







 本文通过一个电影推荐的案例,介绍如何使用julia进行数据分析。选用MovieLens的1M数据集,采用基于用户的协同过滤方法进行推荐。首先,详细阐述问题,接着进行数据准备,然后分析思路,包括基于用户的协同过滤原理。在数据探索阶段,揭示了评分矩阵的稀疏性。最后,展示了计算用户相似度和预测评分的代码实现。
本文通过一个电影推荐的案例,介绍如何使用julia进行数据分析。选用MovieLens的1M数据集,采用基于用户的协同过滤方法进行推荐。首先,详细阐述问题,接着进行数据准备,然后分析思路,包括基于用户的协同过滤原理。在数据探索阶段,揭示了评分矩阵的稀疏性。最后,展示了计算用户相似度和预测评分的代码实现。
前言
通过案例来学习数据分析的思路和练习相应分析工具,往往最有效的。本文用julia来进行全流程的探索和分析,以期达到既掌握分析思路,又练习了这一新兴的数据科学利器。同时,个性化推荐是个太大的topic,涉及的理论方法和实践非常多,本文有些地方会详细展开,有些则一笔带过。
如无特殊说明,本文中所使用的code均为julia代码,IDE环境为JuliaPro.
问题阐述
个性化推荐是当今网络世界上普遍存在的一种大数据服务,视频、音乐、读书、新闻、购物等领域均流行此类服务。本文面对的问题是基于海量用户在MovieLens网站上对不同电影进行的评分数据,来为用户进行电影推荐。
数据准备
本文使用的数据为明尼苏达大学的 [MovieLens],我们下载其中的1M大小版本的数据集,这个数据集存储的是:
100,000 ratings and 1,300 tag applications applied to 9,000 movies by 700 users. Last updated 10/2016. Users were selected at random for inclusion. All selected users had rated at least 20 movies. No demographic information is included. Each user is represented by an id, and no other information is provided.看起来是把用户在 MovieLens网站(感兴趣的话可点击 [movielens.org]]了解)上对电影的评价记录做了抽样采集,通过readme文件可以了解数据集的详细信息。然后即可导入数据,并查看一些简单的信息:
using DataFrames
#为了更方便地对不同数据集进行数据探索,定义一个函数
function get_info(dataset)
println("数据集大小为: ", size(dataset))
println("数据预览: ", head(dataset))
println("字段信息:")
showcols(dataset)
end
#数据导入
movies = readtable("~/ml-latest-small/movies.csv",header=true)
ratings = readtable("~/ml-latest-small/ratings.csv", header=true)
tags = readtable("~/ml-latest-small/tags.csv",header=true)
#获取数据信息
get_info(movies)
get_info(ratings)
get_info(tags)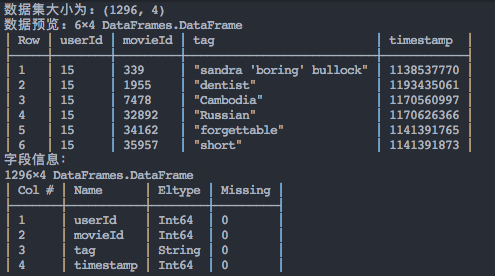
分析思路
电影推荐是一种典型的个性化推荐场景,相关的方法有很多。
1. 基于用户的协同过滤,潜在假设是相似用户对于同类电影可能会有相似的偏好程度,人以类聚嘛,兴趣的相似在现实社会中确实是普遍存在的;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









