






案例一:找出最受欢迎的电影。
数据样本一览:
- <版本 A>
popular-movies.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("PopularMovies")
sc = SparkContext(conf=conf)
lines = sc.textFile("hdfs:///u.data")
movies = lines.map(lambda x: (int(x.split()[1]), 1))
movieCounts = movies.reduceByKey(lambda x, y: x + y)
print(movieCounts.collect())
flipped = movieCounts.map(lambda x: (x[1], x[0]))
sortedMovies = flipped.sortByKey()
results = sortedMovies.collect()
for result in results:
print(result)
运行:$ spark-submit popular-movies.py
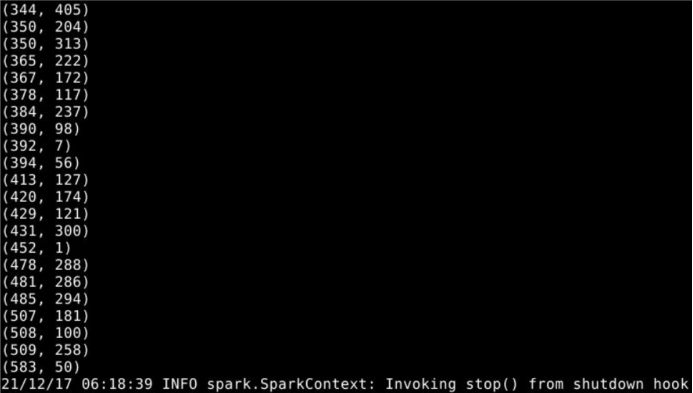
运行结果

- <版本 B> popular-movies-nicer.py
from pyspark import SparkConf, SparkContext
def loadMovieNames():
movieNames = {}
with open("/u.item") as f:
for line in f:
line = line.encode('utf-8').decode('utf-8-sig')
fields = line.split('|')
movieNames[int(fields[0])] = fields[1]
return movieNames
conf = SparkConf().setMaster("local").setAppName("PopularMovies")
sc = SparkContext(conf=conf)
nameDict = sc.broadcast(loadMovieNames())
lines = sc.textFile("hdfs:///u.data")
movies = lines.map(lambda x: (int(x.split()[1]), 1))
movieCounts = movies.reduceByKey(lambda x, y: x + y)
flipped = movieCounts.map(lambda x: (x[1], x[0]))
sortedMovies = flipped.sortByKey()
sortedMoviesWithNames = sortedMovies.map(lambda x: (nameDict.value[x[1]], x[0]))
results = sortedMoviesWithNames.collect()
for result in results:
print(result)
运行:$ spark-submit most-popular-movies-nicer.py
运行结果
- <版本 C> popular-movies-dataframe.py
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql import functions
def loadMovieNames():
movieNames = {}
with open("/u.item") as f:
for line in f:
line = line.encode('utf-8').decode('utf-8-sig')
fields = line.split('|')
movieNames[int(fields[0])] = fields[1]
return movieNames
spark = SparkSession.builder.config("spark.sql.warehouse.dir", "file:///C:/temp").appName("PopularMovies").getOrCreate()
nameDict = loadMovieNames()
lines = spark.SparkContext.textFile("hdfs:///u.data")
movies = lines.map(lambda x: Row(movieID=int(x.split()[1])))
movieDataset = spark.createDataFrame(movies)
topMoviesIDs = movieDataset.groupBy("movieID").count().orderBy("count", ascending=False).cache()
topMoviesIDs.show()
too10 = topMoviesIDs.take(10)
print('\n')
for result in too10:
print("%s: %d" % (nameDict[result[0]], result[1]))
spark.stop()
运行:$spark-submit popular-movies-dataframe.py
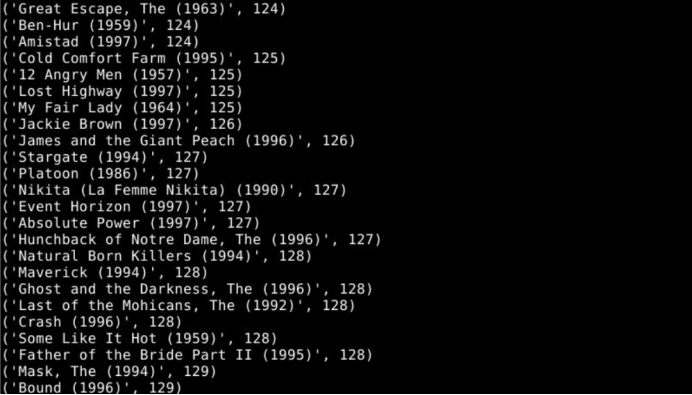
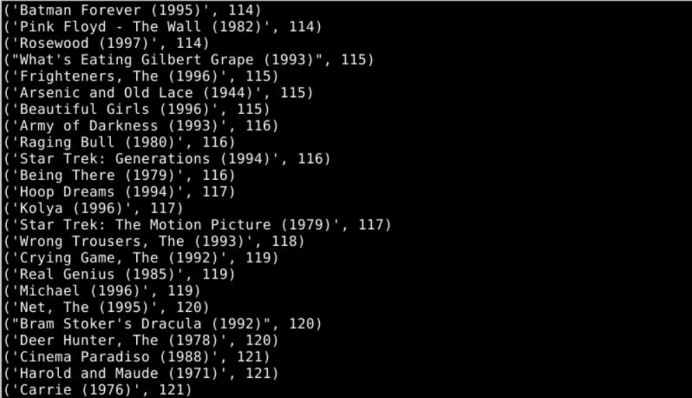
运行结果

案例二:(A)找出社交图中最受欢迎的超级英雄;(B)超级之间的间隔
漫威数据集:
如果两个英雄出现在同一本漫画书里面,则将他们连接。因此可以创建一个超级英雄图。
- <问题 A> most-popular-superhero.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("PopularHero")
sc = SparkContext(conf=conf)
def countCoOccurences(line):
elements = line.split()
return int(elements[0]), len(elements) - 1
def parseNames(line):
fields = line.split('\"')
return int(fields[0]), fields[1].encode("utf8")
names = sc.textFile("hdfs:///Marvel-names.txt")
namesRdd = names.map(parseNames)
lines = sc.textFile("hdfs:///Marvel-graph.txt")
pairings = lines.map(countCoOccurences)
totalFriendsByCharacter = pairings.reduceByKey(lambda x, y: x + y)
flipped = totalFriendsByCharacter.map(lambda x: (x[1], x[0]))
mostPopular = flipped.max()
mostPopularName = namesRdd.lookup(mostPopular[1])[0]
print(mostPopularName.decode() + " is the most popular superhero,with" + str(mostPopular[0]) + " co.appearances.")
运行: $ spark-submit most-popular-superhero.py
实验结果

- <版本 B> degrees-of-separate.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("DegreesOfSeparation")
sc = SparkContext(conf=conf)
startCharacterID = 5306
targetCharacterID = 14
hitCounter = sc.accumulator(0)
def convertToBFS(line):
fields = line.split()
heroID = int(fields[0])
connections = []
for connection in fields[1:]:
connections.append((int(connection)))
color = 'WHITE'
distance = 9999
if heroID == startCharacterID:
color = 'GRAY'
distance = 0
return heroID, (connections, distance, color)
def createStartingRdd():
inputFile = sc.textFile("hdfs:///Marvel-graph.txt")
return inputFile.map(convertToBFS)
def bfsMap(node):
CharacterID = node[0]
data = node[1]
connections = data[0]
distance = data[1]
color = data[2]
results = []
if color == 'GRAY':
for connection in connections:
newCharacterID = connection
newDistance = distance + 1
newColor = 'GRAY'
if targetCharacterID == connection:
hitCounter.add(1)
newEntry = (newCharacterID, ([], newDistance, newColor))
results.append(newEntry)
color = 'BLACK'
results.append((CharacterID, (connections, distance, color)))
return results
def bfsReduce(data1, data2):
edges1 = data1[0]
edges2 = data2[0]
distance1 = data1[1]
distance2 = data2[1]
color1 = data1[2]
color2 = data2[2]
distance = 9999
color = 'WHITE'
edges = []
if len(edges1) > 0:
edges1.extend(edges1)
if len(edges2) > 0:
edges2.extend(edges2)
if distance1 < distance:
distance = distance1
if distance2 < distance:
distance = distance2
if color1 == 'WHITE' and (color2 == 'GRAY' or color2 == 'BLACK'):
color = color2
if color1 == 'GRAY' and color2 == 'BLACK':
color = color2
if color2 == 'WHITE' and (color1 == 'GRAY' or color1 == 'BLACK'):
color = color1
if color2 == 'GRAY' and color1 == 'BLACK':
color = color1
return edges, distance, color
iterationRdd = createStartingRdd()
for iteration in range(0, 10):
print("Running BFS iteration# " + str(iteration + 1))
mapped = iterationRdd.flatMap(bfsMap)
print("Processing" + str(mapped.count()) + " values.")
if hitCounter.value > 0:
print("Hit the target character ! From " + str(hitCounter.value)
+ " diferent direction(s).")
break
iterationRdd = mapped.reduceByKey(bfsReduce)
运行:$ spark-submit degrees-of-separate.py
实验结果






















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









