







前言
前面两节课学了深度学习中的基础概念,今天主要去学习深度学习中一个非常重要的算法——反向传播算法。
前面学的梯度下降算法:

可以看到,求梯度时,上图红色方框里要求的梯度向量是很大很大的。
为了高效计算这个梯度,我们使用反向传播算法。
本质:反向传播算法并不是一个和梯度下降法不同的训练的方法,他就是一个梯度下降的方法,只是它计算这个梯度向量的效率比较高。
反向传播算法并没有什么十分高深的数学,你唯一需要记得的就是:
Chain Rule(链式法则)—这个考研高数学过哈哈哈:

然后我们具体推导反向传播算法:
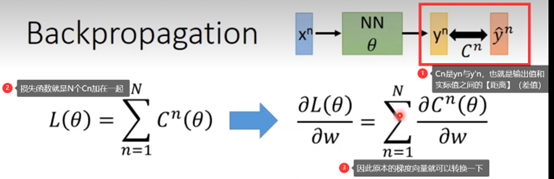
现在我们就focus在怎么计算最右边Cn那个式子
先取神经网络中的某一个神经元:
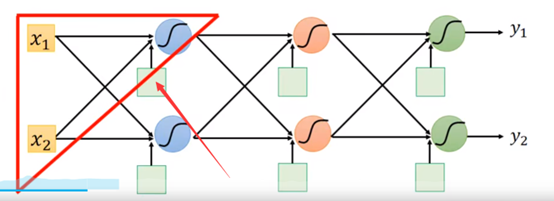
前面我们已经学过怎么由x变成那个“蓝色的蚯蚓”,如图中公式,而我们取其中的参数w,尝试所谓反向传播算法,先用一个链式法则,然后我们定义其中一部分是前向传递,其中一部分是反向传递,如图框柱部分所示:
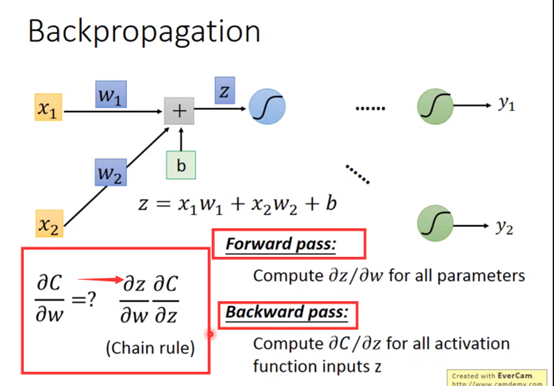
如图所示,前向传播为:αz/αw,后向传播为:αC/αz
对于前向传播,αz/αw这个偏导值很简单,你从那个z=x1w1+x2w2+b就能直接看出来了,下面这个图代入具体数值,方便理解:
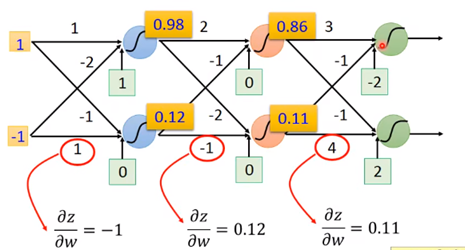
难的是反向传递,妙的也是反向传递αC/αz:
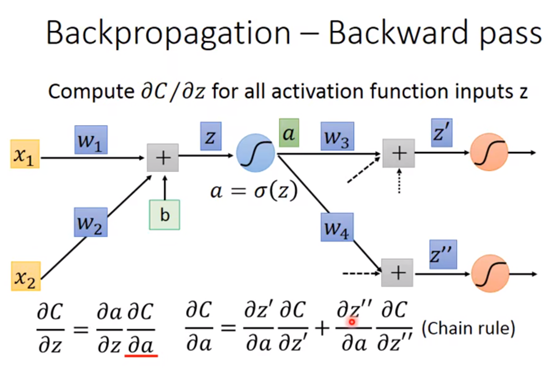
我们先正向推一下,如上图,这时转化为求αC/αz’和αC/αz’’
那么怎么求呢?
反向求解:
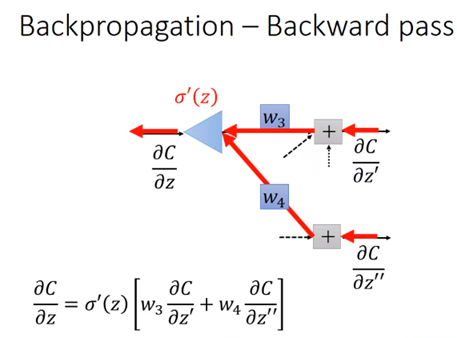
因为最后一定会有一个output—y嘛,那么假如αC/αz’和αC/αz’’是最后一级,之后就输出得到了y,那么αC/αz’和αC/αz’’自然可以根据y由链式法则来求得。如果不是最后一级,那么也可以由上一级推出,而上一级由上上一级…一直到最后一级(可以理解为一个反向递归)
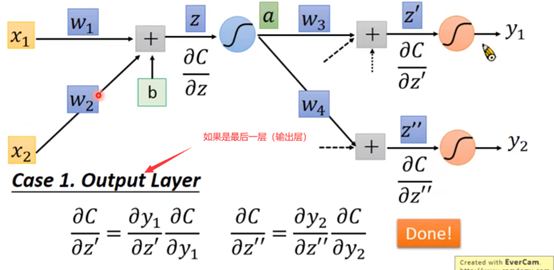
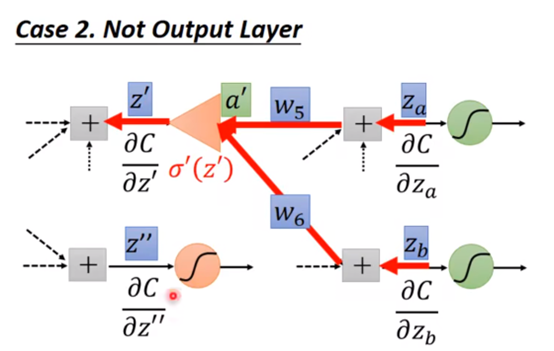
怎么样,是不是很聪明!















 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









