






花了一周时间收集大量MYSQL经典面试题目📚,内容涵盖了数据库范式、事务、引擎、索引、锁、日志、备份、分区、主从复制等知识点🏝️。适合准备MySQL面试的读者参考和复习🌟📢。
📖Mysql经典面试题目Top100道题🔥🔥
- 1 - 25 题
- 26 - 50 题
- 51 - 75 题
- 76 - 100 题 ◀️
🔸题目目录:
76. 一条Sql的执行顺序?
77. 关心过业务系统里面的sql耗时吗?统计过慢查询吗?对慢查询都怎么优化过?
78. 列值为NULL时,查询是否会用到索引?
79. mysql自增主键用完了怎么办?
80. 主键使用自增ID还是UUID,为什么?
81. 字段为什么要求定义为not null?
82. 如果要存储用户的密码散列,应该使用什么字段进行存储?
83. Mysql驱动程序是什么?
84. 优化特定类型的查询语句 ?
85. 如何优化长难的查询语句?有实战过吗
86. MySQL数据库cpu飙升的话,要怎么处理呢?
87. 读写分离常见方案?
88. MySQL的复制原理以及流程
89. Innodb的事务实现原理
90. MySQL中DATETIME和TIMESTAMP的区别?
91. 谈谈MySQL的Explain
92. Innodb的事务与日志的实现方式
93. MySQL中TEXT数据类型的最大长度
94. 500台db,在最快时间之内重启。
95. 你是如何监控你们的数据库的?你们的慢日志都是怎么查询的?
96. 你是否做过主从一致性校验,如果有,怎么做的,如果没有,你打算怎么做?
97. 你们数据库是否支持emoji表情存储,如果不支持,如何操作?
98. MySQL如何获取当前日期?
99. 一个6亿的表a,一个3亿的表b,通过外间tid关联,你如何最快的查询出满足条件的第50000到第50200中的这200条数据记录。
100. Mysql一条SQL加锁分析。
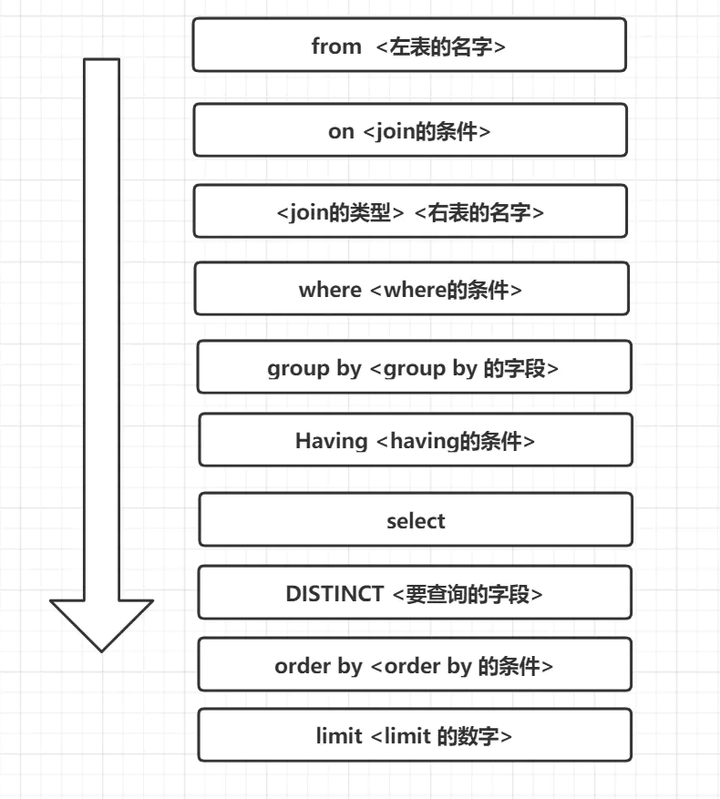
76. 一条Sql的执行顺序?
77. 关心过业务系统里面的sql耗时吗?统计过慢查询吗?对慢查询都怎么优化过?
- 我们平时写Sql时,都要养成用explain分析的习惯。
- 慢查询的统计,运维会定期统计给我们
优化慢查询:
- 分析语句,是否加载了不必要的字段/数据。
- 分析SQl执行句话,是否命中索引等。
- 如果SQL很复杂,优化SQL结构
- 如果表数据量太大,考虑分表
78. 列值为NULL时,查询是否会用到索引?
列值为NULL也是可以走索引的 计划对列进行索引,应尽量避免把它设置为可空,因为这会让 MySQL 难以优化引用了可空列的查询,同时增加了引擎的复杂度
79. mysql自增主键用完了怎么办?
自增主键一般用int类型,一般达不到最大值,可以考虑提前分库分表的。
自增ID用完后 一直都是最大值 如果标识了主键 则主键冲突
80. 主键使用自增ID还是UUID,为什么?
如果是单机的话,选择自增ID;如果是分布式系统,优先考虑UUID吧,但还是最好自己公司有一套分布式唯一ID生产方案吧。
- 自增ID:数据存储空间小,查询效率高。但是如果数据量过大,会超出自增长的值范围,多库合并,也有可能有问题。
- uuid:适合大量数据的插入和更新操作,但是它无序的,插入数据效率慢,占用空间大。
81. 字段为什么要求定义为not null?
null值会占用更多的字节,并且null有很多坑的。
82. 如果要存储用户的密码散列,应该使用什么字段进行存储?
密码散列,盐,用户身份证号等固定长度的字符串,应该使用char而不是varchar来存储,这样可以节省空间且提高检索效率。
83. Mysql驱动程序是什么?
这个jar包: mysql-connector-java-5.1.18.jar Mysql驱动程序主要帮助编程语言与 MySQL服务端进行通信,如连接、传输数据、关闭等。
84. 优化特定类型的查询语句
- 比如使用select 具体字段代替 select *
- 使用count(*) 而不是count(列名)
- 在不影响业务的情况,使用缓存
- explain 分析你的SQL
85. 如何优化长难的查询语句?有实战过吗?
- 将一个大的查询分为多个小的相同的查询
- 减少冗余记录的查询。
- 一个复杂查询可以考虑拆成多个简单查询
- 分解关联查询,让缓存的效率更高。
86. MySQL数据库cpu飙升的话,要怎么处理呢?
排查过程:
- 使用top 命令观察,确定是mysqld导致还是其他原因。
- 如果是mysqld导致的,show processlist,查看session情况,确定是不是有消耗资源的sql在运行。
- 找出消耗高的 sql,看看执行计划是否准确, 索引是否缺失,数据量是否太大。
处理:
- kill 掉这些线程(同时观察 cpu 使用率是否下降),
- 进行相应的调整(比如说加索引、改 sql、改内存参数)
- 重新跑这些 SQL。
其他情况:
也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
87. 读写分离常见方案?
- 应用程序根据业务逻辑来判断,增删改等写操作命令发给主库,查询命令发给备库。
- 利用中间件来做代理,负责对数据库的请求识别出读还是写,并分发到不同的数据库中。(如:amoeba,mysql-proxy)
88. MySQL的复制原理以及流程
主从复制原理,简言之,就三步曲,如下:
- 主数据库有个bin-log二进制文件,纪录了所有增删改Sql语句。(binlog线程)
- 从数据库把主数据库的bin-log文件的sql语句复制过来。(io线程)
- 从数据库的relay-log重做日志文件中再执行一次这些sql语句。(Sql执行线程)
如下图所示:
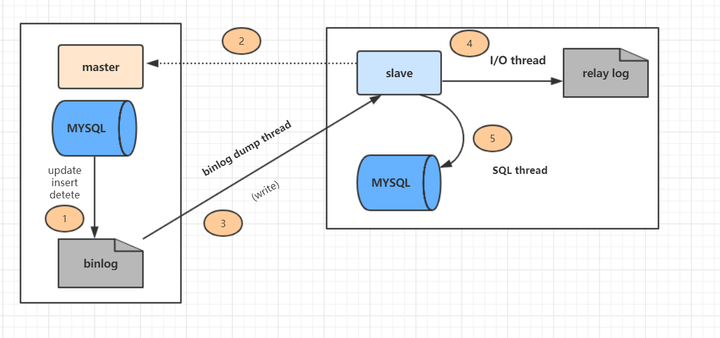
上图主从复制分了五个步骤进行:
- 步骤一:主库的更新事件(update、insert、delete)被写到binlog
- 步骤二:从库发起连接,连接到主库。
- 步骤三:此时主库创建一个binlog dump thread,把binlog的内容发送到从库。
- 步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
- 步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
89. Innodb的事务实现原理?
- 原子性:是使用 undo log来实现的,如果事务执行过程中出错或者用户执行了rollback,系统通过undo log日志返回事务开始的状态。
- 持久性:使用 redo log来实现,只要redo log日志持久化了,当系统崩溃,即可通过redo log把数据恢复。
- 隔离性:通过锁以及MVCC,使事务相互隔离开。
- 一致性:通过回滚、恢复,以及并发情况下的隔离性,从而实现一致性。
90. MySQL中DATETIME和TIMESTAMP的区别
存储精度都为秒
区别:
- DATETIME 的日期范围是 1001——9999 年;TIMESTAMP 的时间范围是 1970——2038 年
- DATETIME 存储时间与时区无关;TIMESTAMP 存储时间与时区有关,显示的值也依赖于时区
- DATETIME 的存储空间为 8 字节;TIMESTAMP 的存储空间为 4 字节
- DATETIME 的默认值为 null;TIMESTAMP 的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP)
91. 谈谈MySQL的Explain
Explain 执行计划包含字段信息如下:
分别是 id、select_type、table、partitions、type、possible_keys、key、key_len、ref、rows、filtered、Extra 等12个字段。 我们重点关注的是type,它的属性排序如下:
system > const > eq_ref > ref > ref_or_null >
index_merge > unique_subquery > index_subquery >
range > index > ALL
92. Innodb的事务与日志的实现方式
- innodb两种日志redo和undo。
日志的存放形式
- redo:在页修改的时候,先写到 redo log buffer 里面, 然后写到 redo log 的文件系统缓存里面(fwrite),然后再同步到磁盘文件( fsync)。
- Undo:在 MySQL5.5 之前, undo 只能存放在 ibdata文件里面, 5.6 之后,可以通过设置 innodb_undo_tablespaces 参数把 undo log 存放在 ibdata之外。
事务是如何通过日志来实现的
- 因为事务在修改页时,要先记 undo,在记 undo 之前要记 undo 的 redo, 然后修改数据页,再记数据页修改的 redo。 Redo(里面包括 undo 的修改) 一定要比数据页先持久化到磁盘。
- 当事务需要回滚时,因为有 undo,可以把数据页回滚到前镜像的 状态,崩溃恢复时,如果 redo log 中事务没有对应的 commit 记录,那么需要用 undo把该事务的修改回滚到事务开始之前。
- 如果有 commit 记录,就用 redo 前滚到该事务完成时并提交掉。
93. MySQL中TEXT数据类型的最大长度
- TINYTEXT:256 bytes
- TEXT:65,535 bytes(64kb)
- MEDIUMTEXT:16,777,215 bytes(16MB)
- LONGTEXT:4,294,967,295 bytes(4GB)
94. 500台db,在最快时间之内重启。
- 可以使用批量 ssh 工具 pssh 来对需要重启的机器执行重启命令。
- 也可以使用 salt(前提是客户端有安装 salt)或者 ansible( ansible 只需要 ssh 免登通了就行)等多线程工具同时操作多台服务
95. 你是如何监控你们的数据库的?你们的慢日志都是怎么查询的?
监控的工具有很多,例如zabbix,lepus,我这里用的是lepus
96. 你是否做过主从一致性校验,如果有,怎么做的,如果没有,你打算怎么做?
主从一致性校验有多种工具 例如checksum、mysqldiff、pt-table-checksum等
97. 你们数据库是否支持emoji表情存储,如果不支持,如何操作?
更换字符集utf8-->utf8mb4
98. MySQL如何获取当前日期?
SELECT CURRENT_DATE();
99. 一个6亿的表a,一个3亿的表b,通过外间tid关联,你如何最快的查询出满足条件的第50000到第50200中的这200条数据记录。
1、如果A表TID是自增长,并且是连续的,B表的ID为索引
select * from a,b where a.tid = b.id and a.tid>500000 limit 200;
2、如果A表的TID不是连续的,那么就需要使用覆盖索引.TID要么是主键,要么是辅助索引,B表ID也需要有索引。
select * from b , (select tid from a limit 50000,200) a where b.id = a .tid;
100. Mysql一条SQL加锁分析
一条SQL加锁,可以分9种情况进行:
- 组合一:id列是主键,RC隔离级别
- 组合二:id列是二级唯一索引,RC隔离级别
- 组合三:id列是二级非唯一索引,RC隔离级别
- 组合四:id列上没有索引,RC隔离级别
- 组合五:id列是主键,RR隔离级别
- 组合六:id列是二级唯一索引,RR隔离级别
- 组合七:id列是二级非唯一索引,RR隔离级别
- 组合八:id列上没有索引,RR隔离级别
- 组合九:Serializable隔离级别
















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











