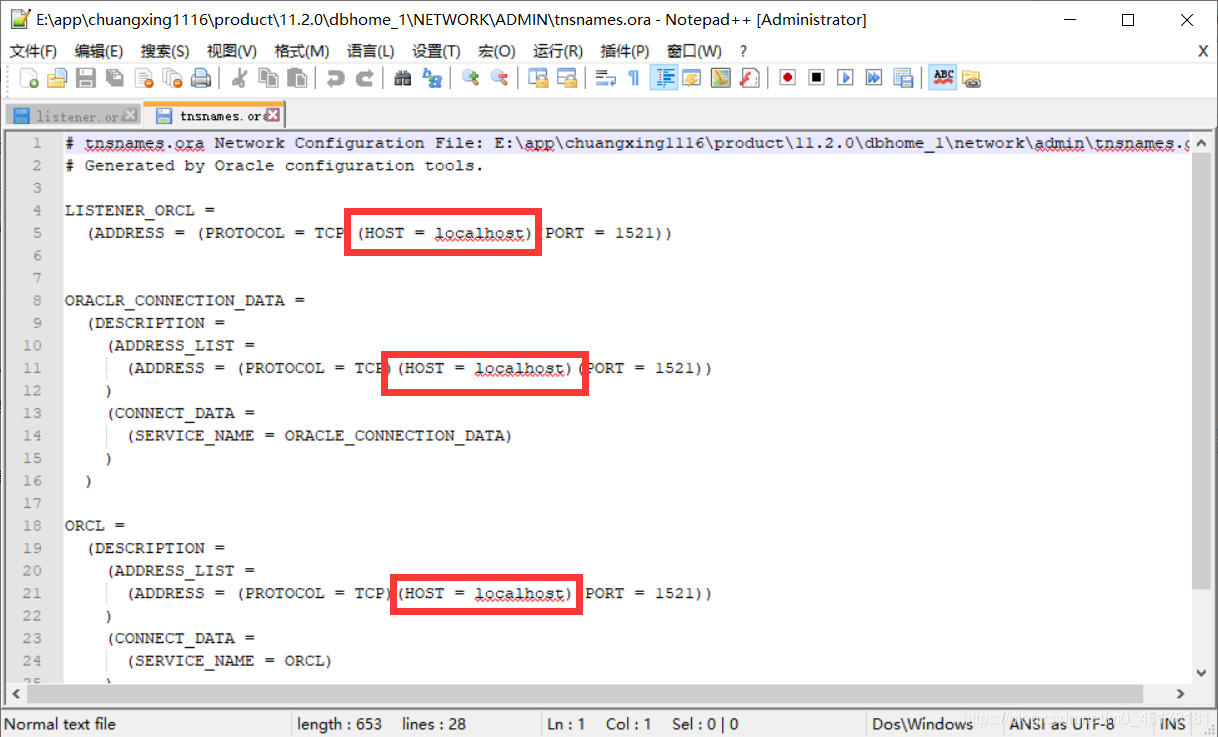
5.找到net configguration assistant 运行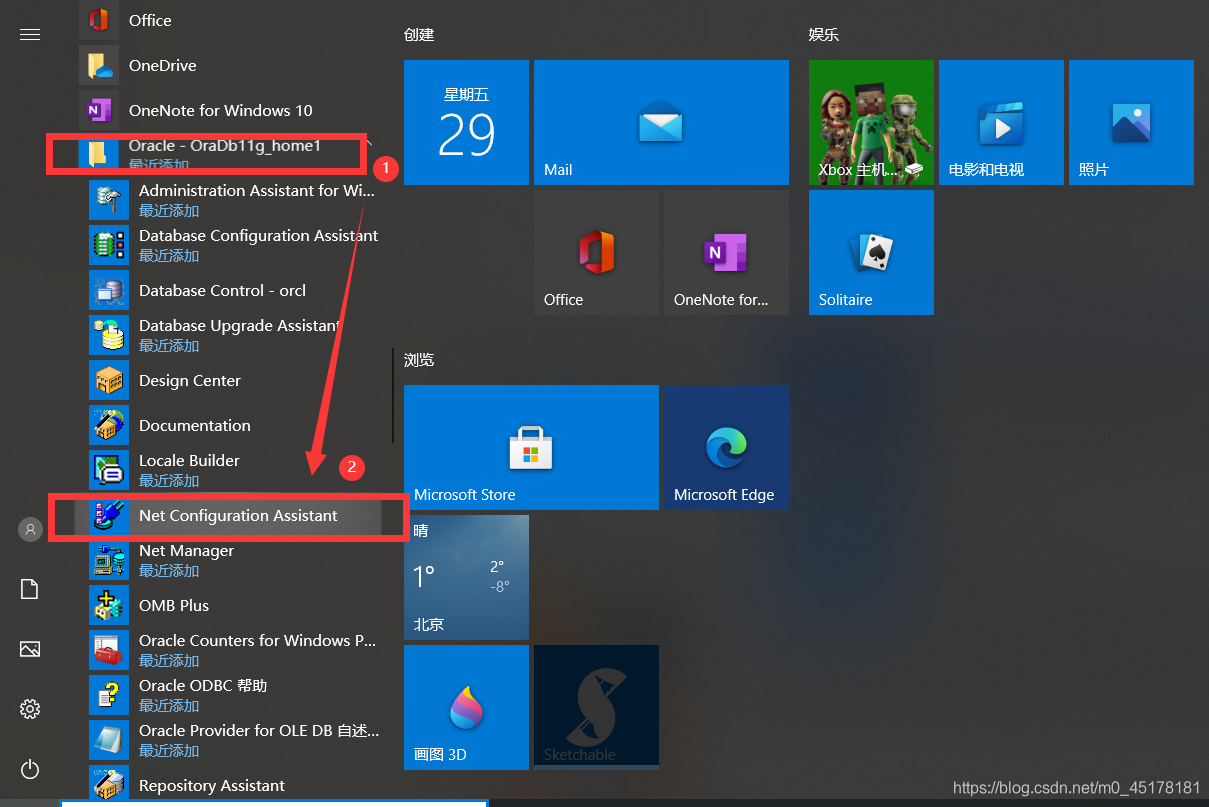
出现如上的原因是,可能是大家再配置oracle客户端时,虽然链接成功了,步骤上可能有些错误。大家使用Net Cofiguration Assistant客户端时重新配置了Orcl,而不是添加,我们应该如下步骤处理,就不会出问题了。
1、如果Net Cofiguration Assistant中已经有了Orcl。我们可以重新配置
2、如果Net Cofiguration Assistant中没有Orcl,我们应该添加 具体界面如下图所示。
3.选择重新配置
4.选择监听程序,如下图所示,选择协议,一般默认就好,点击下一步。

5.选择端口号,如下图所示,点击下一步。

6.选择“否”,如下图所示,点击下一步。

7.监听程序配置完成,如下图所示,点击下一步。

8.选择“本地网络服务名配置”,如下图所示,点击下一步。
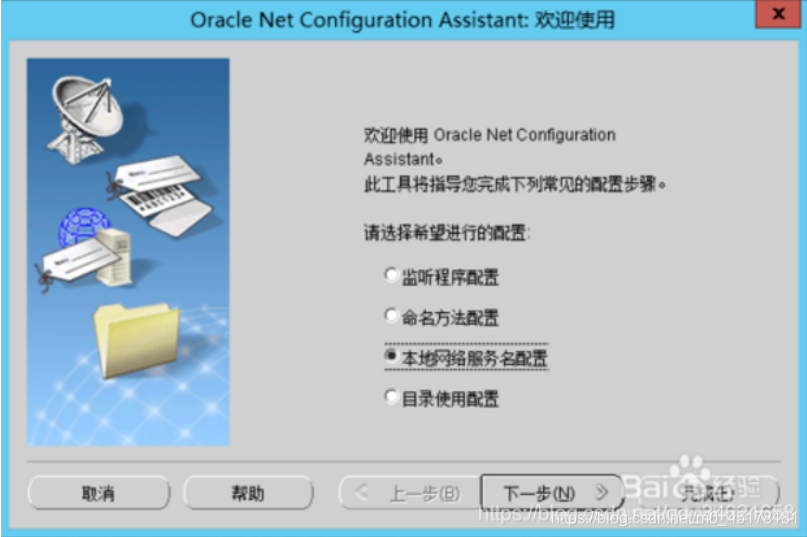
9.选择“重新配置”,如下图所示,点击下一步。

1.“网络服务名”选择你自己数据库的名字,如下图所示,点击下一步。我的是ORCL
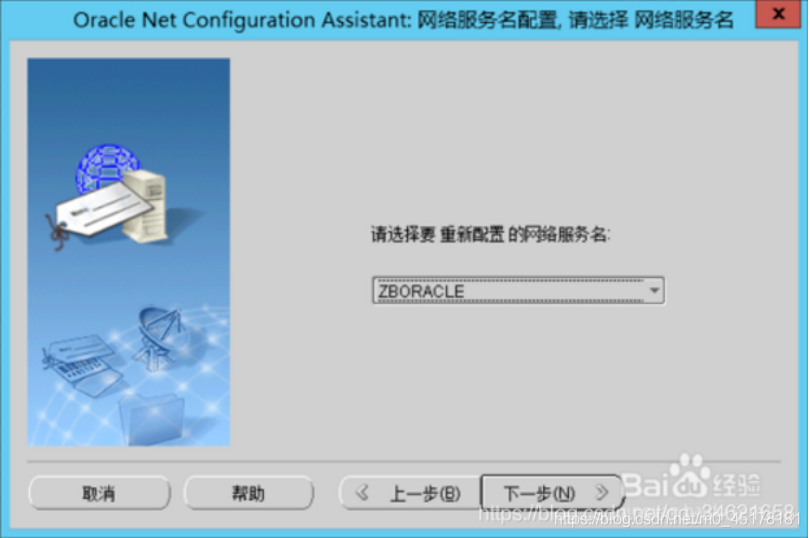
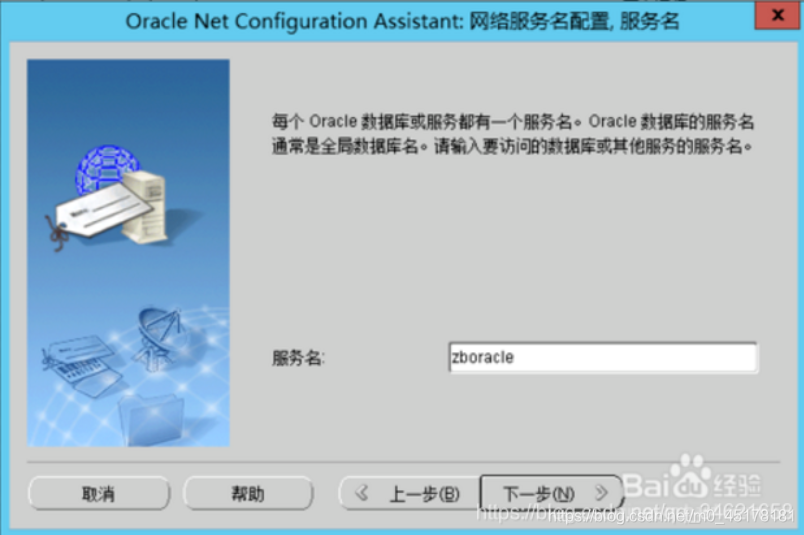
11.填写“服务名”,其实就是你创建数据库时的全数据库名,如下图所示,点击下一步。 我的是ORCL填ORCL
12.选择协议,默认选择“TCP”,如下图所示,点击下一步。

13.填写“主机名”,可以是你的IP地址,也可以是你的主机名;选择端口号,如下图所示,点击下一步。

14.选择“是,进行测试”,如下图所示,点击下一步
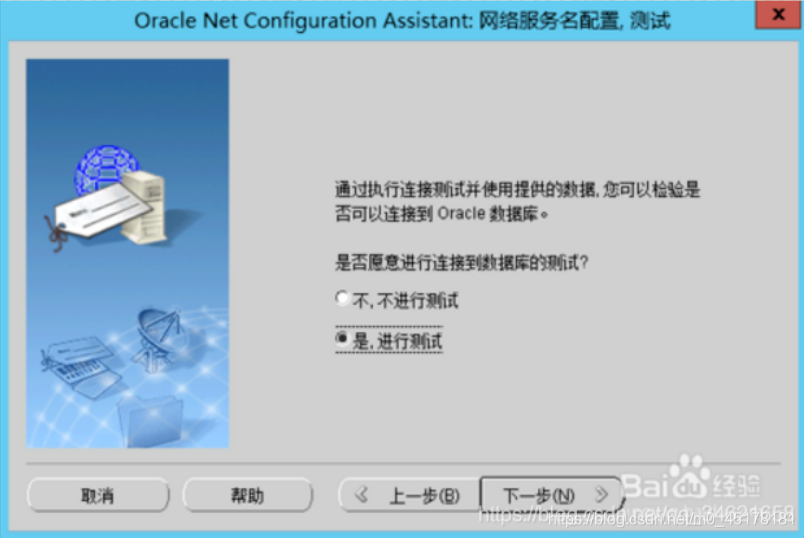
15.选择“更改登陆”,填写“用户名”和“口令”,点击“确定”会显示“正在连接…测试成功。”,点击下一步。
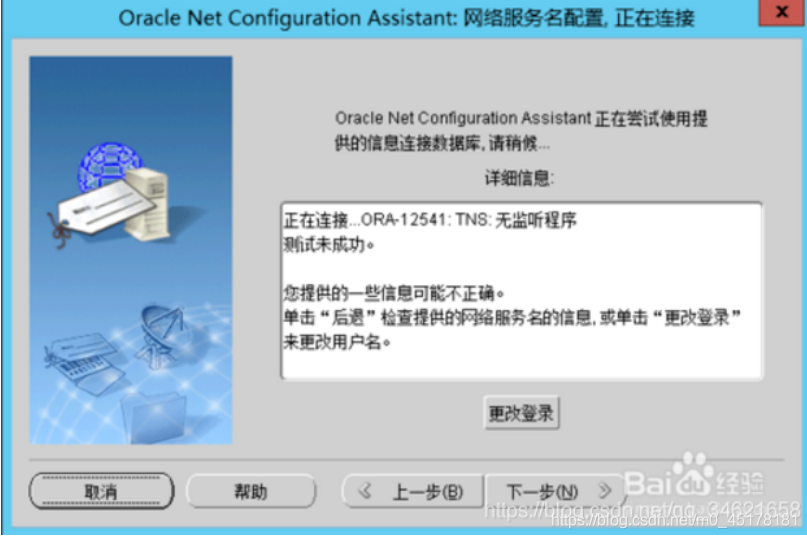
16.填写“网络服务名”,就是你自己的数据库名,小编的是“zboracle”,点击下一步。“是否配置另一个服务名?”选择“否”,点击下一步,完成。
17.重启监听器服务和orcl服务
18.查看能否登录,如果不行进行下面操作
19.再去检查最开始修改的2个文件,确认修改好了
20.重启监听器服务和orcl服务

















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









